






统计模型识别的新视角–《A new look at the statistical model identification》全文阅读
摘要
简要回顾了时间序列分析中统计假设检验的发展历史,并指出假设检验过程不足以定义为统计模型识别的过程。回顾了经典的极大似然估计过程,并引入了一种新的估计,即最小信息理论准则(AIC)估计(MAICE),其设计目的在于统计识别。当存在几种竞争模型时,MAICE 由提供最小 AIC 的模型和参数的极大似然估计值定义,AIC 定义为 AIC = (—2)log (极大似然) + 2(模型中独立调整的参数数量)。MAICE 提供了一种用于统计模型识别的多功能程序,不受传统假设检验程序应用中固有的歧义影响。通过一些数值例子,展示了 MAICE 在时间序列分析中的实际效用。
一、引言
尽管最近统计概念和模型在几乎所有工程和科学领域的应用取得了发展,但似乎并未充分认识到基于有限数量观测值所提供的信息构建适当模型的困难。毫无疑问,统计模型构建或识别的主题很大程度上取决于对观测对象的理论分析结果。然而,必须认识到,理论结果与实际识别程序之间通常存在很大的差距。一个典型的例子是线性系统最小实现理论的结果与基于有限持续时间记录的随机过程马尔可夫表示的识别之间的差距。线性系统的最小实现通常是通过分析某个 Hankel 矩阵的秩或行或列的依赖关系来定义的 [1]。在实际情况中,即使 Hankel 矩阵理论上给定,舍入误差也会使矩阵始终满秩。如果矩阵是从真实对象的观测记录中获得的,则矩阵元素的抽样变异性将远远大于舍入误差,而且系统将始终是无限维的。因此可以看出,统计识别的主题本质上与近似的艺术有关,这是人类智力活动的基本要素。
正如 Lehman [2, p. viii] 注意到的那样,假设检验程序传统上应用于实际需要多重决策程序的情况。如果将统计识别程序视为决策程序,那么最基本的问题是损失函数的适当选择。在 Neyman-Pearson 统计假设检验理论中,仅考虑拒绝和接受正确和不正确假设的概率来定义决策造成的损失。在实际情况中,假定的零假设仅是近似值,并且几乎总是与现实不同。因此,在检验理论中选择损失函数使其实际应用在逻辑上是矛盾的。认识到这一点,即假设检验程序没有充分地公式化为一种近似程序,对于开发实用的识别程序非常重要。
通过分析非常实用且成功的极大似然法,获得了识别问题的新视角。在某些正则条件下,极大似然估计渐近有效这一事实表明,似然函数倾向于成为对参数围绕真值的小变化最敏感的量。这一观察结果表明,可以使用
S ( g ; f ( x ∣ θ ) ) = ∫ g ( x ) log f ( x ∣ θ ) d x S(g;f(x|\theta)) = \int g(x) \log f(x|\theta) dx S(g;f(x∣θ))=∫g(x)logf(x∣θ)dx
作为衡量模型与由概率密度函数 f(x| θ \theta θ) 定义的概率结构对由密度函数 g(x) 定义的结构的“拟合度”的标准。与经典极大似然估计程序中假定单个密度族 f(x| θ \theta θ) 不同,在通常的识别情况中,会考虑几种替代模型或族,这些模型或族由具有不同形式的密度函数和/或具有相同形式但对参数向量 θ \theta θ 有不同限制的密度函数定义。对极大似然估计 (MLE) 的详细分析自然导致了新的估计量的定义,该估计量适用于这种多模型情况。新的估计量称为最小信息理论准则 (AIC) 估计 (MAICE),其中 AIC 代表由本作者最近引入的信息理论准则 [3],并且是衡量模型拟合度的估计量。MAICE 由模型及其参数值定义,这些值给出由 AIC 定义的最小 AIC 值,其中 AIC = (—2)log (极大似然) + 2(模型中独立调整的参数数量)。通过引入 MAICE,统计识别问题被明确地公式化为估计问题,并且完全消除了假设检验程序中对显著性水平决策所需的主观判断。为了给出 MAICE 的明确定义并通过与传统方法的比较来讨论其特性,
