






小铃铛的前言
不同于基础篇中使用的基础的机器学习算法,本章将使用深度学习算法对其进行优化。
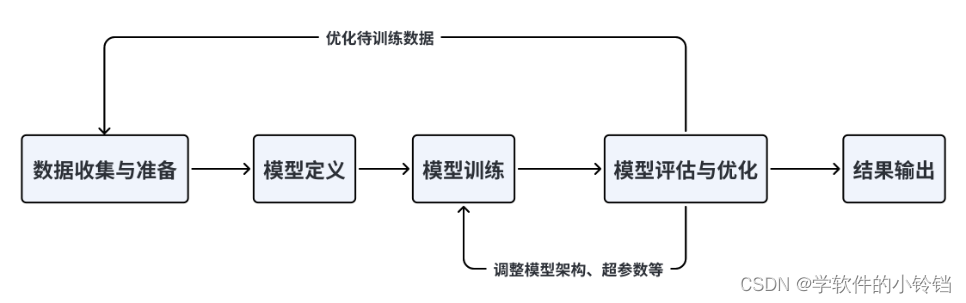
以下是深度学习运行的一般规律:
而之所以采用深度学习算法对其进行优化,是因为随着深度学习的发展,自2013年,神经网络词向量登上时代舞台,神经网络逐渐成为了 NLP 的核心方法,NLP 的核心研究范式逐渐向深度学习演化。以下是NLP算法的演进历程:
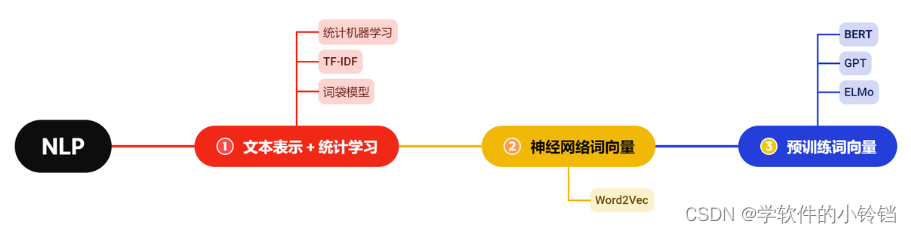
深度学习的研究方法,主要是通过多层的神经网络来端到端处理下游任务,将文本表示、特征工程、建模预测都融合在深度神经网络中,减少了人工特征构建的过程,显著提升了自然语言处理能力。神经网络词向量是其中的核心部分,即文本通过神经网络后的向量表示,这些向量表示能够蕴含深层语义且维度合适,后续研究往往可以直接使用以替代传统的文本表示方法,典型的应用如 Word2Vec (但只能处理静态情况,即对于每一个词有一个固定的向量表示,无法解决一词多义、复杂特征等问题)。
随着动态词向量需求的出现,“预训练+微调”范式应运而生。所谓预训练+微调范式,指先在海量文本数据上进行预训练,再针对特定的下游任务进行微调。预训练一般基于语言模型,即给定上一个词,预测下一个词。语言模型可以在所有文本数据上建模,无需人工标注,因此很容易在海量数据上进行训练。通过在海量数据上进行预训练,模型可以学习到深层的自然语言逻辑。再通过在指定的下游任务上进行微调,即针对部分人工标注的任务数据进行特定训练,如文本分类、文本生成等,来训练模型执行下游任务的能力。
下图给出了不同的遮盖情况,这些遮盖情况分别对应着需要解决的不同的问题。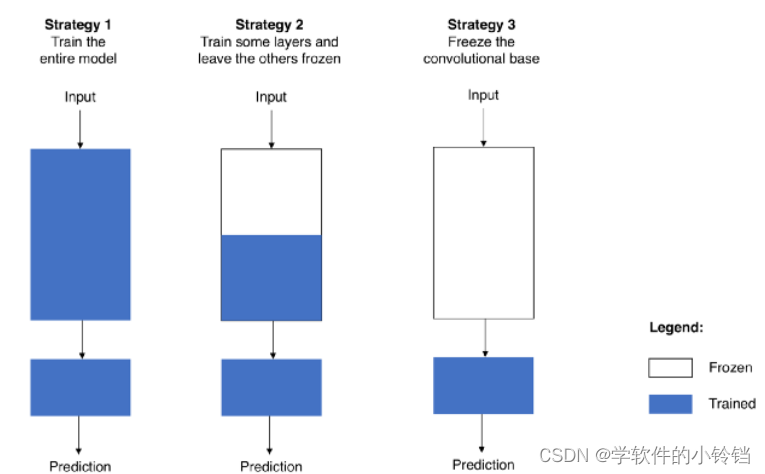
优点:一定程度上缓解了标注数据昂贵的问题,显著提升了模型性能
缺点:难以解决长期依赖、并行效果差的天生缺陷
一、理论知识部分
BERT模型介绍
BERT模型是一个经典的深度学习、预处理模型。该模型实现了包括 GLUE、MultiNLI 等七个自然语言处理评测任务的 the-state-of-art(最优表现),自 BERT 推出以来,预训练+微调的模式开始成为自然语言处理任务的主流,标志着各种自然语言处理任务的重大进展以及预训练模型的统治地位建立。
使用预训练的BERT模型进行建模的思路步骤如下:
- 数据预处理:首先,对文本数据进行预处理,包括文本清洗(如去除特殊字符、标点符号)、分词等操作。可以使用常见的NLP工具包(如NLTK或spaCy)来辅助进行预处理。
- 构建训练所需的dataloader与dataset,构建Dataset类时,需要定义三个方法
__init__,__getitem__,__len__,其中__init__方法完成类初始化,__getitem__要求返回返回内容和label,__len__方法返回数据长度- 构造Dataloader,在其中完成对句子进行编码、填充、组装batch等动作:
- 定义预测模型利用预训练的BERT模型来解决文本二分类任务,我们将使用BERT模型编码中的[CLS]向量来完成二分类任务
- 注:[CLS]向量可用于在单文本分类任务中,对于文本分类任务,BERT模型在文本前插入一个[CLS]符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类
Attention机制
Attention 机制的特点是通过计算 Query (查询值)与Key(键值)的相关性为真值加权求和,从而拟合序列中每个词同其他词的相关关系。其大致计算过程如图:
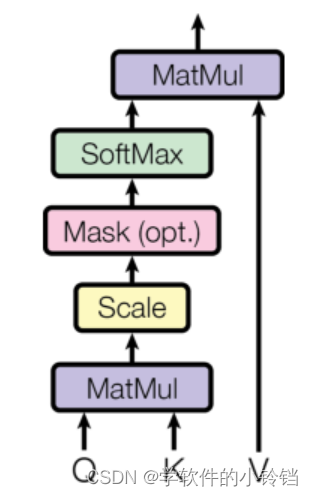
具体而言,可以简单理解为一个输入序列通过不同的参数矩阵映射为 Q、K、V 三个矩阵,其中,Q 是计算注意力的另一个句子(或词组),V 为待计算句子,K 为待计算句子中每个词的对应键。通过对 Q 和 K 做点积,可以得到待计算句子(V)的注意力分布(即哪些部分更重要,哪些部分没有这么重要),基于注意力分布对 V 做加权求和即可得到输入序列经过注意力计算后的输出,其中与 Q (即计算注意力的另一方)越重要的部分得到的权重就越高。
Transformer
Transformer 正是基于 Attention 机制搭建了 Encoder-Decoder(编码器-解码器)结构,主要适用于 Seq2Seq(序列到序列)任务,即输入是一个自然语言序列,输出也是一个自然语言序列。其整体架构如下:

由于是一个 Seq2Seq 任务,在训练时,Transformer 的训练语料为若干个句对,具体子任务可以是机器翻译、阅读理解、机器对话等。在原论文中是训练了一个英语与德语的机器翻译任务。在训练时,句对会被划分为输入语料和输出语料,输入语料将从左侧通过编码层进入 Encoder,输出语料将从右侧通过编码层进入 Decoder。Encoder 的主要任务是对输入语料进行编码再输出给 Decoder,Decoder 再根据输出语料的历史信息与 Encoder 的输出进行计算,输出结果再经过一个线性层和 Softmax 分类器即可输出预测的结果概率。
Bert的预训练任务(理解这一个很重要)
BERT 的模型架构直接使用了 Transformer 的 Encoder 作为整体架构,其最核心的思想在于提出了两个新的预训练任务——MLM(Masked Language Model,掩码模型)和 NSP(Next Sentence Prediction,下个句子预测),而不是沿用传统的 LM(语言模型)。
MLM 任务,是 BERT 能够深层拟合双向语义特征的基础。简单来讲,MLM 任务即以一定比例对输入语料的部分 token 进行遮蔽,替换为 (MASK)标签,再让模型基于其上下文预测还原被遮蔽的单词,即做一个完形填空任务。由于在该任务中,模型需要针对 (MASK) 标签左右的上下文信息来预测标签本身,从而会充分拟合双向语义信息。
例如,原始输入为 I like you。以30%的比例进行遮蔽,那么遮蔽之后的输入可能为:I (MASK) you。而模型的任务即为基于该输入,预测出 (MASK) 标签对应的单词为 like。
NSP 任务,是 BERT 用于解决句级自然语言处理任务的预训练任务。BERT 完全采用了预训练+微调的范式,因此着重通过预训练生成的模型可以解决各种多样化的下游任务。MLM 对 token 级自然语言处理任务(如命名实体识别、关系抽取等)效果极佳,但对于句级自然语言处理任务(如句对分类、阅读理解等),由于预训练与下游任务的模式差距较大,因此无法取得非常好的效果。NSP 任务,是将输入语料都整合成句对类型,句对中有一半是连贯的上下句,标记为 IsNext,一半则是随机抽取的句对,标记为 NotNext。模型则需要根据输入的句对预测是否是连贯上下句,即预测句对的标签。
例如,原始输入句对可能是 (I like you ; Because you are so good) 以及 (I like you; Today is a nice day)。而模型的任务即为对前一个句对预测 IsNext 标签,对后一个句对预测 NotNext 标签。
基于上述两个预训练任务,BERT 可以在预训练阶段利用大量无标注文本数据实现深层语义拟合,从而取得良好的预测效果。同时,BERT 追求预训练与微调的深层同步,由于 Transformer 的架构可以很好地支持各类型的自然语言处理任务,从而在 BERT 中,微调仅需要在预训练模型的最顶层增加一个 SoftMax 分类层即可。同样值得一提的是,由于在实际下游任务中并不存在 MLM 任务的遮蔽,因此在策略上进行了一点调整,即对于选定的遮蔽词,仅 80% 的遮蔽被直接遮蔽,其余将有 10% 被随机替换,10% 被还原为原单词。
二、一起来实操吧
(一)环境的配置
在此前使用机器学习对模型进行训练时,只使用本地的软件即可完成;但是由于深度学习会进行较之前更多轮的训练,因此建议使用服务器完成。
(PS:小铃铛最开始选择了本地运行,win11,python3.8,pytorch1.12,安装cpu版本,在深度学习不断迭代时,曾连续运行24h。cpu都要干烧了,但是cpu算力有限,一共只跑出了25/100的结果,如下图,且文件已经占用10G o(╥﹏╥)o)

PS:小铃铛曾使用过Google、华为、阿里云的免费服务器,分别用于学习pytorch、鲲鹏和linux,如果不想使用以下给出的阿里云教程或已有服务器的,可以跳过这一段。
咳咳,这里是白嫖阿里云教程!!!看过来!!!
