






简介
自然语言处理(Natural Language Processing,简称 NLP)是人工智能领域中的一个重要分支,主要研究如何使计算机能够理解、生成和处理人类自然语言。而语言转换就是如何将语言转换为模型可以直接识别的内容。
语言处理方法
一、统计语言模型
统计语言模型(Statistical Language Model)是一种用于计算自然语言中句子或词组出现概率的数学模型。它是自然语言处理(NLP)领域的基础技术之一,主要用于理解和生成自然语言。
1、简介
统计语言模型的核心思想是基于概率论来描述和预测自然语言中的词汇组合规律。也就是机器学习中的词向量转换方法。这种模型不依赖于复杂的语法规则,而是通过大量文本数据来统计词汇之间的共现关系,从而估计句子或词组的概率。
2、统计语言模型存在的问题
(1)、由于参数空间的爆炸式增长,它无法处理(N>3)的数据。
(2)、没有考虑词与词之间内在的联系性。例如,考虑"the cat is walking in the bedroom"这句话。如果我们在训练语料中看到了很多类似“the dog is walking in the bedroom”或是“the cat is running in the bedroom”这样的句子;那么,哪怕我们此前没有见过这句话"the cat is walking in the bedroom",也可以从“cat”和“dog”(“walking”和“running”)之间的相似性,推测出这句话的概率。
二、神经语言模型
1、简介
神经语言模型(Neural Language Model,NLM)是一种基于神经网络技术的语言模型,它利用深度学习来模拟自然语言的分布特性,捕捉词汇之间的关系,以更精确地估计自然语言中词序列出现的概率。
2、使用方法
(1)、one-hot编码
在处理自然语言时,通常将词语或者字做向量化。
例如:有一句待处理的句子为“好好学习天天向上”,在分词后进行one-hot操作如下:
“好好”:[0, 0, 0, 1]
“学习”:[0, 0 ,1, 0]
“天天”:[0, 1, 0, 0]
“向上”:[1, 0, 0, 0]
这种短数据处理起来看似很简洁,但现实中要处理的数据往往很大,加入一个语料库有10000个词还使用one-hot编码那么矩阵会非常稀疏,出现维度灾难。
(2)、词嵌入(emdedding)
对于在one-hot编码中产生的维度灾难,我们可以用词嵌入来解决。这种将高维度的词表示转换为低维度的词表示的方法,我们称之为词嵌入(word embedding)。
那么如何高维度的词表示转换为低维度的词呢?这就需要使用神经语言模型,常见的模型有:Word2Vec、GloVE、FastText等,这里我们使用Word2Vec模型。
(3)、Word2Vec模型

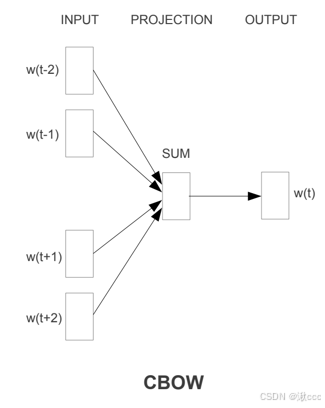
*CBOW
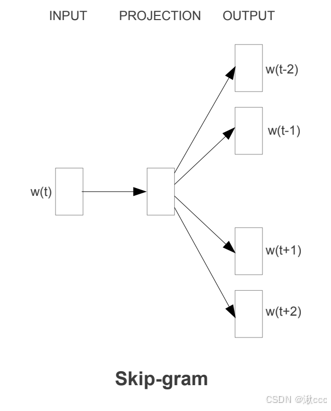
*Skip-Gram
(4)、模型的训练过程
a、当前词的上下文词语的one-hot编码输入到输入层。
b、这些词分别乘以同一个矩阵V*N后分别得到各自的1*N 向量。
c、将多个这些1*N 向量取平均为一个1*N 向量。
d、将这个1*N 向量乘矩阵 N*V ,变成一个1*V 向量。
e、将1*V 向量softmax归一化后输出取每个词的概率向量1*V。
f、将概率值最大的数对应的词作为预测词。
g、将预测的结果1*V 向量和真实标签1*V 向量(真实标签中的V个值中有一个是1,其他是0)计算误差
h、在每次前向传播之后反向传播误差,不断调整 V*N和 N*V矩阵的值。
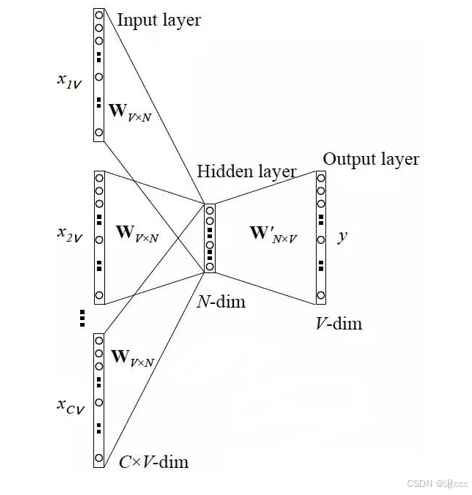
(5)、举例
假如一个语料库有10000个词,则词编码为10000个01组合 现在压缩为300维
以CBOW模型为例子
a、我们需要筛选出w(t-2)、w(t-1)、w(t+1)、w(t+2)四个词语来预测w(t)的词语。经过one-hot编码后得到了4*10000的矩阵。
b、将这个矩阵与10000*300的矩阵相乘,得到一个4*300的矩阵
c、在将得到的4*300矩阵的每一行相加求平局值就会得到一个1*300的矩阵
d、再将这个1*300的矩阵与300*10000的矩阵相乘得到了1*10000的矩阵,这个就是降维后的数据
那么10000*300和300*10000这两个矩阵中的值是如何得到的,这就是后面训练神经网络要得到权重值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