授权有限使用:济南大学。于世界标准时间 2025 年 4 月 15 日 07:09:03 从 IEEE Xplore 下载。适用限制。
以及假设检验构成本文的主要目标。虽然 MAICE 提供了一种多功能的识别方法,可用于统计模型构建的各个领域,但其在时间序列分析中的实际效用非常显著。给出了一些数值示例,以展示 MAICE 如何为时间序列分析问题提供客观定义的答案,这与传统假设检验方法形成对比,后者只能提供主观且往往不确定的答案。
二、时间序列分析中的假设检验
时间序列检验程序的研究始于对单个序列相关系数等于 0 的简单假设的检验。这类检验的效用当然过于有限,无法使其成为用于模型识别的通用实用程序。1947 年,Quenouille [4] 引入了一种用于检验自回归 (AR) 模型拟合优度的检验。Quenouille 检验的思想被 Wold [5] 扩展到用于检验移动平均 (MA) 模型拟合优度的检验。随后出现了这些检验程序的几种改进和推广 [6]-[9],但 Whittle [10], [11] 通过将 Neyman-Pearson 似然比检验程序系统地应用于时间序列情况,对时间序列分析中的假设检验主题做出了最重大的贡献。一个非常基本的时间序列检验是白噪声检验。在许多模型识别情况下,拟合模型后残差序列的白噪声性被要求作为模型充分性的证明,并且白噪声检验在实际应用中被广泛使用 [12]-[15]。对于白噪声检验,周期图分析提供了通用解决方案。Hannan [16] 对经典假设检验程序(包括基于周期图的检验)进行了很好的阐述。AR 或 MA 模型的拟合本质上是一个多重决策程序的主题,而不是假设检验的主题。Anderson [17] 将高斯 AR 过程阶数的确定明确地讨论为多重决策程序。该程序采用一系列模型的检验形式,从最高阶开始,然后依次向下到最低阶。要将该程序应用于实际问题,必须为模型的每个阶数指定检验的显著性水平。虽然该程序旨在满足某些明确定义的最优性条件,但阶数确定的本质困难仍然在于选择显著性水平的困难。此外,决策程序的损失函数由做出错误决策的概率定义,因此该程序并非没有逻辑矛盾,即在实际应用中,真实结构的阶数将始终是无限的。只有通过将问题明确地重新表述为模型对真实结构的近似问题,才能避免这一困难。
三、模型误差控制的直接方法
在非时间序列回归分析领域,Mallows 引入了一种统计量 Cp 用于回归变量的选择 [18]。Cp 的定义为 Cp = ( σ ^ 2 \hat{\sigma}^2 σ^2) − 1 ^{-1} −1 (残差平方和) – N + 2p,其中 σ ^ 2 \hat{\sigma}^2 σ^2 是对真实残差未知方差 σ 2 \sigma^2 σ2 的适当选择的估计量,N 是观测值数量,p 是回归中的变量数量。如果拟合模型准确,Cp 的期望值大致为 p,否则更大。Cp 是在使用估计的回归系数进行预测时预测平方和的期望值的估计量,按 σ 2 \sigma^2 σ2 进行缩放,并且具有明确定义的含义,作为所采用模型充分性的度量。由于具有这一明确定义的拟合标准,Cp 引起了关注实际数据回归分析人员的严重关注。参见 [18] 的参考文献。不幸的是,在 Cp 的定义中对 σ ^ 2 \hat{\sigma}^2 σ^2 的选择需要一些主观判断。几乎在引入 Cp 的同时,Davisson [19] 分析了使用预测器估计系数进行预测时平稳高斯过程的均方预测误差,并讨论了自适应平滑滤波器 [20] 的均方误差。观测到的时间序列 xt 是信号 st 和加性白噪声 nt 的总和。滤波输出 s t ^ \hat{st} st^ 由下式给出
s ^ t = ∑ j = 0 M a j x t − j \hat{s}_t = \sum_{j=0}^{M} a_j x_{t-j} s^t=j=0∑Majxt−j
