







【避雷】实验课打分离谱,同学一次性LL1语法分析器及参考我博客的同学分数还比我高,狠狠避雷
【编译原理】词法分析器
实验要求:
设置一个名字表NameL和常数表ConstL,当遇到标识符时,将其字符串送入名字表NameL,并把其名字表地址作为标识符的语义Seman值。常数情形也一样,不要求翻译成二进制数。要求在NameL和ConstL表中没有相同元素,同时具有简单的错误处理功能(找出源程序中所有存在的词法错误并指出错误所在的行数)。试用高级程序设计语言编写一个针对下述单词集的词法分析器。
token表
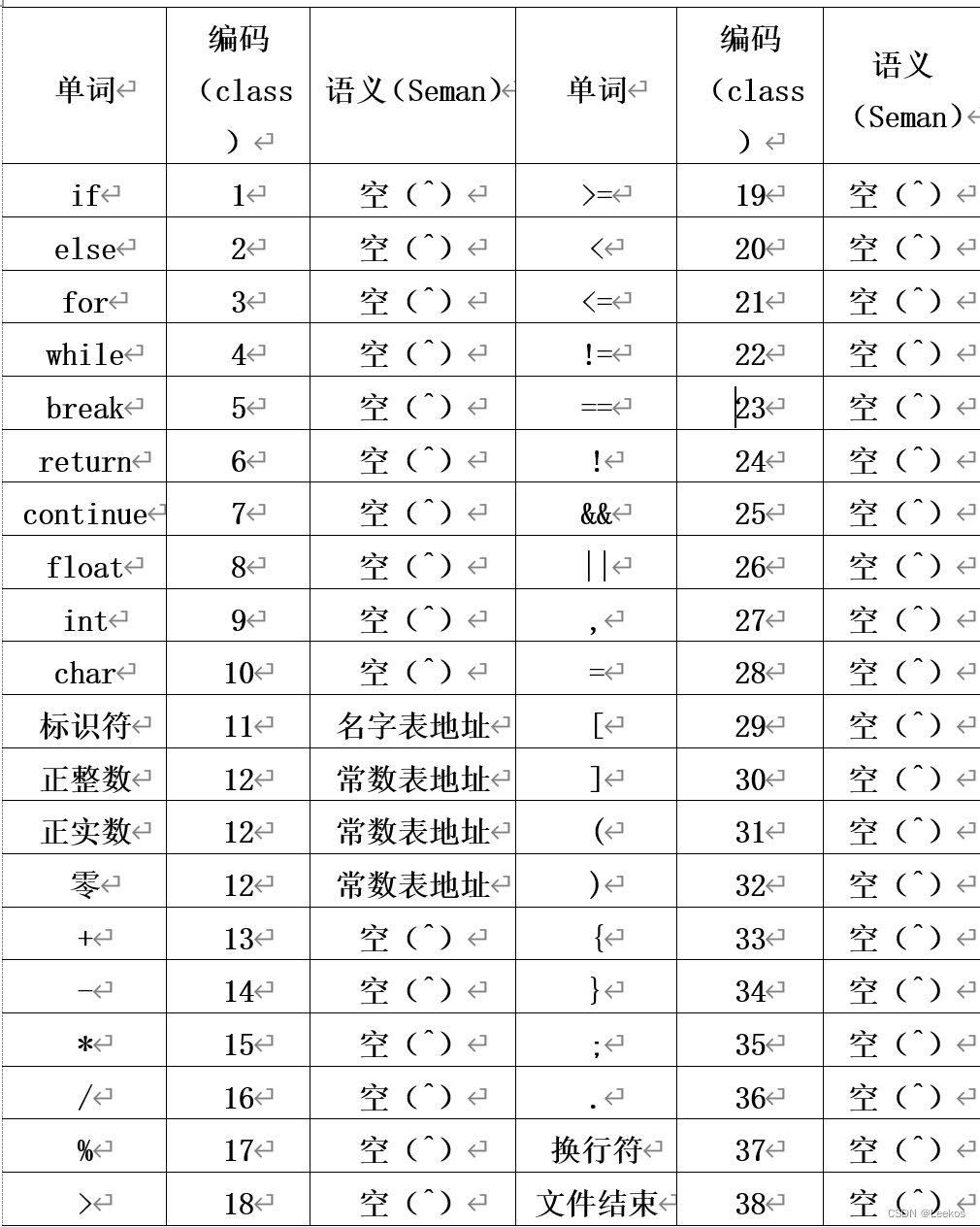
评分标准
①是否使用文件输入、输出;
②是否可以查找多个错误;
③每个错误是否有错误提示,包括错误所在行、错误信息;
④错误提示信息是否区分不同类别;
⑤同名标识符或常数是否重复存放;
⑥是否正确建立单词表和名字表、常量表的链接;
⑦是否处理注释。
词法分析器
import re
class MyToken:
def __init__(self, MyType, seman, MyStr):
self.MyType = MyType
self.seman = seman
self.MyStr = MyStr
def __str__(self):
s = self.MyStr.replace('\n','')
return "token.class: {:5}\t\tstr: {:10}\tseman:\t{} \t".format(self.MyType, s, self.seman)
# 单词集状态列表
states = ['if', 'else', 'for', 'while', 'break', 'return', 'continue', 'float', 'int', 'char', '标识符',
'正整数、正实数、零', '+', '-',
'*', '/', '%', '>', '>=', '<', '<=', '!=', '==', '!', '&', '|', ',', '=', '[', ']', '(', ')', '{', '}', ';',
'.', '\\', '#']
choiceStatec = [13, 14, 15, 16, 17, 18, 20, 24, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36] # 用于防止while循环中出现多次elif
inputs = [] # 输入的字符
tokens = [] # 单词表
NameL = [] # 名字表
ConstL = [] # 常数表
i = 0
line = 1
# 将文件内容提取到inputs
def codeToInputs(sourceCodes):
for line in sourceCodes:
for char in line:
inputs.append(char)
if char == '#':
return
# 判断是否为字母
def isLetter(char):
pattern = r"[a-zA-Z]"
return bool(re.match(pattern, char))
# 判断是否为数字
def isDigit(char):
pattern = r"[0-9]"
return bool(re.match(pattern, char))
# 普通的字符识别
def isC(char, state):
tokens.append(MyToken(state, "^", char))
def choiceState(char): # 选择单字符对应状态
state = 0
if char in states:
for k in range(len(states)):
if states[k] == char: # 判断单个字符
if char in ['>', '<', '!', '=', '&', '|', '\\'] and inputs[i] in ['=', '&', '|', 'n']: # 如果是双字符
state = 19
else:
state = k + 1
else:
state = 0
return state
def error():
print(f"第{line}行---未知字符错误")