阿里云机器学习Pai-DSW服务器部署教程![]() https://qwosdw576oc.feishu.cn/docx/NajfdyJm3oripXxrPFFczjSon4z简介一下环境:小铃铛认为,notebook界面主要用于上传文件,webide主要用于运行代码,terminal主要用于控制终端
https://qwosdw576oc.feishu.cn/docx/NajfdyJm3oripXxrPFFczjSon4z简介一下环境:小铃铛认为,notebook界面主要用于上传文件,webide主要用于运行代码,terminal主要用于控制终端
在配置以上内容的过程中,建议在配置GPU时使用第一个可选项。小铃铛曾在配置过程中使用第二个可选项,在运行代码时经常会出现cannot find pandas(不是原报错,但是类似句意),小铃铛试过很多办法,比如conda install pandas,你完全可以看到该环境下有pandas,但是无法使用,该问题一直没有被解决。如果解决了欢迎大家告诉我o(╥﹏╥)o
另外可能会碰到如下的一个问题:
(base) /mnt/workspace> conda run -n base --no-capture-output --live-stream python /mnt/workspace/second.py
Device: cuda
Traceback (most recent call last):
File "/home/pai/lib/python3.9/site-packages/transformers/utils/hub.py", line 409, in cached_file
resolved_file = hf_hub_download(
File "/home/pai/lib/python3.9/site-packages/huggingface_hub/utils/_validators.py", line 120, in _inner_fn
return fn(*args, **kwargs)
File "/home/pai/lib/python3.9/site-packages/huggingface_hub/file_download.py", line 1259, in hf_hub_download
raise LocalEntryNotFoundError(
huggingface_hub.utils._errors.LocalEntryNotFoundError: Connection error, and we cannot find the requested files in the disk cache. Please try again or make sure your Internet connection is on.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/mnt/workspace/second.py", line 92, in <module>
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
File "/home/pai/lib/python3.9/site-packages/transformers/models/auto/tokenization_auto.py", line 634, in from_pretrained
config = AutoConfig.from_pretrained(
File "/home/pai/lib/python3.9/site-packages/transformers/models/auto/configuration_auto.py", line 896, in from_pretrained
config_dict, unused_kwargs = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/home/pai/lib/python3.9/site-packages/transformers/configuration_utils.py", line 573, in get_config_dict
config_dict, kwargs = cls._get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/home/pai/lib/python3.9/site-packages/transformers/configuration_utils.py", line 628, in _get_config_dict
resolved_config_file = cached_file(
File "/home/pai/lib/python3.9/site-packages/transformers/utils/hub.py", line 443, in cached_file
raise EnvironmentError(
OSError: We couldn't connect to 'https://huggingface.co' to load this file, couldn't find it in the cached files and it looks like bert-base-uncased is not the path to a directory containing a file named config.json.
Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
ERROR conda.cli.main_run:execute(47): `conda run python /mnt/workspace/second.py` failed. (See above for error)
主要是提示无法下载bert-base-uncased模型。
该问题可以通过两个方法解决:
1.粗暴多次运行(在某教程中可以这样实现,小铃铛不确定这样是否可以,但是可以加以尝试)
2.可以点击链接前往网站

按照步骤进行输入。注意:不要选择HTTPS,选择SSH!!!否则会下载失败
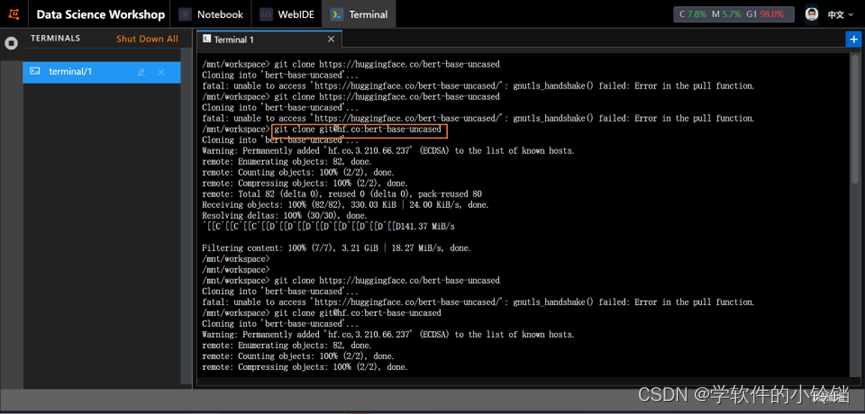
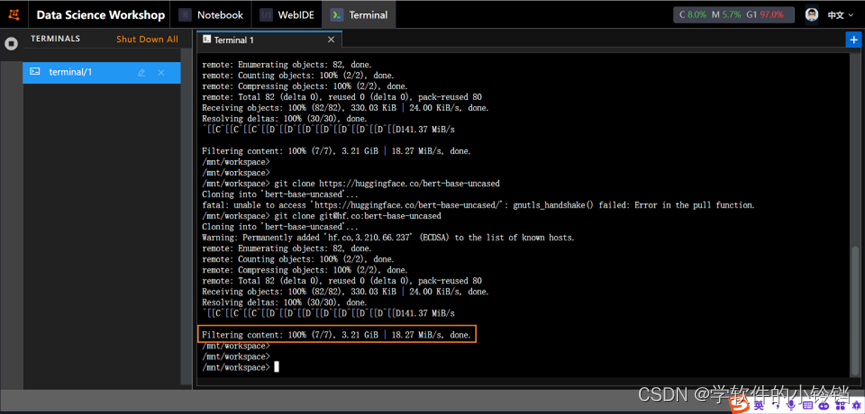
成功
另外,还有可能会碰到服务器打开之后完全黑屏的状况,如下所示:
不用担心,此时你可以点击F12进入开发者模式,如果在前端页面出现报错,则可以通过清除浏览器缓存来解决该问题。
(二)运行的代码
############################导入模块######################################################
#import 相关库
#导入前置依赖
import os
import pandas as pd
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
# 用于加载bert模型的分词器
from transformers import AutoTokenizer
# 用于加载bert模型
from transformers import BertModel
from pathlib import Path
############################设置全局配置##################################################
batch_size = 16
# 文本的最大长度
text_max_length = 128
# 总训练的epochs数,我只是随便定义了个数
epochs = 100
# 学习率
lr = 3e-5
# 取多少训练集的数据作为验证集
validation_ratio = 0.1
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 每多少步,打印一次loss
log_per_step = 50
# 模型存储路径
model_dir = Path("./model/bert_checkpoints")
# 如果模型目录不存在,则创建一个
os.makedirs(model_dir) if not os.path.exists(model_dir) else ''
print("Device:", device)
############################数据收集与准备################################################
# 读取数据集,进行数据处理
pd_train_data = pd.read_csv('data/train.csv')
pd_train_data['title'] = pd_train_data['title'].fillna('')
pd_train_data['abstract'] = pd_train_data['abstract'].fillna('')
test_data = pd.read_csv('data/testB.csv')
test_data['title'] = test_data['title'].fillna('')
test_data['abstract'] = test_data['abstract'].fillna('')
pd_train_data['text'] = pd_train_data['title'].fillna('') + ' ' + pd_train_data['author'].fillna('') + ' ' + pd_train_data['abstract'].fillna('')+ ' ' + pd_train_data['Keywords'].fillna('')
test_data['text'] = test_data['title'].fillna('') + ' ' + test_data['author'].fillna('') + ' ' + test_data['abstract'].fillna('')+ ' ' + pd_train_data['Keywords'].fillna('')
test_data['Keywords'] = test_data['title'].fillna('')
# 从训练集中随机采样测试集
validation_data = pd_train_data.sample(frac=validation_ratio)
train_data = pd_train_data[~pd_train_data.index.isin(validation_data.index)]
#############################构建训练所需的dataloader与dataset############################
# 构建Dataset
class MyDataset(Dataset):
def __init__(self, mode='train'):
super(MyDataset, self).__init__()
self.mode = mode
# 拿到对应的数据
if mode == 'train':
self.dataset = train_data
elif mode == 'validation':
self.dataset = validation_data
elif mode == 'test':
# 如果是测试模式,则返回内容和uuid。拿uuid做target主要是方便后面写入结果。
self.dataset = test_data
else:
raise Exception("Unknown mode {}".format(mode))
def __getitem__(self, index):
# 取第index条
data = self.dataset.iloc[index]
# 取其内容
text = data['text']
# 根据状态返回内容
if self.mode == 'test':
# 如果是test,将uuid做为target
label = data['uuid']
else:
label = data['label']
# 返回内容和label
return text, label
def __len__(self):
return len(self.dataset)
train_dataset = MyDataset('train')
validation_dataset = MyDataset('validation')
train_dataset.__getitem__(0)
#获取Bert预训练模型
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
#接着构造我们的Dataloader。
#我们需要定义一下collate_fn,在其中完成对句子进行编码、填充、组装batch等动作:
def collate_fn(batch):
"""
将一个batch的文本句子转成tensor,并组成batch。
:param batch: 一个batch的句子,例如: [('推文', target), ('推文', target), ...]