其中 aj 由样本 xt (t = 1,2,…,N) 确定。问题是如何定义 M 和 L,以使 N 个样本的均方平滑误差 E[(1/N) ∑ t = 1 N ( s t − s ^ t ) 2 \sum_{t=1}^N (s_t - \hat{s}_t)^2 ∑t=1N(st−s^t)2] 最小。在对 st 和 nt 进行适当假设的情况下,Davisson [20] 得到了该误差的估计量,其定义为
e N 2 [ M , L ] = σ ^ 2 + 2 δ ^ ( M + L + 1 ) / N e_N^2[M,L] = \hat{\sigma}^2 + 2\hat{\delta}(M + L + 1)/N eN2[M,L]=σ^2+2δ^(M+L+1)/N
其中 σ ^ 2 \hat{\sigma}^2 σ^2 是误差方差的估计量, δ ^ \hat{\delta} δ^ 是当 (M + L)/N 处于“较大”值时 σ ^ 2 \hat{\sigma}^2 σ^2 作为 (M + L)/N 函数的斜率。该结果与 Mallows 的 Cp 密切相关,并表明这类统计量在预测模型识别领域的重要性。与 Mallows 的 Cp 中 δ ^ \hat{\delta} δ^ 的选择一样,本统计量 eN2[M, L] 中 δ ^ \hat{\delta} δ^ 的选择成为实际应用中的一个难题。1969 年,在不知道与上述两个程序密切相关的情况下,本作者引入了由 yt = ϕ 1 y t − 1 + . . . + ϕ p y t − p + z t \phi_1 y_{t-1} + ... + \phi_p y_{t-p} + z_t ϕ1yt−1+...+ϕpyt−p+zt 定义的单变量 AR 模型拟合程序,其中 zt 是白噪声 [21]。在该程序中,通过使用最小二乘估计系数获得的单步预测的均方误差被控制。该均方误差称为最终预测误差 (FPE),当数据 yt (t = 1,2,…,N) 给定时,其估计量由下式定义
由下式定义
FPE ( p ) = { ( N + p ) / ( N − p ) } ( 1 / N ) ∑ t = p + 1 N ( y t − y ^ t ) 2 \text{FPE}(p) = \{ (N + p)/(N - p) \} (1/N) \sum_{t=p+1}^N (y_t - \hat{y}_t)^2 FPE(p)={(N+p)/(N−p)}(1/N)t=p+1∑N(yt−y^t)2
其中 y_t 的平均值假定为 0,C_l = (1/N) ∑ t = 1 N − l y t y t + l \sum_{t=1}^{N-l} y_t y_{t+l} ∑t=1N−lytyt+l,并且通过求解由 C_l 定义的 Yule-Walker 方程获得 a ^ i \hat{a}_i a^i。通过将 p 从 0 连续扫描到某个上限 L,由给出 FPE§ 最小值的 p 和相应的 a ^ i \hat{a}_i a^i 定义识别的模型 ( p = 0 , 1 , . . . , L p = 0,1,...,L p=0,1,...,L)。在此过程中,FPE§ 的定义中没有留下任何主观元素。只有上限 L 的确定需要判断。该程序的特性得到了进一步分析 [22],并且该程序在实际数据方面效果显著 [23], [24]。Gersch 和 Sharp [25] 讨论了他们使用该程序的经验。Bhansali [26] 报告了非常令人失望的结果,声称这些结果是 Akaike 方法获得的。实际上,令人失望的结果是由于他错误地定义了相关统计量,与目前的最小 FPE 程序无关。该程序被扩展到多变量 AR 模型拟合的情况 [27]。Otomo 等人 [28] 报告了基于该识别程序获得的结果实现的计算机控制水泥窑过程的成功结果。本节讨论的三个程序的一个共同特点是,对统计量的分析已扩展到主误差的 O(1/N)。
四、平均对数似然作为拟合度量
众所周知,MLE 在正则条件下渐近有效 [29],这表明似然函数倾向于成为对模型参数偏离真实值的微小偏差最敏感的标准。考虑以下情况:x1, x2,…, xN 是随机变量 N 次独立观测的结果,该随机变量具有概率密度函数 g(x)。如果参数密度函数族由 f(x| θ \theta θ) 给出,其中 θ \theta θ 是向量参数,则平均对数似然或对数似然除以 N 由下式给出
