






背景
在现代工业生产中,提高效率和降低成本是最重要的追求的目标。同时,对。提出了越来越高的要求设备的安全性和可靠性。系统一旦出现故障,将造成巨大的损失以人力和财力。故障排除有助于确定原因设备或系统出现问题时,精确定位单个部件。这速度加快维修流程,减少停机时间,提高生产效率。预测性维护通过监测设备状况来防止损坏并降低维修成本和性能数据,预测可能出现的故障,并在故障发生之前制定维护计划。因此,可以大大减少故障排除和预测性维护计划节省了人力,提高了可靠性、可用性和可维护性设备效率。
CMAPSS数据集
数据集:FD001
训练轨迹:100
测试轨迹:100
条件:一个(海平面)
故障模式:ONE(HPC降级)
1)单位编号
2)时间,以周期为单位
3)操作设定1
4)操作设定2
5)操作设置3
6)传感器测量1
7)传感器测量2
…
26)传感器测量26
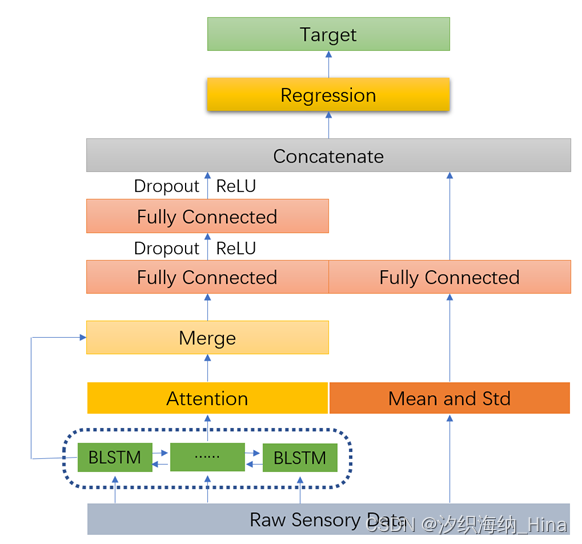
模型结构
class BDLSTM(nn.Module):
def __init__(self,hidden_size=50,input_size=17,seq_selected=30):
super(BDLSTM, self).__init__()
self.seq_selected=seq_selected
self.hidden_size=hidden_size
self.lstm = nn.LSTM(batch_first=True, input_size=input_size, hidden_size=50, num_layers=1,bidirectional=True)
self.attenion = Attention3dBlock(seq_selected)
self.linear = nn.Sequential(
nn.Linear(in_features=seq_selected*self.hidden_size*2, out_features=50),
nn.ReLU(inplace=True),
nn.Dropout(p=0.2),
nn.Linear(in_features=50, out_features=10),
nn.ReLU(inplace=True)
)
self.mslinear = nn.Sequential(
nn.Linear(in_features=input_size*2, out_features=10),
nn.ReLU(inplace=True),
nn.Dropout(p=0.2)
)
self.output = nn.Sequential(
# nn.Linear(in_features=10, out_features=1)
nn.Linear(in_features=20, out_features=1)
)
