







---------------------------------------------------------------------------------------------------------------------------------
声明 ①极简
②可能有误,请纠正
③无力更新了,我自己总结树的公式感觉还可以
---------------------------------------------------------------------------------------------------------------------------------
一、绪论
1.1、数据结构的基本概念
1.2、算法和算法评价
二、线性表
2.1、线性表的定义和基本操作
2.2、顺序表
2.3、线性表的链式表示
三、栈、队列和数组
3.1、栈
3.2、队列
3.3、栈和队列的应用
3.4、特殊矩阵压缩存储
四、串
4.1、串的定义和实现
4.2、串的模式匹配
五、树
5.1、树
1,树的概念
树:n个点的有限集合(递归定义的数据结构)
分支结点:有儿
叶子结点:没儿
路径长度:从上往下,有几条边
点的层次/深度:从上往下数
点的高度:从下往上数
点的度:有几个儿
树的高/深度:总共多少层
树的度:max(点的度)
同构:两棵树,名字不一样,其他都一样
斜树:糖葫芦串,just,全左或全右
2,树的种类
森林:m(m>=0)棵互不相交的的树的集合
(1)满二叉树:堆满了
(2) 完全二叉树:《满》从右下角,按序号删点得到
(3) 二叉排序树:序号往左下依次-,往右下依次+
(4) 平衡二叉树:任一点的左子树和右子树的深度之差≤1
(5)哈夫曼树(最优二叉树)
在有n个带权叶子的二叉树中,WPL最小的树




3,哈夫曼树
哈夫曼树——补充知识
点的权,表示重要性
点的带权路径长度=(根到该点经过的边数)*权值
树的带权路径长度WPL=all(叶的带权路径长度)之和
哈夫曼树——性质
1,每个初始点都成为叶子,权值越小,路径越长
2,点=2n-1
3,无(度=1)的点
4,形状不唯一,但WPL都一样,且最优
哈夫曼树——构造

4,哈夫曼编码
哈夫曼编码——补充知识
①固定长度编码,每个字符,用等长的二进制位表示
②可变长度编码,允许对不同字符用不等长的二进制位表示
③前缀编码,无一个编码是另一个编码的前缀,无歧义
哈夫曼编码——构造
①字符集的每个字符,作为一个叶子
②字符出现频度=权值
③按哈夫曼树构造
哈夫曼编码——性质
①不唯一
②用于数据压缩
5.2、二叉树
1,度=m

2,m叉树

3,二叉树

4,满二叉树

5,完全二叉树

5.3、遍历和线索二叉树
1,树的遍历
树的遍历
1,先根遍历(约=根左右)《深度优先遍历》
2,后根遍历(约=左右根)《深度优先遍历》
3,层次遍历《广度优先遍历》
①根入队
②队头出队,访问这个点,把它孩子入队
③重复
森林的遍历
(1)先序遍历
①分别对每个子树,先序遍历
②森林——>二叉树,先序遍历
(2)中序遍历
①分别对每个子树,后根遍历
②森林——>二叉树,中序遍历
2,二叉树的遍历
二叉树的遍历
①先=根左右
②中=左根右
③后=左右根
遍历⇒完整树(必须有中)
①前+中
②后+中
③层+中
3,线索化
线索化,对叶
①左子+前驱
②右子+后继
5.4、树的存储结构
①双亲表示法
定义,data+parent(指向父)
优,找父方便
缺,找儿,要遍历整个数组
适用,找父多,找子少——并查集
②孩子表示法
定义,data+*firstkid(指向儿的一条链)
优,找儿方便
缺,找父,要遍历整个数组
适用,找父少,找子多——服务流程树
③孩子兄弟表示法
定义,二叉链表,*firstkid(指向第一儿),*nextbro(指向右第一兄)
存森时,每棵树的根,视为平级的兄弟
存储结构,类似于二叉树
5.5、树的应用
1,树的转换
树——>二叉树
①根放一边
②根的子,往右下,串成糖葫芦
③再依次找子的子,串成糖葫芦
④重复