( 1 / N ) ∑ i = 1 N log f ( x i ∣ θ ) (1/N) \sum_{i=1}^N \log f(x_i|\theta) (1/N)i=1∑Nlogf(xi∣θ)
其中,如本文后续部分所述,log 表示自然对数。随着 N 的无限增加,该平均值以概率 1 趋近于
S ( g ; f ( ⋅ ∣ θ ) ) = ∫ g ( x ) log f ( x ∣ θ ) d x S(g;f(\cdot|\theta)) = \int g(x) \log f(x|\theta) dx S(g;f(⋅∣θ))=∫g(x)logf(x∣θ)dx
其中假定积分存在。从 MLE 的效率可以看出,(平均) 平均对数似然 S(g;f( ⋅ \cdot ⋅| θ \theta θ)) 必须是对 f(x| θ \theta θ) 偏离 g(x) 的微小偏差最敏感的标准。差值
I ( g ; f ( ⋅ ∣ θ ) ) = S ( g ) − S ( g ; f ( ⋅ ∣ θ ) ) I(g;f(\cdot|\theta)) = S(g) - S(g;f(\cdot|\theta)) I(g;f(⋅∣θ))=S(g)−S(g;f(⋅∣θ))
被称为 Kullback-Leibler 平均信息,用于区分 g(x) 和 f(x| θ \theta θ),并且其值为正,除非 f(x| θ \theta θ) = g(x) 几乎处处成立 [30]。这些观测表明,S(g;f( ⋅ \cdot ⋅| θ \theta θ)) 将是一个合理的标准,通过最大化它,或者通过最小化 -S(g;f( ⋅ \cdot ⋅| θ \theta θ)) (类似于熵的概念),来定义最佳拟合模型。这里应该提到,在 1950 年,这最后一个量被 Bartlett [31] 采纳为信息函数的定义。S(g;f( ⋅ \cdot ⋅| θ \theta θ)) 最重要的特性之一是其自然估计量,即平均对数似然 (1),无需了解 g(x) 即可获得。当仅给定一个族 f(x| θ \theta θ) 时,通过对 θ \theta θ 最大化 S(g;f( ⋅ \cdot ⋅| θ \theta θ)) 的估计量 (1) 会得到 MLE θ ^ \hat{\theta} θ^。在统计识别的情况下,通常给定几个 f(x| θ \theta θ) 族,这些族具有不同形式的 f(x| θ \theta θ) 和/或具有相同形式但对参数向量 θ \theta θ 有不同限制的族,并且需要决定 f(x| θ \theta θ) 的最佳选择。经典的极大似然原理不能为这类问题提供有用的解决方案。通过将前一节讨论的统计量所依据的基本思想与极大似然原理相结合,可以获得解决方案。考虑 g(x) = f(x| θ 0 \theta_0 θ0) 的情况。对于这种情况,I(g;f( ⋅ \cdot ⋅, θ \theta θ)) 和 S(g;f( ⋅ \cdot ⋅| θ \theta θ)) 将简单地表示为 I( θ 0 \theta_0 θ0; θ \theta θ) 和 S( θ 0 \theta_0 θ0; θ \theta θ),分别。当 θ \theta θ 充分接近 θ 0 \theta_0 θ0 时,I( θ 0 \theta_0 θ0; θ \theta θ) 可以近似为 [30]
I ( θ 0 ; θ 0 + Δ θ ) = 1 2 ∣ Δ θ ∣ J 2 I(\theta_0;\theta_0 + \Delta\theta) = \frac{1}{2} |\Delta\theta|_{J}^2 I(θ0;θ0+Δθ)=21∣Δθ∣J2
其中 ∣ Δ θ ∣ J 2 = Δ θ ′ J Δ θ |\Delta\theta|_J^2 = \Delta\theta' J \Delta\theta ∣Δθ∣J2=Δθ′JΔθ,J 是 Fisher 信息矩阵,它是正定的,定义为
