






模型使用牛顿冷却模型
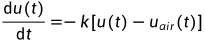
画出外界温度曲线
两端温度不确定,假定为
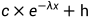
其中h等于外界温度25°,c根据温度计算即可
def T(t,v,T15,T6,T7,T89):
a=[0,25,30.5,5,30.5,5,30.5,5,30.5,5,30.5,5,30.5,5,30.5,5,30.5,5,30.5,5,30.5,5,30.5,25]
a=[i/v*60 for i in a]
m=0
a=[m:=m+i for i in a]
Tair=25
lmd0=-0.5
c0=(T15-Tair)/(math.e**(-lmd0*25/v*60))
lmd=0.015
c=(T89-Tair)/(math.e**(-lmd*339.5/v*60))
if t<a[1]:
return c0*math.e**(-lmd0*t)+Tair
elif t<a[10]:
return T15
elif t<a[11]:
return T15+(T6-T15)/(a[11]-a[10])*(t-a[10])
elif t<a[12]:
return T6
elif t<a[13]:
return T6+(T7-T6)/(a[13]-a[12])*(t-a[12])
elif t<a[14]:
return T7
elif t<a[15]:
return T7+(T89-T7)/(a[15]-a[14])*(t-a[14])
elif t<a[18]:
return T89
else:
return c*math.e**(-lmd*t)+Tairaa=np.linspace(0,400,4001).tolist()
plt.plot(aa,[T(i,70,175,195,235,255)for i in aa])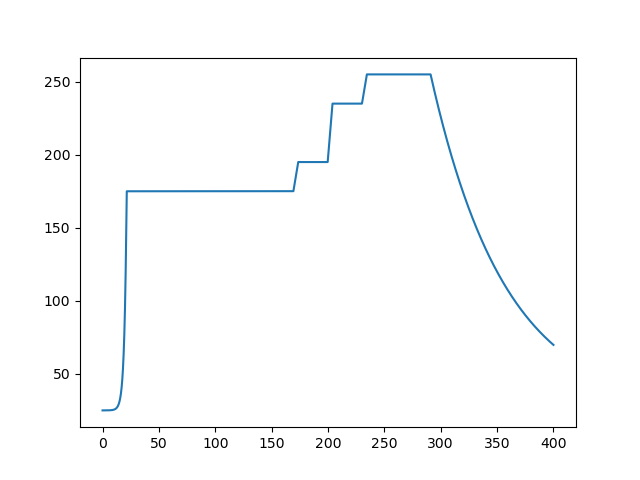
查看题目中给出的数据
def shuju():
a=[float(i[0])for i in csv.reader(open('./附件.csv'))]
b=[float(i[1])for i in csv.reader(open('./附件.csv'))]
plt.plot(a,b)
plt.show()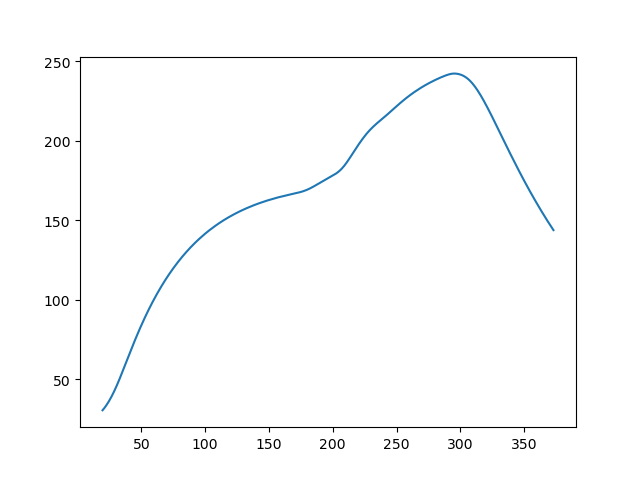
可以看到左端数据量过小,并且环境温度曲线也是假设的,这个值最后根据题目数据估计,使用pytorch求解会使全局误差过大或者温度变化不符合客观规律(k为负)
分段求解k值
def K(start,last):
a=[float(i[0])for i in csv.reader(open('./附件.csv')) if float(i[0])<last and float(i[0])>start]
b=[float(i[1])for i in csv.reader(open('./附件.csv')) if float(i[0])<last and float(i[0])>start]
# k=torch.rand([1,1],requires_grad=True)
k=torch.tensor([0.1],requires_grad=True)
learning_rate=0.01#学习率
learning_times=100#循环次数
criterion=torch.nn.MSELoss()#损失函数
x=torch.tensor(a)
#学习
for i in range(learning_times):
#print(k.data)
y_pre=torch.zeros(len(a))#初始化y_pre
y_true=torch.tensor(b)#这两行必须放在循环内,不然每次循环释放掉了没法计算梯度
for j in range(len(a)):
if j==0:
y_pre[j]=y_true[j]
continue
y_pre[j]=y_pre[j-1]+(T(x[j],70,175,195,235,255)-y_pre[j-1])*k*(x[j]-x[j-1])#即牛顿冷却模型,递归求解出所有温度的预测值
loss=criterion(y_pre,y_true)#计算损失值
# loss=(y_true - y_pre).pow(2).mean()
if k.grad is not None:
k.grad.data.zero_()#重置梯度
loss.backward()#反向传播
k.grad/=len(a)**2#上面循环计算y_pre时每次循环都积累了一次梯度
k.data=k.data-learning_rate*k.grad
if i==learning_times-1:
last_y_pre=y_pre.tolist()
#plt.plot(a,b)
#plt.plot(a,last_y_pre)
#plt.show()
return k.dataprint(K(t_list[1],t_list[11]))
print(K(t_list[11],t_list[13]))
