






https://i-chen.icu/?p=384
Spark 介绍
Apache Spark(简称Spark)是一个开源的统一分析引擎,专为大规模数据处理设计。它最初由加利福尼亚大学伯克利分校的AMPLab开发,旨在克服Hadoop MapReduce的局限性。Spark能够进行内存中的数据处理,这使得它在处理迭代算法和交互式数据分析时,比传统的MapReduce要快得多(Amazon Web Services, Inc.) (Apache Spark)。
安装
wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz2. Unpack:
tar -zxvf spark-3.3.2-bin-hadoop3.tgz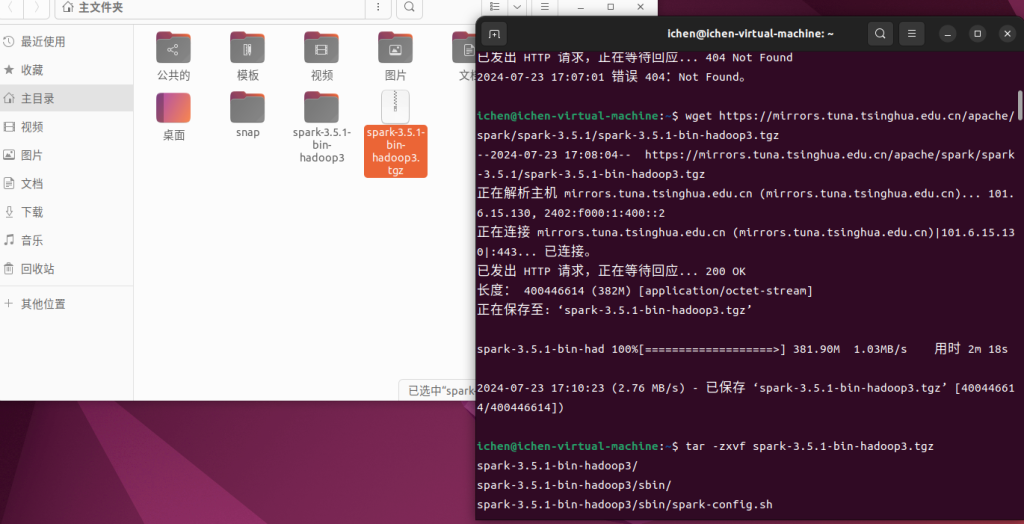
3. 用 “java -version” Check 是否有安装Java,若无,根据指示安装。
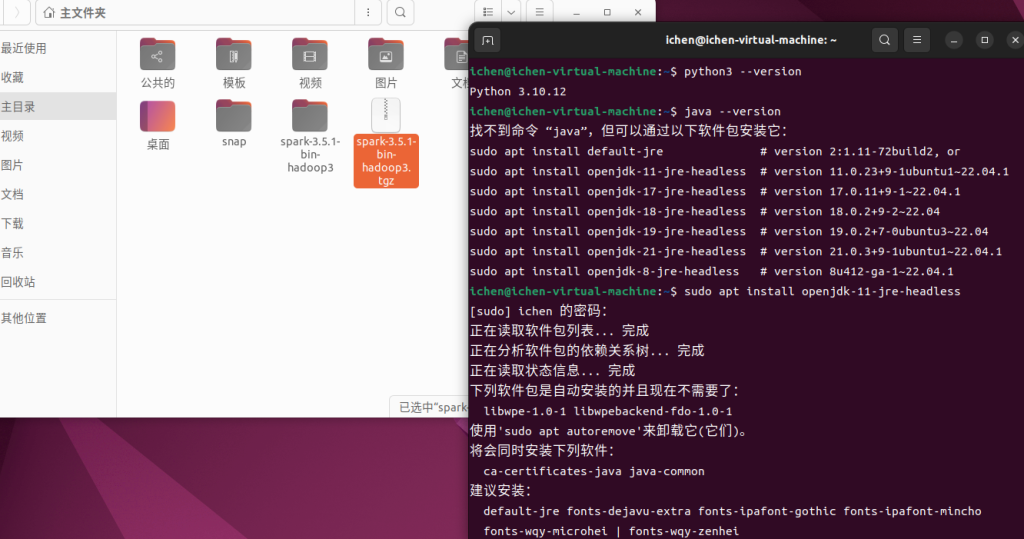
4. 配置环境变量:
vi ~/.bashrc按I进入Insert模式,在末尾添加:(如果无法进入Insert模式,说明Vim未安装,需要通过Sudo Apt Install Vim安装Vim编辑器)