J = E [ − ∂ 2 log f ( X ∣ θ ) ∂ θ i ∂ θ j ] J = E[-\frac{\partial^2 \log f(X|\theta)}{\partial \theta_i \partial \theta_j}] J=E[−∂θi∂θj∂2logf(X∣θ)]
其中 J i j J_{ij} Jij 表示 J 的 (i,j) 元素, t h e t a i theta_i thetai 是 θ \theta θ 的第 i 个分量。因此,当 θ \theta θ 的 MLE θ ^ \hat{\theta} θ^ 非常接近 θ 0 \theta_0 θ0 时,由 f(x| θ ^ \hat{\theta} θ^) 定义的分布与真实分布 f(x| θ 0 \theta_0 θ0) 之间的偏差,以 S(g;f( ⋅ \cdot ⋅| θ \theta θ)) 的变化衡量,将由 1 2 ∣ θ ^ − θ 0 ∣ J 2 \frac{1}{2} |\hat{\theta} - \theta_0|_J^2 21∣θ^−θ0∣J2 衡量。考虑将 θ \theta θ 的变动限制在 θ \theta θ 的一个不包含 θ 0 \theta_0 θ0 的低维子空间 Θ \Theta Θ 的情况。对于限制在 Θ \Theta Θ 内的 θ \theta θ 的 MLE θ ^ \hat{\theta} θ^,如果 θ ^ \hat{\theta} θ^ 在 Θ \Theta Θ 中且给出 S( θ 0 \theta_0 θ0; θ \theta θ) 的最大值足够接近 θ 0 \theta_0 θ0,则可以证明,在某些正则条件下,对于足够大的 N,N 1 2 ∣ θ ^ − θ 0 ∣ J 2 \frac{1}{2} |\hat{\theta} - \theta_0|_J^2 21∣θ^−θ0∣J2 的分布近似于自由度等于受限参数空间维数的卡方分布。例如参见 [32]。因此,成立
E [ 2 N I ( θ 0 ; θ ^ ) ] ≈ k E [ 2N I(\theta_0; \hat{\theta}) ] \approx k E[2NI(θ0;θ^)]≈k
其中 E [ ⋅ ] E[\cdot] E[⋅] 表示近似分布的均值,k 是 θ \theta θ 的维数或为最大化似然而独立调整的参数数量。关系 (2) 是前一节讨论的统计量所依据的期望预测误差的推广。当有几种模型时,自然会采用给出 E [ I ( g ; f ( ⋅ ∣ θ ) ) ] E[I(g;f(\cdot|\theta))] E[I(g;f(⋅∣θ))] 最小值的模型。为此,考虑到这些模型的 θ ^ \hat{\theta} θ^ 非常接近 θ 0 \theta_0 θ0 的情况,有必要开发一些估计量来估计 (2) 中的 N 1 2 ∣ θ ^ − θ 0 ∣ J 2 N \frac{1}{2} |\hat{\theta} - \theta_0|_J^2 N21∣θ^−θ0∣J2。关系 (2) 基于 N ( θ ^ − θ 0 ) \sqrt{N}(\hat{\theta} - \theta_0) N(θ^−θ0) 的渐近分布近似于均值为零方差矩阵为 J − 1 J^{-1} J−1 的高斯分布这一事实。由此,如果
2 ( ∑ i = 1 N log f ( x i ∣ θ ^ ) − ∑ i = 1 N log f ( x i ∣ θ 0 ) ) 2 (\sum_{i=1}^N \log f(x_i|\hat{\theta}) - \sum_{i=1}^N \log f(x_i|\theta_0)) 2(i=1∑Nlogf(xi∣θ^)−i=1∑Nlogf(xi∣θ0))
