







论文:Mobility-Aware Cooperative Caching in Vehicular Edge Computing Based on Asynchronous Federated and DRL
JSTSP 2022 基于异步联邦和深度强化学习的车载边缘计算移动感知协同缓存
代码地址:论文代码
一、Introduction
background:
随着车联网(IoV)和云计算(Cloud Computing)的发展,缓存技术为车载用户(VU)提供了各种实时车辆应用,如自动导航、模式识别和多媒体娱乐。对于标准缓存技术,云缓存各种内容,如数据、视频和网页。车辆将所需内容传输到与云服务器相连的宏基站(MBS),从MBS中获取内容,由于车辆频繁请求内容造成通信拥塞,导致MBS到车辆的内容传输时延较高.车载边缘计算(VEC)可以有效降低内容传输时延,将内容缓存在部署在车载网络(VNs)边缘的路侧单元(RSU)中,车辆直接从本地 RSU 获取内容,减少内容传输延迟。在 VEC 中,本地 RSU 的缓存容量有限,如果车辆无法获取其所需的内容,则拥有所需内容的相邻 RSU 将它们转发到本地 RSU。最坏的情况是本地和相邻的 RSU 都没有缓存请求的内容,车辆需要从 MBS 获取内容。
在 VEC 中,设计一种缓存方案来缓存热门内容至关重要。传统的缓存方案根据历史请求缓存内容。由于VEC中车辆的高机动性特性,先前从车辆请求的内容可能会很快过时,传统的缓存方案无法满足VU的所有需求。因此要预测 VEC 中最受欢迎的内容,提前缓存在合适的 RSU 中。机器学习(ML)可以通过训练用户数据来提取隐藏的特征,有效地预测热门内容。然而,用户数据通常包含隐私信息,用户不愿意直接与他人分享他们的数据,这使得收集和训练用户的数据变得困难。联邦学习 (FL) 可以通过共享用户的本地模型而不是数据来保护用户的隐私 。在传统的联邦学习中,全局模型通过聚合所有车辆的本地模型来定期更新。然而,车辆在更新本地模型之前,可能会频繁地驶出VEC的覆盖区域,因此无法在同一区域上传本地模型,这将降低全局模型的准确性以及获取预测的热门内容的概率。异步联邦学习可以在不聚合所有车辆的局部模型的情况下进行,因此可以上传部分模型以提高全局模型的精度。车辆的移动性对异步联邦学习有很大影响。
预测的热门内容的大小通常会超过本地 RSU 的缓存容量。因此VEC 必须确定预测的热门内容在何处缓存和更新。内容传输时延是车辆提供实时车载应用的重要指标。本地和相邻的RSU中缓存的热门内容不同,会影响车辆获取内容的方式,从而影响内容传输的延迟。每辆车的内容传输时延都受其信道条件的影响,而信道条件又受车辆移动性的影响。因此需要考虑车辆的移动性来设计一种协同缓存方案,将预测的热门内容缓存在RSU之间,以优化内容传输时延。
Motivation:
解决车辆边缘计算(VEC)中缓存效率和传输延迟的问题。VEC在路边单元(RSU)中学习和缓存车辆用户(VU)最受欢迎的内容,降低传输延迟。传统基于历史请求的缓存方案难以适应车辆的高机动性,需要预测和缓存热门内容。传统联邦学习因车辆频繁移动而无法有效更新全局模型,导致预测热门内容的精度降低。异步联邦学习可以在不聚合所有局部模型的情况下提高全局模型的精度。考虑到RSU缓存容量有限,需优化热门内容的缓存位置以减少传输延迟。

Method:
- 异步联邦学习算法:提出一种考虑车辆位置和速度等移动特性的异步联邦学习算法,以提高全局模型的精度。
- 预测热门内容的算法:提出一种基于全局模型预测热门内容的算法。每辆车采用自动编码器(AE)预测基于全局模型的感兴趣内容,本地RSU收集覆盖区域内所有车辆的兴趣内容,以捕获热门内容。
- 深度强化学习框架:设计一个DRL框架(dueling deep Q-network,DQN)解决协同缓存问题。RSU根据dueling DQN算法确定最优的协同缓存策略,以最小化内容传输延迟。
联邦学习概述
2016年,联邦学习的概念由谷歌提出,其主要思想是基于分布在多个设备上的数据集构建机器学习模型,同时防止数据泄露。此外,数据按用户ID或设备ID的数据空间中是水平区分的。为扩展联邦学习概念以覆盖组织之间的协作学习场景,我们将原“联邦学习”扩展到所有保护隐私的分散式协作机器学习技术的一般概念。在本节中,提供了一个更全面的联邦学习定义,它考虑了数据分区、安全性和应用程序,还描述了联邦学习系统的工作流程和系统架构。
隐私=是联邦学习的基本属性之一,这需要安全模型和分析来提供有意义的隐私保证。比较一些联邦学习的不同隐私技术:
安全多方计算(SMC)
安全多方计算允许多个参与方在保持输入数据私密的情况下共同计算函数,并仅揭示计算结果。这种方法提供了强的隐私保障,但实现复杂且计算开销较大。
差分隐私
差分隐私通过在数据中加入噪声或使用泛化技术,确保数据在泄露后无法恢复到个人身份,从而保护用户隐私。然而,这种方法通常需要在隐私保护和数据准确性之间进行权衡。
同态加密
同态加密允许在加密数据上进行计算,保护数据隐私而无需解密。这种方法减少了数据泄露的风险,但计算开销较大,并可能影响模型的准确性。
二、SYSTEM MODEL
考虑城市场景中的三层 VEC,该场景由本地 RSU、相邻 RSU、连接云的 MBS 和在 RSU 覆盖区域内行驶的一些车辆组成。顶层是部署在 VEC 中心的 MBS,而中间层是部署在 MBS 覆盖区域内的 RSU,放置在道路侧。底层是在 RSU 的覆盖区域内行驶的车辆。
每辆车都存储了大量的VU的历史数据,即本地数据。每个数据都是反映 VU 不同信息的向量,包括 VU 的个人信息,例如身份证 (ID) 号码、性别、年龄和邮政编码、VU 可能请求的内容,以及 VU 对内容的评级,对内容的评级越大表明 VU 对内容更感兴趣。内容的评级为0即它不受欢迎或未被 VU 请求。每辆车随机选择一部分本地数据形成训练集,其余部分作测试集。每轮每辆车从测试集随机选择内容作为请求的内容,将请求信息发送到本地 RSU。MBS缓存所有可用内容,每个RSU容量有限。车辆在不同条件下从本地 RSU、相邻 RSU 或 MBS 获取每个请求的内容。具体说来
1) 本地 RSU
如果请求的内容缓存在本地 RSU 中,则本地 RSU 会将请求的内容发送回车辆。在这种情况下,车辆从本地 RSU 获取内容。
2) 邻近的 RSU
如果请求的内容未缓存在本地 RSU 中,则本地 RSU 会将请求传输到相邻的 RSU,而相邻的 RSU 会将内容发送到本地 RSU(如果它缓存了请求的内容)。之后,本地 RSU 将内容发送回车辆。在这种情况下,车辆从相邻的 RSU 获取内容。
3) MBS
如果内容既未缓存在本地 RSU 中,也未缓存在相邻 RSU 中,则车辆会向 MBS 发送请求,MBS 直接将请求的内容发送回车辆。在这种情况下,VU 从 MBS 获取内容。

