







数据集链接,在评论区最底部
目录
实验一、基于经典机器学习的文本聚类
1,题目
一、任务背景
文本聚类主要是从杂乱的文本集合中发掘对用户有价值的信息,这些蕴含在文本集中的未被发现的信息能够更为合理地组织文本集合。文本聚类的主要思想是可以对无类别标示的文本文档集合进行分析,通过对文本特性的分析探索其应有的信息,再将集合中的文本按照特性分析的结果进行标识类别,发现文本内容中潜在的信息。文本聚类是对文本数据进行组织、过滤的有效手段,并广泛应用于主题发现、社团发现、网络舆情监测、网络信息内容安全监测等领域。传统的文本聚类方法使用 TF-IDF 技术对文本进行向量化,然后使用 KMeans 等聚类手段对文本进行聚类处理。文本向量化表示和聚类算法是提升文本聚类精度的重要环节,选择恰当的文本向量化表示和聚类算法成为文本聚类的关键问题。
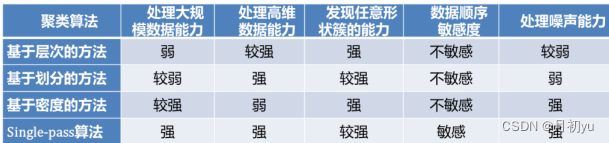
聚类算法是机器学习中的一种无监督学习算法,它不需要对数据进行标记,也不需要训练过程,通过数据内在的相似性将数据点划分为多个子集,每个子集也称为一个簇,对应着潜在的类别,而同一类别中的数据相似性较大,不同类别之间的数据相似性较小。聚类实质上就是将相似度高的样本聚为一类,并且希望同类样本之间的相似度高,不同类别之间的样本相似度低。不同聚类算法性能对比。
二、数据说明
数据来自新闻网站的新闻数据合集,选取 4 个类别标签,分别有体育、健康、教育、旅游、消费每个标签下分别有近 500 条新闻数据,部分信息如表所示。

三、分析目标
利用机器学习算法进行文本分类或聚类,一般包含数据准备、特征提取、模型选择与训练、模型评估及优化、误差分析、模型融合等步骤,具体介绍如下。
(1)数据准备
文本数据一般是非结构化的数据,这些数据或多或少会存在数据缺失、数据异常、数据格式不规范等情况,这时需要对其进行预处理,包括数据清洗、数据转换、数据标准化、缺失值和异常值处理等。
(2)特征提取
特征提取是文本分类前的步骤之一,它有几种经典的特征提取方法,分别是BOW 模型、TF、TF-IDF、n-gram 和 Word2Vec。BOW 模型拥有过大的特征维度,数据过于稀疏。TF 和 TF-IDF 运用统计的方法,将词汇的统计特征作为特征集,但效果与 BOW 模型相差不大。
(3)模型选择与训练
对处理好的数据进行分析,判断适合用于训练的模型。首先,判断数据是否属于监督学习,即数据中是否存在类标签,如果有那么归为监督学习问题,否则划分为无监督学习问题。在模型的训练过程中,通常会将数据划分为训练集和测试集,训练集用于训练模型,测试集则不参与训练,用于后续验证模型效果。
(4)模型测试
通过测试数据可以对模型进行验证,分析产生误差的原因,包括数据来源、特征、算法等。寻找在测试数据中的错误样本,发现特征或规律,从而找到提升算法性能、减少误差的方法。
(5)模型融合
模型融合是提升算法准确率的一种方法,当模型效果不太理想时,可以考虑使用模型融合的方式进行改善。单个机器学习算法的准确率不一定比多个模型集成的准确率高。模型融合是指同时训练多个模型,综合考虑不同模型的结果,再根据一定的方法集成模型,得到更好的结果。
四、分析方法与过程
4.1 数据读取通过获取文件列表信息,逐一读取数据,在获得文本内容的同时去除文本中的换行符制表符等特殊符号,最后对每个类别的新闻文本进行划分,80%的数据作为训练集,20%的数据作为测试集。
4.2 文本预处理通过对文本预处理,方便对训练集与测试集进行相关的文本处理。由于使用pandas 库的 read_csv 函数读取文件时默认将空格符去除,在加载停用词后会加上空格符号。读取数据中的每个新闻文本,并使用 jieba 库进行分词处理并去除停用词。本节划分了训练集与测试集,在数据处理时也要分别进行数据的预处理和后续的特征提取。
4.3 特征提取特征提取环节调用 CountVectorizer 函数将文本中的词语转换为词频矩阵,矩阵中的元素 a[i][j]表示 j 词在 i 类文本下的词频;调用 TfidfTransformer 函数计算TF-IDF 权值并转化为矩阵,矩阵中元素 w[i][j]表示 j 词在 i 类文本中的 TF-IDF权重。
4.4 聚类由于本节选取 4 分类,因此,选用 4 个中心点。随后进行模型的训练,调用fit 函数将数据输入到分类器中,训练完成后保存模型,并查看训练集的准确率分类情况。
4.5 模型评价输入测试数据进行模型训练,计算测试数据的准确率。依据度量指标选择最优聚类模型。ARI 评价法(兰德系数)、AMI 评价法(互信息)、V-measure 评分。
2,代码
import jieba
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.metrics import adjusted_rand_score
from sklearn.metrics import adjusted_mutual_info_score
from sklearn.metrics import v_measure_score
#1,读数据
data_path=r"C:\Users\yu\Desktop\课设\NLP课设\实验\实验1\数据集\news.csv"
stopword_path=r"C:\Users\yu\Desktop\课设\NLP课设\实验\实验1\数据集\stopword.txt"
#加载数据
df=pd.read_csv(data_path,header=None,names=["content","label"])
#2,文本预处理
#2.1加载停用词,用gbk编码
with open(stopword_path,"r",encoding="gbk") as f:
stopword=set(f.read().splitlines())
#2.2定义数据预处理函数
def deal_data(text):
#jieba分词
word=jieba.cut(text)
#去除停用词
word=[i for i in word if i not in stopword]#过滤停用词
return " ".join(word)
#2.3数据预处理
df["content"]=df["content"].apply(deal_data)
#2.4划分训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(df["content"],df["label"],test_size=0.2,random_state=40)
#3,将文本转换为TF-IDF特征向量
vectorizer=TfidfVectorizer(max_df=0.85,min_df=3,ngram_range=(1,2))
#max_df常用词
#min_df罕见词
#ngram_range连续词
x_train_tfidf=vectorizer.fit_transform(x_train)
x_test_tfidf=vectorizer.transform(x_test)
#4,建聚类模型
num_cluster=4
kmeans=KMeans(n_clusters=num_cluster,random_state=40,n_init=30,max_iter=500,tol=1e-5)