print(K(t_list[13],t_list[15]))
print(K(t_list[15],t_list[18]))
print(K(t_list[18],t_list[-1]))
# tensor([0.0177])
# tensor([0.0166])
# tensor([0.0243])
# tensor([0.0202])
# tensor([0.0276])多个局部最优不一定是全局最优,后面直接将所有数据一起计算loss值得出全局最优
求解全局最优k值
最左端数据太少,会受到全局的影响使得k值为负数,故暂时先不求解最左端的k值,最后再单独求
def _loss_(start,k1,k2,k3,k4,k5,time,t_list):
a=[float(i[0])for i in csv.reader(open('./附件.csv'))if float(i[0])>start]
b=[float(i[1])for i in csv.reader(open('./附件.csv'))if float(i[0])>start]
x=torch.tensor(a)
y_pre=torch.zeros(len(a))#初始化y_pre
y_true=torch.tensor(b)#这两行必须放在循环内,不然每次循环释放掉了没法计算梯度
for j in range(len(a)):
if j==0:
y_pre[j]=y_true[j]
continue
if(x[j]<t_list[1]):
continue
elif(x[j]<t_list[11]):
y_pre[j]=y_pre[j-1]+(T(x[j],70,175,195,235,255)-y_pre[j-1])*k1*(x[j]-x[j-1])
elif(x[j]<t_list[13]):
y_pre[j]=y_pre[j-1]+(T(x[j],70,175,195,235,255)-y_pre[j-1])*k2*(x[j]-x[j-1])
elif(x[j]<t_list[15]):
y_pre[j]=y_pre[j-1]+(T(x[j],70,175,195,235,255)-y_pre[j-1])*k3*(x[j]-x[j-1])
elif(x[j]<t_list[18]):
y_pre[j]=y_pre[j-1]+(T(x[j],70,175,195,235,255)-y_pre[j-1])*k4*(x[j]-x[j-1])
else:
y_pre[j]=y_pre[j-1]+(T(x[j],70,175,195,235,255)-y_pre[j-1])*k5*(x[j]-x[j-1])
#if not time%99:
#plt.plot(x.tolist(),y_pre.tolist())
#plt.plot(a,b)
#plt.show()
return torch.nn.MSELoss()(y_pre,y_true)#计算损失值
def _k_together():
learning_rate=0.01
learning_times=1000
t_list=[0.0, 21.42857142857143, 47.57142857142857, 51.857142857142854, 78.0, 82.28571428571429, 108.42857142857143,
112.71428571428572, 138.85714285714286, 143.14285714285714, 169.28571428571428,173.57142857142856,
199.7142857142857, 203.99999999999997, 230.1428571428571, 234.4285714285714, 260.57142857142856, 264.85714285714283,
291.0, 295.2857142857143, 321.42857142857144, 325.7142857142857, 351.8571428571429, 373.28571428571433]
#t_list是每个温区的起始位置和结束位置除以速度70
k1=torch.tensor([0.2],requires_grad=True)
k2=torch.tensor([0.2],requires_grad=True)
k3=torch.tensor([0.2],requires_grad=True)
k4=torch.tensor([0.2],requires_grad=True)
k5=torch.tensor([0.2],requires_grad=True)
#初始值定位0.2,减少学习次数
for i in range(learning_times):
loss=_loss_(t_list[1],k1,k2,k3,k4,k5,i,t_list)
if k1.grad is not None:
k1.grad.data.zero_()
k2.grad.data.zero_()
k3.grad.data.zero_()
k4.grad.data.zero_()
k5.grad.data.zero_()