森林——>二叉树
同上,区别=无根,直接把第一层串起来就行


二叉树——>树
一个糖葫芦,就是上面一个点的儿


二叉树——>森林
第一个糖葫芦,就是森林的第一层


2,并查集
查,一路向北,查到根
并,一棵树成为另一棵树的子树
并查集——时间复杂度
1,未优化
最坏
find=最坏树高O(n)
将n个独立元素,多次并为一个集合,O(n*n)
2,优化union
最坏
find=最坏树高=O(log₂n)
将n个独立元素,多次并为一个集合,O(nlog₂n)
3,优化find
最坏
find=最坏树高=(α(n))
将n个独立元素,多次并为一个集合,O(nα(n))
((α(n))增长很慢,一般<=4)
3,tip
(1)《线树》——目的
①加速遍历
②方便找前驱后继
(2)删点
①删左右儿
②删该点
⇒后遍删✔
(3)《后线树》——缺
①难找后继
②栈
(4)树的《顺存》
①just,完+满
②存all点
(5)《二》遍历结果=唯一
(6)《森》——《二》(根的左子树的点)=m1-1
(7)《森》叶=《二》(左子=null)
(8)遍历关系①森先=二先
②森后=二中
六、图
6.1、图的基本概念
0,补充
路径:点序列abcd
回路/环:第一个点=最后一个点
简单路径:点不重复出现的路径
简单回路:除第一个点和最后一个点,其余点不重复出现的回路
路径长度:几条边
点到点的距离:a到b的最短路径(无,就=∞)
子图,部分点+部分边
生成子图,all点+部分边
边的权(权值):边,标上(有含义的值)
带权图/网:边,有权值
带权路径长度:带权图中,一条路上,(all边的权值)之和
1,图
图——定义
①点,必非空,可∞
②边
图——种类
(1)简单图
① 无重复边
② 无指向自身的边
(2)多重图
两点之间边数>1,又有指向自身的边
(3)稀疏图:边少
稠密图:边多
2,无
无向图——定义
①边,无向,有限
②点
无连图——定义
无孤立点
无连图——种类
①树,无回路的无连图
②环
③无完图,无向图中,任两点之间有边
3,无的补充
连通:两点之间有边
极小连通子图:刚好连,少一边就不连
极大连通子图/连通分量:尽可能,多点+多边
(其中,极大=该连通分量中,all点+all点依附的边)
连通图的生成树:含all点的极小连通图,all点+少边
非连通图的生成森林:由连通分量的生成树构成
极大连通子图的特例
若图
①不连通
②每个子部分,含all点和边它自己,就是极大连通子图
4,无的公式


5,有
有——定义
①边,有向,有限
②点
有完图:有中,任两点之间,有双向弧
有向树
①just一(点的入度)=0
②其余(点的入度)=1
③有向图
6,有的补充
①弧头:箭头指的(b)
②弧尾:箭尾指的(a)
①入度
②出度
③点的度=出度+入度
强连通:两点之间,有双向弧
强连通图:一点到另一点,有相反的两条路
极大强连通子图/强连通分量,多边+多点
强连通分量的特例
一点只有出边,或只有入边,该点单独构成一个强连通分量

7,有的公式

6.2、图的存储、基操
1,邻接矩阵
邻接矩阵,用数组实现的顺序存储
邻接矩阵——特点
①求度/出度/入度,时=O(n)
②空=O(n²),稀✔,稠X
③若点的编号写好,则表示方式唯一
邻接矩阵——代码
①点的信息
②二维数组
③点数,边数
邻接矩阵——带权图代码
①点max
②∞(环=0)
③点的类型
④权值的类型
⑤点的信息
⑥权值二维数组
⑦点数,弧数


邻接矩阵——存无
(是对称矩阵,可压缩存储,只存上三角区/下三角区)
A[i][j]=1有边
A[i][j]=0无边
第i个点的度=(第i行/第j列=1)的sum

邻接矩阵——存有
A[i][j]=1,有(i——>j的弧)
A[i][j]=0,无(i——>j的弧)
第i个点的出度 = 第i行,1的sum
第i个点的入度 = 第i列,1的sum
第i个点的度 = 第i行、第i列的1的sum之和

邻接矩阵A
的元素,
——>

2,邻接表
邻接表——特点
①顺+链
②表示方式不唯一,边可换顺序
③稀✔,稠也✔
邻接表——存无
①边=2*实际边
②空=O(n+2e)
邻接表——存有
空=O(n+e)
邻接表——代码
点
①点信息
②指向点的第一条边点数组
①点数
②边树边
①指的点
②指向下一条边的指针
3,图的基操