#n_clusters:聚类的数量
#n_init:运行次数
#max_iter:最大迭代次数
#tol:容忍度,用于判断是否已经收敛
kmeans.fit(x_train_tfidf)
#5,模型评价
#5.1预测测试集类别
y_pred=kmeans.predict(x_test_tfidf)
#5.2三种评价指标
ARI=adjusted_rand_score(y_test,y_pred)
AMI=adjusted_mutual_info_score(y_test,y_pred)
v=v_measure_score(y_test,y_pred)
print("模型评价如下")
print(f"ARI评价法={ARI}")
print(f"AMI评价法={AMI}")
print(f"V-measure评分={v}")3,运行结果

实验二、基于经典机器学习的文本分类
1,题目
一、任务背景
随着经济的不断发展以及互联网技术的稳步提升,各种各样的新闻平台应运而生(如人民网、新华网、环球网、中国新闻网等),人们获取新闻的方式逐渐多样化,由传统的纸质、广播渠道增广到如今的网络化新闻展示,新闻的呈现形式已然在大众群体中越来越多样化及便捷化。
目前很多新闻的发布都附带其分类好的类别范畴,这就利于人们在阅读的时候,能够快速的悉知一篇新闻的主题方向,同时也便于时间、内容方面的效率提升,信息化服务也就更为快捷与方便。
本案例使用人民网科技类别下的前 8 个栏目下的部分新闻数据,结合支持向量机分类模型,并对模型进行评价,从而将栏目下的每篇新闻内容其所属的类型进行更为精细化的划分。
二、数据说明
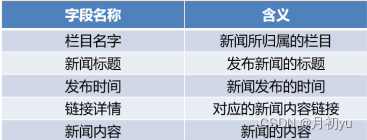
该案例选取的是人民网科技类别的前 8 个栏目下的部分新闻数据,本次读取了 2020 年 1 月 15 日至 2021 年 1 月 10 日共 2992 条发布的新闻数据。人民网科技新闻信息数据(保存在人民网科技新闻数据.xlsx 文件中)属性说明如表所示。
三、分析目标
如何将新闻内容所表达的主体方向准确、有效的进行分类,从而提升用户阅读新闻的体验感与效率,是广大新闻发布平台及用户所共同期待的。本案例根据新闻文本分类项目的业务需求,即需要实现的目标如下。
(1)对滚动与独家栏目下的每一条新闻内容进行详细的分类。
(2)评估该分类情况的优劣,并提出更好的分类改进建议。
新闻文本分类的主要步骤
(1)分析各栏目下新闻之间的相似度、新闻发布量,对数据进行探索。
(2)对文本进行基础处理、向量化等预处理操作。
(3)构建分类模型,对滚动与独家栏目进行分类。
(4)根据构建后的模型结果进行模型评价。
(5)根据分类模型得到的滚动与独家下的新闻分类结果提出更好的改进建议。
四、分析方法与过程
数据概况
4.1 数据探索
为进一步对数据进行分析,查看数据中各字段所反映出的具体情况,需要对整体数据进行数据清洗及可视化展示。其中,包括删除数据中的重复、缺失等噪声数据,再调用预先自定义计算相似度的函数,计算出滚动和原创栏目与剩余 5个栏目之间的新闻内容相似度,分析各栏目新闻的总发布量情况和月份新闻发布量趋势等。
(1)数据清洗
对数据进行清洗,包括对数据中的重复值、缺失值(有缺失值的行全部删除)和干扰内容(\n,\t,\xa0 等转移字符全部删除)等进行去除,减弱不必要的信息干扰,同时也便于后续对数据进行更为深入的探索。
(2)可视化展示
将经清洗过后的数据进行可视化展示,包括查看滚动与独家和其它 6 个栏目的新闻内容之间的相似度、查看各栏目新闻总发布量、查看各栏目的月份新闻发布量趋势。通过可视化的展现,从而更直观的挖掘出数据的额外信息,便于开展更为准确、合理的分析。
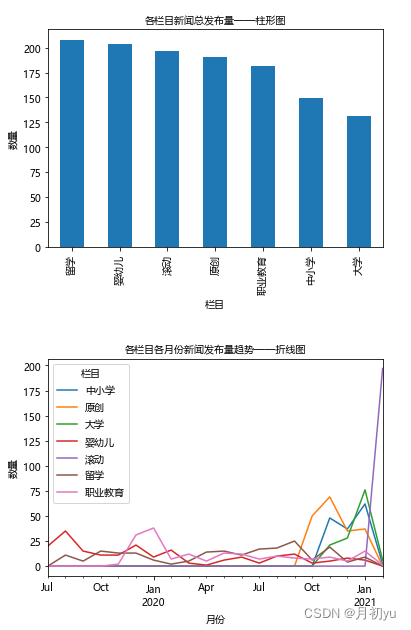
绘为查看进行数据清洗之后各栏目的新闻发布数量的详细情况,从而把握数据的实际情况以便于分析,需要绘制各个栏目新闻发布量柱状图,制各栏目新闻总发布量柱形图,如图所示。
由图可知,滚动与独家栏目的发布数量较高,尤其是滚动栏目,其新闻发布数量为 343 个,而其它的 6 个栏目的发布数量则相对均衡的分布在 190 上下,6个栏目间并无太大差异。
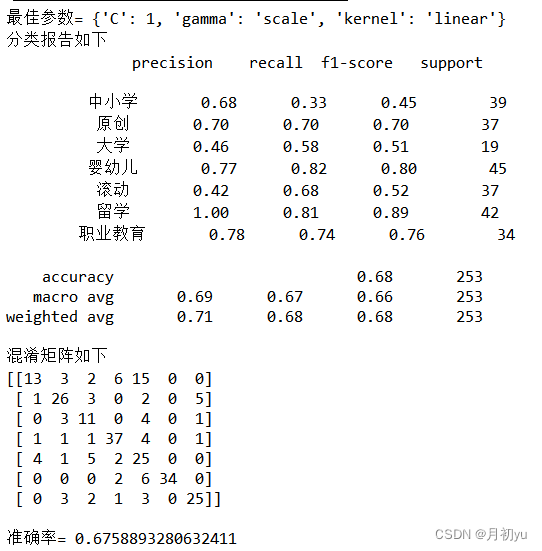
为更进一步观察滚动、独家和产业创新、医学·健康、发明·创新、探索·发现、科学界、航空·航天这 8 个栏目的新闻发布数量变化趋势,可对各栏目各月份具体的新闻发布数量进行观察,绘制各栏目各月份折线图,如左图和右图所示。由左图可知,独家栏目的发布数量较为平均,都在 40 个左右,时长为 6 个月;滚动栏目的发布数量从开始便达到了发布数量的峰值 258,但之后便急剧下降至 85,时长为 2 个月。
由右图可知,各栏目的新闻发布数量波动较大主要位于 2020 年 6 月至 2020年 10 月之间,且在这几个月间,绝大部分栏目的新闻发布数量都达到了对应的高峰值,而其它月份各栏目的新闻发布数量则相对较低。
4.2 文本预处理
在自然语言中,需要对语料库进行基本处理,常见的语料库处理包括去除数据中非文本部分、中文分词、去停用词等,而经过处理过后的语料库基本上是干净的文本了,但无法直接用于后续文本的计算和模型的构建等,因此还需要将文本进行向量化处理,从而便于后续的案例开展。
4.2.1 文本基础处理
对文本进行基础处理,包括了对数据进行结巴分词、去停用词((包含空格)、去分词结果中的段落符(('\u3000')进行处理等操作。为查看当前处理后文本集中的新闻文本所出现的高频词,可通过绘制词云图和排名前 10 的词语词频饼图进行分析。
由图可知,在训练集中的新闻文本中所表现较多的高频词主要有发展、研究、中国、创新、技术和科技等词。(背景图在下载数据中)
4.2.1 文本向量化
对经过文本基础处理的新闻文本使用预训练好的 192 维的语料库模型构建词向量,目的是使将词语转换成机器所能识别的形态,从而便于模型的实际运用。对文本构建词向量矩阵,需要通过调用预先训练好的语料库模型,生成每篇新闻中的每个分词的词向量,再通过将词向量进行求和的方式从而得出该篇新闻文本的最终 1×192 维词向量矩阵(Gensim 模块实现)。
4.3 模型构建与选择
在选定 SVM、K 近邻、随机森林分类模型的条件下,利用交叉验证的方式选择模型最优的参数,筛选最优分类模型。




2,代码
import pandas as pd
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_extraction.text import TfidfVectorizer
from matplotlib.font_manager import FontProperties
import warnings
#0,小细节处理
#0.1解决字体缺失问题
font_path=r"C:\Windows\Fonts\msyh.ttc"
font_prop=FontProperties(fname=font_path)
plt.rcParams["font.sans-serif"]=["Microsoft YaHei"]#指定默认字体
