







内容预知
排序的概念
排序是计算机内经常进行的一种操作,其目的是将一组“无序”的记录序列调整为“有序”的记录序列。对于数组来讲,我们在起始构造时,只能赋予它所对应下标的元素。
当用数组记录或则获取一组数据时,数据并不会呈现我们想要的规律和顺序,大多数情况下都是杂乱无章的,不方便进行数据分析等需要找规律的操作,为此程序员必须掌握简单的排序算法,来达到让数组成为有序的数组来应用相对的场景。
本文一共介绍了五种排序方式:直接选择排序,反转排序,冒泡排序,插入排序和希尔排序
1.直接选择排序
直接选择排序(Straight Select Sorting) 也是一种简单的排序方法,它的基本思想是:第一次从array[0]~array[n-1]中选取最大值,将该最大值放在末尾。第二次从array[1]~array[n-1]中选取最大值,放在倒数第二的位置,....,第i次从array[i-1]~array[n-1]中选取最大值,放在了array[lenth-1-i]的位置上,得到一个按排序码从小到大排列的有序序列。

该方法:类似于打擂台比赛,第一轮选出最大的数值 ,成为第一(并且不参加后面的比较)
第二轮再次选出本轮中第一的值,成为所有元素中的第二(并且往后不参与比较)
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
一直进行到比到倒数第一和倒数第二的产生
运用演示:
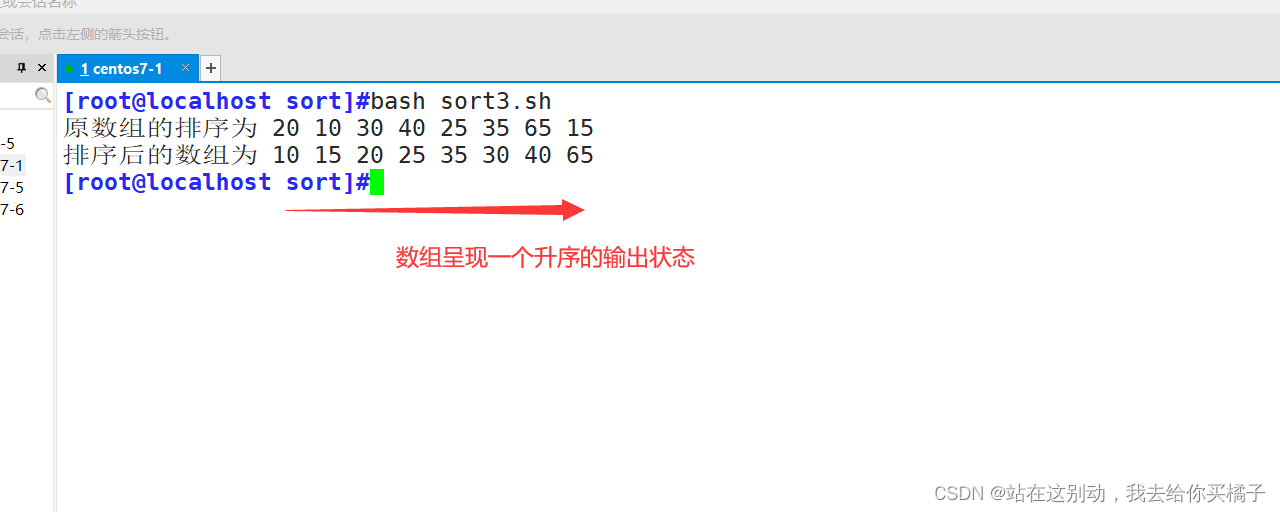
需求:对数组 array=(20 10 30 40 25 35 65 15),使用直接选择排序,让其元素随着元素的下标增大而升序