:return: 处理后的结果,例如:
src: {'input_ids': tensor([[ 101, ..., 102, 0, 0, ...], ...]), 'attention_mask': tensor([[1, ..., 1, 0, ...], ...])}
target:[1, 1, 0, ...]
"""
text, label = zip(*batch)
text, label = list(text), list(label)
# src是要送给bert的,所以不需要特殊处理,直接用tokenizer的结果即可
# padding='max_length' 不够长度的进行填充
# truncation=True 长度过长的进行裁剪
src = tokenizer(text, padding='max_length', max_length=text_max_length, return_tensors='pt', truncation=True)
return src, torch.LongTensor(label)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
validation_loader = DataLoader(validation_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
inputs, targets = next(iter(train_loader))
print("inputs:", inputs)
print("targets:", targets)
############################定义模型######################################################
#定义预测模型,该模型由bert模型加上最后的预测层组成
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
# 加载bert模型
self.bert = BertModel.from_pretrained('bert-base-uncased', mirror='tuna')
# 最后的预测层
self.predictor = nn.Sequential(
nn.Linear(768, 256),
nn.ReLU(),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, src):
"""
:param src: 分词后的推文数据
"""
# 将src直接序列解包传入bert,因为bert和tokenizer是一套的,所以可以这么做。
# 得到encoder的输出,用最前面[CLS]的输出作为最终线性层的输入
outputs = self.bert(**src).last_hidden_state[:, 0, :]
# 使用线性层来做最终的预测
return self.predictor(outputs)
model = MyModel()
model = model.to(device)
#定义出损失函数和优化器。这里使用Binary Cross Entropy:
criteria = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# 由于inputs是字典类型的,定义一个辅助函数帮助to(device)
def to_device(dict_tensors):
result_tensors = {}
for key, value in dict_tensors.items():
result_tensors[key] = value.to(device)
return result_tensors
#定义一个验证方法,获取到验证集的精准率和loss
def validate():
model.eval()
total_loss = 0.
total_correct = 0
for inputs, targets in validation_loader:
inputs, targets = to_device(inputs), targets.to(device)
outputs = model(inputs)
loss = criteria(outputs.view(-1), targets.float())
total_loss += float(loss)
correct_num = (((outputs >= 0.5).float() * 1).flatten() == targets).sum()
total_correct += correct_num
return total_correct / len(validation_dataset), total_loss / len(validation_dataset)
############################模型训练、评估################################################
# 首先将模型调成训练模式
model.train()
# 清空一下cuda缓存
if torch.cuda.is_available():
torch.cuda.empty_cache()
# 定义几个变量,帮助打印loss
total_loss = 0.
# 记录步数
step = 0
# 记录在验证集上最好的准确率
best_accuracy = 0
# 开始训练
for epoch in range(epochs):
model.train()
for i, (inputs, targets) in enumerate(train_loader):
# 从batch中拿到训练数据
inputs, targets = to_device(inputs), targets.to(device)
# 传入模型进行前向传递
outputs = model(inputs)
# 计算损失
loss = criteria(outputs.view(-1), targets.float())
loss.backward()
optimizer.step()
optimizer.zero_grad()
total_loss += float(loss)
step += 1
if step % log_per_step == 0:
print("Epoch {}/{}, Step: {}/{}, total loss:{:.4f}".format(epoch+1, epochs, i, len(train_loader), total_loss))
total_loss = 0
del inputs, targets
# 一个epoch后,使用过验证集进行验证
accuracy, validation_loss = validate()
print("Epoch {}, accuracy: {:.4f}, validation loss: {:.4f}".format(epoch+1, accuracy, validation_loss))
torch.save(model, model_dir / f"model_{epoch}.pt")
# 保存最好的模型
if accuracy > best_accuracy:
torch.save(model, model_dir / f"model_best.pt")
best_accuracy = accuracy
#加载最好的模型,然后进行测试集的预测
model = torch.load(model_dir / f"model_best.pt")
model = model.eval()
test_dataset = MyDataset('test')
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
############################结果输出######################################################
results = []
for inputs, ids in test_loader:
outputs = model(inputs.to(device))
outputs = (outputs >= 0.5).int().flatten().tolist()
ids = ids.tolist()
results = results + [(id, result) for result, id in zip(outputs, ids)]
test_label = [pair[1] for pair in results]
test_data['label'] = test_label
test_data['Keywords'] = test_data['title'].fillna('')
test_data[['uuid', 'Keywords', 'label']].to_csv('submit_task1.csv', index=None)(三)成绩展示
分别进行了三次训练:两次使用GPU,一次使用CPU
CPU已经展示,并未完全训练完成,因此也没有提交
以下是两次GPU训练情况展示


以下是其中一次的结果参考:
(base) /mnt/workspace> conda run -n base --no-capture-output --live-stream python /mnt/workspace/second.py
Device: cuda
inputs: {'input_ids': tensor([[ 101, 2070, 2047, ..., 2951, 4106, 102],
[ 101, 1037, 3117, ..., 2000, 10197, 102],
[ 101, 1996, 2535, ..., 2740, 3141, 102],
...,
[ 101, 5731, 1997, ..., 2965, 1998, 102],
[ 101, 9849, 1999, ..., 9281, 1999, 102],
[ 101, 28105, 9380, ..., 2869, 3012, 102]]), 'token_type_ids': tensor([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
...,
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1]])}
targets: tensor([1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1])
Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertModel: ['cls.predictions.decoder.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.seq_relationship.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.bias', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.bias']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Epoch 1/100, Step: 49/338, total loss:16.0853
Epoch 1/100, Step: 99/338, total loss:6.6900
Epoch 1/100, Step: 149/338, total loss:6.7295
Epoch 1/100, Step: 199/338, total loss:6.4598
Epoch 1/100, Step: 249/338, total loss:5.3197
Epoch 1/100, Step: 299/338, total loss:4.6202
Epoch 1, accuracy: 0.9683, validation loss: 0.0064
Epoch 2/100, Step: 11/338, total loss:5.2402
Epoch 2/100, Step: 61/338, total loss:3.3994
Epoch 2/100, Step: 111/338, total loss:4.0118
Epoch 2/100, Step: 161/338, total loss:3.8793
Epoch 2/100, Step: 211/338, total loss:4.7791
Epoch 2/100, Step: 261/338, total loss:3.2731
Epoch 2/100, Step: 311/338, total loss:4.6622
Epoch 2, accuracy: 0.9767, validation loss: 0.0037
Epoch 3/100, Step: 23/338, total loss:3.4723
Epoch 3/100, Step: 73/338, total loss:2.3355
Epoch 3/100, Step: 123/338, total loss:3.4103
Epoch 3/100, Step: 173/338, total loss:2.8350
Epoch 3/100, Step: 223/338, total loss:3.0033
Epoch 3/100, Step: 273/338, total loss:3.0584
Epoch 3/100, Step: 323/338, total loss:2.6211
Epoch 3, accuracy: 0.9767, validation loss: 0.0065
Epoch 4/100, Step: 35/338, total loss:2.7945
Epoch 4/100, Step: 85/338, total loss:1.6429
Epoch 4/100, Step: 135/338, total loss:0.8042
Epoch 4/100, Step: 185/338, total loss:1.8824
Epoch 4/100, Step: 235/338, total loss:2.2482
Epoch 4/100, Step: 285/338, total loss:2.8741
Epoch 4/100, Step: 335/338, total loss:1.4104
Epoch 4, accuracy: 0.9800, validation loss: 0.0058
Epoch 5/100, Step: 47/338, total loss:1.2224
Epoch 5/100, Step: 97/338, total loss:1.0822
Epoch 5/100, Step: 147/338, total loss:0.7819
Epoch 5/100, Step: 197/338, total loss:1.8284
Epoch 5/100, Step: 247/338, total loss:1.2448
Epoch 5/100, Step: 297/338, total loss:0.5109
Epoch 5, accuracy: 0.9800, validation loss: 0.0063
Epoch 6/100, Step: 9/338, total loss:1.2508
Epoch 6/100, Step: 59/338, total loss:0.9672
Epoch 6/100, Step: 109/338, total loss:0.9594
Epoch 6/100, Step: 159/338, total loss:0.3619
Epoch 6/100, Step: 209/338, total loss:2.6982