6.3、图的遍历
1,广搜BFS
树的广搜=层遍
广——步骤
(1)找一点相邻的all点,用基操
①找第一邻点
②找第一邻点的下一邻点(无,返-1)(2)标记,已访过的点
(3)辅助队列
广——完整代码
①访点 ②标记 ③点V=✔,入队 ④if(队非空) ①V出队 ②找V的邻点V1 if(V1=X) ①访V1 ②标记V1=✔ ③V1入队
广——优化代码
①设标记数组=bool ②优() ①数组全=X ②初始化队列Q ③for(标记数组) if(X){BFS}
广——时空,不看代码,看矩和表
①空,最坏=O(n)
②时

广度优先生成树
(高度min的树)
表示方式 广树形态 矩 唯一 唯一 表 不唯一 不唯一
2,深搜DFS
树的深搜=树的先序遍历
深——未优化代码
①标记数组设为bool ②DFS(图,点) ①访点 ②点,标=✔ ③for(第一邻点,第二邻点) if(第一邻点=X){DFS}
深——优化代码
①for(图) 标记数组,全=X ②for(图) if(点=X){DFS}
深——时空
①空
最坏=O(n)
最好=O(1)
②时

3,广深对比
广深——共性
(1)广、深序列
(2)
无,调次=连通分量数
有,调次
①if起始点,到每个点都有路,1次
②有强连,从哪开始,都是1次

广深——步骤区别
(1)广
头(all邻点)(2)深
头(头的第一邻点A——>A的下一邻点)——>头的第二邻点
十字链表
解决表——存有时,入边和出边重复
邻接多重表
解决表——存无时,边冗余

6.4、图的应用
1,最小生成树MST
带权无连图G——>all生成树R——>最小生成树T
(R中边的权值之和min)
MST——性质
①形态可多样,但边权值之和all一样,且min
②if一无连,本身就是树,其MST就是自己
③just连,有生成树④非连,just有生成森林
⑤
边=点-1
边+1⇒一个环
边-1⇒不连
求MST的算法
(1)Prim算法(普里姆)
①从一点,开始建树
②每次把,代价min的新点,加入树
③重复,直到all点加入
(2)Kruskal算法(克鲁斯卡尔)①每次选,一条权值min的边
②使该边的两头连(已连的不选)
③重复,直到all点连
算法——时
(1)Prim=O(n²)
for(n-1)
①for(n),找LowCast中min的点
②for(n),更新(X的LowCast值)
准确来说,O(n-1)*O(2n)
(2)Kruskal=O(e*log2(e))
①边,按权值排序
②看,第1条边的两头,连不连(用并查集判断)
23
4
***
n
BFS——求无权图的单源最短路径
(all权值一样的带权图,也能求)
d[]——各点到源点,的min路长
path[]——各点的直接前驱
BFS_找最短路(图,源点)
(1)for(图) ①d[i]=∞ ②path[i]=-1 (2)d[源点]=0 (3)标记数组[源点]=✔ (4)入队(Q。源点) (5)while(队非空) ①出队(Q,源点) ②for(W=第一邻点(图,源点);W=all邻点(图,源点,W);W++) if(标记数组[W]=X) d[W]=d[源点]+1 path[W]=源点 标记数组[W]=✔ 入队(Q,W)

2,Dijkstra
Dijkstra——步骤
(1)初始化
①若从V0开始,设final[0]=✔
dist[0]=0
path[0]=-1
②其余点,设final[i]=Xdist[i]=arcs[0][i]
path[i]=(arcs[0][i]=∞)? -1:0
(2)n-1轮处理
①遍历all点,找到点a,有final[a]=X,令final[a]=✔dist[a]最小
②看a的all邻点b,若final[b]=X ,令dist[b]=dist[a]+arcs[a][b]dist[a]+arcs[a][b]<dist[b] path[b]=a
(准确来说,时=O(n-1)*O(2n))

Dijkstra,重复n次——>可求带权图中,all点间的最短路径,时=O(n³)
3,Floyd
①动态规划
②求每一对点之间的最短路径
Floyd——步骤
(1)初始化,无中转点和中转路径
(2)n次循环
①允许在V0中转⇒、
②允许在V1中转⇒、
V2 ⇒
***
Vn-1 ⇒

