






目录
HTML语法
(Hyper Text Markup Language)超文本标记语言
<h>标签 标题
在pycharm里创建一个html文件
<h1>text</h1>> 会显示一个标题(换成h2等会显示一个小一点的标题)
会显示一个标题(换成h2等会显示一个小一点的标题)
<h1 align="center">text</h1>>加上参数会居中
#h1标签
#align属性
#center属性值
<a href> 网页链接
<a href="http://www.baidu.com">周杰伦</a>><img >图片 特殊
<img src="图片的路径" /> 不用后面的
html语法规则
<标签 属性="属性值">被标记的内容</标签>>通过标签 名字 属性名 属性值来爬虫

实例:菜价
源代码里没有页面里的内容 看看是不是json
安装库
from bs4 import BeautifulSoup拿源代码(用json抓包)
from bs4 import BeautifulSoupimport requestsimport jsonurl='http://www.xinfadi.com.cn/getPriceData.html'#检查 Network 刷新里的#发送json请求xin=requests.post(url)text=xin.text#json解析获取的信息content = json.loads(text)#获取json中list数据lists = content.get("list")#遍历list数据 并输出对应的数据for lis in lists: print("名称:"+lis.get("prodName"), "最高价格:"+lis.get("highPrice"), "最低价格:"+lis.get("lowPrice"), "平均价格:"+lis.get("avgPrice"))BeautifulSoup交页面源代码
html表格找table
步骤BeautifulSoup
源代码交给BeautifulSoup进行处理 生成bs对象
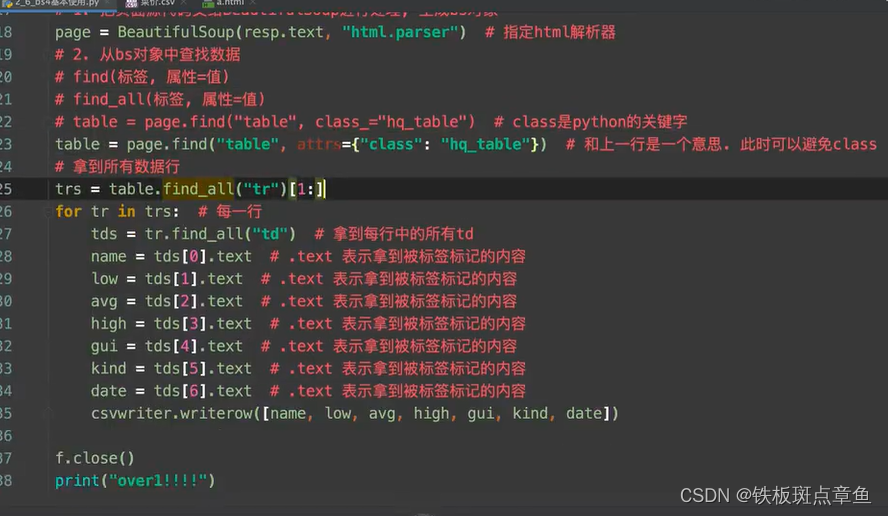
page=BeautifulSoup(页面源代码,"html.parser")#指定html解析器 参数指定是页面源代码bs对象中查找数据
#find就找第一个
#find_all所有都找
table=page.find('table',class_=’hp_talb‘)找 标签是table中 属性class 是hp_table的带有标签
class是python的关键字 不能直接用 所以要加上下划线
另一种写法 不用下划线
table=page.find('table',atts={"class_"="hp_talb"})找到的数据还带有标签
标签范围
如上图
突出的标签 包含其中的内容 (含标签)
找的范围太大缩小范围
再次find 用上次找的(本题table)
trs=table.find_all("tr")[1:]#切片去除第一个text去除标签
find_all 后用text去除标签 索引(有)
tds[0].text#从第零个中拿被标签标记的内容 tds[0]是指列表中第一个善用for循环
实例:优美图库
拿主页面源代码 提取子页面地址
标签img 图片
<li> <ul>等标签太多 再向外招 再搜索标签是否过多
拿标签里属性的值get
a.get('属性名')#a是一行(标签 被标记 标签)乱码格式解决
从网页拿到图片content
img=request.get(图片网址)#网站上只有图片img.content #拿到字节 字节放到文件里就是图片img_name #变量定义文件名字 图片名字频繁访问 防止服务器禁止访问 有time 制造时间间隔
import timetime.sleep(1)#暂停一秒import requestsfrom bs4 import BeautifulSoupurl=requests.get('https://www.umei.cc//bizhitupian/weimeibizhi/')url.encoding="utf-8"url_text=url.text #获取主网页源代码main_page=BeautifulSoup(url_text,"html.parser")alist=main_page.find('div',class_="swiper-wrapper after").find_all('a')#拿那一段中的 a标签for nn in alist: ziwang='https://www.umei.cc/'+nn.get('href')#获取标签里的属性值 重要 zi_resp=requests.get(ziwang) zi_resp.encoding="utf-8" zi_text=zi_resp.text img_dizhi=BeautifulSoup(zi_text,"html.parser").find('section').find('img').get('src') tu_resp=requests.get(img_dizhi) name=img_dizhi.split('/')[-1] with open(r'D:桌面 upian\'+name,'wb') as fp: fp.write(tu_resp.content) print('over',name)














 50
50











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