Epoch 6/100, Step: 259/338, total loss:1.4741
Epoch 6/100, Step: 309/338, total loss:1.3984
Epoch 6, accuracy: 0.9750, validation loss: 0.0054
Epoch 7/100, Step: 21/338, total loss:2.3745
Epoch 7/100, Step: 71/338, total loss:1.5688
Epoch 7/100, Step: 121/338, total loss:1.0056
Epoch 7/100, Step: 171/338, total loss:0.4054
Epoch 7/100, Step: 221/338, total loss:0.8185
Epoch 7/100, Step: 271/338, total loss:2.2563
Epoch 7/100, Step: 321/338, total loss:1.7560
Epoch 7, accuracy: 0.9800, validation loss: 0.0060
Epoch 8/100, Step: 33/338, total loss:0.8179
Epoch 8/100, Step: 83/338, total loss:0.5738
Epoch 8/100, Step: 133/338, total loss:0.0869
Epoch 8/100, Step: 183/338, total loss:0.2665
Epoch 8/100, Step: 233/338, total loss:0.4335
Epoch 8/100, Step: 283/338, total loss:0.7802
Epoch 8/100, Step: 333/338, total loss:0.3107
Epoch 8, accuracy: 0.9733, validation loss: 0.0098
Epoch 9/100, Step: 45/338, total loss:0.0294
Epoch 9/100, Step: 95/338, total loss:0.0871
Epoch 9/100, Step: 145/338, total loss:0.0995
Epoch 9/100, Step: 195/338, total loss:0.0236
Epoch 9/100, Step: 245/338, total loss:0.0478
Epoch 9/100, Step: 295/338, total loss:0.4348
Epoch 9, accuracy: 0.9717, validation loss: 0.0065
Epoch 10/100, Step: 7/338, total loss:1.3483
Epoch 10/100, Step: 57/338, total loss:0.3626
Epoch 10/100, Step: 107/338, total loss:0.2525
Epoch 10/100, Step: 157/338, total loss:0.1583
Epoch 10/100, Step: 207/338, total loss:0.6215
Epoch 10/100, Step: 257/338, total loss:0.5952
Epoch 10/100, Step: 307/338, total loss:0.8487
Epoch 10, accuracy: 0.9750, validation loss: 0.0065
Epoch 11/100, Step: 19/338, total loss:0.2554
Epoch 11/100, Step: 69/338, total loss:0.0798
Epoch 11/100, Step: 119/338, total loss:0.2512
Epoch 11/100, Step: 169/338, total loss:0.0704
Epoch 11/100, Step: 219/338, total loss:0.2000
Epoch 11/100, Step: 269/338, total loss:0.0319
Epoch 11/100, Step: 319/338, total loss:0.1053
Epoch 11, accuracy: 0.9683, validation loss: 0.0132
Epoch 12/100, Step: 31/338, total loss:0.6225
Epoch 12/100, Step: 81/338, total loss:0.0418
Epoch 12/100, Step: 131/338, total loss:0.0192
Epoch 12/100, Step: 181/338, total loss:0.0111
Epoch 12/100, Step: 231/338, total loss:0.0129
Epoch 12/100, Step: 281/338, total loss:0.0085
Epoch 12/100, Step: 331/338, total loss:0.0100
Epoch 12, accuracy: 0.9800, validation loss: 0.0079
Epoch 13/100, Step: 43/338, total loss:0.0082
Epoch 13/100, Step: 93/338, total loss:0.0075
Epoch 13/100, Step: 143/338, total loss:0.0080
Epoch 13/100, Step: 193/338, total loss:0.0064
Epoch 13/100, Step: 243/338, total loss:0.0072
Epoch 13/100, Step: 293/338, total loss:0.0084
Epoch 13, accuracy: 0.9783, validation loss: 0.0087
Epoch 14/100, Step: 5/338, total loss:0.0055
Epoch 14/100, Step: 55/338, total loss:0.0054
Epoch 14/100, Step: 105/338, total loss:0.0051
Epoch 14/100, Step: 155/338, total loss:0.0053
Epoch 14/100, Step: 205/338, total loss:0.0047
Epoch 14/100, Step: 255/338, total loss:0.0044
Epoch 14/100, Step: 305/338, total loss:0.0043
Epoch 14, accuracy: 0.9767, validation loss: 0.0089
Epoch 15/100, Step: 17/338, total loss:0.0046
Epoch 15/100, Step: 67/338, total loss:0.0041
Epoch 15/100, Step: 117/338, total loss:0.0043
Epoch 15/100, Step: 167/338, total loss:0.0040
Epoch 15/100, Step: 217/338, total loss:0.0037
Epoch 15/100, Step: 267/338, total loss:0.0037
Epoch 15/100, Step: 317/338, total loss:0.0035
Epoch 15, accuracy: 0.9767, validation loss: 0.0093
Epoch 16/100, Step: 29/338, total loss:0.0034
Epoch 16/100, Step: 79/338, total loss:0.0032
Epoch 16/100, Step: 129/338, total loss:0.0032
Epoch 16/100, Step: 179/338, total loss:0.0030
Epoch 16/100, Step: 229/338, total loss:0.0029
Epoch 16/100, Step: 279/338, total loss:0.0028
Epoch 16/100, Step: 329/338, total loss:0.0030
Epoch 16, accuracy: 0.9817, validation loss: 0.0091
Epoch 17/100, Step: 41/338, total loss:0.0066
Epoch 17/100, Step: 91/338, total loss:0.0026
Epoch 17/100, Step: 141/338, total loss:0.0025
Epoch 17/100, Step: 191/338, total loss:0.0023
Epoch 17/100, Step: 241/338, total loss:0.0023
Epoch 17/100, Step: 291/338, total loss:0.0024
Epoch 17, accuracy: 0.9783, validation loss: 0.0098
Epoch 18/100, Step: 3/338, total loss:0.0023
Epoch 18/100, Step: 53/338, total loss:0.0021
Epoch 18/100, Step: 103/338, total loss:0.0020
Epoch 18/100, Step: 153/338, total loss:0.0021
Epoch 18/100, Step: 203/338, total loss:0.0020
Epoch 18/100, Step: 253/338, total loss:0.0019
Epoch 18/100, Step: 303/338, total loss:0.0018
Epoch 18, accuracy: 0.9767, validation loss: 0.0101
Epoch 19/100, Step: 15/338, total loss:0.0017
Epoch 19/100, Step: 65/338, total loss:0.0019
Epoch 19/100, Step: 115/338, total loss:0.0017
Epoch 19/100, Step: 165/338, total loss:0.0016
Epoch 19/100, Step: 215/338, total loss:0.0016
Epoch 19/100, Step: 265/338, total loss:0.0016
Epoch 19/100, Step: 315/338, total loss:0.0015
Epoch 19, accuracy: 0.9767, validation loss: 0.0104
Epoch 20/100, Step: 27/338, total loss:0.0015
Epoch 20/100, Step: 77/338, total loss:0.0014
Epoch 20/100, Step: 127/338, total loss:0.0015
Epoch 20/100, Step: 177/338, total loss:0.0013
Epoch 20/100, Step: 227/338, total loss:0.0013
Epoch 20/100, Step: 277/338, total loss:0.0014
Epoch 20/100, Step: 327/338, total loss:0.0012
Epoch 20, accuracy: 0.9767, validation loss: 0.0109
Epoch 21/100, Step: 39/338, total loss:0.0013
Epoch 21/100, Step: 89/338, total loss:0.0012
Epoch 21/100, Step: 139/338, total loss:0.0011
Epoch 21/100, Step: 189/338, total loss:0.0011
Epoch 21/100, Step: 239/338, total loss:0.0010
Epoch 21/100, Step: 289/338, total loss:0.0010
Epoch 21, accuracy: 0.9767, validation loss: 0.0111
Epoch 22/100, Step: 1/338, total loss:0.0010
Epoch 22/100, Step: 51/338, total loss:0.0010
Epoch 22/100, Step: 101/338, total loss:0.0010
Epoch 22/100, Step: 151/338, total loss:0.0009
Epoch 22/100, Step: 201/338, total loss:0.0009
Epoch 22/100, Step: 251/338, total loss:0.0010
Epoch 22/100, Step: 301/338, total loss:0.0008
Epoch 22, accuracy: 0.9767, validation loss: 0.0113
Epoch 23/100, Step: 13/338, total loss:0.0009
Epoch 23/100, Step: 63/338, total loss:0.0029
Epoch 23/100, Step: 113/338, total loss:0.0017
Epoch 23/100, Step: 163/338, total loss:0.0008
Epoch 23/100, Step: 213/338, total loss:0.0011
Epoch 23/100, Step: 263/338, total loss:0.0007
Epoch 23/100, Step: 313/338, total loss:0.0007
Epoch 23, accuracy: 0.9800, validation loss: 0.0123
Epoch 24/100, Step: 25/338, total loss:0.0006
Epoch 24/100, Step: 75/338, total loss:0.0006
Epoch 24/100, Step: 125/338, total loss:0.0006
Epoch 24/100, Step: 175/338, total loss:0.0006
Epoch 24/100, Step: 225/338, total loss:0.0006
Epoch 24/100, Step: 275/338, total loss:0.0006
Epoch 24/100, Step: 325/338, total loss:0.0006
Epoch 24, accuracy: 0.9783, validation loss: 0.0124
Epoch 25/100, Step: 37/338, total loss:11.8819
Epoch 25/100, Step: 87/338, total loss:14.2724
Epoch 25/100, Step: 137/338, total loss:13.3796
Epoch 25/100, Step: 187/338, total loss:7.4229
Epoch 25/100, Step: 237/338, total loss:3.2743