Floyd——例子
(1)初始化

(2)n次循环
①允许在V0中转
②允许在V1中转
***
允许在Vn-1中转



Floyd——代码
for (int k = 0; k < n; k++) {//以Vk为中转点 for (int i = 0; i < n; i++) {//遍历矩阵 for (int j = 0; j < n; j++) { if (A[i][j] > A[i][k] + A[k][j]) {//以Vk为中转点的路径更短 A[i][j] = A[i][k] + A[k][j];//更改最短路长 path[i][j] = k;//中转点 } } } }
Floyd——时空
时=O(n³)
空=O(n²)
| BFS | Dijkstra | Floyd | |
| 无 | ✔ | ✔ | ✔ |
| 带 | X | ✔ | ✔ |
| 负权图 | X | X | ✔ |
| 负权回路 | X | X | X |
| 时 | O(n²)或O(n+e) | O(n²) | O(n²) |
| 适用 | 无权图的单源最短路 | ①带权图的单源最短路 ②有、无中的最短路径问题 | 带权图中各点间的最短路 |
4,拓扑排序
有向无环图DAG——描述表达式
(多形态)
①把点,不重复的排成一排
②标,运算符顺序
③按序,加入运算符,分层
④自底向上,看同层可否合体
有向无环图DAG——例子


AOV网,用点表示活动的网
(是DAG,必无环)
拓扑排序——定义
(找做事的先后顺序)
当一个由有向无环图的点组成的序列,满足
①每个点,just出现一次
②若A在B前面,必无A<——B的路
拓扑排序——步骤
在AOV网中
①找一无前驱的点,并输出
②删该点
all该点指向的边
③重复①②,直到网空
网中,无(无前驱的点)⇒有环
拓扑排序——时
矩 O(n²) 表 O(n+e)
拓扑排序——代码

逆拓扑排序——步骤
在AOV网中
①找一无后继的点,并输出
②删该点
all指向它的边
逆拓扑排序_DFS——代码
(在点退栈前输出)

5,关键路径
AOE网(用边表示活动的网络)
有带无环图中
①点——事件
②边——活动
③边权——完成该活动的开销
AOE网——性质
①just点发生后,点所指的边,才能开始
②just点的入度边,all结束时,该点才能发生
③点可并行
源点
①just一个
②入度=0
③表示整个工程的开始
汇点
①just一个
②出度=0
③表示整个工程的结束
关键路径
从源点到汇点,的all路中,路长max
关键活动
关路上的活动(边)
结论
①完成整个工程的min时=关路的长
②关活,耗时↗,工期↗③关活,时↘,可能变成非关活
④关路,可能有多条
⑤加快all关路上的关活,工期才↘
关键路径——步骤
待完成
6,tip
(1)图的遍历,每个点,just被访1次
(2)对无连图深搜,可访问到all点
(3)不是图
(4)图的点,可∞个
(5)连通分量中,可能有回路
(6)有向图的矩,若对角线以下,全=0——>无环
(7)矩,若主对角线,全=0——>每个点,无指向自己的边
(8)无完/有完,矩①主=0
②其余=1
(9)判,有向图,有无环
①拓
②深③关路
(10)不是环
①简单路径
②最短路径
(11)Floyd,求每对点间的最短路
①边权,可=负
②不可有,含负边的环
(12)修改深
输出后,马上退出栈⇒序列=逆拓扑
(13)无连,权all=1
广,可求从某点,到其余点的最短路
(14)若有的拓,序列唯一
①X,每个点,入度≤1,出度≤1
②✔,入度=0的点仅一个,出度=0的点仅一个


七、查找
7.1、查找
查找
在数据集合中,找数据元素
查找表(查找结构)
①⽤于查找的数据集合
②由同类型的数据元素(或记录)组成
关键字
①数据元素中,唯⼀标识该元素的某个数据项的值
②基于关键字的查找,查找结果唯⼀
(1)静态查找表
just查
(2)动态查找表
①查
②插入、删
查找⻓度
对⽐关键字的次数
平均查找⻓度(ASL, Average Search Length)
所有查找过程中,进⾏关键字的⽐较次数,的平均值
ASL=∑PiCi (i=1,2,3,…,n)
7.2、顺查和折半
1,顺查
顺查——视频代码
//顺序表 typedef struct{ int *p;//动态数组基址 int len; };sb //顺查 int f(sb a,int key){ for(int i=0;i<len&&a.p[i]!=key;i++) {return i==a.len ? -1:i;} } //✔,返坐标 //X,返-1
顺查——课本代码
//顺序表 typedef struct{ int *p;//动态数组基址 int len; };sb //顺查 int f(sb a,int key){ a.p[0]=key;//哨兵 for(int i=a.len;a.p[i]!=key;i--) return i; } //✔,返坐标 //X,返0变化
①0号位置空出来,放哨兵
②从1号开始,存数据
优
不用判越界
顺查优化——有序表
用查找判定树,分析ASL
一个成功点的查长=自身所在层
失败 父