plt.rcParams["axes.unicode_minus"]=False#解决保存图像时负号'-'显示为方块的问题
#0.2忽略sklearn的UndefinedMetricWarning
warnings.filterwarnings("ignore", category=UserWarning, module="sklearn")
warnings.filterwarnings("ignore", category=RuntimeWarning, module="sklearn.metrics")
#1,数据加载
path=r"C:\Users\yu\Desktop\课设\NLP课设\实验\实验2\数据集\新闻分类数据\教育新闻数据.xlsx"
data=pd.read_excel(path)
#2,数据清洗
data.dropna(inplace=True)#删除缺失值
data.drop_duplicates(inplace=True)#删除重复值
#删除干扰内容
data["新闻内容"]=data["新闻内容"].str.replace("\n", "")
data["新闻内容"]=data["新闻内容"].str.replace("\t", "")
data["新闻内容"]=data["新闻内容"].str.replace("\xa0", "")
#3,分析与可视化
#3.1查看各栏目新闻总发布量——柱形图
breed_count=data["栏目名称"].value_counts()
plt.figure()
breed_count.plot(kind="bar")
plt.title("各栏目新闻总发布量——柱形图", fontproperties=font_prop)
plt.xlabel("栏目", fontproperties=font_prop)
plt.ylabel("数量", fontproperties=font_prop)
plt.xticks(fontproperties=font_prop)
plt.show()
#3.2查看各栏目的月份新闻发布量趋势——折线图
data["发布时间"]=pd.to_datetime(data["发布时间"])
data["月份"]=data["发布时间"].dt.to_period("M")
monthly_trend=data.groupby(["栏目名称", "月份"]).size().unstack().T.fillna(0)
monthly_trend.plot()
plt.title("各栏目各月份新闻发布量趋势——折线图", fontproperties=font_prop)
plt.xlabel("月份", fontproperties=font_prop)
plt.ylabel("数量", fontproperties=font_prop)
plt.legend(title="栏目", prop=font_prop)
plt.xticks(fontproperties=font_prop)
plt.show()
#4,文本预处理
#4.1加载停用词
stopword_path=r"C:\Users\yu\Desktop\课设\NLP课设\实验\实验2\数据集\新闻分类数据\stopword.txt"
with open(stopword_path, "r", encoding="utf-8") as f:
stopword=set(f.read().split())
#4.2定义数据预处理函数
def deal_data(text):
#jieba 分词
word=jieba.cut(text)
#去除停用词
word=[i for i in word if i not in stopword]
return " ".join(word)
data["新闻内容_处理之后"]=data["新闻内容"].apply(deal_data)
#4.3生成词云图
text=" ".join(data["新闻内容_处理之后"])
cloud=WordCloud(font_path=font_path).generate(text)
plt.figure()
plt.imshow(cloud)
plt.axis("off")
plt.show()
#5,文本向量化(使用TF-IDF)
vectorizer=TfidfVectorizer(max_features=5000)
x=vectorizer.fit_transform(data["新闻内容_处理之后"]).toarray()
y=data["栏目名称"]
#6,构建分类模型
le=LabelEncoder()
y_encoded=le.fit_transform(y)
x_train, x_test, y_train, y_test=train_test_split(x, y_encoded, test_size=0.2, random_state=40)
#使用支持向量机
param_grid={"C": [0.1, 1, 10], "gamma": ["scale", "auto"], "kernel": ["linear", "rbf"]}
svc=SVC()
grid_search=GridSearchCV(svc, param_grid, cv=5, scoring="accuracy")
grid_search.fit(x_train, y_train)
#7,模型评估
model=grid_search.best_estimator_
y_pred=model.predict(x_test)
print("最佳参数=", grid_search.best_params_)
print("分类报告如下")
print(classification_report(y_test, y_pred, target_names=le.classes_))
print("混淆矩阵如下")
print(confusion_matrix(y_test, y_pred), "\n")
print("准确率=", accuracy_score(y_test, y_pred))3,运行结果

实验三、基于深度学习的文本情感分析
1,题目
一、案例介绍
天问一号是由中国空间技术研究院研制的探测器,负责执行中国第一次自主火星探测的任务。结合当前开放式的网络环境,对天问一号事件中bilibili网站用户所发表的观点和评论等文本数据进行收集整理,并进行评论文本的情感分析,可以直观地体现网络用户对于天问一号成功登陆火星事件的情感倾向。对于了解网络用户对于中国航天事业发展的认知度与认可度,有着一定的参考价值与可观之处。
二、数据说明
从“天问一号成功着陆火星”事件入手,爬取了天问一号发射与登陆火星前后的bilibili相关视频下的用户评论,组成评论数据csv文件,爬取的内容包括用户名、点赞数、评论内容、视频网址等。评论数据的时间窗口从2020年4月24日至2021年7月7日,共爬取了10380条数据。根据提供的评论数据,结合舆论分析的场景,对用户针对天问一号事件的情感表现进行分类,分类标签分为-1(表示负面评论)、0(表示中性评论)以及1(表示正面评论)。