B. 车辆的移动性模型

为每个车辆生成速度、距离等初始参数:select_vehicle.py
def select_vehicle_mobility(client_num):
#each vehicle distance
#the coverage of RSU 1000m
dis_round=1000#每个 RSU 的覆盖范围为 1000 米
vehicle_dis=np.zeros(client_num)#每辆车的初始距离
#vehicle speed 截断高斯分布
mu, sigma = 55,2.5#符合一个截断的正态分布(或高斯分布)
lower, upper = mu - 2 * sigma, mu + 2 * sigma # 截断在[μ-2σ, μ+2σ]
# 生成截断正态分布的速度
x=stats.truncnorm((lower - mu) / sigma, (upper - mu) / sigma, loc=mu, scale=sigma)
veh_speed=x.rvs(client_num)#根据截断正态分布生成每辆车的速度
for i in range(len(veh_speed)):
veh_speed[i]=veh_speed[i]*0.278
print("each vehicle's speed:",veh_speed)
# veh_age=np.true_divide(dis_round-veh_dis,veh_speed)
# print("each vehicle's remaining time:",veh_age)
all_pos_weight=[]#每个车辆的位置权重
#sel_turn={}
for i in range(client_num):
all_pos_weight.append(dis_round/dis_round)
return all_pos_weight, veh_speed, vehicle_dis
C.通信模型
VEC中的多辆车采用正交频分复用(OFDM)技术与RSU通信,在通信模型中不考虑干扰。本地RSU和相邻RSU之间的通信采用有线链路。每辆车在一轮中保持相同的通信模型,并针对不同的轮次更改其通信模型。

1、信道增益计算:
信道增益(或路径损耗)是在 Environ 类的 renew_channel 函数中计算的。
renew_channel 函数通过调用 V2Ichannels 类的 get_path_loss 和get_path_loss_mbs 方法,分别为 RSU 和 MBS 计算路径损耗。
同时,通过调用 get_shadowing 方法更新阴影衰落,从而计算得到完整的信道增益(V2I_channels_abs 和 V2I_channels_abs_mbs)。
self.V2I_Shadowing = self.V2Ichannels.get_shadowing(self.delta_distance, self.V2I_Shadowing)
for i in range(number_vehicle):
self.V2I_pathloss[i] = self.V2Ichannels.get_path_loss(veh_dis[i])
self.V2I_pathloss_mbs[i] = self.V2Ichannels.get_path_loss_mbs(veh_dis[i])
self.V2I_channels_abs = self.V2I_pathloss + self.V2I_Shadowing
self.V2I_channels_abs_mbs = self.V2I_pathloss_mbs + self.V2I_Shadowing
调用的V2Ichannels 类的方法:
def get_path_loss_mbs(self, position):
distance=0
if self.BS_position[0]<position<self.BS_position[1]:
distance = position - self.BS_position[0]
if self.BS_position[1]<position<self.BS_position[2]:
distance = position - self.BS_position[1]
if position>self.BS_position[2]:
distance = position - self.BS_position[2]
#128.1+37.6log10(d)
return 128.1 + 37.6 * np.log10(
math.sqrt((4*distance) ** 2 + (self.h_bs - self.h_ms) ** 2) / 1000) # + self.shadow_std * np.random.normal()
def get_shadowing(self, delta_distance, shadowing):
nVeh = len(shadowing)
return np.multiply(np.exp(-1 * (delta_distance / self.Decorrelation_distance)), shadowing) \
+ np.sqrt(1 - np.exp(-2 * (delta_distance / self.Decorrelation_distance))) * np.random.normal(0, 8, nVeh)
2、传输速率计算:
传输速率的计算发生在 Compute_Performance_Train 和 Compute_Performance_Train_mobility 函数中。
通过信道增益和噪声功率密度的比值来计算信号强度(platoon_V2I_Signal 和 platoon_V2I_Signal_mbs)。
然后根据香农定理,通过公式 log2(1 + SINR) 计算车辆与 RSU 和 MBS 的传输速率。
V2I_Rate = np.log2(1 + np.divide(self.platoon_V2I_Signal, self.sig2))
V2I_Rate_mbs = np.log2(1 + np.divide(self.platoon_V2I_Signal_mbs, self.sig2))
self.interplatoon_rate = V2I_Rate * self.bandwidth
self.interplatoon_rate_mbs = V2I_Rate_mbs * self.bandwidth_mbs
三、协同缓存方案
提出一种协作缓存方案来优化每一轮r中的内容传输延迟。首先提出异步 FL 算法来保护 VU 的信息并获得准确的模型。然后提出基于获得的模型来预测流行内容的算法。最后提出基于 DRL 的算法,根据预测确定最佳协作缓存流行内容。