Epoch 25/100, Step: 287/338, total loss:2.8395
Epoch 25/100, Step: 337/338, total loss:8.5020
Epoch 25, accuracy: 0.9633, validation loss: 0.0074
Epoch 26/100, Step: 49/338, total loss:3.9889
Epoch 26/100, Step: 99/338, total loss:2.0728
Epoch 26/100, Step: 149/338, total loss:1.4572
Epoch 26/100, Step: 199/338, total loss:0.7338
Epoch 26/100, Step: 249/338, total loss:1.0156
Epoch 26/100, Step: 299/338, total loss:1.0119
Epoch 26, accuracy: 0.9800, validation loss: 0.0059
Epoch 27/100, Step: 11/338, total loss:1.2156
Epoch 27/100, Step: 61/338, total loss:0.5004
Epoch 27/100, Step: 111/338, total loss:1.2495
Epoch 27/100, Step: 161/338, total loss:0.6783
Epoch 27/100, Step: 211/338, total loss:0.2407
Epoch 27/100, Step: 261/338, total loss:0.1807
Epoch 27/100, Step: 311/338, total loss:0.0760
Epoch 27, accuracy: 0.9783, validation loss: 0.0070
Epoch 28/100, Step: 23/338, total loss:0.0130
Epoch 28/100, Step: 73/338, total loss:0.0348
Epoch 28/100, Step: 123/338, total loss:0.0129
Epoch 28/100, Step: 173/338, total loss:0.0143
Epoch 28/100, Step: 223/338, total loss:0.0076
Epoch 28/100, Step: 273/338, total loss:0.1191
Epoch 28/100, Step: 323/338, total loss:0.1115
Epoch 28, accuracy: 0.9817, validation loss: 0.0105
Epoch 29/100, Step: 35/338, total loss:0.0115
Epoch 29/100, Step: 85/338, total loss:0.0316
Epoch 29/100, Step: 135/338, total loss:0.0149
Epoch 29/100, Step: 185/338, total loss:0.0064
Epoch 29/100, Step: 235/338, total loss:0.0046
Epoch 29/100, Step: 285/338, total loss:0.0045
Epoch 29/100, Step: 335/338, total loss:0.0040
Epoch 29, accuracy: 0.9800, validation loss: 0.0109
Epoch 30/100, Step: 47/338, total loss:0.0040
Epoch 30/100, Step: 97/338, total loss:0.0037
Epoch 30/100, Step: 147/338, total loss:0.0038
Epoch 30/100, Step: 197/338, total loss:0.0035
Epoch 30/100, Step: 247/338, total loss:0.0034
Epoch 30/100, Step: 297/338, total loss:0.0032
Epoch 30, accuracy: 0.9750, validation loss: 0.0070
Epoch 31/100, Step: 9/338, total loss:0.9879
Epoch 31/100, Step: 59/338, total loss:0.0927
Epoch 31/100, Step: 109/338, total loss:0.4559
Epoch 31/100, Step: 159/338, total loss:0.6058
Epoch 31/100, Step: 209/338, total loss:0.3157
Epoch 31/100, Step: 259/338, total loss:1.9285
Epoch 31/100, Step: 309/338, total loss:0.5659
Epoch 31, accuracy: 0.9700, validation loss: 0.0097
Epoch 32/100, Step: 21/338, total loss:0.0329
Epoch 32/100, Step: 71/338, total loss:0.0074
Epoch 32/100, Step: 121/338, total loss:0.1469
Epoch 32/100, Step: 171/338, total loss:0.2068
Epoch 32/100, Step: 221/338, total loss:0.1004
Epoch 32/100, Step: 271/338, total loss:0.3878
Epoch 32/100, Step: 321/338, total loss:0.6625
Epoch 32, accuracy: 0.9567, validation loss: 0.0080
Epoch 33/100, Step: 33/338, total loss:0.4451
Epoch 33/100, Step: 83/338, total loss:1.1067
Epoch 33/100, Step: 133/338, total loss:0.0536
Epoch 33/100, Step: 183/338, total loss:0.0076
Epoch 33/100, Step: 233/338, total loss:1.3185
Epoch 33/100, Step: 283/338, total loss:0.8945
Epoch 33/100, Step: 333/338, total loss:0.0658
Epoch 33, accuracy: 0.9683, validation loss: 0.0155
Epoch 34/100, Step: 45/338, total loss:0.0254
Epoch 34/100, Step: 95/338, total loss:0.0185
Epoch 34/100, Step: 145/338, total loss:0.0104
Epoch 34/100, Step: 195/338, total loss:0.0039
Epoch 34/100, Step: 245/338, total loss:0.0031
Epoch 34/100, Step: 295/338, total loss:0.0029
Epoch 34, accuracy: 0.9800, validation loss: 0.0103
Epoch 35/100, Step: 7/338, total loss:0.0174
Epoch 35/100, Step: 57/338, total loss:0.0026
Epoch 35/100, Step: 107/338, total loss:0.2028
Epoch 35/100, Step: 157/338, total loss:0.0041
Epoch 35/100, Step: 207/338, total loss:0.0169
Epoch 35/100, Step: 257/338, total loss:0.0035
Epoch 35/100, Step: 307/338, total loss:0.0023
Epoch 35, accuracy: 0.9800, validation loss: 0.0096
Epoch 36/100, Step: 19/338, total loss:0.0022
Epoch 36/100, Step: 69/338, total loss:0.0026
Epoch 36/100, Step: 119/338, total loss:0.0023
Epoch 36/100, Step: 169/338, total loss:1.9263
Epoch 36/100, Step: 219/338, total loss:0.4497
Epoch 36/100, Step: 269/338, total loss:0.0374
Epoch 36/100, Step: 319/338, total loss:0.0073
Epoch 36, accuracy: 0.9833, validation loss: 0.0082
Epoch 37/100, Step: 31/338, total loss:0.0228
Epoch 37/100, Step: 81/338, total loss:0.0069
Epoch 37/100, Step: 131/338, total loss:0.0050
Epoch 37/100, Step: 181/338, total loss:0.0444
Epoch 37/100, Step: 231/338, total loss:0.0045
Epoch 37/100, Step: 281/338, total loss:0.0091
Epoch 37/100, Step: 331/338, total loss:0.0103
Epoch 37, accuracy: 0.9833, validation loss: 0.0091
Epoch 38/100, Step: 43/338, total loss:0.0032
Epoch 38/100, Step: 93/338, total loss:0.0032
Epoch 38/100, Step: 143/338, total loss:0.0029
Epoch 38/100, Step: 193/338, total loss:0.0028
Epoch 38/100, Step: 243/338, total loss:0.0100
Epoch 38/100, Step: 293/338, total loss:0.0025
Epoch 38, accuracy: 0.9833, validation loss: 0.0087
Epoch 39/100, Step: 5/338, total loss:0.0022
Epoch 39/100, Step: 55/338, total loss:0.0098
Epoch 39/100, Step: 105/338, total loss:0.0021
Epoch 39/100, Step: 155/338, total loss:0.0021
Epoch 39/100, Step: 205/338, total loss:0.0020
Epoch 39/100, Step: 255/338, total loss:0.0019
Epoch 39/100, Step: 305/338, total loss:0.0018
Epoch 39, accuracy: 0.9817, validation loss: 0.0094
Epoch 40/100, Step: 17/338, total loss:0.0018
Epoch 40/100, Step: 67/338, total loss:0.0017
Epoch 40/100, Step: 117/338, total loss:0.0016
Epoch 40/100, Step: 167/338, total loss:0.0016
Epoch 40/100, Step: 217/338, total loss:0.0015
Epoch 40/100, Step: 267/338, total loss:0.0015
Epoch 40/100, Step: 317/338, total loss:0.0014
Epoch 40, accuracy: 0.9817, validation loss: 0.0096
Epoch 41/100, Step: 29/338, total loss:0.0014
Epoch 41/100, Step: 79/338, total loss:0.0014
Epoch 41/100, Step: 129/338, total loss:0.0013
Epoch 41/100, Step: 179/338, total loss:0.0012
Epoch 41/100, Step: 229/338, total loss:0.0012
Epoch 41/100, Step: 279/338, total loss:0.0012
Epoch 41/100, Step: 329/338, total loss:0.0012
Epoch 41, accuracy: 0.9817, validation loss: 0.0098
Epoch 42/100, Step: 41/338, total loss:0.0011
Epoch 42/100, Step: 91/338, total loss:0.0011
Epoch 42/100, Step: 141/338, total loss:0.0010
Epoch 42/100, Step: 191/338, total loss:0.0011
Epoch 42/100, Step: 241/338, total loss:0.0010
Epoch 42/100, Step: 291/338, total loss:0.0010
Epoch 42, accuracy: 0.9817, validation loss: 0.0097
Epoch 43/100, Step: 3/338, total loss:0.0009
Epoch 43/100, Step: 53/338, total loss:0.0009
Epoch 43/100, Step: 103/338, total loss:0.0009
Epoch 43/100, Step: 153/338, total loss:0.0009
Epoch 43/100, Step: 203/338, total loss:0.0009
Epoch 43/100, Step: 253/338, total loss:0.0008
Epoch 43/100, Step: 303/338, total loss:0.0008
Epoch 43, accuracy: 0.9817, validation loss: 0.0099
Epoch 44/100, Step: 15/338, total loss:0.0008
Epoch 44/100, Step: 65/338, total loss:0.0007
Epoch 44/100, Step: 115/338, total loss:0.0008
Epoch 44/100, Step: 165/338, total loss:0.0007
Epoch 44/100, Step: 215/338, total loss:0.0007
Epoch 44/100, Step: 265/338, total loss:0.0007