正面评论表达了 bilibili 网站用户对天问一号成功登陆火星的喜悦之感,同时表现出对中国航天事业的殷切期望与祝愿,对中国航天事业充满期待。负面评论表达了部分网络用户对于天问一号成功登陆火星的不以为然,又或是对于视频形式、背景音乐等的反感。中性评论则是网络用户对于该事件的客观评价与分析,既不过分吹嘘他国实力也不贬低自身国家成就,或者是表达自己对于太空宇宙的想象,又或是提出自身的疑问、建议等,没有明显或直接表现出自身的态度立场。
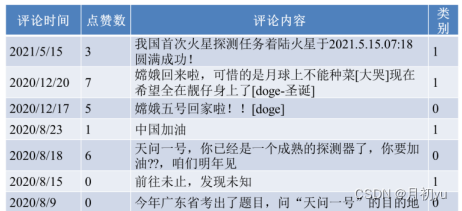
“天问一号成功着陆火星” bilibili 相关视频部分评论信息如下表。
三、分析目标
《天问一号成功着陆火星》案例——步骤
①数据探索:通过可视化的方法分析不同情感类型的评论数量分布、每月评论量的变化和获赞数前 10 的评论的获赞数
②文本预处理:对抽取到的数据进行清洗、特殊字符处理、中文分词、停用词过滤和词云图分析
③构建模型与训练:将分词结果进行特征向量化,将数据集划分成训练集和测试集,并构建朴素贝叶斯模型进行分类
④模型评估:通过混淆矩阵、准确率、精确率等评价指标对模型分类效果进行评价
四、分析方法与过程
自从天问一号成功发射,中国航天工程话题再度迎来了热议,关于天问一号发射以及登陆火星前后的相关新闻、视频与评论也层出不穷。本次建模针对的是天问一号事件中bilibii网站出现的相关视频下的评论,本节将对评论数据进行数据探索,对文本进行基本的预处理(包括中文分词、去停用词等)并通过词云图查看预处理效果,然后进行特征向量化,最后构建朴素贝叶斯模型并通过混淆矩阵、准确率、精确率等评价指标对模型分类效果进行评估,并根据模型评估结果对模型进行优化。
4.1 数据探索
为了解本案例使用的数据的基本特征,将从不同情感类型评论的数量分布、2020年4月24日至2021年7月7日期间每个月的评论数量以及获赞数排名前10的评论这3个方面对案例数据进行探索分析。
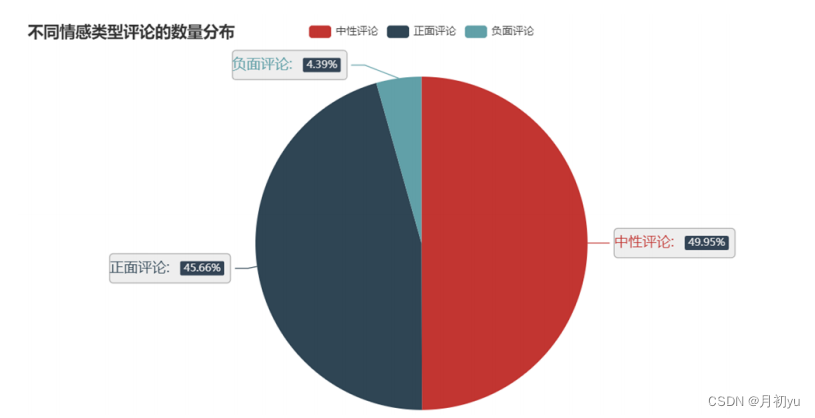
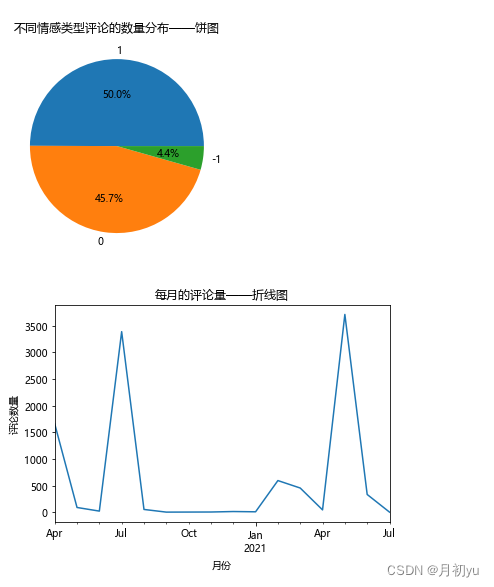
4.1.1 不同情感类型评论的数量分布
案例中使用的数据是从bilibili爬取的有关天问一号成功登陆火星事件的相关视频下的评论数据,格式为csv文件。使用pandas库中的read_csv函数读取数据集,对特征“类别”中的不同类型进行计数并进行计数。然后使用Matplotlib库pyplot模块中的pie函数绘制不同评论类型的数量分布饼图。
从图中可以看出,在所有的评论数据中,中性评论占比49.95%,正面评论占比45.66%,负面评论占比4.39%。正面评论占比远远高于负面评论,说明大部分的用户并没有对天问一号持有消极观念,并对中国的航天事业抱有期望。同时也有相当一部分的网友持中立观点,并对天问一号事件发表了自己的看法和建议。总体来看,bilibili用户对天问一号倾向于积极支持的态度。
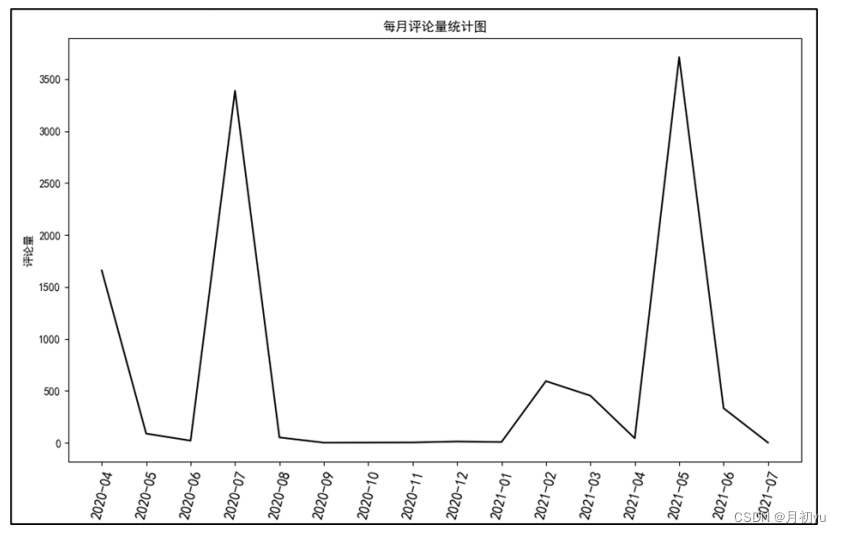
4.1.2 每月的评论量
为查看2020年4月24日至2021年7月7日间每个月的用户评论量情况。首先需要统计所涉及的时间范围,并删除时间不是2020-2021年的数据。然后使用groupby函数和sum函数对“评论时间”列进行分组统计评论量,最后使用plot函数绘制折线图。
通过折线图可以看出,根据事件发展及评论量随时间的变化趋势,将用户评论时间分为5个阶段,分别为初始期,爆发期、骤减期、再次爆发期和平稳期。
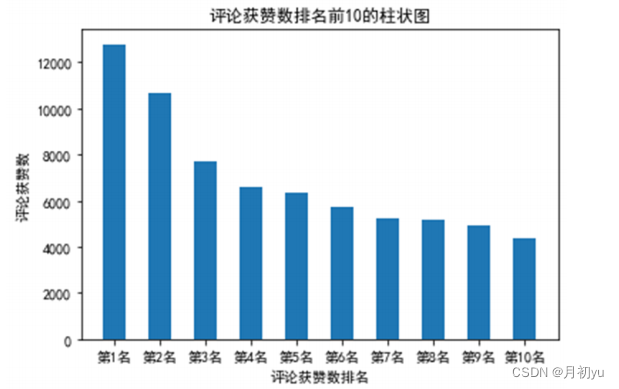
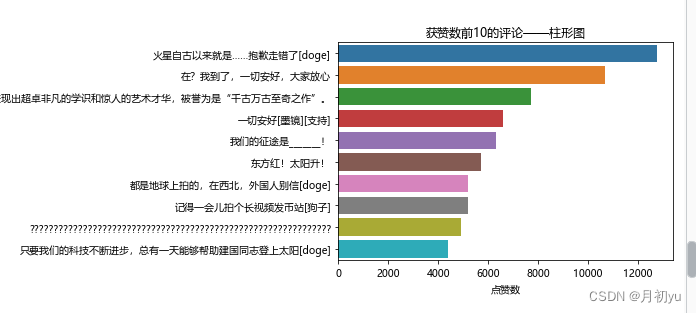
4.1.3 获赞数前10的评论
数据集中有个特征为点赞数,点赞是指其他用户同意该用户的评论观点,点赞数则是点赞这个行为的数量,点赞数越多意味着持有相同观点的人越多。为了解2020年4月24日至2021年7月7日间天问一号发射与登陆前后相关视频下bilibili用户文本评论中哪些评论获得的点赞数最多,即哪条评论的获赞数最多,以特征点赞数进行排序,并取其中排名前10的评论绘制柱状图。
从图中可以看出,排名第1与第2的评论获赞数均超出了一万。排名第3的评论为“(天天问是是中国国国时期人人原原创作的一首长人。除前3名外,第4名至第10名的获赞数相差不大。
4.2 文本预处理
在数据爬取过程中会产生部分内容缺失、内容重复和价值含量很低甚至没有价值的文本数据,如果将这部分数据引入分词、词频统计和模型训练等操作中,会影响后续的建模分析。同时,评论文本数据是由字符和字符串构成的短文本或长文本,与标准的数值型数据不同,不能对其进行常用的逻辑运算和统计计算。因此,为了处理起来更加方便,在进行统计分析和建模之前,需要对数据进行文本预处理,包括数据清洗、特殊字符处理、中文分词、去停用词等。
本案例主要从数据清洗、特殊字符处理、中文分词、去停用词对数据进行文本预处理。
4.2.1 数据清洗
数据清洗的主要目的是考虑业务和模型的相关需求,筛选出需要的数据。有些bilibii网站用户如果对某个评论持有相同看法,会出现直接复制该评论进行发表的现象,这会导致出现不同bilibili网站用户之间的评论内容完全重复的现象,如果不处理重复的评论直接进行建模会影响分析的效率。因此,需要对重复的评论进行去重,保留一条即可。同时还可能会存在部分评论相似程度极高的情况,这类评论只在某些词语的运用上存在差异,虽然此类评论也可归为重复评论,但若是删除文字相近评论,则可能会出现误删的情况,而且文字相近的评论也可能存在不少有用的信息,去除这类评论显然不合适。
因此,为了存留更多的有用评论,应只针对完全重复的评论进行去重,仅删除完全重复部分,以确保尽可能保留有用的评论文本信息。对评论数据进行去重以降低数据处理和建模过程的复杂度。(提示:pandas.drop_duplicates()函数)
4.2.2 特殊字符处理
经过观察数据,可发现数据中存在空格、制表符、字母等特殊字符,它们对于模型的建模分析是无意义的,因此,在数据处理前需要将这类特殊字符处理干净。对文本数据中的特殊字符进行处理,如代码如下所示。
import pandas as pd import re df_clean = df.copy() # 数据框复制 # 将遍历到的非文字、数字、转义符、天问一号、天问、胖 5 替换成空 df_clean[' 评 论 内 容 '] = df[' 评 论 内 容 '].astype('str').apply(lambda x:re.sub('[^\u4E00-\u9FD5]|[0-9]|\\s|\\t|天问一号|天问 1 号|天问|胖 5|时分', '', x)) # astype()函数可用于转化 content 的数据类型为 str # apply 遍历每个值,与 lambda 表达式相结合 # re.sub 替换所有的匹配项,返回一个替换后的字符串,如果匹配失败,返回原字符串
4.2.3 中文分词
利用jieba库对评论内容进行分词
4.2.4 去停用词
在Python中通常使用停用词表进行去停用词,常用的停用词表包括四川大学机器智能实验室停用词库、哈尔滨工业大学停用词表、中文停用词表和百度停用词表等。本案例采用哈尔滨工业大学停用词表stopwordsHIT.txt进行去停用词处理,将每一条评论中出现在停用词表中的词去掉。