A.异步联邦学习
如上图所示,传统的同步FL(右),本地 RSU 等待所有车辆上传其本地模型并聚合所有本地模型来更新全局模型。然后每辆车从本地RSU下载更新后的模型。相比之下,对于异步FL(左),每上传成功一个本地模型,本地RSU都会聚合并更新其全局模型。
文章考虑车辆移动性在VEC中提出一种异步FL算法,该算法由5步组成:

选择车辆:
车辆的移动性:
通过 select_vehicle_mobility 函数生成车辆的移动性参数(包括车辆的权重、速度和位置),并在每轮训练后更新车辆的位置和速度。
all_pos_weight, veh_speed, veh_dis = select_vehicle_mobility(args.clients_num)
time_slow = 0.1
veh_dis, veh_speed ,all_pos_weight = vehicle_p_v_mobility(veh_dis , epoch_time, args.clients_num, idx, args.clients_num)
通信环境初始化与更新:
使用 Environ 类模拟 C-V2X 的通信环境,并初始化车辆的位置和速度。每一轮训练结束后,都会更新信道的慢衰落和快衰落参数。
env.new_random_game(veh_dis, veh_speed) # initialize parameters in env
env.renew_channel(args.clients_num, veh_dis, veh_speed) # update channel slow fading
env.renew_channels_fastfading() # update channel fast fading
下载模型
1、初始化:
在训练过程开始时,创建一个全局模型 (global_model),并将其复制到每个车辆的模型中,存储在 vehicle_model_dict 列表中。这个全局模型是每个客户端本地模型的起始点。
global_model = AutoEncoder(int(max(data_set[:, 1])), 100)
# 将全局模型复制到每辆车中
for i in range(args.clients_num):
vehicle_model_dict[i].append(copy.deepcopy(global_model))
2、下载和更新:
在每一轮训练中,每个客户端首先从 vehicle_model_dict 中获取其本地模型,然后在本地进行训练。训练完成后,客户端将更新后的模型权重发送回中央服务器。
在每轮结束时,你会将所有客户端的本地模型权重加权平均,得到更新后的全局模型权重,并将这些权重更新到 global_model 中。
# 更新全局模型权重
global_weights_avg = average_weights(local_weights_avg)
global_model.load_state_dict(global_weights_avg)


本地模型的初始化:
-
在每一轮训练开始时,从 vehicle_model_dict 中获取当前车辆的本地模型副本。 本地训练:
-
在本地进行训练,并更新模型权重。每个车辆都使用自己的数据集进行训练,更新后的模型权重会被保存起来。 权重更新:
-
在一轮训练结束时,所有车辆的本地权重被加权平均,得到新的全局模型权重,然后更新到 global_model 中。
本地训练代码:
for veh in range(15):
#对同一辆车(通过 idx % args.clients_num 选择的)的数据进行了15次重复更新
#使用每辆车的本地数据(users_group_train)训练
local_model = LocalUpdate(args=args, dataset=data_set,
idxs=users_group_train[idx % args.clients_num])
# 更新本地模型权重,并将更新的权重存储起来
w, loss, local_net = local_model.update_weights(
model=local_net, client_idx=idx % args.clients_num + 1, global_round=idx + 1)
local_weights_avg.append(copy.deepcopy(w))
# update global weights将本轮次所有车辆的本地权重加权平均,得到全局模型的更新权重
global_weights_avg = average_weights(local_weights_avg)
# update global weights更新全局模型的参数
global_model.load_state_dict(global_weights_avg)

异步联邦学习整体算法:

代码:
v2i_rate_all = []
v2i_rate_mbs_all = []
idx = 0
# 开始时间
start_time = time.time()
# args & 输出实验参数
args = args_parser()
exp_details(args)
# gpu or cpu
if args.gpu: torch.cuda.set_device(args.gpu)
device = 'cuda' if args.gpu else 'cpu'
# 样本数据、训练集、测试集、请求内容和每轮车辆请求数
# load sample users_group_train users_group_test训练和测试数据集
sample, users_group_train, users_group_test, request_content, vehicle_request_num = sampling_mobility(args,
args.clients_num)
print('different epoch vehicle request num', vehicle_request_num)
data_set = np.array(sample)
# test_dataset & test_dataset_idx
test_dataset_idxs = []
for i in range(args.clients_num):#遍历所有客户端
test_dataset_idxs.append(users_group_test[i])#每个客户端对应的测试集索引
test_dataset_idxs = list(chain.from_iterable(test_dataset_idxs))#包含所有测试集数据的索引列表
test_dataset = data_set[test_dataset_idxs]#提取出对应的数据集,形成最终的测试数据集
request_dataset = []
for i in range(args.epochs):
request_dataset_idxs = []
request_dataset_idxs.append(request_content[i])
request_dataset_idxs = list(chain.from_iterable(request_dataset_idxs))#将嵌套的请求索引列表展平为一个一维列表
request_dataset.append(data_set[request_dataset_idxs])#每个元素对应一轮训练中的请求数据集
#生成车辆的移动性参数 包括车辆的权重、速度和位置
all_pos_weight, veh_speed, veh_dis = select_vehicle_mobility(args.clients_num)
time_slow = 0.1#仿真时间以实际时间的十分之一进行
# c-v2x simulation parameters:(车辆与基础设施)通信的最低数据速率要求
V2I_min = 100 # minimum required data rate for V2I Communication
bandwidth = int(540000)#V2V(车辆之间通信)的带宽
bandwidth_mbs = int(1000000)#蜂窝通信(C-V2X)带宽
# 客户端数量、V2I通信的最低数据速率、V2V通信带宽和蜂窝通信带宽
env = Environ(args.clients_num, V2I_min, bandwidth, bandwidth_mbs)
# 初始化车辆的位置和速度
env.new_random_game(veh_dis, veh_speed) # initialize parameters in env
# build model全局自编码器模型global_model,用于缓存数据的压缩和恢复
global_model = AutoEncoder(int(max(data_set[:, 1])), 100)
V2Ichannels = V2Ichannels()#V2I通信信道的初始化
# Set the model to train and send it to device.
global_model.to(device)
global_model.train()
vehicle_model_dict = [[], [], [], [], [], [], [], [], [], [], [], [], []
, [], [], [], [], [], [], []]#存储每辆车的模型
for i in range(args.clients_num):
#遍历每辆车,将全局模型的深拷贝添加到中的对应位置
vehicle_model_dict[i].append(copy.deepcopy(global_model))
# copy weights全局模型的权重状态
global_weights = global_model.state_dict()
# all epoch weights字典,键是epochs,值是对应轮次的模型权重列表
w_all_epochs = dict([(k, []) for k in range(args.epochs)])
# Training loss每轮训练的损失值
train_loss = []
# each epoch train time
each_epoch_time=[]
each_epoch_time.append(0)
vehicle_leaving=[]#记录在训练过程中离开网络的车辆
# 记录每轮次的 V2I(车辆到基础设施)通信速率和蜂窝带宽通信速率
v2i_rate_epoch=dict([(k, []) for k in range(args.epochs)])
v2i_rate_mbs_epoch = dict([(k, []) for k in range(args.epochs)])
cache_efficiency_list=[]#每轮次的缓存效率
cache_efficiency_without_list=[]#没有缓存策略时的效率
request_delay_list=[]#每轮次的请求延迟
while idx < args.epochs:
# 开始
print(f'\n | Global Training Round : {idx + 1} |\n')
global_model.train()
# 本地模型 用于在本轮次中进行本地训练
local_net = copy.deepcopy(vehicle_model_dict[idx % args.clients_num][-1])
local_net.to(device)
# v2i rate计算车辆间的V2I(车辆到基础设施)通信速率和MBS(主基站)通信速率
v2i_rate, v2i_rate_mbs = env.Compute_Performance_Train_mobility(args.clients_num)
v2i_rate_mbs_all.append(v2i_rate_mbs)
v2i_rate_all.append(v2i_rate)
print('v2i rate', v2i_rate)
print('v2i rate mbs', v2i_rate_mbs)
v2i_rate_epoch[idx] = v2i_rate
v2i_rate_mbs_epoch[idx] = v2i_rate_mbs
v2i_rate_weight = v2i_rate / max(v2i_rate)#基于最大通信速率对每辆车的速率进行归一化
print('vehicle position', veh_dis)
print('vehicle speed', veh_speed)
print("vehicle ", idx % args.clients_num + 1, " start synchronous training for ", args.local_ep)
epoch_start_time = time.time()
local_weights_avg=[]
for veh in range(15):
#对同一辆车(通过 idx % args.clients_num 选择的)的数据进行了15次重复更新
#使用每辆车的本地数据(users_group_train)训练
local_model = LocalUpdate(args=args, dataset=data_set,
idxs=users_group_train[idx % args.clients_num])
# 更新本地模型权重,并将更新的权重存储起来
w, loss, local_net = local_model.update_weights(
model=local_net, client_idx=idx % args.clients_num + 1, global_round=idx + 1)
local_weights_avg.append(copy.deepcopy(w))
# update global weights将本轮次所有车辆的本地权重加权平均,得到全局模型的更新权重
global_weights_avg = average_weights(local_weights_avg)
# update global weights更新全局模型的参数
global_model.load_state_dict(global_weights_avg)
epoch_time = time.time() - epoch_start_time
each_epoch_time.append(epoch_time)
# 每轮次的全局模型权重
w_all_epochs[idx] = global_weights_avg['linear1.weight'].tolist()
B.流行的内容预测
提出一种预测流行内容的算法。流行的内容预测算法由4个步骤组成:


对应部分代码: 根据用户行为和相似度来为活跃用户生成推荐列表代码:
推荐电影列表生成:
- recommend_movies_c500 用于存储每辆车(客户端)推荐的电影列表。
对于每辆车,首先提取测试数据集 (test_dataset_i) 并转换为用户-电影矩阵 (user_movie_i)。 - 使用 recommend 函数基于用户-电影矩阵和全局模型的权重 (w_all_epochs[idx]) 生成推荐列表。
- count_top_items 函数从推荐列表中选择前 int(2.5 * cache_size) 个电影,生成最终的推荐电影列表。
推荐电影列表聚合:
- 将每辆车的推荐电影列表 recommend_movies_c500 聚合,传递给缓存环境 CacheEnv,用于后续的强化学习训练。
recommend_movies_c500 = []#通过推荐算法生成每辆车的推荐电影列表
for i in range(args.clients_num):
vehicle_seq = i
test_dataset_i = data_set[users_group_test[vehicle_seq]]
user_movie_i = convert(test_dataset_i, max(sample['movie_id']))
recommend_list = recommend(user_movie_i, test_dataset_i, w_all_epochs[idx])
recommend_list500 = count_top_items(int(2.5 * cache_size), recommend_list)
recommend_movies_c500.append(list(recommend_list500))
# AFPCC将推荐电影列表 recommend_movies_c500 进行聚合,输入到缓存环境env_rl中,用于DRL训练
recommend_movies_c500 = count_top_items(int(2.5 * cache_size), recommend_movies_c500)
调用的recommend函数:user_cluster_recommend.py
def recommend(user_movie, test_dataset, weights):
"""
:param user_movie: user-movie-rating 第一列用户id,1682个电影,最后三列为用户信息(和test_dataset最后三列信息一样),12个用户
:param weights: model模型权重,用于计算用户的电影偏好相似度
:param test_dataset: 第i个client的测试集矩阵 14个client
,user_num*6(['user_id', 'movie_id', 'rating', 'gender', 'age', 'occupation'],
:return:recommend_list: 电影的推荐列表
user_movie 里面的user_id 和 test_dataset 里面的user_id是一样的,只不过test_dataset里面一个用户可能看了多个电影
"""
# 计算user_movie_cos
# user_movie_cos 是user_movie经过压缩得到的
weights = np.array(weights)
#用户的电影评分与权重矩阵的点积,前面的列代表用户对电影的压缩评分,最后三列保留用户信息(性别、年龄、职业)
user_movie_cos = np.zeros((user_movie.shape[0], weights.shape[0] + 3)) # 用户数 * 100
user_movie_cos[:, [-3, -2, -1]] = user_movie[:, [-3, -2, -1]] # 用户数 * 103
user_movie_cos[:, 0:-3] = np.dot(user_movie[:, 1:-3], weights.T) # 用户数 * 103
# 得到第i个用户的测试集中的电影
#统计用户活跃度:统计test_dataset中每个用户的出现次数,即用户对不同电影的评分次数
user_in_dataset = test_dataset[:, 0].astype(np.uint16) # 第一列:用户id,用户可以多次评分
count = Counter(user_in_dataset)
# all_list: 用来保存一个client中每个用户所得到推荐列表的总和
all_list = []
# 遍历user id
# 设置活跃用户为访问最多的1/3
request_times = sorted(count.values()) # 用户活跃度排序
# 列表的长度就代表了所有用户活跃度的总和
active_times = request_times[int(len(request_times)/3*2)]
#为活跃用户生成推荐列表:
for (user_id, times) in count.items():
# 遍历测试集中的用户,得到他们的相似用户
# 活跃用户应该如何界定,是items多的用户吗,这个多应该如何界定
# 设置1/3的活跃用户
# 判断该用户的活跃度是否大于active活跃度
if times > active_times:#寻找与该用户最相似的一组用户
user_sim = get_user_cluster(user_id, user_movie, user_movie_cos)
# 得到用户的推荐10人,以及他们的推荐列表中最多的10个
#从这些相似用户的电影推荐列表中提取出最多的10个推荐电影,形成该用户的推荐列表
finallist = get_user_recommend(user_sim, test_dataset)
all_list.append(list(finallist))
return all_list
C.基于DRL的协同缓存——DRL框架
每个RSU的计算能力很强,协作缓存可以在短时间内确定。主要目标是找到一个基于DRL的最优协同缓存,以最小化内容传输延迟。接下来将制定 DRL 框架,然后介绍 DRL 算法

动作a(t)=1的代码:
代码未写action=0情况,也就是a(t)=0时无论本地还是相邻RSU,缓存位置都不变。
if action == 1:#缓存替换
if len((self.last_content))>=5:#从self.last_content随机选择5个替换缓存
replace_content = random.sample(list(self.last_content), 5)
count = 0#替换 self.state 的末尾元素
if count < 5:
self.state[-count - 1] = replace_content[count]
count += 1
else:#如果last_content少于5个,直接使用last_content替换self.state中的末尾内容
replace_content = self.last_content
count = 0
if count < 5:
self.state[-count-1]=replace_content[count]
count+=1
state1 = []
for i in range(len(self.popular_content)):
# 按照内容流行度进行排序
if self.popular_content[i] in self.state:
state1.append(self.popular_content[i])
self.state = state1
#根据新的缓存内容,重新计算当前流行内容中未被缓存的部分
last_content=[]
for i in range(len(self.popular_content)):
if self.popular_content[i] not in self.state:
last_content.append(self.popular_content[i])
self.last_content=last_content
if len(self.last_content)<=self.cache_size:#剩余的内容<=缓存大小
self.state2 = self.last_content#直接将 self.last_content 全部赋值给 RSU2
if len(self.last_content)>self.cache_size:#随机选择一部分内容填充 RSU2
self.state2 = random.sample(list(self.last_content), self.cache_size)

奖励的计算:
# 奖励和请求延迟的计算
reward=0
request_delay=0
for i in range(len(vehicle_epoch)):
vehicle_idx=vehicle_epoch[i]
#奖励函数基于缓存效率和请求延迟来计算
#本地 RSU 的缓存效率、邻近 RSU 的缓存效率以及回落到基站(MBS)时的性能
reward += cache_efficiency * math.exp(-0.0001 * 8000000 / v2i_rate[vehicle_idx]) * vehicle_request_num[vehicle_idx]
reward += cache_efficiency2 * math.exp(-0.0001 * 8000000 / v2i_rate[vehicle_idx]
-0.4 * 8000000 / 15000000) * vehicle_request_num[vehicle_idx]
reward += (1-cache_efficiency-cache_efficiency2)\
* math.exp(- 0.5999 * 8000000 / (v2i_rate[vehicle_idx]/2))* vehicle_request_num[vehicle_idx]
# 本地 RSU 的延迟:缓存命中率*请求次数/车辆到基础设施的通信速率
request_delay += cache_efficiency * vehicle_request_num[vehicle_idx] / v2i_rate[vehicle_idx]*800
#邻近 RSU 的延迟:邻近 RSU 的缓存命中率*(请求次数/车辆到基础设施的通信速率+相邻RSU->本地RSU时间)
request_delay += cache_efficiency2 * (
vehicle_request_num[vehicle_idx] / v2i_rate[vehicle_idx]+vehicle_request_num[vehicle_idx] / 15000000) *800
#MBS 的延迟:均未命中*(请求次数/MBS的速率(v2i_rate[vehicle_idx] / 2))
request_delay +=(1-cache_efficiency-cache_efficiency2)*(vehicle_request_num[vehicle_idx] / (v2i_rate[vehicle_idx]/2))*800
#print(i,'mbs delay',(vehicle_request_num[vehicle_idx] / v2i_rate_mbs[vehicle_idx]) *100000)
request_delay = request_delay/len(vehicle_epoch)*1000
C.基于DRL的协同缓存——DRL算法