Epoch 44/100, Step: 315/338, total loss:0.0006
Epoch 44, accuracy: 0.9817, validation loss: 0.0101
Epoch 45/100, Step: 27/338, total loss:0.0006
Epoch 45/100, Step: 77/338, total loss:0.0006
Epoch 45/100, Step: 127/338, total loss:0.0006
Epoch 45/100, Step: 177/338, total loss:0.0006
Epoch 45/100, Step: 227/338, total loss:0.0006
Epoch 45/100, Step: 277/338, total loss:0.0005
Epoch 45/100, Step: 327/338, total loss:0.0005
Epoch 45, accuracy: 0.9817, validation loss: 0.0102
Epoch 46/100, Step: 39/338, total loss:0.0005
Epoch 46/100, Step: 89/338, total loss:0.0026
Epoch 46/100, Step: 139/338, total loss:0.0016
Epoch 46/100, Step: 189/338, total loss:0.0005
Epoch 46/100, Step: 239/338, total loss:0.0005
Epoch 46/100, Step: 289/338, total loss:0.0004
Epoch 46, accuracy: 0.9800, validation loss: 0.0110
Epoch 47/100, Step: 1/338, total loss:0.0004
Epoch 47/100, Step: 51/338, total loss:0.0004
Epoch 47/100, Step: 101/338, total loss:0.0004
Epoch 47/100, Step: 151/338, total loss:0.0004
Epoch 47/100, Step: 201/338, total loss:0.0004
Epoch 47/100, Step: 251/338, total loss:0.0004
Epoch 47/100, Step: 301/338, total loss:0.0004
Epoch 47, accuracy: 0.9800, validation loss: 0.0112
Epoch 48/100, Step: 13/338, total loss:0.0004
Epoch 48/100, Step: 63/338, total loss:0.0003
Epoch 48/100, Step: 113/338, total loss:0.0003
Epoch 48/100, Step: 163/338, total loss:0.0003
Epoch 48/100, Step: 213/338, total loss:0.0003
Epoch 48/100, Step: 263/338, total loss:0.0003
Epoch 48/100, Step: 313/338, total loss:0.0003
Epoch 48, accuracy: 0.9800, validation loss: 0.0114
Epoch 49/100, Step: 25/338, total loss:0.0003
Epoch 49/100, Step: 75/338, total loss:0.0003
Epoch 49/100, Step: 125/338, total loss:0.0003
Epoch 49/100, Step: 175/338, total loss:0.0003
Epoch 49/100, Step: 225/338, total loss:0.0003
Epoch 49/100, Step: 275/338, total loss:0.0003
Epoch 49/100, Step: 325/338, total loss:0.0002
Epoch 49, accuracy: 0.9800, validation loss: 0.0115
Epoch 50/100, Step: 37/338, total loss:0.0002
Epoch 50/100, Step: 87/338, total loss:0.0002
Epoch 50/100, Step: 137/338, total loss:0.0002
Epoch 50/100, Step: 187/338, total loss:0.0002
Epoch 50/100, Step: 237/338, total loss:0.0002
Epoch 50/100, Step: 287/338, total loss:0.0002
Epoch 50/100, Step: 337/338, total loss:0.0002
Epoch 50, accuracy: 0.9800, validation loss: 0.0117
Epoch 51/100, Step: 49/338, total loss:0.0002
Epoch 51/100, Step: 99/338, total loss:0.0002
Epoch 51/100, Step: 149/338, total loss:0.0002
Epoch 51/100, Step: 199/338, total loss:0.0002
Epoch 51/100, Step: 249/338, total loss:0.0002
Epoch 51/100, Step: 299/338, total loss:0.0002
Epoch 51, accuracy: 0.9800, validation loss: 0.0119
Epoch 52/100, Step: 11/338, total loss:0.0002
Epoch 52/100, Step: 61/338, total loss:0.0002
Epoch 52/100, Step: 111/338, total loss:0.0002
Epoch 52/100, Step: 161/338, total loss:0.0002
Epoch 52/100, Step: 211/338, total loss:0.0001
Epoch 52/100, Step: 261/338, total loss:0.0001
Epoch 52/100, Step: 311/338, total loss:0.0001
Epoch 52, accuracy: 0.9800, validation loss: 0.0121
Epoch 53/100, Step: 23/338, total loss:0.0001
Epoch 53/100, Step: 73/338, total loss:0.0001
Epoch 53/100, Step: 123/338, total loss:0.0001
Epoch 53/100, Step: 173/338, total loss:0.0001
Epoch 53/100, Step: 223/338, total loss:0.0001
Epoch 53/100, Step: 273/338, total loss:0.0001
Epoch 53/100, Step: 323/338, total loss:0.0001
Epoch 53, accuracy: 0.9800, validation loss: 0.0122
Epoch 54/100, Step: 35/338, total loss:0.0001
Epoch 54/100, Step: 85/338, total loss:0.0001
Epoch 54/100, Step: 135/338, total loss:0.0001
Epoch 54/100, Step: 185/338, total loss:0.0001
Epoch 54/100, Step: 235/338, total loss:0.0001
Epoch 54/100, Step: 285/338, total loss:0.0001
Epoch 54/100, Step: 335/338, total loss:0.0001
Epoch 54, accuracy: 0.9800, validation loss: 0.0124
Epoch 55/100, Step: 47/338, total loss:0.0001
Epoch 55/100, Step: 97/338, total loss:0.0001
Epoch 55/100, Step: 147/338, total loss:0.0001
Epoch 55/100, Step: 197/338, total loss:0.0001
Epoch 55/100, Step: 247/338, total loss:0.0001
Epoch 55/100, Step: 297/338, total loss:0.0001
Epoch 55, accuracy: 0.9800, validation loss: 0.0126
Epoch 56/100, Step: 9/338, total loss:0.0001
Epoch 56/100, Step: 59/338, total loss:0.0001
Epoch 56/100, Step: 109/338, total loss:0.0001
Epoch 56/100, Step: 159/338, total loss:0.0001
Epoch 56/100, Step: 209/338, total loss:0.0001
Epoch 56/100, Step: 259/338, total loss:0.0001
Epoch 56/100, Step: 309/338, total loss:0.0001
Epoch 56, accuracy: 0.9800, validation loss: 0.0128
Epoch 57/100, Step: 21/338, total loss:0.0001
Epoch 57/100, Step: 71/338, total loss:0.0001
Epoch 57/100, Step: 121/338, total loss:0.0001
Epoch 57/100, Step: 171/338, total loss:0.0001
Epoch 57/100, Step: 221/338, total loss:0.0001
Epoch 57/100, Step: 271/338, total loss:0.0001
Epoch 57/100, Step: 321/338, total loss:0.0001
Epoch 57, accuracy: 0.9800, validation loss: 0.0129
Epoch 58/100, Step: 33/338, total loss:0.0001
Epoch 58/100, Step: 83/338, total loss:0.0001
Epoch 58/100, Step: 133/338, total loss:0.0001
Epoch 58/100, Step: 183/338, total loss:0.0000
Epoch 58/100, Step: 233/338, total loss:0.0000
Epoch 58/100, Step: 283/338, total loss:0.0000
Epoch 58/100, Step: 333/338, total loss:0.0000
Epoch 58, accuracy: 0.9800, validation loss: 0.0131
Epoch 59/100, Step: 45/338, total loss:0.0000
Epoch 59/100, Step: 95/338, total loss:0.0000
Epoch 59/100, Step: 145/338, total loss:0.0000
Epoch 59/100, Step: 195/338, total loss:0.0000
Epoch 59/100, Step: 245/338, total loss:0.0000
Epoch 59/100, Step: 295/338, total loss:0.0000
Epoch 59, accuracy: 0.9800, validation loss: 0.0132
Epoch 60/100, Step: 7/338, total loss:0.0000
Epoch 60/100, Step: 57/338, total loss:0.0000
Epoch 60/100, Step: 107/338, total loss:0.0000
Epoch 60/100, Step: 157/338, total loss:0.0000
Epoch 60/100, Step: 207/338, total loss:0.0000
Epoch 60/100, Step: 257/338, total loss:0.0000
Epoch 60/100, Step: 307/338, total loss:0.0000
Epoch 60, accuracy: 0.9800, validation loss: 0.0136
Epoch 61/100, Step: 19/338, total loss:0.0000
Epoch 61/100, Step: 69/338, total loss:0.0000
Epoch 61/100, Step: 119/338, total loss:0.0000
Epoch 61/100, Step: 169/338, total loss:0.0000
Epoch 61/100, Step: 219/338, total loss:0.0000
Epoch 61/100, Step: 269/338, total loss:0.0000
Epoch 61/100, Step: 319/338, total loss:0.0000
Epoch 61, accuracy: 0.9800, validation loss: 0.0137
Epoch 62/100, Step: 31/338, total loss:0.0000
Epoch 62/100, Step: 81/338, total loss:0.0000
Epoch 62/100, Step: 131/338, total loss:0.0000
Epoch 62/100, Step: 181/338, total loss:0.0000
Epoch 62/100, Step: 231/338, total loss:0.0000
Epoch 62/100, Step: 281/338, total loss:0.0000
Epoch 62/100, Step: 331/338, total loss:0.0000
Epoch 62, accuracy: 0.9800, validation loss: 0.0138
Epoch 63/100, Step: 43/338, total loss:0.0000
Epoch 63/100, Step: 93/338, total loss:0.0000
Epoch 63/100, Step: 143/338, total loss:0.0000
Epoch 63/100, Step: 193/338, total loss:0.0000
Epoch 63/100, Step: 243/338, total loss:0.0000