4.2.5 去除空值数据
删除列“评论内容”、“评论时间”、“点赞数”中为空的数据,注意不要删除“点赞数”为0的数据。
4.3 模型构建
80%数据作为训练集,剩余20%数据作为测试集。
对预处理后的文本利用Gensim模块中Word2vec算法获得词向量,从TextCNN算法、TextRNN算法(RNN层后添加一个线性层)和TextLSTM算法(LSTM层后添加一个线性层)中选择最优模型。
2,代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import jieba
from gensim.models import Word2Vec
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix,classification_report,accuracy_score
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding,Conv1D,MaxPooling1D,Flatten,Dense,SimpleRNN,LSTM
from matplotlib.font_manager import FontProperties
import warnings
#0,细节处理
#解决字体缺失问题
font_path=r"C:\Windows\Fonts\msyh.ttc"
font_prop=FontProperties(fname=font_path)
plt.rcParams["font.sans-serif"]=["Microsoft YaHei"]#设置默认字体为微软雅黑
plt.rcParams["axes.unicode_minus"]=False#解决负号显示问题
#1,读数据
data_path=r"C:\Users\yu\Desktop\课设\NLP课设\实验\实验3\数据集\基于深度学习的文本情感分析\BiliBiliComments.csv"
data=pd.read_csv(data_path)
#2,分析与可视化
#2.1不同情感类型评论的数量分布——饼图
sentiment_counts=data["类别"].value_counts()#统计不同类别的评论数量
plt.figure()
plt.pie(sentiment_counts,labels=sentiment_counts.index,autopct="%.1f%%")
plt.title("不同情感类型评论的数量分布——饼图")
plt.show()
#2.2每月的评论量——折线图
data["评论时间"]=pd.to_datetime(data["评论时间"],errors="coerce")#将评论时间转换为datetime格式
data=data.dropna(subset=["评论时间"])#删除评论时间为空的行
data=data[(data["评论时间"]>="2020-04-24") & (data["评论时间"]<="2021-07-07")]#筛选特定数据
data["评论月份"]=data["评论时间"].dt.to_period("M")#提取评论月份
monthly_comments=data.groupby("评论月份").size()#按月份统计评论数量
plt.figure()
monthly_comments.plot(kind="line")
plt.title("每月的评论量——折线图")
plt.xlabel("月份")
plt.ylabel("评论数量")
plt.show()
#2.3获赞数前10的评论——柱形图
data["点赞数"]=pd.to_numeric(data["点赞数"],errors="coerce")#将点赞数列转换为数值类型
top10_comments=data.nlargest(10,"点赞数")#获取点赞数前10的评论
plt.figure()
sns.barplot(x="点赞数",y="评论内容",data=top10_comments)
plt.title("获赞数前10的评论——柱形图")
plt.show()
#3,文本预处理
#预处理函数
def deal_data(data,stop_words_path):
#3.1数据清洗:删除重复评论内容
data.drop_duplicates(subset=["评论内容"],inplace=True)
#3.2特殊字符处理:移除非中文字符
data["评论内容"]=data["评论内容"].str.replace(r"[^\u4e00-\u9fa5]","",regex=True)
#3.3中文分词
data["分词"]=data["评论内容"].apply(lambda x: " ".join(jieba.cut(x)))
#3.4去停用词
with open(stop_words_path,"r",encoding="utf-8") as f:
stop_words=f.read().splitlines()
data["分词"]=data["分词"].apply(lambda x: " ".join([word for word in x.split() if word not in stop_words]))
#3.5去除空值数据
data.dropna(subset=["评论内容","评论时间","点赞数"],inplace=True)
return data
stop_words_path=r"C:\Users\yu\Desktop\课设\NLP课设\实验\实验3\数据集\基于深度学习的文本情感分析\stopwordsHIT.txt"
data=deal_data(data,stop_words_path)
#4,模型构建与训练
x=data["分词"]#分词后的评论内容
y=data["类别"]#评论类别
#5,文本向量化
#5.1用Word2Vec训练词向量
sentences=[text.split() for text in x]#将分词后的评论内容转为列表形式
w2v_model=Word2Vec(sentences,vector_size=100,window=5,min_count=1,workers=4)#训练Word2Vec模型
w2v_model.save("word2vec.model")#保存模型
#5.2将评论转化为词向量
tokenizer=Tokenizer()
tokenizer.fit_on_texts(x)#使用评论内容训练Tokenizer
x_seq=tokenizer.texts_to_sequences(x)#将文本转化为序列
x_pad=pad_sequences(x_seq,maxlen=100)#使用pad_sequences对序列进行填充
x_train,x_test,y_train,y_test=train_test_split(x_pad,y,test_size=0.2,random_state=42)
#6,建模
#TextCNN模型
def create_textcnn_model():