对应代码:
##DDQN
cache_size=100#缓存大小
MAX_EPISODES = 30
MAX_STEPS = 200
BATCH_SIZE = 32
recommend_movies_c500 = []#通过推荐算法生成每辆车的推荐电影列表
for i in range(args.clients_num):
vehicle_seq = i
test_dataset_i = data_set[users_group_test[vehicle_seq]]
user_movie_i = convert(test_dataset_i, max(sample['movie_id']))
recommend_list = recommend(user_movie_i, test_dataset_i, w_all_epochs[idx])
recommend_list500 = count_top_items(int(2.5 * cache_size), recommend_list)
recommend_movies_c500.append(list(recommend_list500))
# AFPCC将推荐电影列表 recommend_movies_c500 进行聚合,输入到缓存环境env_rl中,用于DRL训练
recommend_movies_c500 = count_top_items(int(2.5 * cache_size), recommend_movies_c500)
# recommend_movies_c500 存放了推荐的电影;cache_size = 100
env_rl = CacheEnv(recommend_movies_c500,cache_size)
agent = DuelingAgent(env_rl,cache_size)
episode_rewards, cache_efficiency, request_delay = mini_batch_train(env_rl, agent, MAX_EPISODES, MAX_STEPS, BATCH_SIZE,
request_dataset[idx], v2i_rate,v2i_rate_mbs,
[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14], vehicle_request_num[idx])
cache_efficiency_list.append(cache_efficiency[-1])
cache_efficiency_without_list.append(cache_efficiency[0])
request_delay_list.append(request_delay[-1])
idx += 1
#更新车辆的位置和速度,并更新通信信道的慢衰落和快衰落参数
veh_dis, veh_speed ,all_pos_weight = vehicle_p_v_mobility(veh_dis , epoch_time, args.clients_num, idx, args.clients_num)
env.renew_channel(args.clients_num, veh_dis, veh_speed) # update channel slow fading
env.renew_channels_fastfading() # update channel fast fading
if idx == args.epochs:
cache_efficiency_list.insert(0, 0)
for i in range(len(cache_efficiency_list)):
cache_efficiency_list[i] *= 100
print('Cache hit radio',cache_efficiency_list)
cache_efficiency_without_list.insert(0, 0)
for i in range(len(cache_efficiency_without_list)):
cache_efficiency_without_list[i] *= 100
print('Cache hit radio without RL',cache_efficiency_without_list)
# 输出缓存命中率 cache_efficiency_list 和没有使用强化学习的缓存命中率
print('each_epoch_time',each_epoch_time)
print('request_delay',request_delay_list)
if idx > args.epochs:
break
Dueling DQN流程