用作 N 1 2 ∣ θ ^ − θ 0 ∣ J 2 N \frac{1}{2} |\hat{\theta} - \theta_0|_J^2 N21∣θ^−θ0∣J2 的估计量,则需要对由将 θ 0 \theta_0 θ0 替换为 θ ^ \hat{\theta} θ^ 引入的向下偏差进行修正。这种修正只需在 (3) 中加上 k 即可实现。对于识别的目的,只需比较不同模型的 E [ I ( g ; f ( ⋅ ∣ θ ) ) ] E[I(g;f(\cdot|\theta))] E[I(g;f(⋅∣θ))] 估计量的值,因此包含 θ 0 \theta_0 θ0 的 (3) 中的公共项可以舍弃。
五、信息准则的定义
基于前一节的观察,将 θ \theta θ 的信息准则 AIC 定义为
AIC ( θ ^ ) = ( − 2 ) log ( maximum likelihood ) + 2 k \text{AIC}(\hat{\theta}) = (-2) \log (\text{maximum likelihood}) + 2k AIC(θ^)=(−2)log(maximum likelihood)+2k
其中,如前所述,k 是为获得 θ ^ \hat{\theta} θ^ 而独立调整的参数数量。(1/N) AIC( θ ^ \hat{\theta} θ^) 可以视为 -2E S(g;f( ⋅ \cdot ⋅| θ \theta θ)) 的估计量。IC 代表信息准则,添加 A 以便可以效仿类似的统计量,如 BIC、DIC 等。当有几种对应于不同模型的 f(x| θ \theta θ) 规范时,MAICE 由给出最小 AIC( θ ^ \hat{\theta} θ^) 的 f(x| θ \theta θ) 定义。当只有一个无约束的 f(x| θ \theta θ) 族时,MAICE 由 f(x| θ ^ \hat{\theta} θ^) 定义,其中 θ ^ \hat{\theta} θ^ 与经典的 MLE 相同。应该注意到,当不打算比较不同观测集的结果时,可以在 AIC( θ ^ \hat{\theta} θ^) 的定义中引入任意加性常数。MAICE 的当前定义给出了模型构建中简约性原则的数学表述。当两个模型的极大似然相同,MAICE 是由参数数量较少的模型定义。在时间序列分析中,即使在高斯假定下,似然的精确定义通常也过于复杂而难以实用,因此需要进行一些近似。对于 MAICE 的应用,在定义似然函数的近似时存在一个微妙的问题。这是因为为了定义 AIC,对数似然必须一致地定义到数量级 1。对于平稳高斯过程模型的拟合,模型偏离真实结构的度量可以定义为当观测数量 N 无限增加时平均平均对数似然的极限。该量与由拟合模型定义的创新过程的平均对数似然相同。因此,对于将平稳零均值高斯过程模型拟合到观测序列 y1, y2,…, yN 的自然程序是定义一个基本平稳高斯模型,其 l 滞后协方差矩阵 R(l) 定义为
R ( l ) = ( 1 / N ) ∑ t = 1 N − l y t y t + l R(l) = (1/N) \sum_{t=1}^{N-l} y_t y_{t+l} R(l)=(1/N)t=1∑N−lytyt+l
l = 0 , 1 , 2 , . . . , N − 1 l = 0,1,2,...,N-1 l=0,1,2,...,N−1,并通过最大化创新过程的平均对数似然进行拟合,或者等价地,如果创新过程协方差矩阵的元素在参数集内,则最小化创新过程方差矩阵的对数行列式,其 N 倍将用于代替 AIC 定义中的对数似然。在 R(l) 的定义中采用除数 N 对于保持协方差矩阵序列正定至关重要。通过基本模型拟合高斯过程模型的当前程序在 [33] 中详细讨论。它自然导致了 Whittle [34] 发展的高斯估计的概念。当 yt 的标准化相关系数的渐近分布与高斯过程的渐近分布相同时,定义为这些系数函数的统计量的渐近分布也将与高斯过程的假定无关。这一点和 AIC 当前定义所需的渐近行为在 Whittle 的上述论文中详细讨论。对于单变量高斯 AR 模型的拟合,用当前 AIC 定义定义的 MAICE 与通过最小 FPE 程序获得的估计渐近一致。AIC 和 MAICE 的原始定义由本作者于 1971 年首次引入 [3]。早期成功的应用结果在 [3], [35], [36] 中报告。