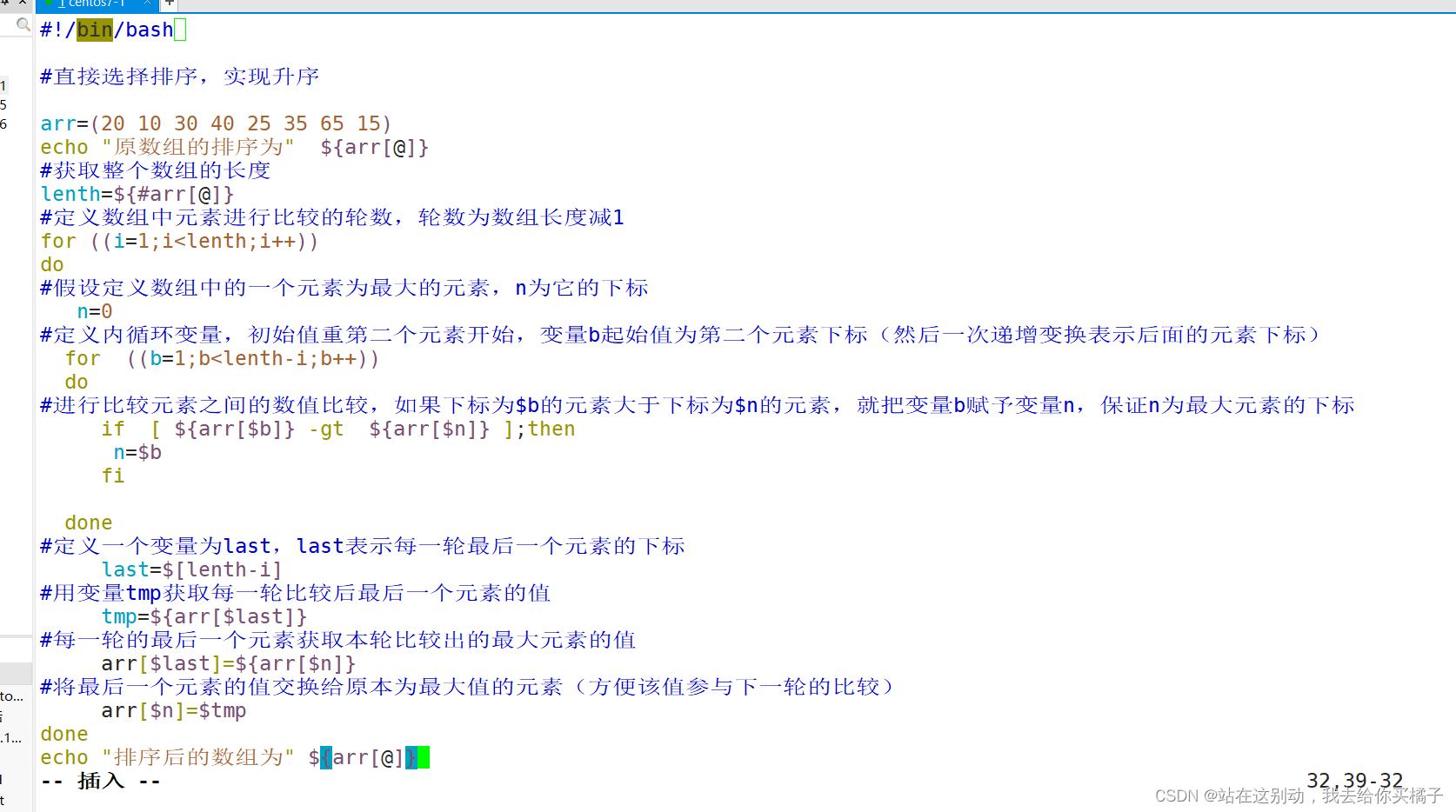
#!/bin/bash
#直接选择排序,实现升序
arr=(20 10 30 40 25 35 65 15)
echo "原数组的排序为" ${arr[@]}
#获取整个数组的长度
lenth=${#arr[@]}
#定义数组中元素进行比较的轮数,轮数为数组长度减1
for ((i=1;i<lenth;i++))
do
#假设定义数组中的一个元素为最大的元素,n为它的下标
n=0
#定义内循环变量,初始值重第二个元素开始,变量b起始值为第二个元素下标(然后一次递增变换表示后面的元素下标)
for ((b=1;b<lenth-i;b++))
do
#进行比较元素之间的数值比较,如果下标为$b的元素大于下标为$n的元素,就把变量b赋予变量n,保证n为最大元素的下标
if [ ${arr[$b]} -gt ${arr[$n]} ];then
n=$b
fi
done
#定义一个变量为last,last表示每一轮最后一个元素的下标
last=$[lenth-i]
#用变量tmp获取每一轮比较后最后一个元素的值
tmp=${arr[$last]}
#每一轮的最后一个元素获取本轮比较出的最大元素的值
arr[$last]=${arr[$n]}
#将最后一个元素的值交换给原本为最大值的元素(方便该值参与下一轮的比较)
arr[$n]=$tmp
done
echo "排序后的数组为" ${arr[@]}
排序结果:
2.反转排序
