







 本文详细介绍了Python中文件的基本操作,包括open()函数的各种模式、read()和write()方法,以及如何使用with语句安全地打开文件和os.walk函数遍历文件目录。
本文详细介绍了Python中文件的基本操作,包括open()函数的各种模式、read()和write()方法,以及如何使用with语句安全地打开文件和os.walk函数遍历文件目录。
文件基本操作
基本函数
open打开文件
open(name[, mode[, buffering]])
name : 一个包含了你要访问的文件名称的字符串值。
mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读®。
buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
这一个函数会返回一个文件的结构体
read/write读写
write()方法可以向文件中写入指定内容。writelines()方法可以将多行内容写入文件。(使用一个列表)
f = open("test.txt", "w")
f.write("Hello world")
- read() 函数:逐个字节或者字符读取文件中的内容;
- readline() 函数:逐行读取文件中的内容;
- readlines() 函数:一次性读取文件中多行内容。把所有的行放在一个列表里面
- 文件对象是可迭代的,因此我们可以使用
for循环逐行读取文件内容。 - 使用
with语句打开文件,可以确保在文件使用完毕后自动关闭文件,避免资源泄漏。
file.read([size])
size 作为一个可选参数,用于指定一次最多可读取的字符(字节)个数,如果省略,则默认一次性读取所有内容。
with open('example.txt', 'r') as file:
for line in file:
print(line)
with open('example.txt', 'r') as file:
content = file.read()
print(content) # 文件自动关闭
Python中with的用法_python中with用法-CSDN博客
with 语句实现原理建立在上下文管理器之上。
上下文管理器是一个实现 __enter__ 和 __exit__ 方法的类。
close关闭
f.close()
使用os.walk遍历文件
这一个可以遍历出来文件夹里面的所有文件以及文件夹
这一个函数的返回值是一个迭代器
这一个函数的walk参数是一个路径, 返回值是一个元组
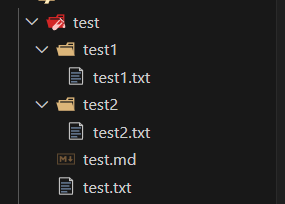
import os
for temp in os.walk("./test"):
print(temp)
PS E:\JHY\python\2024-4-22> python -u "e:\JHY\python\2024-4-22\main.py"
('./test', ['test1', 'test2'], ['test.md', 'test.txt'])
('./test\\test1', [], ['test1.txt'])
('./test\\test2', [], ['test2.txt'])
第一个参数是这一个文件夹的路径, 第二个参数是这一个文件夹里面的文件夹, 第三个数据是这一个文件夹里面的文件的名称
实际使用深度遍历, 把一个文件夹里面所有的文件遍历完以后出来遍历和他同一级的其他文件















 799
799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