对应代码:
class DuelingAgent:
#buffer size?
def __init__(self, env, c_s, learning_rate=0.01, gamma=0.99, buffer_size=10000):
self.env = env
self.c_s = c_s
self.learning_rate = learning_rate
self.gamma = gamma
self.replay_buffer = BasicBuffer(max_size=buffer_size)
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.model = DuelingDQN(self.c_s, 2).to(self.device)
self.optimizer = torch.optim.Adam(self.model.parameters())
self.MSE_loss = nn.MSELoss()
def get_action(self, state, eps=0.20):
state = torch.DoubleTensor(state).to(self.device)
qvals = self.model.forward(state)#前向传播得到当前状态的Q值
action = np.argmax(qvals.cpu().detach().numpy())
action_bound=[0,1]
if(np.random.randn() > eps):
action = random.sample(action_bound, 1)
action = action[0]
return action
return action
def compute_loss(self, batch):
states, actions, rewards, next_states = batch
states = torch.DoubleTensor(states).to(self.device)
actions = torch.LongTensor(actions).to(self.device)
rewards = torch.FloatTensor(rewards).to(self.device)
next_states = torch.DoubleTensor(next_states).to(self.device)
# 当前状态的Q值
curr_Q = self.model.forward(states).gather(1, actions.unsqueeze(1))
curr_Q = curr_Q.squeeze(1)
next_Q = self.model.forward(next_states)#下一状态的Q值
max_next_Q = torch.max(next_Q, 1)[0]
expected_Q = rewards.squeeze(1) + self.gamma * max_next_Q#根据贝尔曼方程计算期望Q值
# 使用MSE损失函数计算当前Q值和期望Q值之间的差异
loss = self.MSE_loss(curr_Q, expected_Q)
return loss
def update(self, batch_size):
for i in range(50):
batch = self.replay_buffer.sample(batch_size)
loss = self.compute_loss(batch)
#print("update loss ", loss)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def mini_batch_train(env, agent, max_episodes, max_steps, batch_size
,request_dataset, v2i_rate, v2i_rate_mbs,vehicle_epoch, vehicle_request_num):
episode_rewards = []
cache_efficiency_list=[]
cache_efficiency2_list = []
request_delay_list=[]
for episode in range(max_episodes):
state , _ , _= env.reset()
episode_reward = 0
# state 是前100个电影
for step in range(max_steps):
action = agent.get_action(state)
