






背景介绍
近期老板发个任务,想要测试一下半精度下的GPU稀疏算力,探索了多个软件和脚本,包括DeepBench、GPU-Burn、Pytorch基准测试等,发现均不太好用;
找寻过程中发现一篇文章,发现想要简单快速又比较准的的测出实际峰值算力,可以使用CUTLASS profiler提供的GEMM算子进行测试,通常认为GEMM是计算受限的算子,且当下大热的Transformer模型负载基本上都是GEMM,故GEMM测得的最优性能可以被当作GPU的实际峰值算力,当然GEMM是通用矩阵,但查看官方文档,最新3.9.0版本内添加了稀疏矩阵的支持;

GitHub - NVIDIA/cutlass: CUDA Templates for Linear Algebra Subroutines)
克隆源码并且按照文档里的方法编译cutlass_profiler程序,使用方法见cutlass_profiler --help;
环境配置
首先准备我们的工具,使用的是NVIDIA提供的cutlass,这里大家可以复制到此代理网站中,添加上代理,来进行快速的下载:Github Proxy 文件代理加速
# https://github.com/NVIDIA/cutlass.git
git clone https://github.akams.cn/https://github.com/NVIDIA/cutlass.git

然后进入文件夹内,创建build文件夹
cd cutlass/
mkdir build && cd build
查看nvcc路径,并导入环境变量,之后就可以进行编译
开始测试
密集矩阵
- 4090测试时的CUTLASS编译选项-DCUTLASS_NVCC_ARCHS="89"
- H100测试时的CUTLASS编译选项-DCUTLASS_NVCC_ARCHS="90a"
- A10测试时的CUTLASS编译选项-DCUTLASS_NVCC_ARCHS="86"
- A100测试时的CUTLASS编译选项-DCUTLASS_NVCC_ARCHS="80"
接着配置一下github全局代理,编译时候要用到
git config --global url."https://github.moeyy.xyz/https://github.com/".insteadOf "https://github.com/"
开始进行编译
which nvcc
export CUDACXX=/usr/local/cuda/bin/nvcc
cmake .. -DCUTLASS_NVCC_ARCHS=89 -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc
注意,这里cmake版本要求3.19.3以上,因此版本不够则需要进行更新(注意需要提前删除原有版本,这里可以自行搜集下教程)
开始进行编译,注意此部分需要很长时间,耐心等待~
make cutlass_profiler -j16
./tools/profiler/cutlass_profiler --operation=Gemm --m=8192 --n=8192 --k=8192 --A=f16:column --B=f16:column --C=f16:column --beta=0,1,2 --profiling-iterations=1 --providers=cutlass --output=functional-test.csv
该命令用于使用CUTLASS库分析矩阵乘法(GEMM)的性能,验证FP16大矩阵乘法在不同 beta 值下的正确性或性能,适用于GPU计算优化或深度学习模型调优。参数解释如下:
【operation=Gemm】指定操作为通用矩阵乘法(GEMM),即计算 C = alpha*A*B + beta*C。
【m=8192、--n=8192、--k=8192】定义矩阵维度,测试大规模矩阵运算性能。
A的形状为M×K = 8192×8192B的形状为K×N = 8192×8192C的形状为M×N = 8192×8192