model=Sequential()
model.add(Embedding(input_dim=len(tokenizer.word_index) + 1,output_dim=100,input_length=100))#添加嵌入层
model.add(Conv1D(128,5,activation="relu"))#添加卷积层
model.add(MaxPooling1D(5))#添加最大池化层
model.add(Flatten())#添加展平层
model.add(Dense(128,activation="relu"))#添加全连接层
model.add(Dense(1,activation="sigmoid"))#添加输出层
model.compile(optimizer="adam",loss="binary_crossentropy",metrics=["accuracy"])#编译模型
return model
#TextRNN模型
def create_textrnn_model():
model=Sequential()
model.add(Embedding(input_dim=len(tokenizer.word_index) + 1,output_dim=100,input_length=100))#添加嵌入层
model.add(SimpleRNN(128))#添加SimpleRNN层
model.add(Dense(128,activation="relu"))#添加全连接层
model.add(Dense(1,activation="sigmoid"))#添加输出层
model.compile(optimizer="adam",loss="binary_crossentropy",metrics=["accuracy"])#编译模型
return model
#TextLSTM模型
def create_textlstm_model():
model=Sequential()
model.add(Embedding(input_dim=len(tokenizer.word_index) + 1,output_dim=100,input_length=100))#添加嵌入层
model.add(LSTM(128))#添加LSTM层
model.add(Dense(128,activation="relu"))#添加全连接层
model.add(Dense(1,activation="sigmoid"))#添加输出层
model.compile(optimizer="adam",loss="binary_crossentropy",metrics=["accuracy"])#编译模型
return model
#7,训练和评估模型
#7.1定义模型字典
models={"TextCNN": create_textcnn_model(),"TextRNN": create_textrnn_model(),"TextLSTM": create_textlstm_model()}
results={}#存储结果的字典
#7.2忽略警告
warnings.filterwarnings("ignore")
#7.3训练模型
for model_name,model in models.items():
print()
print(f"训练模型——{model_name}")
model.fit(x_train,y_train,epochs=5,batch_size=32,validation_split=0.2,verbose=1)#训练模型
y_pred=(model.predict(x_test) > 0.5).astype("int32")#预测
accuracy=accuracy_score(y_test,y_pred)#算准确率
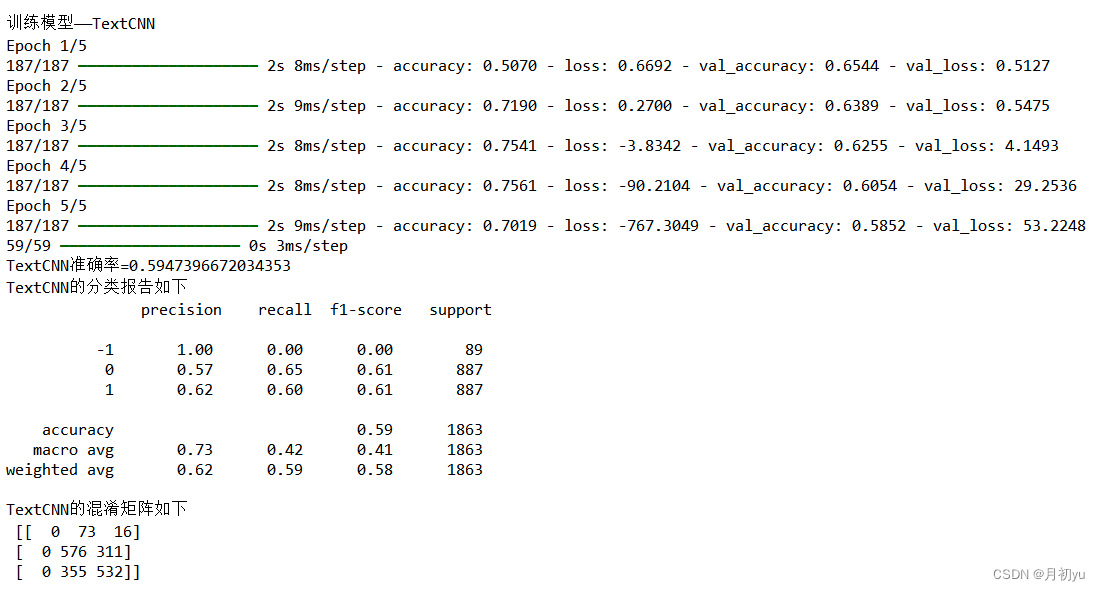
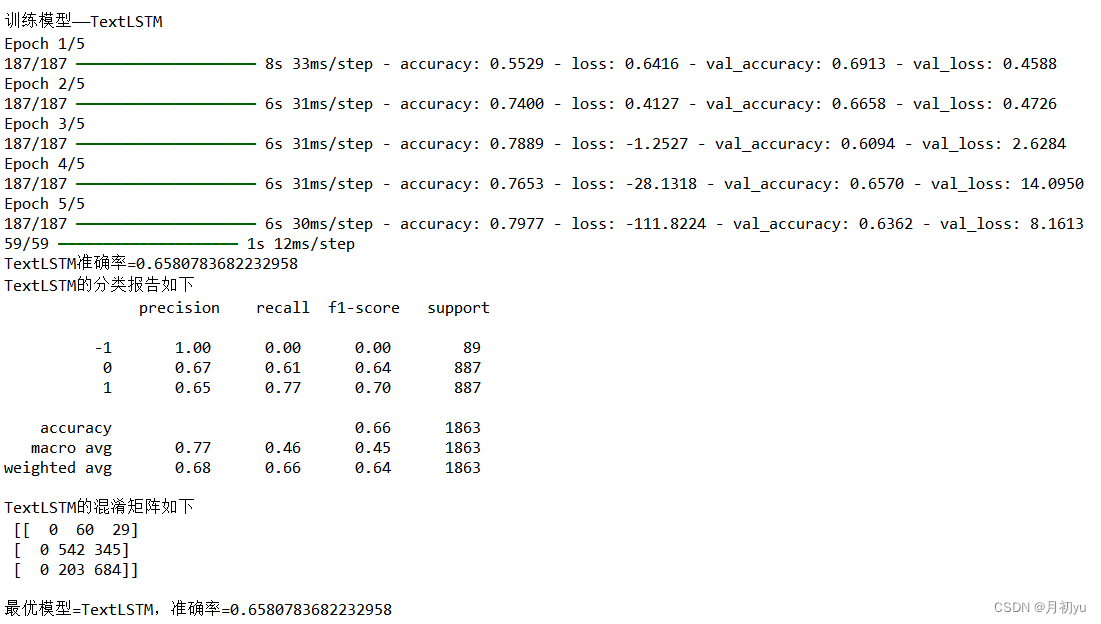
print(f"{model_name}准确率={accuracy}")
results[model_name]=accuracy
#打印分类报告和混淆矩阵
print(f"{model_name}的分类报告如下\n",classification_report(y_test,y_pred,zero_division=1))
print(f"{model_name}的混淆矩阵如下\n",confusion_matrix(y_test,y_pred))
print()
#8,打印最优模型
best_model=max(results,key=results.get)
print(f"最优模型={best_model},准确率={results[best_model]}")3,运行结果

实验四、基于浏览记录的个性化新闻推荐
1,题目
一、任务背景
个性化新闻推荐指基于用户的单击历史,分析用户的兴趣偏好,预测用户未来的新闻单击概率,指导展现给用户的新闻排序,为用户实现感兴趣信息的私人定制,并根据实时需求为用户提供个性化服务。个性化新闻推荐给新闻与传播领域带来了前所未有的变革。
个性化新闻推荐系统(Personalized News Recommender System)是一种备受学界和业界关注的新型新闻分发方式,其所依托的推荐系统技术基于计算机技术和统计学知识,将数据、算法、人机交互有机结合,建立用户和资源的个性化关联机制,在信息过载时代,为用户的消费和信息摄取提供决策支持。个性化新闻推荐系统对推荐给用户的新闻进行判断与选择,代替了编辑的重复劳动,从而使信息产业的生产效率得以提高,促进新闻产业向更加精深的方向发展。
二、数据说明
本案例使用的数据为某新闻网站的新闻浏览记录,包括用户编号、新闻编号以及相关的新闻发布时间、标题和文本内容,其中用户编号已做了匿名化处理。新闻发布时间窗口为 2021 年 6 月 16 日至 2021 年 7 月 18 日,获取的新闻浏览记录数据共 279908 条。每一行代表一条浏览记录,共有如下 5 个特征,其中用户编号和新闻编号是唯一的,如下图所示。

三、分析目标
1. 本案例的分析目标
1) 基于新闻内容,分析不同类型新闻的发布量和浏览量,以及不同用户查看新闻数量的分布
2) 总结用户浏览新闻的行为特征,实现用户的新闻个性化推荐。
2. 总体流程
1) 数据抽取:读取用户浏览新闻的历史记录
2) 数据探索:对新闻类型进行探索分析,对不同类型新闻的浏览记录进行初步分析
3) 数据预处理:删除异常数据并对数据进行去重
4) 模型构建与训练:划分数据集为训练集和测试集,并根据训练集构建和训练基于新闻内容的协同过滤智能推荐模型
5) 模型评估:对模型的推荐效果进行评价,对推荐结果进行总结和分析
四、分析方法与过程
针对一段时期内用户访问网络新闻的浏览记录进行数据探索分析,分析不同类型新闻的分布和浏览量,以及用户查看新闻的数量;再对数据进行基本的预处理,并通过构建基于物品的协同过滤模型,计算新闻 A 和新闻 B 之间的相似度;最后基于相似度矩阵向目标用户推荐与其喜欢的新闻相似度高的其他新闻。
4.1 数据探索