2,折半查找(二分查找)
just适用于有序的顺序表
折——代码
//顺序表 typedef struct{ int *p; int len; }sb; //折 int f(sb a,int key){ int low=0; int high=a.len-1; int mid; while(low<=high){ mid=(low+high)/2; if(a.p[mid]==key) reutrn mid;//✔ if(a.p[mid]>key) high=mid-1;//往左走 if(a.p[mid]<key) low=mid+1;//往右走 } return -1;//X } //代码不能正常运行,just为了美观简洁
折树
①平二树,just最后一层不满
②二排树,左<中<右
③失败点=n+1=空链表
④若mid=(low+high)/2,对任一点,右子树的点-左=0/1⑤点=n——>h=log2(n+1)——>查✔,ASL≤h
查X,ASL≤h⑥时=O(log2n)
3,分块查找
分——特点
①块内无序
②块间有序
分——代码
//索引表 typedef struct{ int maxv; int low,high; }index; //顺序表存的元素 int list[100];
分——步骤
(1)在索引表中,找对应分块
①顺
或
②折
(若索引表中无目标,此时折索表,停在low>high,要在low所指分块中找)
(2)在块内顺查
分——时


7.3、树型查找
1,二叉排序树(二叉查找树)
二排——定义
①可空
②左<根<右
③左、右子树,all是二排
(中遍——>递增序列)
④点不能重复
二排——时
=查长=O(log₂n +1)查最坏情况,糖葫芦=O(n)
二排——代码
//二排树 typedef struct{ int k; struct node *l,*r; }node,*tree; //查——非递归(空复=O(1)) node *f_find(tree a,int k){ while(a非空&&k!=a->k){ if(k<a->k) a=a->l; if(k>a->k) a=a->l; } return a; } //查——递归(空复=O(h)) node *f_find(tree a,int k){ if(a空) return null; //树空,X if(k=a->k) return a; //=根,✔ if(k<a->k) return f_find(a->l,k); //<根,查左儿 if(k>a->k) return f_find(a->r,k); //>根,查右儿 } //插——递归 int f_insert(tree a,int k){ if(a空){ a=(tree)malloc(sizeof(node)); a->k=k; a->l=a->r=空; return 1; } //树空,X if(k=a->k) return 0; //=根,✔ if(k<a->k) return f_insert(a->l,k); //<根,查左儿 if(k>a->k) return f_insert(a->r,k); //>根,查右儿 } //新插入的点,包是叶——>空=O(h) //构 void f_create(tree &a,int str[],int n){ a=空; int i=0; while(i<n){ f_insert(a,str[i]); i++; } } //不同的关键字序列,可能得到,相同的树
删——步骤
(1)叶,直接删,无影响
(2)just左儿,或,just右儿让k的儿,替代k
(3)左右儿,all有
①让k的直接前驱,替代k
直接后继
②删该直接前驱
直接后继
注
①直前,左儿中最右下的点,包无右儿
②直后,右儿中最左下的点,包无左儿
2,平衡二叉树AVL
定义
任一点的左、右子树的高度差≤1
点的平衡因子=左子树的高-右子树的高
(平二树,每个点的平衡因子,just=-1/0/1)
平二树——代码
//平二树——点 typedef struct node{ int k; //数据域 int balance; //平衡因子 struct node *l,*r; }node,*tree;
二排树,插之后,how保持平衡
①从插入点,往上找,第一个不平衡点A
②调整以A为根的树(最小不平衡树)
调整最小不平衡树——目标
①恢复平衡
②保持二排特性(左<根<右)
调整最小不平衡树——原因
插入时,只要调整最小不平衡树,让它平衡,其他祖先点都会平衡
最小不平衡树——情况
①LL,对A的L,右旋
②RR,对A的R,左旋
③LR,对A的LR,左旋,再右旋
④RL,对A的RL,右旋,再左旋
平二树——时