export SPARK_HOME=~/spark-3.5.1-bin-hadoop3
export PATH=${SPARK_HOME}/bin:$PATHEsc退出Insert模式,输入:Wq命令保存并退出Vim。
5. 使用source ~/.bashrc使.Bashrc文件配置生效。
6. Pyspark/Ctrl+D退出
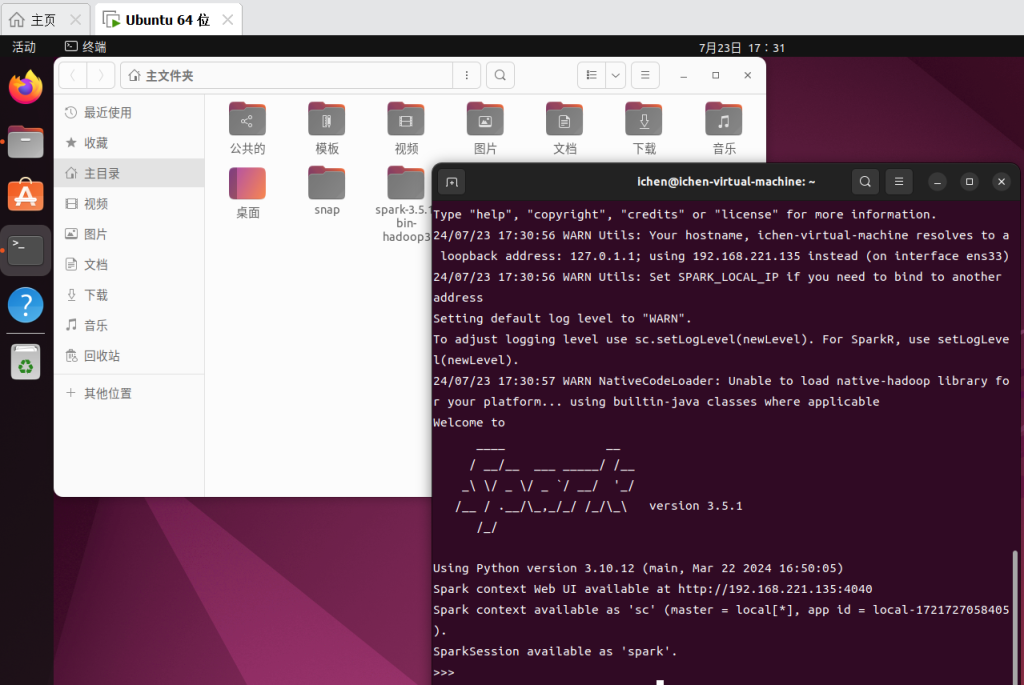
Jupyter配置
参考了:Https://Www.Cnblogs.Com/Kingwz/P/18132309
先安装Anaconda,需要下载.Sh文件。老规矩,先上清华镜像!:Https://Mirrors.Tuna.Tsinghua.Edu.Cn/Anaconda/Archive/ 不过我用Wget命令获取时出现了403错误,通过在Windows下载粘贴过去的。
使用Bash命令进行安装,一直回车到Answer Yes Or No。
Bash Anaconda3-2024.02-1-Linux-x86_64.Sh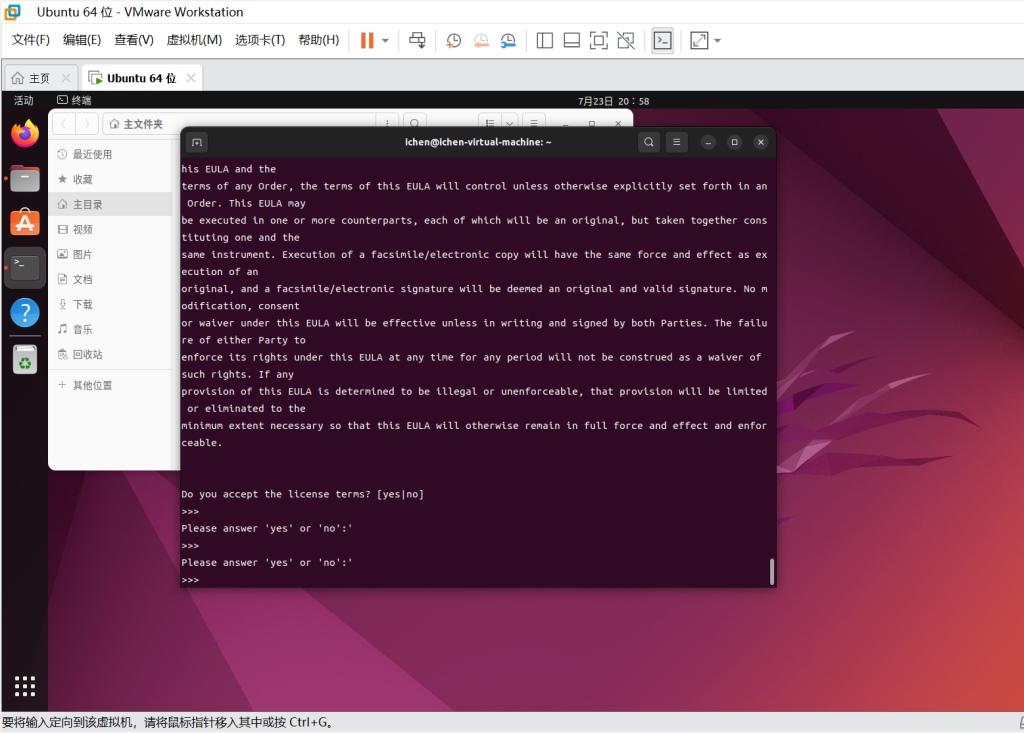
