







为什么要有哨兵?
对于主从结构的redis集群来说,可用性和可靠性相比于单机架构还是有不少的提升,抗压能力也得到了提高,但是对于主从结构来说有一个致命的问题就是说主节点挂了怎么办?对于从节点挂了还无伤大雅,无非就是数据能抗住的并发少了点,但是整个redis服务还是能响应用户的写请求和读请求;
可是最怕的就是主节点挂了,主节点一挂,整个redis服务就只能够提供读服务,写服务无法响应,这显然是致命的,无法进行写,那么我们读取的就是一些旧数据,这可能会导致客户端出现一些意想不到的错误。因此,一般主节点出现了问题,都是由我们开发人员,手动的去检查故障,然后重启主节点,可是redis机器可是7x24小时跑着的,我们开发人员无法预料到它什么时候会挂,就算是知道了我们去排查错误,然后重启也是需要一定的时间,那么在这段时间内,我们都无法给用户提供“写”服务,这显然是不科学的,公司利益是会受到损害的。
为了解决上述问题,redis提出了哨兵机制,该机制会在我们的主节点挂掉过后,在其从节点中新挑一个从节点来充当主节点,维持整个redis的正常服务;
什么是哨兵机制?
哨兵机制的大致工作原理如下:
我们在启动redis主从结构服务过后,我们会再多开几个单独的进程,这些进程就是哨兵进程。这些进程不存储数据,就专门用来监控主从结构中的所有节点,当这些监控进程检测到主节点挂掉过后,那么这些监控进程会从这个主节点中的从节点中挑选出一个从节点晋升为新的主节点,并且会将这个新的主节点的IP和端口号通知给此时连接着的客户端;
因此,说白了,哨兵机制主要包含三个方面:
- 检测主节点是否挂掉
- 选举新的主节点
- 通知客户端
接下来我们将围绕着这三个过程来具体讲一讲,哨兵节点如何检测到主节点挂了?如何选举新节点?如何通知客户端;
哨兵如何检测主节点是否已经挂了?
哨兵节点和主从节点之间都有心跳包机制,就比如说哨兵节点会定时的给主节点和从节点发送一个ping命令,主节点接收到这个命令过后,会立刻做出响应,如果在规定时间内哨兵节点没有接收到对应主节点的响应,那么这个哨兵节点就会认为这个主节点主观下线了,但是这仅仅是当前这个哨兵节点的个人意见,有可能是主节点与当前哨兵节点之间出现了网络波动,导致响应延迟了,而主节点和其他哨兵之间通信正常,如果这时候就简单的进行选新主节点的操作,成本也太高了;为了避免上述这个误判操作发生,当前这个哨兵节点会与其它的哨兵节点进行商量,这个商量过程如下:
当一个哨兵进程判断主节点主管下线过后,它会向其他哨兵进程发起命令,其它哨兵进程接收到这个命令过后,会根据自身与主节点的通信关系,投出赞成票和反对票;当这个哨兵节点的赞同票数达到哨兵配置未见中的quorum配置设定的值后,这时主节点会被认为客观下线,然后下一步就要进行选举主节点的操作了;
eg:现在有3个哨兵进程,quorum也设置为了2,那么此时一个哨兵进程认为主节点主观下线了,那么他就会去与其它两个哨兵进程进行商量,其它两个哨兵进程会根据自己与主节点的通信状态,投出赞成票和反对票,这时只需要其它两个哨兵进程至少投出一张暂存票再加上当前哨兵节点自己的赞成票就可以判定主节点客观下线了,之后就可以开始对从节点进行选主操作了;
哨兵如何选举出新的主节点?
当主节点被哨兵进程们判定为客观下线过后,哨兵进程们会会选出一个leader哨兵来全权处理新主节点的选举事宜;
而对于这个leader的选举,规则如下:
- 每个哨兵都会给其它哨兵发起拉票请求;
- 每个哨兵都只有一票;
- 每个哨兵可以将票投给自己或者其它哨兵;
- 一轮投票结束过后,票数大于等于(总哨兵数/2+1)的并且票数大于等于quorum的哨兵被选举为leader哨兵,全权负责新主节点的选举事宜;
如果存在多名哨兵向同一个哨兵拉票的情况,先到达的哨兵先拿到票,后续到来的哨兵没办法拿到票;
为了演示一下,这个拉票过程我们来演示一下:
具体实战如下:
我们使用docker创建了3个redis节点,这3个redis节点组成主从结构;
再用docker创建3个哨兵节点,quorum配置为2,来监控这3个redis节点;
大致结构如下:

通过docker日志和配置信息,我们可以知道:
master的ip地址为:172.18.0.3
slave0: 172.18.0.2
slave1: 172.18.0.4
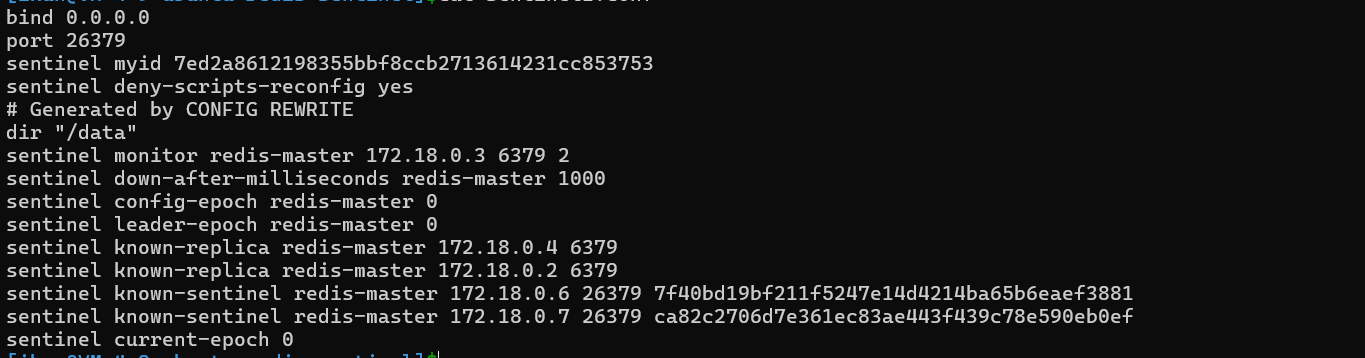
这是哨兵1的配置信息,通过配置信息我们可以看到,主节点和从节点的基本信息以及其它哨兵节点的信息;
接下来我们来模拟主节点挂掉的场景,使用
docker-compose stop redis-master来停止主节点:

