







目录
在数据挖掘,处理数据时,经常用到pandas的相关函数,经常不能准确的把函数完全写出来,这一次索性把我知道的常用的函数都整理出来。因为函数有很多,这里就不将函数所有的参数列举出来解释了,望理解!需要的话可以自己复制下去补充。
numpy常用函数
t1 = np.array([1,2,3]) # 使用numpy生成数组,得到ndarray的类型
t2 = np.arange(12) # 等同于使用range使用的方法也相同 这里range也可以使用
t=np.random.randint(40,100,51) # 随机生成51个40到100的数字,
t6 = t5.flatten() # 多维数据转换成一维数组
t6=t5.reshape((3,4)) #改变数组的形状,多维数据时为元组形式
t1 = t.astype(float) # 改变数组中的数据类型
t1 = t.T # 将数组转置
t3 = np.vstack((t1,t2)) # 将t1,t2竖直拼接 ,元组形式,
t3 = np.hstack((t1,t2)) # 将t1,t2水平拼接,元组形式
t.isnull() # 返回的是bool值 , 空数据为 True ,有数据则为False
t.isnull().sum() # 返回t中的空数据的个数
c.dropna(axis=0,how="any",inplace=False) # 删除缺失值 默认将含有NaN的结果一行删除
# axis = 1 时,删除含有空数据的一列数据
# 将any改为 all 时 时指当一行数据全部为nan的行删除
# 将false改为true就会更改原本的内容
a.fillna(a.mean()) # 将数组a中的空数据 用a中的有值数据的平均值填充
res = t.value_counts() # 得到一维数组中的每种数据的个数
pandas常用函数
# pandas读取文件
df=pd.read_excel("文件路径",header=None,nrows = 15,names=['A', 'B','C'])
# 读取excel文件,
# header=None 当excel文件中没有列名的时候使用,否则会将第一行数据设置为列名
# nrows 读取文件的行数
# name 设置列名
df=pd.read_csv("文件路径",sep="\t",header=None,,index_col='year')
# 读取csv和txt文件(格式和csv相同),
# seq="\t" # 将数据中 ‘,’分隔符换成\t # 主要使数据排列更美观
# 读取文件同时将year列作为索引
t = pd.Series([random.random()*100 for i in range(3)],index=["苹果","香蕉","葡萄"])
# 生成一维数据,同时指定index的值
data1 = df.set_index('year') # 将df中的year列设置为索引(此时的数组已经生成)
data=df.reset_index(drop=True) # 重置索引的同时删除原来的索引
# 数组取值
t.loc["苹果"] # 通过字段名来得到
data = df.iloc[1:7,[2,4]]
# 取df数据的中第二到第七行,中的第三列,第五列数据 (逗号前的是行数,逗号后是列数)
# :是使用切片的方法 ,列表中是具体取值
df = df.apply(lambda x: x.sum())
# apply函数,既能使用在Series 也能使用在 DataFrame,是数组中的每一个数据执行函数
df.info() # 展示df的数据的类型,个数,数据大小
df.describe() # 返回数组中的每一列的count,mean等值
df = df.groupby(by=['种类']).mean() # 将df中的数据按照‘种类’列分组,求每一组的平均值
data = df.sort_values(by=['列名1','列名2'],ascending=False,inplace=True)
# 没有设置inplace值就需要用变量接收
# 将数组中的数据先按照列名1排序,当列名1相同时按照列名2排序。
np.where(condition, x, y) # 满足condition, 输出x, 不满足,输出y
np.where(condition) # 只有条件 (condition),没有x和y,则输出满足条件 (即非0) 元素的坐标 ,
# 这里的坐标以tuple的形式给出,通常原数组有多少维,输出的tuple中就包 含几个数组,分别对应符合条
# 件元素的各维坐标。
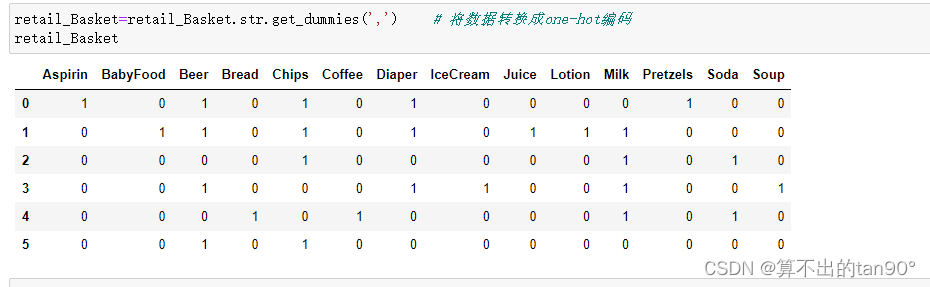
data = pd.get_dummies(df) # 将字符数据转换成one-hot数据
暂时把我所知道的常用函数都列举出来了,大家用得上的话可以拿去补充完整的参数。如果还有没有提到的函数,有空的话也可以发到评论区。
补充:
列中的数据为列表,将列表中的数据转换成one-hot编码
转换get_dummies编码的实例:
retail_shopping_basket={'ID':[1,2,3,4,5,6],
'Basket':[['Beer','Diaper',"Pretzels",'Chips','Aspirin'],
['Diaper','Beer','Chips','Lotion','Juice','BabyFood','Milk'],
['Soda',"Chips",'Milk'],
['Soup','Beer','Diaper','Milk','IceCream'],
['Soda','Coffee','Milk','Bread'],
["Beer",'Chips']
]
}
数据展示
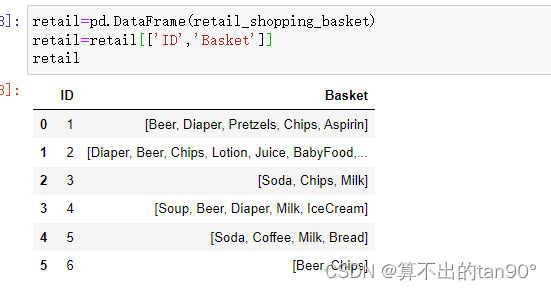
df["Baset"].str.join(",") # 将df的Basket列的字符串数据直接操作
















 4986
4986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