平二树——删步骤
①按二排删,删点
②往上找,最小不平衡树A,无就end
③找A下面,最高的儿和孙
④根据孙,调整A
⑤if不平衡向上传导,继续②(平二删——时=O(log₂n))
3,红黑树RBT
定义
①点=红/黑
②根=黑
③叶(外部点、NULL点、失败点)all=黑
④父子不能同时=红
⑤每个点,从该点,到其他点的路上,黑相同(黑高bh)
定义——简记
①左根右
②根叶黑
③不红红
④黑路同
红黑树——代码
struct node{ int k; node* dad; node* l; node* r; int color; }
红黑树——性质

红黑树——插
(1)按左<根<右,插
(2)新点=根,染黑
新点≠根,染红
①if插新点,红黑树✔,end
②if插新点,红黑树X,看叔色
黑叔
LL,右旋,父爷换色
RR,左旋,父爷换色
LR,先左旋,再右旋,儿爷换色
RL,先右旋,再左旋,儿爷换色
红叔
叔父爷换色,爷变新点
红黑树——删
①时=O(log₂n))
②=二排删
③删后,会破坏红黑特性,需调整
7.4、B树和B+树
1,B树
又称多路平衡查找树
5叉查找树——代码
struct node{ int k[4]; //关键字 struct node* kid[5];//儿 int num; //点中,有几个关键字 }
5叉查找树——↑ 查效率
①除了根,all点,分叉≥⌈m/2⌉,关键字≥⌈m/2⌉-1(向上取整)
②all点,其所有子树的高相同
B树的阶,max(儿个数),⽤m表示
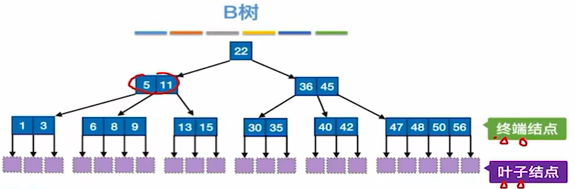
B树——定义
空树,或满⾜如下性质的m叉树
①all点,⼦树≤m,关键字≤m-1
②if根≠终端结点,⼦树≥2
③除了根,all点,分叉≥⌈m/2⌉,关键字≥⌈m/2⌉-1
④非叶点,结构如下
ki,关键字,k1<k2<...<kn
pi,指针
pi-1所指子树<ki
pi所指子树>ki
n,关键字个数(⌈m/2⌉-1≤n≤m-1)
⑤all叶在同一层,无信息(=失败结点)
B树——核心性质
①根, ⼦树∈[2, m], 关键字∈[1,m−1]
其他点,⼦树∈[⌈m/2⌉,m],关键字∈[⌈m/2⌉−1,m−1]
②all点,其所有子树的高相同
③⼦树0<关键字1<⼦树1…. (≈左<中<右)
B树——高


B树——插
①插后,if点,关键字>上限,则从中间位置⌈m/2⌉二分,左放在原点,右放到新点,《中》插⼊原点的⽗
(若⽗的关键字也>上限,重复①,直⾄传到根为⽌,导致B树h+1)
②新元素,包是,插到最底层的终端点
B树——点
①叶——失败点
②终端点——失败点上面一层
B树——删
若被删关键字
(1)在终端点
直接删
(2)在⾮终端点
⽤直前/直后,替代被删的关键字
①直接前驱:当前关键字,左⼦树中,最右下元素
②直接后继:当前关键字,右⼦树中,最左下元素
(3)所在点
①删之后的关键字<下限
②兄富
左兄富,⽤当前点的前驱、前驱的前驱,填空
右兄富,⽤当前点的后继、后继的后继,填空
(4)所在点
①删之后的关键字<下限
②兄穷
③左右兄的关键字=⌈m/2⌉ − 1
删后,则合并(左/右兄+父)的关键字
合并——注
合并时,父的关键字会-1
若
①父=根
②父的关键字=0
则删根,让合并后的新点成为新根
若
①父不等于根
②父的关键字=⌈m/2⌉ − 2
则父与其兄调整,重复,直到满足B树
2,B+树
B+树——点
①叶——就是普通树的叶
②分支点——非叶的点
B+树,查✔或X,all查到最后一层
B+树,just叶,存记录
B树,每个点,存(关键字+记录+地址)
B+树——定义
①分支点,儿≤m
②根, 关键字∈[1,m]
其他点,关键字∈[⌈m/2⌉,m]
③点,儿=关键字
④叶,存(关键字+记录的指针)
分支点,存(关键字max+儿指针)
叶中,关键字按大小排列,相邻叶,顺序链接——>可顺查
B树和B+树——区别
①B, 关键字=n,子树=n+1
B+,关键字=n,子树=n
②关键词区间,不同
③B, 关键字不重复
B+,关键字可能重复
④点存的信息,不同
数据库,索引功能常用B+树实现
7.5、散列查找
0,补充
冲突(碰撞)
在散中,插一元素时,需根据关键字确定地址,该地址已存了其他元素
同义词
不同的关键字,通过散列函数,映射到同⼀个地址
1,散列表(哈希表)
散——定义
①⼀种数据结构
②特点,可根据数据元素的关键字,算出它在散列表中的存储地址
散列函数(哈希函数)
Addr=H(key)
关键字→存储地址,的映射关系
散函——注意
Addr=H(key)
①定义域key,含all关键字
②值域Addr,≤散表的地址范围
③少冲突,Addr,要匀布在地址空间
④散函H,要简单,能快算出key对应的Addr
散函——构造
①除留余数法,H(key)=key%p
(表长=m,取质数p,≤m且接近m)
②直接定址法,H(key)=a*key+b
(最简单,无冲突。若关键字不连续,空位多浪费)
③数字分析法,选数码分布较为均匀的若⼲位
(在某些位上,分布均匀)
④平⽅取中法,选关键字的平⽅值的中间⼏位