# 词法分析
def nextToken():
global i
global line
name = ""
char = inputs[i]
i += 1
while char == ' ' or char == '\n' or char == '\t': # 如果是空就跳过
if char == '\n':
line += 1
char = inputs[i]
i += 1
if char == '#':
i -= 1
global state
state = 0
while True:
if state == 0: # 选择
if char == '#':
i -= 1
state = 38
continue
if char == '/' and (inputs[i] == '/' or inputs[i] == '*'): # 注释
state = 42
continue
if choiceState(char) != 0: # 判断后面的单字符,获取状态
state = choiceState(char)
i -= 1
continue
if char == "i":
state = 1
elif char == "e":
state = 2
elif char == 'f':
state = 3
elif char == 'w':
state = 4
elif char == 'b':
state = 5
elif char == 'r':
state = 6
elif char == 'c':
state = 7
elif isDigit(char): # 数字
state = 12
elif isLetter(char): # 字符串
i -= 1
state = 11
else:
error() # 非法字符报错
i -= 1
state = 38
elif state == 1: # if
if inputs[i] == 'f': # 判断第二个是否为f
if isDigit(inputs[i + 1]) or isLetter(inputs[i + 1]): # 标识符
i -= 1
state = 11
else:
m = MyToken(1, "^", "if") # 在单词表和名字表加入
tokens.append(m)
state = 38
elif inputs[i] == 'n': # 判断第二个是否为n
i += 1
if inputs[i] == 't':
if isDigit(inputs[i + 1]) or isLetter(inputs[i + 1]): # 标识符
i -= 2
state = 11
else:
m = MyToken(9, "^", "int") # 在单词表和名字表加入
tokens.append(m)
state = 38
else:
if isDigit(inputs[i]) or isLetter(inputs[i]): # 标识符
i -= 2
state = 11
else:
m = MyToken(11, "^", "in") # 在单词表和名字表加入
tokens.append(m)
state = 38
i -= 1
else: # 以i开头的标识符
i -= 1
state = 11
elif state == 2: # else
if ''.join(inputs[i:i + 3]) == 'lse':
if isDigit(inputs[i + 3]) or isLetter(inputs[i + 3]):
i -= 1
state = 11
else:
m = MyToken(2, "^", "else") # 在单词表和名字表加入
tokens.append(m)
state = 38
i += 2
else:
i -= 1
state = 11
elif state == 3: # for
if inputs[i] == 'o':
if inputs[i + 1] == 'r':
if isDigit(inputs[i + 2]) or isLetter(inputs[i + 2]):
i -= 1
state = 11
else:
m = MyToken(3, "^", "for") # 在单词表和名字表加入
tokens.append(m)