六、数值例子
在讨论 MAICE 特性之前,本节将展示其实际效用。为了方便可能希望自行检查结果的读者,将高斯 AR 模型拟合到 Anderson 时间序列分析书中给出的数据 [37]。对于 Wold 用二阶 AR 方案人工生成的三组序列,拟合了高达 50 阶的模型。在两种情况下,MAICE 是二阶模型。在 MAICE 是一阶模型的情况下,生成方程的二阶系数的绝对值与其采样变异性相比非常小,并且对于用 MLE 的系数定义的二阶模型,单步预测误差方差对于 MAICE 更小。对于 N = 176 的经典 Wolfer 太阳黑子数序列,拟合了高达 35 阶的 AR 模型,MAICE 是八阶模型。AIC 在二阶处达到局部最小值。对于 N = 370 的 Beveridge 小麦价格指数序列,AR 模型拟合到 50 阶,MAICE 再次是八阶。AIC
在二阶处达到局部最小值,这被 Sargan [38] 采纳。根据 Anderson 对这些序列的讨论,为这两组序列选择八阶模型似乎是合理的。[3] 中报告了最小 FPE 程序(该程序产生的估计量与 MAICE 渐近等价)的两个应用例子。在取自 Jenkins 和 Watts 书籍 [39,第 5.4.3 节] 的例子中,估计量与该书作者在仔细分析后选择的估计量相同。在 Whittle [40] 处理的湖震记录的情况下,最小 FPE 程序清楚地表明需要非常高阶的 AR 模型。Whittle [41,第 38 页] 讨论了将 AR 模型拟合到这组数据的困难。该程序还应用于 Box 和 Jenkins [12] 书籍中给出的序列 F 和 F。作者建议对序列 F 使用二阶或三阶 AR 模型,该序列是 N = 100 的 Wolfer 太阳黑子数序列的一部分。高达 20 阶的 AR 模型中的 MAICE 是二阶模型。对 N = 70 的序列 F 拟合的 AR 模型中,高达 10 阶的 MAICE 是二阶模型,这与该书作者提出的建议一致。为了测试区分 AR 和 MA 模型的能力,通过关系 y t = z t + 0.6 z t − 1 − 0.1 z t − 2 y_t = z_t + 0.6 z_{t-1} - 0.1 z_{t-2} yt=zt+0.6zt−1−0.1zt−2 生成了十组 y t y_t yt (n = 1,…,1600) 序列,其中 z t z_t zt 从物理噪声源生成,并被假定为高斯白噪声。AR 模型拟合到每个序列的前 N 个点,对于 N = 50, 100, 200, 400, 800, 1600。对于连续增加的 N 值,MAICE AR 阶的样本平均值分别为 3.1, 4.1, 6.5, 6.8, 8.2 和 9.3。将近似 MAICE 程序(该程序旨在为马尔可夫模型拟合获取 MAICE 的初始估计量,如 [33] 中所述)应用于这些数据。除少数例外,近似 MAICE 是二阶。这对应于具有二阶 AR 和一阶 MA 的 AR-MA 模型。然后将二阶和三阶 MA 模型拟合到 N = 1600 的数据。在拟合到数据的 AR 和 MA 模型中,二阶 MA 模型被选为 MAICE 九次,三阶 MA 被选为一次。AR 和 MA 模型之间 AIC 最小值的平均差为 7.7,这大致意味着对于 N = 1600 的一组数据,一对两个拟合模型的预期似然比约为 47,有利于 MA 模型。另一个测试使用 Gersch 和 Sharp [25] 讨论的例子。通过文中描述的 AR-MA 方案生成了八组长度 N = 800 的序列。MAICE AR 阶的平均值为 17.9,这与 Gersch 和 Sharp 报告的值非常吻合。应用近似 MAICE 程序来确定过程的马尔可夫表示的阶数或维数。对于八个案例,该程序完全识别了正确的阶数四。将不同阶数的 AR-MA 模型拟合到一组数据,并计算相应的 AIC(p,q) 值,其中 AIC(p,q) 是 AR 阶数为 p 和 MA 阶数为 q 的模型的 AIC 值,并定义为