散函——适用
①除,通⽤,关键字=整
②直,关键字连续分布
③数,关键字已知,且关键字的某⼏个数码位分布均匀
④平,关键字的每位取值,all不均匀
2,拉链法
解决冲突——方法
①拉链法
②开放定址法
拉链法
拉——插
①用散函,算地址
②把新元素,插入地址对应的链表
拉——查
①用散函,算地址
②顺查地址对应的链表,直到查✔/X
(查长,只统计关键字的对比次数,空指针的对比次数不计入)
拉——删
①用散函,算地址
②顺查地址对应的链表,if查✔,删
3,开放定址法
开放定址法——原理
①有冲突,就给新元素找空位
②开放定址,指地址,对同义词、⾮同义词all开放
开放定址法——方法
①线性探测法, di=0, 1, 2, 3, …, m-1
②平方探测法, di=0²,1²,-1²,2²,-2²...,k²,-k²
③双散列法, di=i×hash2(key)
④伪随机序列法, di=0, 5, 3, 11, …
Hi = (H(key) + di) % m
Hi ,第 i 次冲突的地址
H ,初始地址
di,偏移量
m,散列表长
开放定址法——查/插
①根据探测序列,依次对⽐关键字
②探到⽬标关键字,查✔
探到空单元,查X
开放定址法——删
①散函算地址,对⽐关键字是否匹配。若匹配,则查✔
②若关键字不匹配,根据探测序列,对⽐下⼀个关键字,直到查✔/查X
③查✔,则删元素
(只能逻辑删,标记“已删”)——>查效率低,散列表看起来满,实则很空
开放定址法——探测覆盖率
①线,经m-1次冲突,包能探到all
②平,至少能探到一半(若表长m=4X+3的素数,则能探到all)
③双,若hash2(key)与m互质,则经m-1次冲突,包能探到all
④伪,just伪随机序列合理,包能探到all
八、排序
8.1、排序的基本概念
排序
重新排列表中元素,使元素按关键字有序
稳定性
关键字相同的元素,在排序之后相对位置不变
排序算法
(1)内部排序,data都在内存
①时
②空
(2)外部排序,data多,无法全放内存
①时
②空
③读写磁盘次数
8.2、插入排序
算法思想
每次将⼀个待排序的记录按其关键字⼤⼩,插⼊到前⾯已排好序的⼦序列中,直到全部记录插⼊完成
直接插入排序——步骤
void f(待排序数组A,A的长){
i-待排序位置
j-i左边的元素
t-暂存A[i]
for(i从1到n-1循环)
if(A[i]<)
}
//直接插入排序——代码
void f(int A[],int n){
int i,j,t;
for(i=1;i<n;i++)
if(A[i]<A[i-1]){
t=A[i];
for(j=i-1;j≥0&&A[j]>t;j--)
A[j+1]=A[j];
A[j+1]=t;
}
}8.3、希尔排序
8.4、冒泡排序
8.5、快速排序
8.6、简单选择排序
8.7、堆排序

















 9186
9186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