state = 38
i += 1
else:
i -= 1
state = 11
elif inputs[i] == 'l':
if "".join(inputs[i:i + 4]) == 'loat':
if isDigit(inputs[i + 4]) or isLetter(inputs[i + 4]):
i -= 1
state = 11
else:
m = MyToken(8, "^", "float") # 在单词表和名字表加入
tokens.append(m)
state = 38
i += 3
else:
i -= 1
state = 11
else:
i -= 1
state = 11
elif state == 4: # while
if "".join(inputs[i:i + 4]) == 'hile':
if isDigit(inputs[i + 4]) or isLetter(inputs[i + 4]):
i -= 1
state = 11
else:
m = MyToken(4, "^", "while") # 在单词表和名字表加入
tokens.append(m)
state = 38
i += 3
else:
i -= 1
state = 11
elif state == 5: # break
if "".join(inputs[i:i + 4]) == 'reak':
if isDigit(inputs[i + 4]) or isLetter(inputs[i + 4]):
i -= 1
state = 11
else:
m = MyToken(5, "^", "break") # 在单词表和名字表加入
tokens.append(m)
state = 38
i += 3
else:
i -= 1
state = 11
elif state == 6: # return
if "".join(inputs[i:i + 5]) == 'eturn':
if isDigit(inputs[i + 5]) or isLetter(inputs[i + 5]):
i -= 1
state = 11
else:
m = MyToken(6, "^", "return") # 在单词表和名字表加入
tokens.append(m)
state = 38
i += 4
else:
i -= 1
state = 11
elif state == 7: # continue
if inputs[i] == 'o':
if "".join(inputs[i + 1:i + 7]) == 'ntinue':
if isDigit(inputs[i + 7]) or isLetter(inputs[i + 7]):
i -= 1
state = 11
else:
m = MyToken(7, "^", "continue") # 在单词表和名字表加入
tokens.append(m)
state = 38
i += 6
else:
i -= 1
state = 11
elif inputs[i] == 'h':
if "".join(inputs[i + 1:i + 3]) == 'ar':
if isDigit(inputs[i + 3]) or isLetter(inputs[i + 3]):
i -= 1
state = 11
else:
m = MyToken(10, "^", "char") # 在单词表和名字表加入
tokens.append(m)
state = 38
i += 2
else:
state = 11
i -= 1
else:
i -= 1
state = 11
elif state == 11: # 标识符
char = inputs[i]
i += 1
name += char
if isLetter(char):
state = 39
else:
state = 40
elif state == 12:
name += char
char = inputs[i]
if isDigit(inputs[i]): # 判断数字
i += 1
state = 12
else:
if inputs[i] == ' ' or inputs[i] == '\n' or inputs[i] == '\t' or inputs[i] == '#':