Epoch 63/100, Step: 293/338, total loss:0.0000
Epoch 63, accuracy: 0.9800, validation loss: 0.0139
Epoch 64/100, Step: 5/338, total loss:0.0000
Epoch 64/100, Step: 55/338, total loss:0.0000
Epoch 64/100, Step: 105/338, total loss:0.0000
Epoch 64/100, Step: 155/338, total loss:0.0000
Epoch 64/100, Step: 205/338, total loss:0.0000
Epoch 64/100, Step: 255/338, total loss:0.0000
Epoch 64/100, Step: 305/338, total loss:0.0000
Epoch 64, accuracy: 0.9800, validation loss: 0.0140
Epoch 65/100, Step: 17/338, total loss:0.0000
Epoch 65/100, Step: 67/338, total loss:0.0000
Epoch 65/100, Step: 117/338, total loss:0.0000
Epoch 65/100, Step: 167/338, total loss:0.0000
Epoch 65/100, Step: 217/338, total loss:0.0000
Epoch 65/100, Step: 267/338, total loss:0.0000
Epoch 65/100, Step: 317/338, total loss:0.0000
Epoch 65, accuracy: 0.9800, validation loss: 0.0140
Epoch 66/100, Step: 29/338, total loss:0.0000
Epoch 66/100, Step: 79/338, total loss:0.0000
Epoch 66/100, Step: 129/338, total loss:0.0000
Epoch 66/100, Step: 179/338, total loss:0.0000
Epoch 66/100, Step: 229/338, total loss:0.0000
Epoch 66/100, Step: 279/338, total loss:0.0000
Epoch 66/100, Step: 329/338, total loss:0.0000
Epoch 66, accuracy: 0.9800, validation loss: 0.0492
Epoch 67/100, Step: 41/338, total loss:0.0000
Epoch 67/100, Step: 91/338, total loss:0.0000
Epoch 67/100, Step: 141/338, total loss:0.0000
Epoch 67/100, Step: 191/338, total loss:0.0000
Epoch 67/100, Step: 241/338, total loss:0.0000
Epoch 67/100, Step: 291/338, total loss:0.0000
Epoch 67, accuracy: 0.9800, validation loss: 0.0492
Epoch 68/100, Step: 3/338, total loss:0.0000
Epoch 68/100, Step: 53/338, total loss:0.0000
Epoch 68/100, Step: 103/338, total loss:0.0000
Epoch 68/100, Step: 153/338, total loss:0.0000
Epoch 68/100, Step: 203/338, total loss:0.0000
Epoch 68/100, Step: 253/338, total loss:0.0000
Epoch 68/100, Step: 303/338, total loss:0.0000
Epoch 68, accuracy: 0.9800, validation loss: 0.0492
Epoch 69/100, Step: 15/338, total loss:0.0000
Epoch 69/100, Step: 65/338, total loss:0.0000
Epoch 69/100, Step: 115/338, total loss:0.0000
Epoch 69/100, Step: 165/338, total loss:0.0000
Epoch 69/100, Step: 215/338, total loss:0.0000
Epoch 69/100, Step: 265/338, total loss:0.0000
Epoch 69/100, Step: 315/338, total loss:0.0000
Epoch 69, accuracy: 0.9800, validation loss: 0.0493
Epoch 70/100, Step: 27/338, total loss:0.0000
Epoch 70/100, Step: 77/338, total loss:0.0000
Epoch 70/100, Step: 127/338, total loss:0.0000
Epoch 70/100, Step: 177/338, total loss:0.0000
Epoch 70/100, Step: 227/338, total loss:0.0000
Epoch 70/100, Step: 277/338, total loss:0.0000
Epoch 70/100, Step: 327/338, total loss:0.0000
Epoch 70, accuracy: 0.9800, validation loss: 0.0494
Epoch 71/100, Step: 39/338, total loss:0.0000
Epoch 71/100, Step: 89/338, total loss:0.0000
Epoch 71/100, Step: 139/338, total loss:0.0000
Epoch 71/100, Step: 189/338, total loss:0.0000
Epoch 71/100, Step: 239/338, total loss:0.0000
Epoch 71/100, Step: 289/338, total loss:0.0000
Epoch 71, accuracy: 0.9800, validation loss: 0.0495
Epoch 72/100, Step: 1/338, total loss:0.0000
Epoch 72/100, Step: 51/338, total loss:0.0000
Epoch 72/100, Step: 101/338, total loss:0.0000
Epoch 72/100, Step: 151/338, total loss:0.0000
Epoch 72/100, Step: 201/338, total loss:0.0000
Epoch 72/100, Step: 251/338, total loss:0.0000
Epoch 72/100, Step: 301/338, total loss:0.0000
Epoch 72, accuracy: 0.9800, validation loss: 0.0496
Epoch 73/100, Step: 13/338, total loss:0.0000
Epoch 73/100, Step: 63/338, total loss:0.0000
Epoch 73/100, Step: 113/338, total loss:0.0000
Epoch 73/100, Step: 163/338, total loss:0.0000
Epoch 73/100, Step: 213/338, total loss:0.0000
Epoch 73/100, Step: 263/338, total loss:0.0000
Epoch 73/100, Step: 313/338, total loss:0.0000
Epoch 73, accuracy: 0.9800, validation loss: 0.0497
Epoch 74/100, Step: 25/338, total loss:0.0000
Epoch 74/100, Step: 75/338, total loss:0.0000
Epoch 74/100, Step: 125/338, total loss:0.0000
Epoch 74/100, Step: 175/338, total loss:0.0000
Epoch 74/100, Step: 225/338, total loss:0.0000
Epoch 74/100, Step: 275/338, total loss:0.0000
Epoch 74/100, Step: 325/338, total loss:0.0000
Epoch 74, accuracy: 0.9800, validation loss: 0.0498
Epoch 75/100, Step: 37/338, total loss:0.0000
Epoch 75/100, Step: 87/338, total loss:0.0000
Epoch 75/100, Step: 137/338, total loss:0.0000
Epoch 75/100, Step: 187/338, total loss:0.0000
Epoch 75/100, Step: 237/338, total loss:0.0000
Epoch 75/100, Step: 287/338, total loss:0.0000
Epoch 75/100, Step: 337/338, total loss:0.0000
Epoch 75, accuracy: 0.9800, validation loss: 0.0498
Epoch 76/100, Step: 49/338, total loss:0.0000
Epoch 76/100, Step: 99/338, total loss:0.0000
Epoch 76/100, Step: 149/338, total loss:0.0000
Epoch 76/100, Step: 199/338, total loss:0.0000
Epoch 76/100, Step: 249/338, total loss:0.0000
Epoch 76/100, Step: 299/338, total loss:0.0000
Epoch 76, accuracy: 0.9800, validation loss: 0.0499
Epoch 77/100, Step: 11/338, total loss:0.0000
Epoch 77/100, Step: 61/338, total loss:0.0000
Epoch 77/100, Step: 111/338, total loss:0.0000
Epoch 77/100, Step: 161/338, total loss:0.0000
Epoch 77/100, Step: 211/338, total loss:0.0000
Epoch 77/100, Step: 261/338, total loss:0.0000
Epoch 77/100, Step: 311/338, total loss:0.0000
Epoch 77, accuracy: 0.9800, validation loss: 0.0500
Epoch 78/100, Step: 23/338, total loss:0.0000
Epoch 78/100, Step: 73/338, total loss:0.0000
Epoch 78/100, Step: 123/338, total loss:0.0000
Epoch 78/100, Step: 173/338, total loss:0.0000
Epoch 78/100, Step: 223/338, total loss:0.0000
Epoch 78/100, Step: 273/338, total loss:0.0000
Epoch 78/100, Step: 323/338, total loss:0.0000
Epoch 78, accuracy: 0.9800, validation loss: 0.0501
Epoch 79/100, Step: 35/338, total loss:0.0000
Epoch 79/100, Step: 85/338, total loss:0.0000
Epoch 79/100, Step: 135/338, total loss:0.0000
Epoch 79/100, Step: 185/338, total loss:0.0000
Epoch 79/100, Step: 235/338, total loss:0.0000
Epoch 79/100, Step: 285/338, total loss:0.0000
Epoch 79/100, Step: 335/338, total loss:0.0000
Epoch 79, accuracy: 0.9800, validation loss: 0.0502
Epoch 80/100, Step: 47/338, total loss:0.0000
Epoch 80/100, Step: 97/338, total loss:0.0000
Epoch 80/100, Step: 147/338, total loss:0.0000
Epoch 80/100, Step: 197/338, total loss:0.0000
Epoch 80/100, Step: 247/338, total loss:0.0000
Epoch 80/100, Step: 297/338, total loss:0.0000
Epoch 80, accuracy: 0.9800, validation loss: 0.0502
Epoch 81/100, Step: 9/338, total loss:0.0000
Epoch 81/100, Step: 59/338, total loss:0.0000
Epoch 81/100, Step: 109/338, total loss:0.0000
Epoch 81/100, Step: 159/338, total loss:0.0000
Epoch 81/100, Step: 209/338, total loss:0.0000
Epoch 81/100, Step: 259/338, total loss:0.0000
Epoch 81/100, Step: 309/338, total loss:0.0000
Epoch 81, accuracy: 0.9800, validation loss: 0.0503
Epoch 82/100, Step: 21/338, total loss:0.0000
Epoch 82/100, Step: 71/338, total loss:0.0000
Epoch 82/100, Step: 121/338, total loss:0.0000
Epoch 82/100, Step: 171/338, total loss:0.0000
Epoch 82/100, Step: 221/338, total loss:0.0000
Epoch 82/100, Step: 271/338, total loss:0.0000