loss.backward()
k1.grad/=200**2
k2.grad/=70**2
k3.grad/=70**2
k4.grad/=70**2
k5.grad/=100**2#每段中数据个数的平方,这里我估计了一下,并不是准确值
k1.data=k1.data-k1.grad*learning_rate
k2.data=k2.data-k2.grad*learning_rate
k3.data=k3.data-k3.grad*learning_rate
k4.data=k4.data-k4.grad*learning_rate
k5.data=k5.data-k5.grad*learning_rate
#print(k1,k2,k3,k4,k5)
_k_together()
#tensor([0.0177], requires_grad=True) tensor([0.0171], requires_grad=True) tensor([0.0242], requires_grad=True) tensor([0.0216], requires_grad=True) tensor([0.0276], requires_grad=True)
#0.0177
#0.0171
#0.0242
#0.0216
#0.0276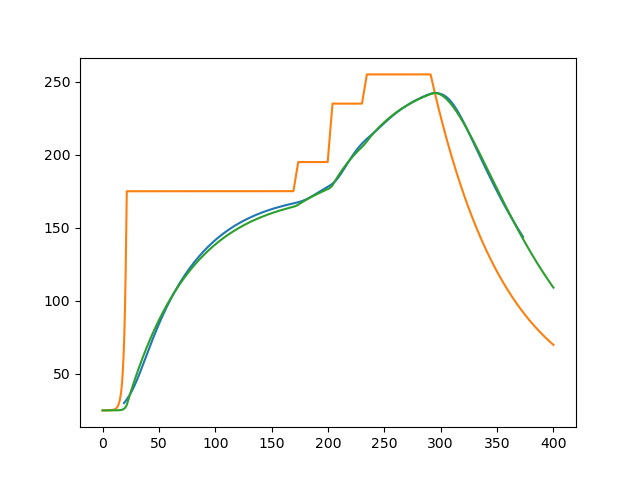
最后单独计算左端的k值为0.0128(·这个不是很重要,范围小数据少,对整体的影响不大)
分段 | 炉前 | 1-5 | 6 | 7 | 8-9 | 10-炉后 |
k | 0.0128 | 0.0177 | 0.0171 | 0.0242 | 0.0216 | 0.0276 |
第一问的求解
a=[0,25,30.5,5,30.5,5,30.5,5,30.5,5,30.5,5,30.5,5,30.5,5,30.5,5,30.5,5,30.5,5,30.5,25]
a=[i/78*60 for i in a]
m=0
a=[m:=m+i for i in a]
h=25
lmd0=-0.5
c0=(173-h)/(math.e**(-lmd0*25/78*60))
lmd=0.015
c=(257-h)/(math.e**(-lmd*339.5/78*60))
def T(t):
if t<a[1]:
return c0*math.e**(-lmd0*t)+h
elif t<a[10]:
return 173
elif t<a[11]:
return 173+(198-173)/(a[11]-a[10])*(t-a[10])
elif t<a[12]:
return 198
elif t<a[13]:
return 198+(230-198)/(a[13]-a[12])*(t-a[12])
elif t<a[14]:
# return 235
return 230
elif t<a[15]:
return 230+(257-230)/(a[15]-a[14])*(t-a[14])
elif t<a[18]:
return 257
else:
return c*math.e**(-lmd*t)+h
def k(t):
if t<a[1]:
return 0.0128
elif t<a[11]:
return 0.0177
elif t<a[13]:
return 0.0171
elif t<a[15]:
return 0.0242
elif t<a[18]:
return 0.0216
else:
return 0.0276aa=np.linspace(0,400,4001).tolist()
plt.plot(aa,[T(i)for i in aa])
bb=[25]
for i in aa:
bb.append(bb[-1]+k(i)*(T(i)-bb[-1])*0.1)
bb.pop()
plt.plot(aa,bb)
plt.show()
aa=[round(i,1) for i in aa]
print(bb[aa.index(round((a[6]+a[5])/2,1))])
print(bb[aa.index(round((a[11]+a[12])/2,1))])
print(bb[aa.index(round((a[13]+a[14])/2,1))])
print(bb[aa.index(round(a[16],1))])
# 128.42713353818752
# 167.691867327485
# 189.18635779121473
# 224.58207564933335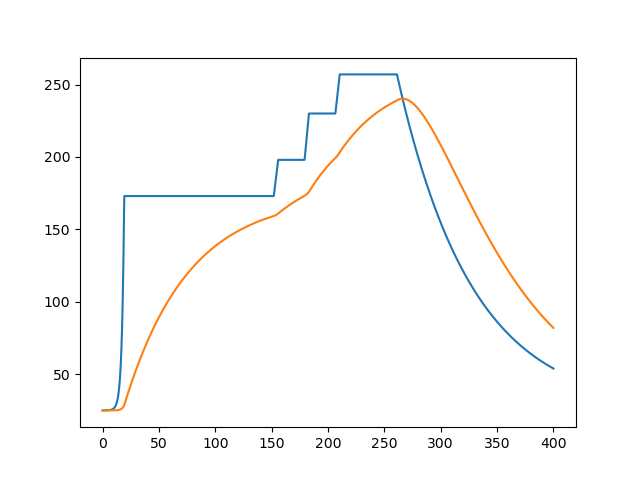
位置 | 小温区3中点 | 小温区6中点 | 小温区7中点 | 小温区8结束点 |
温度 | 128.42713353818752 | 167.691867327485 | 189.18635779121473 | 224.58207564933335 |















 3521
3521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