flag = 0
index = -1
for ii in range(len(ConstL)):
if ConstL[ii].MyStr == name:
flag = 1
index = ii
if flag == 1:
tokens.append(MyToken(12, index, name))
else:
ConstL.append(MyToken(12, len(ConstL), name))
tokens.append(MyToken(12, len(ConstL)-1, name))
else:
print(f"第{line}行---标识符错误")
char = inputs[i]
while char != ' ' and char != '\t' and char != '\n' and char != '#':
i += 1
char = inputs[i]
state = 38
i -= 1
elif state == 19: # 处理双字符
m = ""
if inputs[i] == '>' and inputs[i + 1] == '=':
m = MyToken(19, "^", ">=")
if inputs[i] == '<' and inputs[i + 1] == '=':
m = MyToken(21, "^", "<=")
if inputs[i] == '!' and inputs[i + 1] == '=':
m = MyToken(22, "^", "!=")
if inputs[i] == '=' and inputs[i + 1] == '=':
m = MyToken(23, "^", "==")
if inputs[i] == '&' and inputs[i + 1] == '&':
m = MyToken(25, "^", "&&")
if inputs[i] == '|' and inputs[i + 1] == '|':
m = MyToken(26, "^", "||")
if inputs[i] == '\\' and inputs[i + 1] == 'n':
m = MyToken(37, "^", "\\n")
tokens.append(m)
i += 1
return
elif state == 38: # 文件结束
return
elif state == 39: # 处理标识符
char = inputs[i]
i += 1
if char == '#':
i -= 1
state = 40
continue
if isDigit(char) or isLetter(char):
state = 39
if char != '\n':
name += char
else:
line += 1
else: # 不是字母和数字,就不是标识符了
state = 40
elif state == 40:
flag = 0
index = -1
for ii in range(len(NameL)):
if NameL[ii].MyStr == name:
flag = 1
index = ii
if flag == 1:
tokens.append(MyToken(11, index, name))
else:
NameL.append(MyToken(11, len(NameL), name))
tokens.append(MyToken(11, len(NameL)-1, name))
i -= 2 # 外面的while+1,所以这里要-1
if char == '#':
i += 1
try:
if states.index(char) and char != '#': # 如果有字符
name = name[:-1]
state = 41
except:
pass
return
elif state == 41:
st = states.index(char)
isC(char, st)
i -= 1
return
elif state == 42: # 处理注释 // /**/
if inputs[i] == '/': # //注释
i += 1
char = inputs[i]
while char != '\n':
i += 1
char = inputs[i]