然后会问安装目录:选择默认目录则直接回车,若自定义目录则输入路径。之后再输入一次Yes。如果在输入Yes之前出现了Error应该是磁盘空间不够了,尝试扩容。
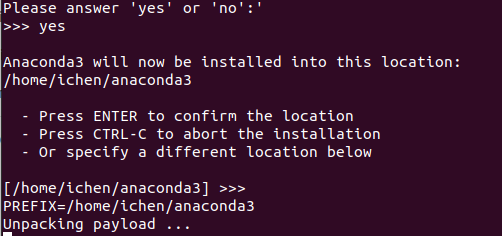
如果安装后输入conda -V查不到信息,显示Conda: Command Not Found,这是因为Anaconda路径没有被识别,输入source ~/.bashrc。到此已经安装好Anaconda了。
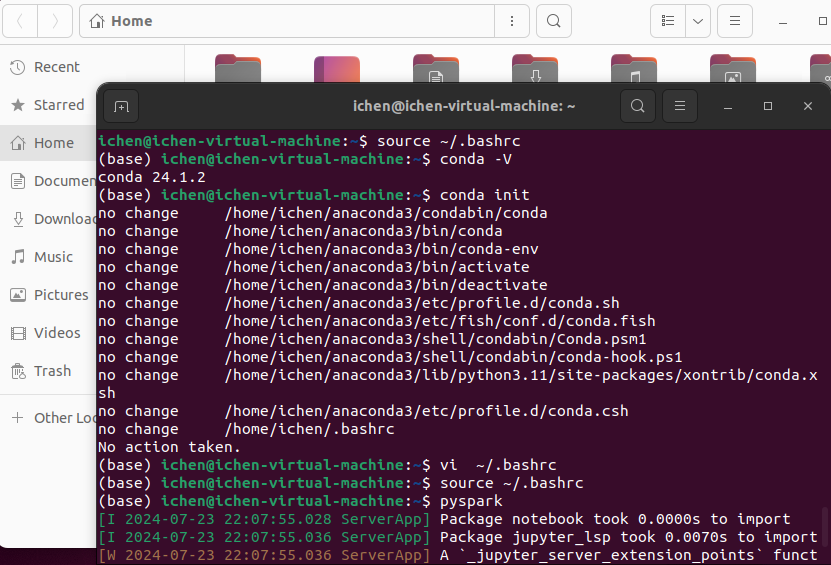
之后配置环境变量,添加:
export PYSPARK_DRIVER_PYTHON="jupyter"
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"Source之后Pyspark,如果想打开指定的网址上的.Ipynb文件,需要先通过Wget 网址来把文件下载到本地,再启动Pyspark,在Jupyter Notebook界面打开文件来编辑。















 3188
3188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