反转排序的作用就是将 原本的一个数组,让它们所有的位置都倒过来,(第一个元素和最后一个元素交换位置,第二个元素和倒数第二个元素交换位置。。。。。以此内推,达到所有位置成对称交换的现象)
运用演示:
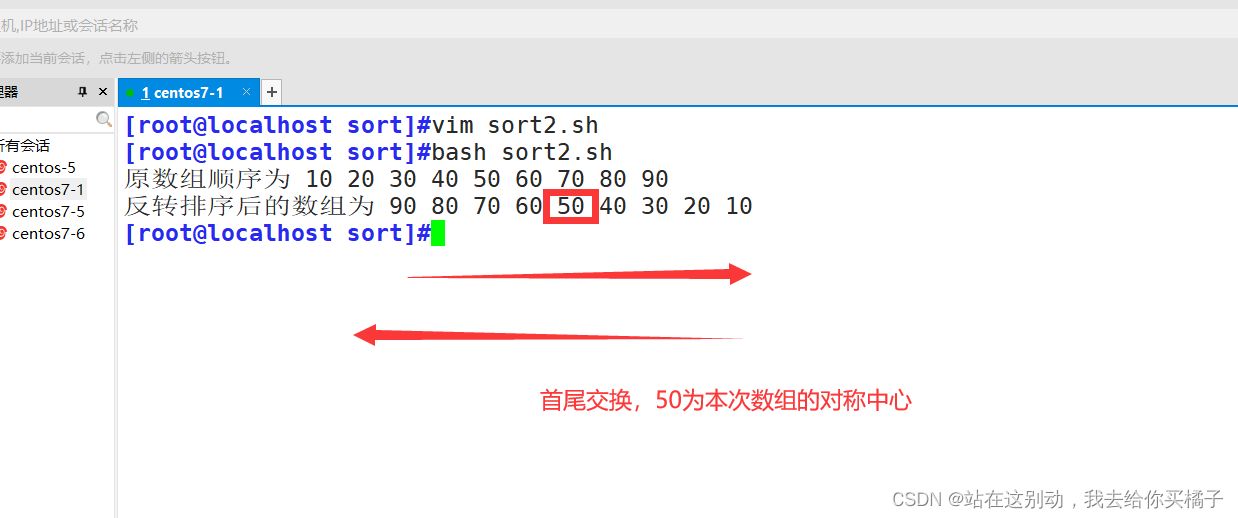
需求:将arr=(10 20 30 40 50 60 70 80 90)进行反转排序
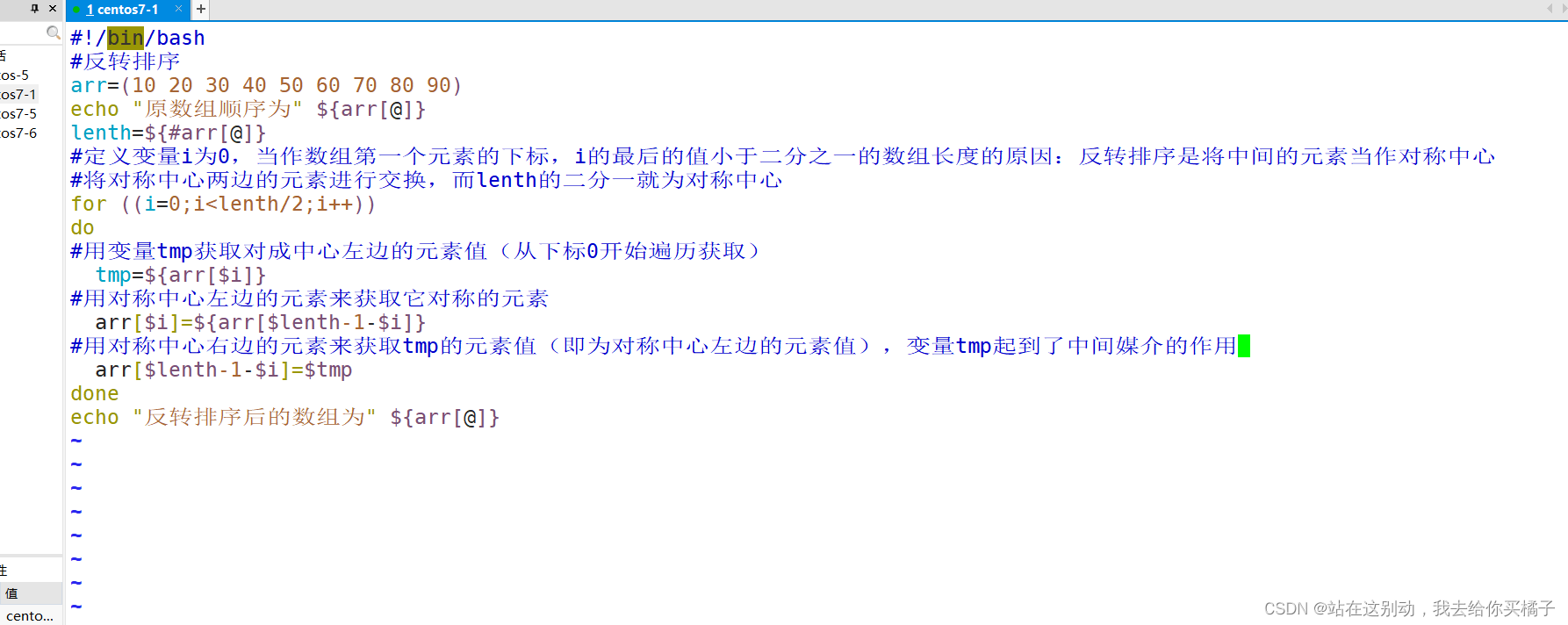
#!/bin/bash
#反转排序
arr=(10 20 30 40 50 60 70 80 90)
echo "原数组顺序为" ${arr[@]}
lenth=${#arr[@]}
#定义变量i为0,当作数组第一个元素的下标,i的最后的值小于二分之一的数组长度的原因:反转排序是将中间的元素当作对称中心
#将对称中心两边的元素进行交换,而lenth的二分一就为对称中心
for ((i=0;i<lenth/2;i++))
do
#用变量tmp获取对成中心左边的元素值(从下标0开始遍历获取)
tmp=${arr[$i]}
#用对称中心左边的元素来获取它对称的元素
arr[$i]=${arr[$lenth-1-$i]}
#用对称中心右边的元素来获取tmp的元素值(即为对称中心左边的元素值),变量tmp起到了中间媒介的作用
arr[$lenth-1-$i]=$tmp
done
echo "反转排序后的数组为" ${arr[@]}
排序结果:
3.冒泡排序