next_state, reward, cache_efficiency, cache_efficiency2, request_delay = env.step(action, request_dataset, v2i_rate,v2i_rate_mbs, vehicle_epoch, vehicle_request_num, step)
agent.replay_buffer.push(state, action, reward, next_state)
episode_reward += reward
#if len(agent.replay_buffer) > batch_size:
if len(agent.replay_buffer) % batch_size == 0:
agent.update(batch_size)
if step == max_steps-1:
episode_rewards.append(episode_reward)
print("Episode " + str(episode) + ": " + str(episode_reward))
cache_efficiency_list.append(cache_efficiency)
cache_efficiency2_list.append(cache_efficiency2)
request_delay_list.append(request_delay)
break
state = next_state
print(len(agent.replay_buffer.buffer))
# 30个episode的数据
return episode_rewards, cache_efficiency_list, request_delay_list
main_avg.py整体流程:
1. 初始化和数据准备
-
参数解析与设备设置:
- 解析命令行参数,并设置使用的计算设备(CPU或GPU)。
- 从命令行参数中获取配置,如客户端数量、训练轮次等。
-
数据加载:
- 使用
sampling_mobility函数加载样本数据、训练集、测试集和请求内容。 - 将数据集转换为测试数据集和每轮训练的请求数据集。
- 使用
-
车辆移动性参数:
- 使用
select_vehicle_mobility生成车辆的移动性参数,包括权重、速度和位置。
- 使用
2. 环境初始化
-
环境参数设置:
- 设置V2I(车辆到基础设施)和V2V(车辆之间)通信的带宽。
- 创建环境对象
Environ,并初始化车辆的位置和速度。
-
模型初始化:
- 初始化全局自编码器模型
AutoEncoder,用于缓存数据的压缩和恢复。 - 初始化V2I通信信道对象
V2Ichannels。
- 初始化全局自编码器模型
3. 联邦学习训练
-
模型复制和权重初始化:
- 将全局模型的深拷贝分配给每辆车,存储在
vehicle_model_dict中。 - 初始化全局模型的权重和权重存储字典
w_all_epochs。
- 将全局模型的深拷贝分配给每辆车,存储在
-
训练循环:
- 对于每轮训练(
idx从0到args.epochs-1):- 复制全局模型作为本地模型进行本地训练。
- 使用
LocalUpdate类进行本地模型更新。 - 聚合所有本地模型的权重,更新全局模型的权重。
- 计算并记录V2I和蜂窝通信的速率。
- 对于每轮训练(
4. 流行内容预测与缓存优化
-
推荐系统:
- 对每辆车的测试数据集进行推荐,生成推荐电影列表(
recommend_movies_c500)。 - 使用推荐列表更新缓存环境对象
CacheEnv。
- 对每辆车的测试数据集进行推荐,生成推荐电影列表(
-
强化学习训练:
- 使用Dueling DQN(
DuelingAgent)对缓存环境进行训练,优化缓存效率。 mini_batch_train函数执行强化学习训练,更新缓存策略,并记录缓存效率和请求延迟。
- 使用Dueling DQN(
5. 模型和结果评估
-
更新车辆移动性:
- 在每轮训练后更新车辆的位置和速度,并更新通信信道的慢衰落和快衰落参数。
-
结果输出:
- 在所有轮次结束后,计算和输出缓存命中率、没有使用强化学习的缓存命中率、每轮训练时间和请求延迟。
实验结果:
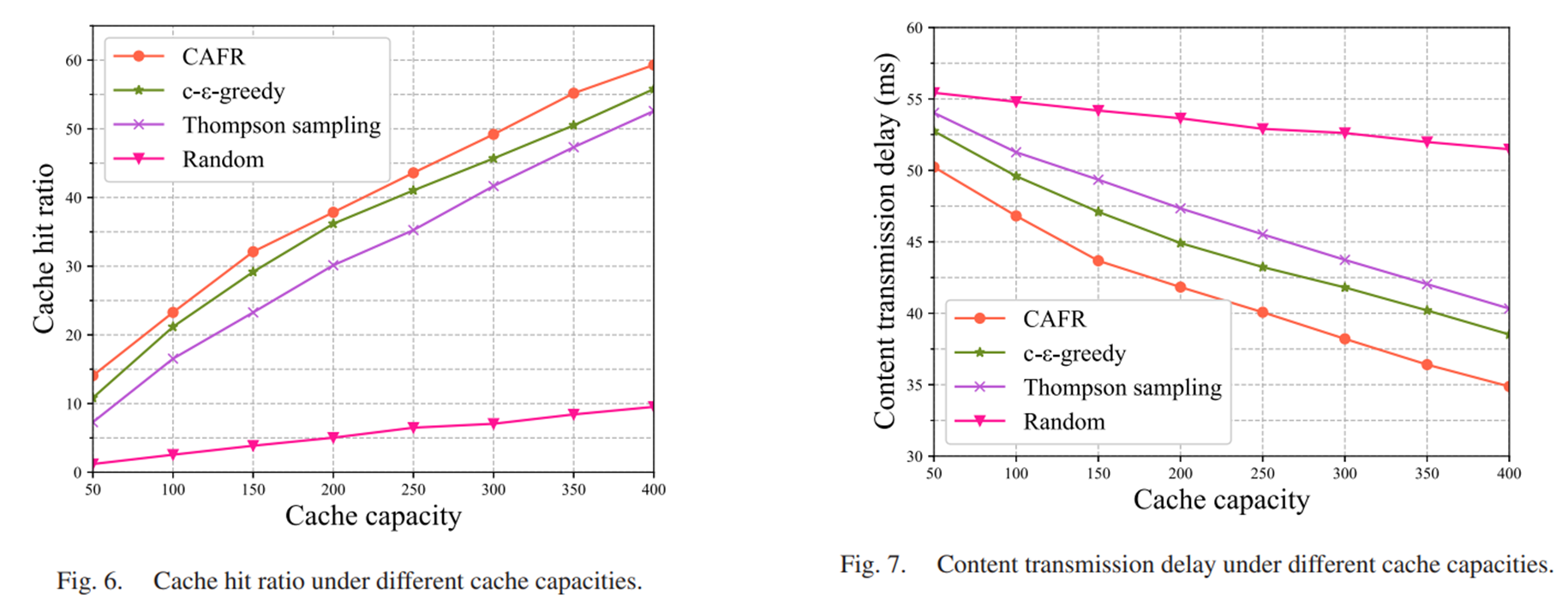
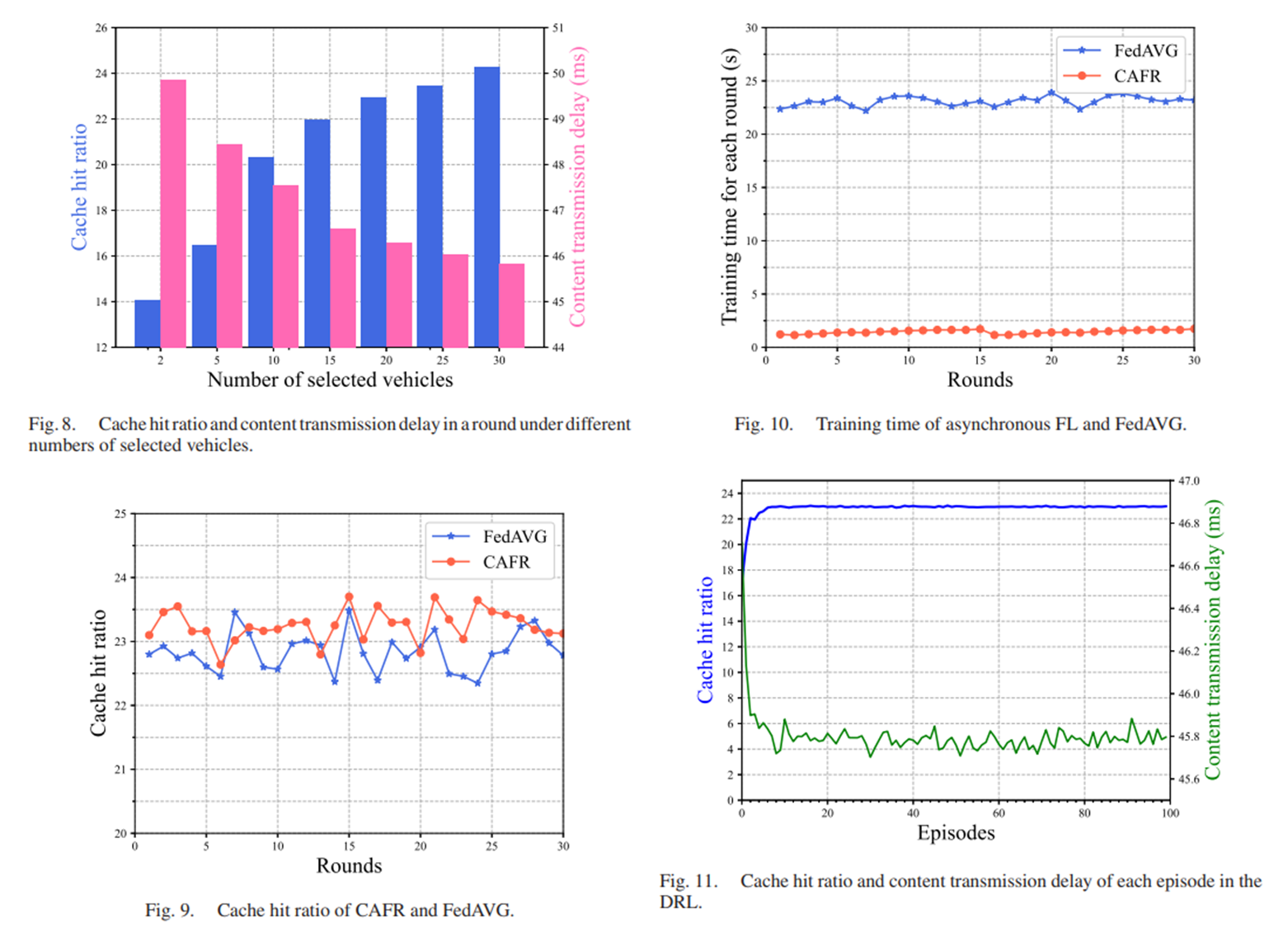
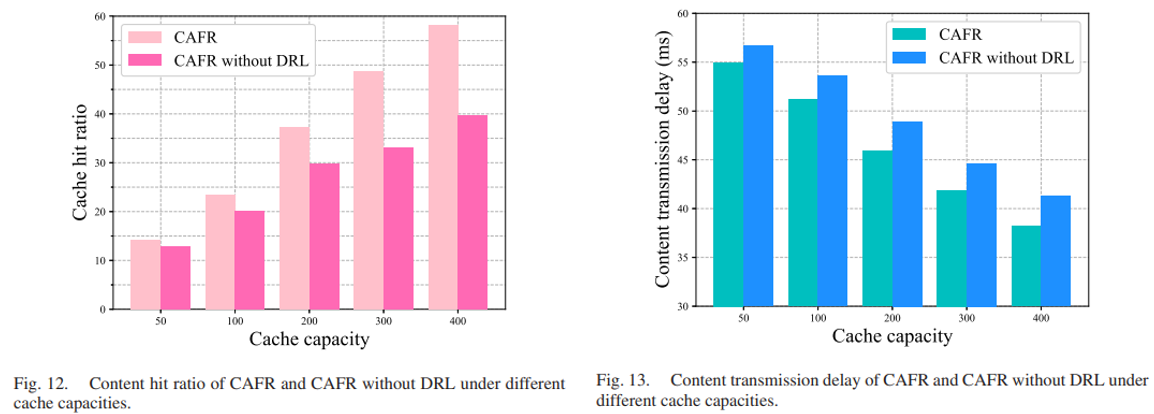


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