通过观察表 7-1 可以发现原始数据中存在新闻标题(news title)有文本内容,但新闻详细内容(news all)为“nan”的新闻。经向相关人员求证,此类新闻可能为视频或全图式的新闻。除此之外,对原始数据主要为新闻内容的新闻进行统计分析,发现部分新闻的文本内容偏短。经向相关人员求证,此类新闻属于图形与文字相结合的新闻或者短篇新闻。一般而言,短篇新闻的篇幅小于 200 字。
为了了解本案例使用的数据的基本特征,针对一段时期内用户访问网络新闻的浏览记录进行数据探索分析,分析不同类型新闻的数量分布和浏览数量分布。
1.1 不同类型新闻的发布量
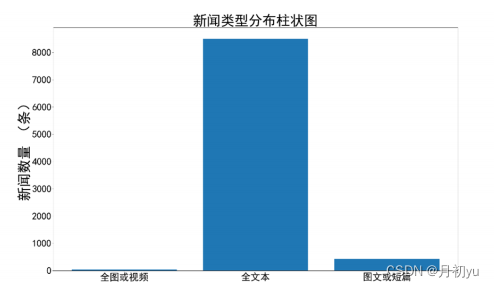
使用 pandas 库中的 read_csv 数读取数据集,对数据中的新闻类型进行识别,然后对全图或视频新闻、图文或短篇新闻和全文本类新闻这 3 类新闻的分布进行比较,并绘制柱状图。
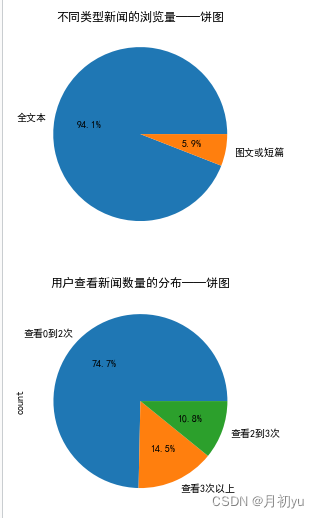
1.2 不同类型新闻的浏览量
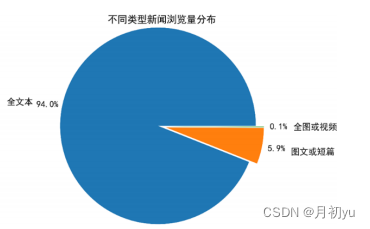
为更好地了解不同类型新闻的浏览数量的分布,在不同新闻类型的数量分布图的基础上,可对特征 news_id 中的新闻类型进行计数,并使用 Matplotlib 库中的 pyplot 模块中的 pie 函数绘制不同新闻类型的浏览数量分布饼图。
1.3 不同类型新闻的浏览量
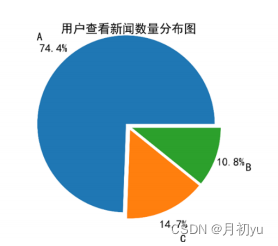
将所有查看新闻数量小于等于 2 条的用户分类为 A,将所有查看新闻数量等于 3 条的用户分类为 B,将所有查看新闻数量大于 3 条的用户分类为 C。并使用 Matplotlib 库中的 pyplot 模块中的 pie 函数绘制用户查看新闻数量分布饼图。
4.2 数据预处理
在进行数据探索时对浏览记录中的新闻类型和浏览量进行计数,发现 8976 条新闻共产生了 279908 条新闻浏览记录,同时发现浏览记录数据中存在着重复数据,这些重复数据不仅会消耗更多的计算资源,而且还会造成分析结果的偏差。因此在利用新闻浏览记录数据进行推荐之前需要对这些重复数据进行处理。
可以看出大部分用户在观测窗口期间只查看了 2 条新闻,此类用户大多为游客,随机点击页面查看新闻。鉴于新闻业务方面与新闻个性化推荐方面的考虑,若将此类用户数据加入模型训练,将会导致后续建模时出现相似度矩阵过于稀疏、计算开销非常庞大、预测结果精确度低下等情况。因此仅筛选在观测期间查看新闻数目大于等于 3 条的用户数据用于训练模型。
4.3 模型构建
基于用户的协同过滤推荐算法的推荐更社会化,能反映用户所在的小型兴趣群体中物品的热门程度;而基于物品的协同过滤推荐算法的推荐更加个性化,能反映用户自己的兴趣传承。因此选择基于物品的协同过滤推荐算法介绍如何进行推荐。
针对一段时期内用户访问网络新闻的统计数据构建模型,主要包括划分数据集、计算物品相似度矩阵、基于相似度矩阵进行排序推荐。
4.3.1 划分数据集
在对数据进行探索和预处理以后,模型构建之前需要将数据集按 7:3 的比例划分为训练集和测试集,训练集用于训练推荐模型;测试集用于预测推荐给用户的新闻。
4.3.2 构建物品相似度矩阵
案例中物品与物品间的相似度采用杰卡德相似系数。物品 i 和物品 j 相似是因为它们共同被多个用户喜欢,相似度越高表示同时喜欢它们的用户数越多。
其中 |𝑁(𝑖)|,|𝑁(𝑗)| 分别是喜欢物品 i 和 j 的用户数,|𝑁(𝑖) ∩ 𝑁(𝑗)| 表示同时喜欢物品 i 和 j 的用户数,|𝑁(𝑖) ∪ 𝑁(𝑗)| 表示喜欢物品 i 和 j 的用户总数。
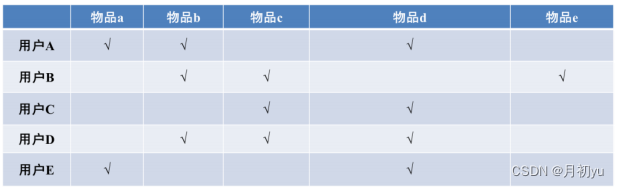
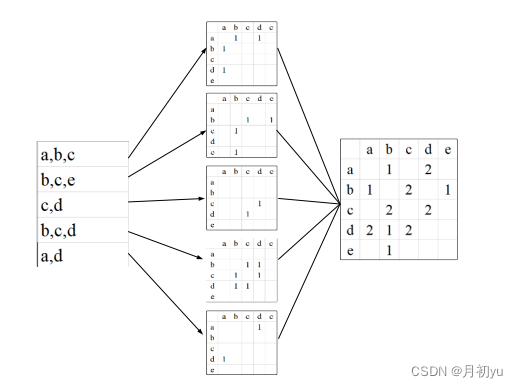
假设用户 A 浏览过物品 a、b、d,用户 B 浏览过物品 b、c、e,用户 C 浏览过物品 c、d,用户 D 浏览过物品 b、c、d,用户 E 浏览过物品 a、d。
用户浏览物品表如下:
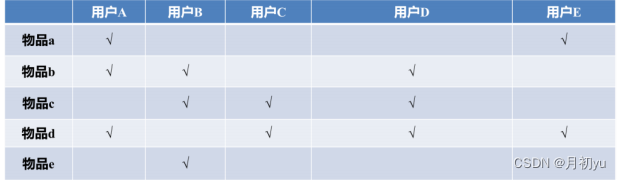
用户-物品倒排表如下:
根据用户-物品倒排表可以构建物品相似度矩阵。
4.3.3 基于相似度矩阵进行推荐
基于物品的协同过滤算法可通过下面的公式计算用户 u 对一个物品 j 的兴趣。
公式的含义为和用户历史上最感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。其中 N(u) 表示用户喜欢的物品集合,S(j,k) 是和物品 j 最相似的 k 个物品的集合,wij 是物品 j 和 k 的相似度,rui 表示用户 u 对物品 i 的兴趣。
在生成推荐列表时有时需要使用热点新闻补充个性化推荐的结果。这是因为部分新闻因点击用户过少,导致与其最相似的 k 个新闻中,存在相似度为 0 的推荐新闻,此时仅保留相似度大于 0 的个推荐新闻,再推荐 k-k1 个热点新闻。在测试集中,由于部分新闻不在训练集的相似度矩阵中,无法根据相似度矩阵进行推荐,因此推荐 k 个热点新闻作为替代。最后,依据训练集中的物品相似度矩阵对测试集用户进行推荐。
4.3.4 模型评估
利用离线测试集构造模型评价指标,主要用精确度和召回率
精确度,推荐给用户的新闻中,真正在测试集中被该用户浏览的个数与推荐给用户的新闻个数的比率
召回率,推荐给用户的新闻中,真正在测试集中被该用户浏览的个数与测试集中用户浏览的新闻个数的比率
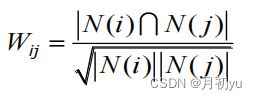
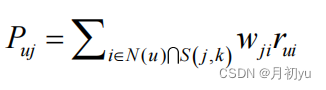
2,代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics.pairwise import cosine_similarity
import warnings
#0,细节处理
#0.1解决字体缺失问题
font_path=r"C:\Windows\Fonts\simhei.ttf"
plt.rcParams["font.sans-serif"]=["SimHei"]
plt.rcParams["axes.unicode_minus"]=False
#0.2忽略警告
warnings.filterwarnings("ignore", category=UserWarning, module="sklearn")
warnings.filterwarnings("ignore", category=RuntimeWarning, module="sklearn.metrics")
#1,读数据
path=r"C:\Users\yu\Desktop\课设\NLP课设\实验\实验4\数据集\基于浏览记录的个性化新闻推荐.csv"
data=pd.read_csv(path)
#2,数据清洗
data.drop_duplicates(inplace=True)
data.dropna(subset=["new_all"], inplace=True)
#将new_times转换为数值类型
data["new_times"]=pd.to_numeric(data["new_times"].str.extract(r'(\d+)')[0])