AIC ( p , q ) = N log ( MLE of innovation variance ) + 2 ( p + q ) \text{AIC}(p,q) = N \log (\text{MLE of innovation variance}) + 2(p + q) AIC(p,q)=Nlog(MLE of innovation variance)+2(p+q)
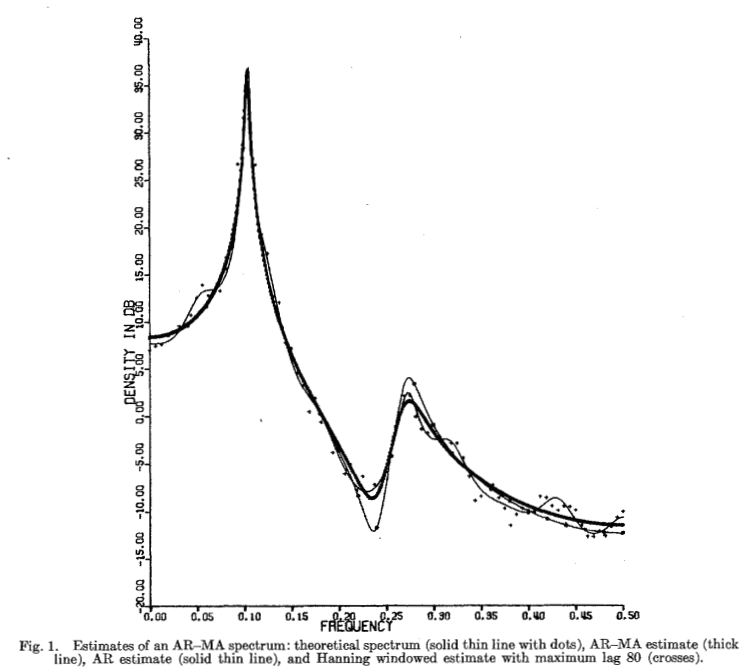
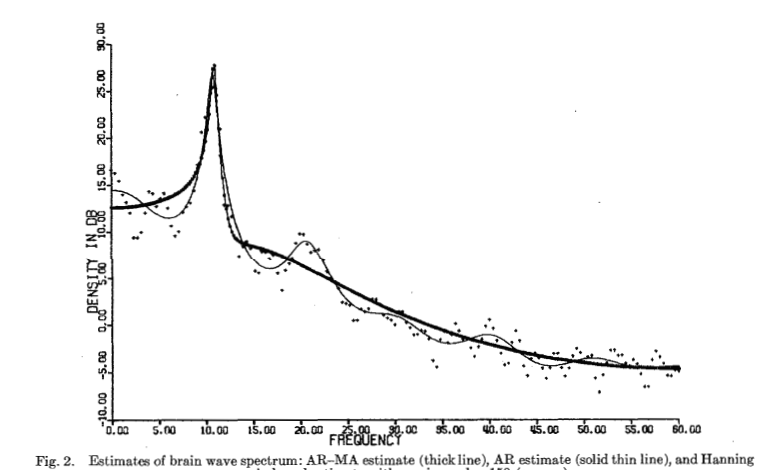
结果为 AIC(4,2) = 192.72, AIC(4,3) = 66.54, AIC(4,4) = 67.44, AIC(5,3) = 67.48 AIC(6,3) = 67.65, 和 AIC(5,4) = 69.43。最小值在 p = 4 和 q = 3 处达到,这对应于真实结构。图 1 说明了通过将各种程序应用于这组数据获得的功率谱密度估计。应该提到的是,在此示例中,对于 p 和 q 同时大于 4 和 3 的模型,平均对数似然函数的 Hessian 在参数的真实值处变得奇异。与此奇异性相关的困难的详细讨论超出了本文的范围。图 2 显示了将相同类型的程序应用于 N = 1420 的脑电波记录的结果。在这种情况下,只拟合了一个 AR 阶数为 4 和 MA 阶数为 3 的 AR-MA 模型。此模型的 AIC 值为 1145.6,而 MAICE AR 模型的 AIC 值为 1120.9。这表明 13 阶 MAICE AR 模型是更好的选择,这一结论似乎与从检查图 2 获得的印象非常吻合。
七、讨论
当 f(x| θ \theta θ) 与 g(x) 相距很远时,S(g;f( ⋅ \cdot ⋅| θ \theta θ)) 只是衡量 f(x| θ \theta θ) 与 g(x) 偏离程度的主观指标。因此,只有在假定至少一个族 f(x| θ \theta θ) 足够接近 g(x) 且与 f(x| θ ^ \hat{\theta} θ^) 偏离 f(x| θ \theta θ) 的预期偏差相比时,才可能对 MAICE 的特性进行一般性讨论。仅当存在几个满足此条件的族时,才有必要对 MAICE 的统计特性进行详细分析。作为 -2N S(g;f( ⋅ \cdot ⋅| θ \theta θ)) 的单一估计量,-2 乘以对数极大似然就足够了,但对于当前“估计” -2N S(g;f( ⋅ \cdot ⋅| θ \theta θ)) 之“差”的目的,在 AIC 定义中引入 +2k 项至关重要。Bhansali [26] 报告的令人失望的结果是由于他对统计量的错误使用,这相当于在 AIC 中使用 +k 而不是 +2k。当模型通过对 f(x| θ \theta θ) 的参数 θ \theta θ 施加的限制逐步增加而指定时,MAICE 程序采用重复应用传统的拟合优度对数似然比检验的形式,其显著性水平由 +2k 项自动调整。当存在不同族以同等程度近似真实似然时,至少局部情况将由同一族的不同参数化近似。对于这些情况,两个模型之间 AIC 差异的显著性将通过将其与两个模型 k 值之差的卡方变量的变异性进行比较来评估。当两个模型在 Cox [42], [43] 的意义上形成独立的族时,由 Cox 提出并由 Walker [44] 扩展到时间序列情况的程序可能对详细评估 AIC 的差异很有用。必须清楚地认识到,MAICE 不能与假设检验程序进行比较,除非后者被定义为具有所需显著性水平的决策程序。使用固定的显著性水平比较不同参数数量的模型是错误的,因为它没有考虑到随着参数数量增加而估计量变异性的增加。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