i += 1
state = 0
pass
elif state in choiceStatec:
isC(states[state - 1], state) # 普通的字符识别
return
else:
pass
# 从文件读取内容
def readSourceCode(read_path):
with open(read_path, "r") as file:
lines = file.readlines()
return lines
# def sort_by_type(token):
# return token.MyType
# 将单词表输出到文件
def writeTokens(tokens,Name,Const):
with open("tokens.txt", "w") as file:
for token in tokens:
file.write(f"{token}\n")
with open("NameL.txt","w") as file:
for n in Name:
file.write(str(n)+"\n")
with open("ConstL.txt", "w") as file:
for c in Const:
file.write(str(c)+"\n")
if __name__ == '__main__':
read_path = 'source_code.txt'
sourceCodes = readSourceCode(read_path)
codeToInputs(sourceCodes)
while inputs[i] != '#':
nextToken()
i += 1
tokens.append(MyToken(38, "^", "#")) # 最后一个
writeTokens(tokens,NameL,ConstL)
"""
设置一个名字表NameL和常数表ConstL,当遇到标识符时,将其字符串送入名字表NameL,并把其名字表地址作为标识符的语义Seman值。
常数情形也一样,不要求翻译成二进制数。
要求在NameL和ConstL表中没有相同元素,同时具有简单的错误处理功能(找出源程序中所有存在的词法错误并指出错误所在的行数)。
试用高级程序设计语言编写一个针对下述单词集的词法分析器
"""
# 单词 编码 语义
# if 1 空(^)
# else 2 空(^)
# for 3 空(^)
# while 4 空(^)
# break 5 空(^)
# return 6 空(^)
# continue 7 空(^)
# float 8 空(^)
# int 9 空(^)
# char 10 空(^)
# 标识符 11 名字表地址
# 正整数 12 常数表地址
# 正实数 12 常数表地址
# 零 12 常数表地址
# + 13 空(^)
# - 14 空(^)
# * 15 空(^)
# / 16 空(^)
# % 17 空(^)
# > 18 空(^)
# >= 19 空(^)
# < 20 空(^)
# <= 21 空(^)
# != 22 空(^)
# == 23 空(^)
# ! 24 空(^)
# && 25 空(^)
# || 26 空(^)
# , 27 空(^)
# = 28 空(^)
# [ 29 空(^)
# ] 30 空(^)
# ( 31 空(^)
# ) 32 空(^)
# { 33 空(^)
# } 34 空(^)
# ; 35 空(^)
# . 36 空(^)
# 换行符 37 空(^)
# 文件结束 38 空(^)
运行
首先创建:source_code.txt
123 456 123
while ( i < 0 )
if i > 1
return
else
i += 1
for ( int i = 0 ; i <= 3 ; i += 1 )
flag += 1
if flag == 10
continue
int j = 0 ;
#
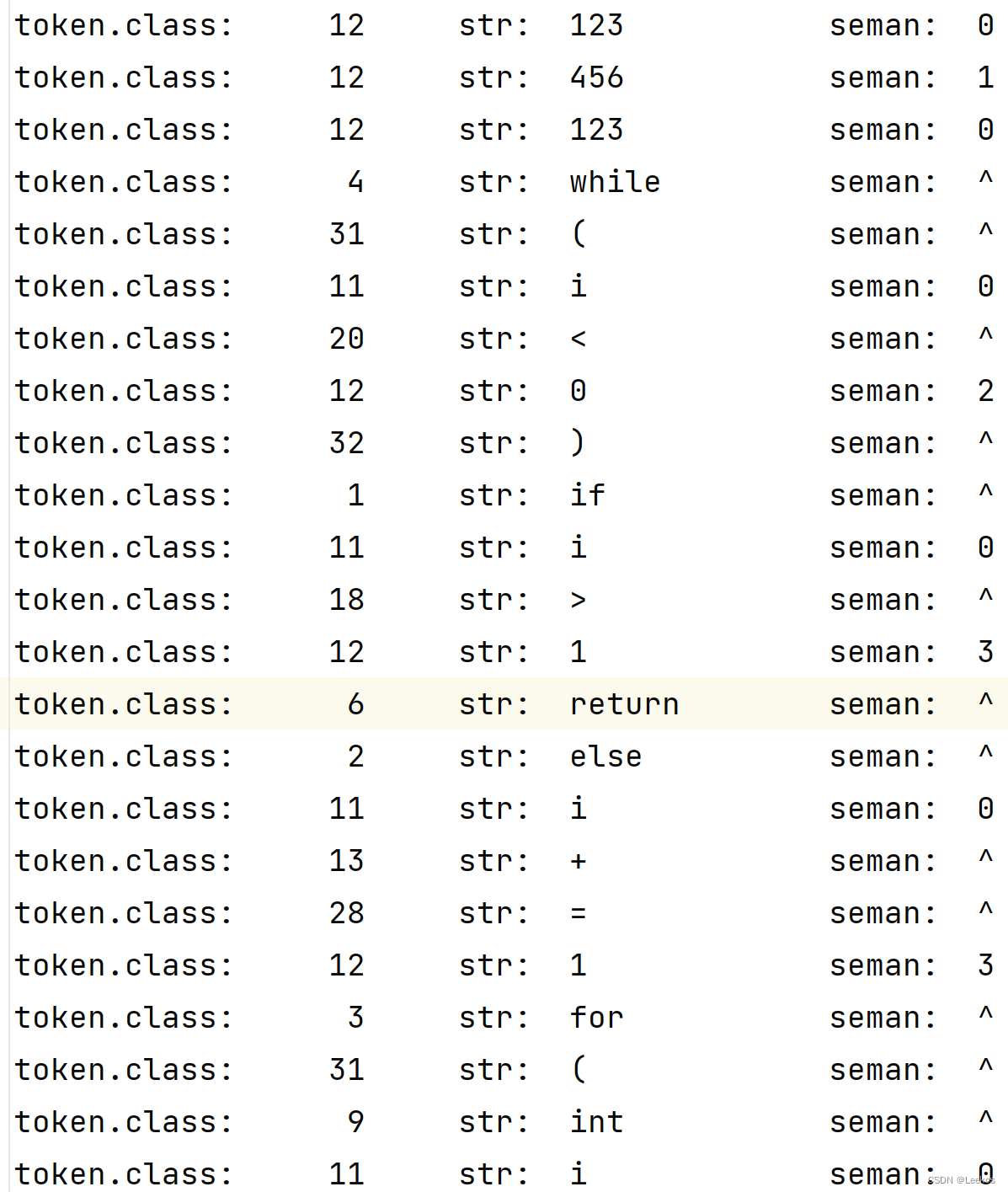
执行后,会在同目录下生成三个文件:
tokens.txt、NameL.txt、ConstL.txt
token.txt内容如下:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