#3,数据探索与可视化
#3.1不同类型新闻的发布量
data["news_type"]=data["new_all"].apply(lambda x: "全图或视频"
if pd.isna(x)
else ("图文或短篇" if len(x)<200 else "全文本") )
type_counts=data["news_type"].value_counts()
plt.figure()
type_counts.plot(kind="bar")
plt.title("不同类型新闻的发布量——柱形图")
plt.xlabel("新闻类型")
plt.ylabel("发布量")
plt.show()
#3.2不同类型新闻的浏览量
view_counts=data.groupby("news_type").size()
plt.figure()
view_counts.plot(kind="pie", autopct="%.1f%%")
plt.title("不同类型新闻的浏览量——饼图")
plt.show()
#3.3不同用户查看新闻数量的分布
user_view_counts=data["user_id"].value_counts()
user_view_counts_bins=pd.cut(user_view_counts, bins=[0, 2, 3, float("inf")], labels=["查看0到2次", "查看2到3次", "查看3次以上"])
user_view_counts_bins.value_counts().plot(kind="pie", autopct="%.1f%%")
plt.title("用户查看新闻数量的分布——饼图")
plt.show()
#4,数据预处理
#删除浏览记录<=2条的用户
valid_users=user_view_counts[user_view_counts>=3].index
data=data[data["user_id"].isin(valid_users)]
#5,模型构建与训练
#5.1构建用户-新闻矩阵
user_news_matrix=data.pivot(index="user_id", columns="news_id", values="new_times").fillna(0)
#5.2确保所有值为浮点数
user_news_matrix=user_news_matrix.astype(float)
#5.3计算新闻相似度矩阵
news_similarity=cosine_similarity(user_news_matrix.T)
news_similarity_df=pd.DataFrame(news_similarity, index=user_news_matrix.columns, columns=user_news_matrix.columns)
#5.4划分数据集
train_data,test_data=train_test_split(data, test_size=0.3, random_state=40)
train_matrix=train_data.pivot(index="user_id", columns="news_id", values="new_times").fillna(0)
#5.5基于物品的协同过滤推荐
def recommend_news(user_id, top_k=5):
#获取用户已经评价过的新闻和评分
if user_id not in train_matrix.index:
return pd.Series(dtype=float)
user_ratings=train_matrix.loc[user_id]
user_ratings=user_ratings[user_ratings > 0]
#创建一个空的Series来存储相似度分数
similar_news=pd.Series(dtype=float)
#遍历用户评价过的每个新闻
for news_id in user_ratings.index:
#获取当前新闻与其他新闻的相似度分数
similar_score=news_similarity_df[news_id] * user_ratings[news_id]
#移除用户已经评价过的新闻
similar_score=similar_score.drop(user_ratings.index)
#将当前新闻的相似度分数添加到similar_news中
similar_news=pd.concat([similar_news, similar_score])
#对相似度分数按新闻ID进行分组并求和,得到推荐结果
recommendations=similar_news.groupby(similar_news.index).sum()
#按相似度分数降序排列,并取前top_k个作为推荐结果
recommendations=recommendations.sort_values(ascending=False).head(top_k)
return recommendations
#6,模型评估
#6.1获取测试用户列表
test_users=test_data["user_id"].unique()
#6.2初始化存储准确率和召回率的空列表
precisions=[]
recalls=[]
#6.3遍历每个测试用户
for user_id in test_users:
#获取真实评分过的新闻列表
true_news=test_data[test_data["user_id"] == user_id]["news_id"]
#跳过未评分用户
if len(true_news) == 0:
continue
#获取推荐的新闻列表
recommended_news=recommend_news(user_id).index
#计算命中数、准确率和召回率
hits=len(set(recommended_news) & set(true_news))
precision=hits/len(recommended_news) if len(recommended_news)>0 else 0
recall=hits/len(true_news) if len(true_news)>0 else 0
#存储准确率和召回率
precisions.append(precision)
recalls.append(recall)
avg_precision=np.mean(precisions)
avg_recall=np.mean(recalls)
#6.4打印评估指标
print(f"平均准确率={avg_precision:.2f}")
print(f"平均召回率={avg_recall:.2f}")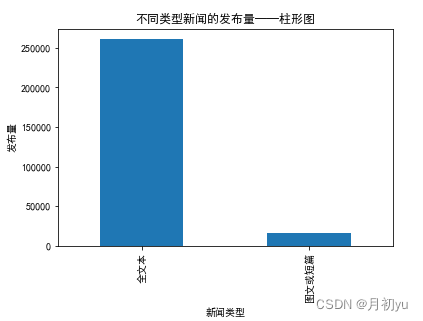
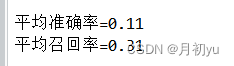

















 2966
2966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