Epoch 82/100, Step: 321/338, total loss:0.0000
Epoch 82, accuracy: 0.9800, validation loss: 0.0504
Epoch 83/100, Step: 33/338, total loss:0.0000
Epoch 83/100, Step: 83/338, total loss:0.0000
Epoch 83/100, Step: 133/338, total loss:0.0000
Epoch 83/100, Step: 183/338, total loss:0.0000
Epoch 83/100, Step: 233/338, total loss:0.0000
Epoch 83/100, Step: 283/338, total loss:0.0000
Epoch 83/100, Step: 333/338, total loss:0.0000
Epoch 83, accuracy: 0.9817, validation loss: 0.0492
Epoch 84/100, Step: 45/338, total loss:0.0000
Epoch 84/100, Step: 95/338, total loss:0.0000
Epoch 84/100, Step: 145/338, total loss:0.0000
Epoch 84/100, Step: 195/338, total loss:0.0000
Epoch 84/100, Step: 245/338, total loss:0.0000
Epoch 84/100, Step: 295/338, total loss:0.0000
Epoch 84, accuracy: 0.9817, validation loss: 0.0493
Epoch 85/100, Step: 7/338, total loss:0.0000
Epoch 85/100, Step: 57/338, total loss:0.0000
Epoch 85/100, Step: 107/338, total loss:0.0000
Epoch 85/100, Step: 157/338, total loss:0.0000
Epoch 85/100, Step: 207/338, total loss:0.0000
Epoch 85/100, Step: 257/338, total loss:0.0000
Epoch 85/100, Step: 307/338, total loss:0.0000
Epoch 85, accuracy: 0.9817, validation loss: 0.0494
Epoch 86/100, Step: 19/338, total loss:0.0000
Epoch 86/100, Step: 69/338, total loss:0.0000
Epoch 86/100, Step: 119/338, total loss:0.0000
Epoch 86/100, Step: 169/338, total loss:0.0000
Epoch 86/100, Step: 219/338, total loss:0.0000
Epoch 86/100, Step: 269/338, total loss:0.0000
Epoch 86/100, Step: 319/338, total loss:0.0000
Epoch 86, accuracy: 0.9817, validation loss: 0.0494
Epoch 87/100, Step: 31/338, total loss:0.0000
Epoch 87/100, Step: 81/338, total loss:0.0000
Epoch 87/100, Step: 131/338, total loss:0.0000
Epoch 87/100, Step: 181/338, total loss:0.0000
Epoch 87/100, Step: 231/338, total loss:0.0000
Epoch 87/100, Step: 281/338, total loss:0.0000
Epoch 87/100, Step: 331/338, total loss:0.0000
Epoch 87, accuracy: 0.9817, validation loss: 0.0495
Epoch 88/100, Step: 43/338, total loss:0.0000
Epoch 88/100, Step: 93/338, total loss:0.0000
Epoch 88/100, Step: 143/338, total loss:0.0000
Epoch 88/100, Step: 193/338, total loss:0.0000
Epoch 88/100, Step: 243/338, total loss:0.0000
Epoch 88/100, Step: 293/338, total loss:0.0000
Epoch 88, accuracy: 0.9817, validation loss: 0.0496
Epoch 89/100, Step: 5/338, total loss:0.0000
Epoch 89/100, Step: 55/338, total loss:0.0000
Epoch 89/100, Step: 105/338, total loss:0.0000
Epoch 89/100, Step: 155/338, total loss:0.0000
Epoch 89/100, Step: 205/338, total loss:0.0000
Epoch 89/100, Step: 255/338, total loss:0.0000
Epoch 89/100, Step: 305/338, total loss:0.0000
Epoch 89, accuracy: 0.9817, validation loss: 0.0496
Epoch 90/100, Step: 17/338, total loss:0.0000
Epoch 90/100, Step: 67/338, total loss:0.0000
Epoch 90/100, Step: 117/338, total loss:0.0000
Epoch 90/100, Step: 167/338, total loss:0.0000
Epoch 90/100, Step: 217/338, total loss:0.0000
Epoch 90/100, Step: 267/338, total loss:0.0000
Epoch 90/100, Step: 317/338, total loss:0.0000
Epoch 90, accuracy: 0.9817, validation loss: 0.0497
Epoch 91/100, Step: 29/338, total loss:0.0000
Epoch 91/100, Step: 79/338, total loss:0.0000
Epoch 91/100, Step: 129/338, total loss:0.0000
Epoch 91/100, Step: 179/338, total loss:0.0000
Epoch 91/100, Step: 229/338, total loss:0.0000
Epoch 91/100, Step: 279/338, total loss:0.0000
Epoch 91/100, Step: 329/338, total loss:0.0000
Epoch 91, accuracy: 0.9817, validation loss: 0.0497
Epoch 92/100, Step: 41/338, total loss:0.0000
Epoch 92/100, Step: 91/338, total loss:0.0000
Epoch 92/100, Step: 141/338, total loss:0.0000
Epoch 92/100, Step: 191/338, total loss:0.0000
Epoch 92/100, Step: 241/338, total loss:0.0000
Epoch 92/100, Step: 291/338, total loss:0.0000
Epoch 92, accuracy: 0.9817, validation loss: 0.0498
Epoch 93/100, Step: 3/338, total loss:0.0000
Epoch 93/100, Step: 53/338, total loss:0.0000
Epoch 93/100, Step: 103/338, total loss:0.0000
Epoch 93/100, Step: 153/338, total loss:0.0000
Epoch 93/100, Step: 203/338, total loss:0.0000
Epoch 93/100, Step: 253/338, total loss:0.0000
Epoch 93/100, Step: 303/338, total loss:0.0000
Epoch 93, accuracy: 0.9817, validation loss: 0.0498
Epoch 94/100, Step: 15/338, total loss:0.0000
Epoch 94/100, Step: 65/338, total loss:0.0000
Epoch 94/100, Step: 115/338, total loss:0.0000
Epoch 94/100, Step: 165/338, total loss:0.0000
Epoch 94/100, Step: 215/338, total loss:0.0000
Epoch 94/100, Step: 265/338, total loss:0.0000
Epoch 94/100, Step: 315/338, total loss:0.0000
Epoch 94, accuracy: 0.9817, validation loss: 0.0499
Epoch 95/100, Step: 27/338, total loss:0.0000
Epoch 95/100, Step: 77/338, total loss:0.0000
Epoch 95/100, Step: 127/338, total loss:0.0000
Epoch 95/100, Step: 177/338, total loss:0.0000
Epoch 95/100, Step: 227/338, total loss:0.0000
Epoch 95/100, Step: 277/338, total loss:0.0000
Epoch 95/100, Step: 327/338, total loss:0.0000
Epoch 95, accuracy: 0.9817, validation loss: 0.0500
Epoch 96/100, Step: 39/338, total loss:0.0000
Epoch 96/100, Step: 89/338, total loss:0.0000
Epoch 96/100, Step: 139/338, total loss:0.0000
Epoch 96/100, Step: 189/338, total loss:0.0000
Epoch 96/100, Step: 239/338, total loss:0.0000
Epoch 96/100, Step: 289/338, total loss:0.0000
Epoch 96, accuracy: 0.9817, validation loss: 0.0500
Epoch 97/100, Step: 1/338, total loss:0.0000
Epoch 97/100, Step: 51/338, total loss:0.0000
Epoch 97/100, Step: 101/338, total loss:0.0000
Epoch 97/100, Step: 151/338, total loss:0.0000
Epoch 97/100, Step: 201/338, total loss:0.0000
Epoch 97/100, Step: 251/338, total loss:0.0000
Epoch 97/100, Step: 301/338, total loss:0.0000
Epoch 97, accuracy: 0.9817, validation loss: 0.0501
Epoch 98/100, Step: 13/338, total loss:0.0000
Epoch 98/100, Step: 63/338, total loss:0.0000
Epoch 98/100, Step: 113/338, total loss:0.0000
Epoch 98/100, Step: 163/338, total loss:0.0000
Epoch 98/100, Step: 213/338, total loss:0.0000
Epoch 98/100, Step: 263/338, total loss:0.0000
Epoch 98/100, Step: 313/338, total loss:0.0000
Epoch 98, accuracy: 0.9817, validation loss: 0.0501
Epoch 99/100, Step: 25/338, total loss:0.0000
Epoch 99/100, Step: 75/338, total loss:0.0000
Epoch 99/100, Step: 125/338, total loss:0.0000
Epoch 99/100, Step: 175/338, total loss:0.0000
Epoch 99/100, Step: 225/338, total loss:0.0000
Epoch 99/100, Step: 275/338, total loss:0.0000
Epoch 99/100, Step: 325/338, total loss:0.0000
Epoch 99, accuracy: 0.9817, validation loss: 0.0502
Epoch 100/100, Step: 37/338, total loss:0.0000
Epoch 100/100, Step: 87/338, total loss:0.0000
Epoch 100/100, Step: 137/338, total loss:0.0000
Epoch 100/100, Step: 187/338, total loss:0.0000
Epoch 100/100, Step: 237/338, total loss:0.0000
Epoch 100/100, Step: 287/338, total loss:0.0000
Epoch 100/100, Step: 337/338, total loss:0.0000
Epoch 100, accuracy: 0.9817, validation loss: 0.0502
三、总结
在本次实践当中第一次使用云服务器,过程还是比较坎坷的,相信从我的报错经验就可以看出来hhh。因此收获良多,体验到商用GPU的强大性能,举现实的例子,小铃铛的CPU用7h跑出来七个模型,GPU只需要7min。另外,认识到了bert模型的强大优势,在此后的各类学习中,也是可以直接使用现成的模型对其进行训练,再根据需求进行微调,或可大大提高效率。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