def forward(self, inputs):#256,31,17
mean=torch.mean(inputs,dim=1)#256,17
std=torch.std(inputs,dim=1)#256,17
mean_std_feature=torch.concat((mean,std),dim=1)#256,34
y = self.mslinear(mean_std_feature)
x, (hn, cn) = self.lstm(inputs)#256,31,50
x = self.attenion(x)#256, 31, 50
# flatten
x = x.reshape(-1, self.seq_selected*self.hidden_size*2)#256, 1550
x = self.linear(x)#256, 10
out = torch.concat((x, y), dim=1)
# out=x
out = self.output(out)
return out
实验结果
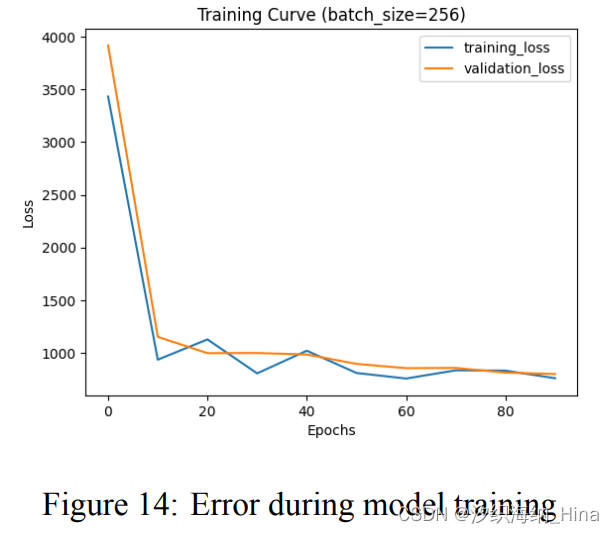
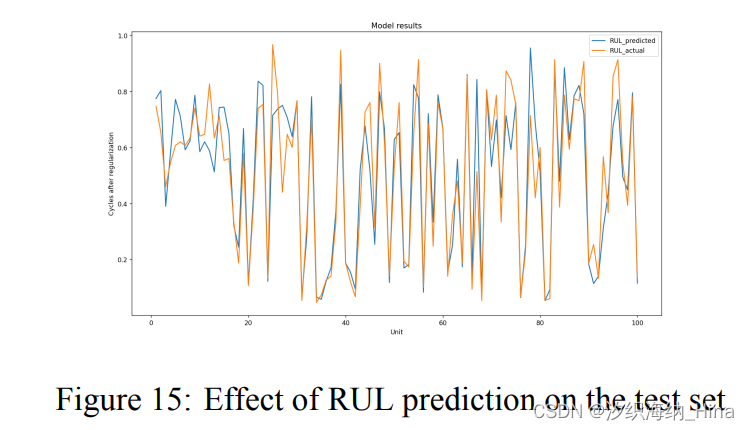
每轮训练后测试集误差
score:445.4610 334.5140 358.6489 365.9250 331.4520 283.3463 460.4766 314.7196 325.5950 452.3746
RMSE:16.3614 14.8254 14.9796 15.5157 14.7853 14.2053 16.2834 14.6757 14.7481 15.8802
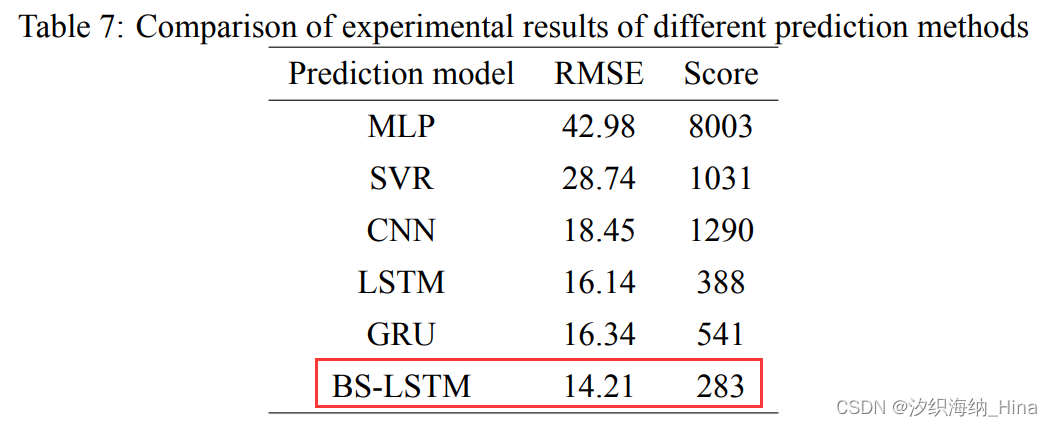
结论
由实验结果可知,MS-BLSTM 的预测误差均为最低水平,并且实际训练过程中收敛速度较快,涡扇发动机接近损坏时预测准确率较高。与传统机器学习方法相比,深度学习模型如CNN 和 LSTM的预测误差相对较小。而本文所提的 MS-BLSTM 混合深度学习预测模型进一步提高了 RUL 预测精度,,这得益于 MS-BLSTM 混合模型有效利用了时间段内传感器测量值的均值和方差与RUL的相关性,并使用 BLSTM学习历史数据和未来数据的长程依赖。本文所提的 MS-BLSTM 剩余使用寿命预测模型预测精度高,可有力支撑涡扇发动机的健康管理与运维决策。
源代码
https://download.csdn.net/download/qq_61908212/88643920
https://github.com/xizhihina/Turbofan-RUL-Prediction

















 85
85

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