【A=f16:column、--B=f16:column、--C=f16:column】
f16:矩阵数据类型为半精度浮点(FP16),节省内存带宽并加速计算。column:列主序存储(与cuBLAS默认一致),内存中按列优先排列数据。
【beta=0,1,2】测试三种不同的 beta 值:
beta=0:结果C = alpha*A*B(忽略原C的值)。beta=1:结果C = alpha*A*B + C(累加到原C)。beta=2:结果C = alpha*A*B + 2*C(验证复杂计算路径)。
【profiling-iterations=1】每个配置仅运行1次迭代,快速验证功能或初步性能(非稳定性测试)。
【providers=cutlass】指定使用CUTLASS库实现,而非其他后端(如cuBLAS),CUTLASS是NVIDIA优化的矩阵计算模板库。
【output=functional-test.csv】将结果(如耗时、吞吐量)保存到CSV文件,便于后续分析。
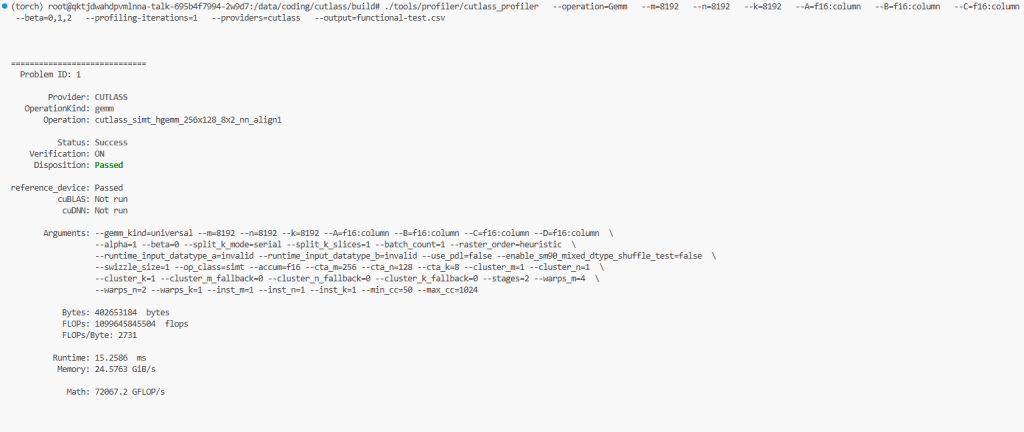
最终生成一个CSV文件
| Problem (Beta) | Operation | Runtime (ms) | GB/s | GFLOPs |
|---|---|---|---|---|
| 1 (β=0) | SIMT HGEMM | 15.2975 | 24.5138 | 71883.9 |
| 1 (β=0) | TensorOp F16 S1688 | 7.40659 | 50.6306 | 148469 |
| 1 (β=0) | TensorOp H1688 | 4.76467 | 78.7043 | 230792 |
| 1 (β=0) | TensorOp F16 S16816 | 6.31603 | 59.3727 | 174104 |
| 1 (β=0) | TensorOp H16816 | 3.43142 | 109.284 | 320463 |
| 2 (β=1) | SIMT HGEMM | 15.5003 | 32.2575 | 70943.6 |
| 2 (β=1) | TensorOp F16 S1688 | 7.48749 | 66.7781 | 146864 |
| 2 (β=1) | TensorOp H1688 | 5.0185 | 99.6314 | 219119 |
| 2 (β=1) | TensorOp F16 S16816 | 6.38157 | 78.3507 | 172316 |
| 2 (β=1) | TensorOp H16816 | 3.30051 | 151.492 | 333174 |
| 3 (β=2) | SIMT HGEMM | 15.4532 | 32.3558 | 71159.8 |
| 3 (β=2) | TensorOp F16 S1688 | 7.48339 | 66.8146 | 146945 |
| 3 (β=2) | TensorOp H1688 | 5.05574 | 98.8974 | 217504 |
| 3 (β=2) | TensorOp F16 S16816 | 6.38362 | 78.3255 | 172261 |
| 3 (β=2) | TensorOp H16816 | 3.30035 | 151.499 | 333190 |
稀疏矩阵(后续更新)
稀疏矩阵测试需要重新进行编译,在编译时候启动稀疏矩阵功能支持,如果未启用稀疏支持,相关内核会被跳过,当前官方是专门针对 Blackwell SM120a 架构的块缩放稀疏 GEMM(Block-Scaled Sparse GEMM)设计了单元测试,因此目前仅支持50系列显卡,还无法测试其他卡。



















 1180
1180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