接下来我们再来看看哨兵进程的日志信息:
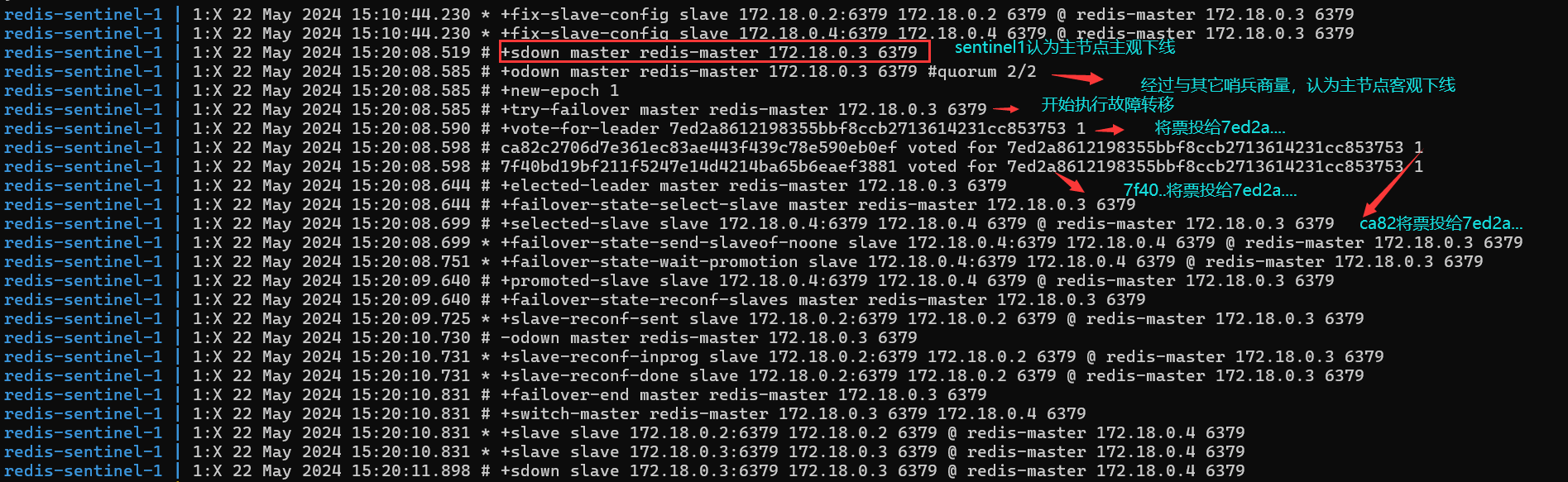


通过查看各个哨兵的配置文件,我们发现:

7ed2a…开头的编号是哨兵1,因此最后哨兵1的票最多,因此最后哨兵1回去完成换主的操作;
至此leader被选举出来了,因此哨兵1会去从节点中挑选出一个新的主节点,而挑选规则如下:
- 优先级越高的,先挑选,这个优先级由配置文件中的slave-priority或replica-priority决定;
- 优先级一样,必将各自的复制进度,复制进度越大的先挑选;
- 复制进度也一样,比较run_id,run_id较小的先挑选;

如何通知客户端?
经过前面一系列的操作后,哨兵集群终于完成主从切换的工作,那么新主节点的信息要如何通知给客户端呢?
这主要通过 Redis 的发布者/订阅者机制来实现的。每个哨兵节点提供发布者/订阅者机制,客户端可以从哨兵订阅消息。
客户端和哨兵建立连接后,客户端会订阅哨兵提供的频道。主从切换完成后,哨兵就会向 +switch-master 频道发布新主节点的 IP 地址和端口的消息,这个时候客户端就可以收到这条信息,然后用这里面的新主节点的 IP 地址和端口进行通信了。
通过发布者/订阅者机制机制,有了这些事件通知,客户端不仅可以在主从切换后得到新主节点的连接信息,还可以监控到主从节点切换过程中发生的各个重要事件。这样,客户端就可以知道主从切换进行到哪一步了,有助于了解切换进度。
总结
- 哨兵节点不能只有⼀个. 否则哨兵节点挂了也会影响系统可⽤性.
- 哨兵节点最好是奇数个. ⽅便选举 leader, 得票更容易超过半数.
- 哨兵节点不负责存储数据. 仍然是 redis 主从节点负责存储.
- 哨兵 + 主从复制解决的问题是 “提⾼可⽤性”, 不能解决 “数据极端情况下写丢失” 的问题.
- 哨兵 + 主从复制不能提⾼数据的存储容量. 当我们需要存的数据接近或者超过机器的物理内存, 这样的结构就难以胜任了.为了能存储更多的数据, 就引⼊了集群.
















 4954
4954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