它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序(如从大到小、首字母从Z到A)错误就把他们交换过来。走访元素的工作是重复地进行,直到没有相邻元素需要交换,也就是说该元素列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中的气泡最终会上浮到顶端一样,故名“冒泡排序”。

运用演示:
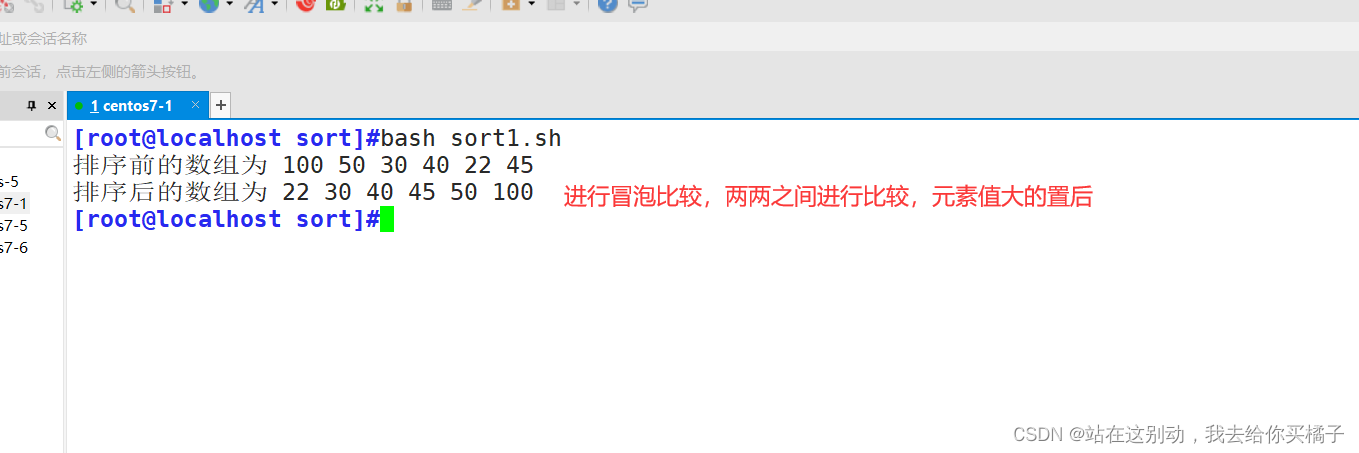
需求:将数组arr=(100 50 30 40 22 45)进行冒泡排序,呈现一个升序数组
#!/bin/bash
#冒泡排序
arr=(100 50 30 40 22 45)
echo "排序前的数组为" ${arr[@]}
lenth=${#arr[@]}
#使用外部循环定义比较轮数,比较轮数为数组长度减,且从1开始
for ((a=1;a<lenth;a++))
do
#使用内部循环进行相邻的元素进行比较,如果左边元素大于右边,则左右互换位置,直到这一轮比较出最大的,锁定本轮最后的位置
#随着每一次比较产生每一轮最大值置后,轮数也会随之减少,缩小比较的范围
for((b=0;b<lenth-a;b++))
do
#用变量left获取前一个元素的值
left=${arr[$b]}
#定义相邻两个元素后一个元素的下标
c=$[b+1]
#用变量right获取相邻两个元素中后一个元素的值
right=${arr[$c]}
#if判断语句,当相邻两个元素之间左边元素大于右边元素时,两个元素进行位置互换
if [ $left -gt $right ];then
#用变量tmp记录备份左边元素的值
tmp=${arr[b]}
#将右边元素的值赋予左边元素
arr[$b]=${arr[$c]}
#将备份好的的左边元素值赋予右边,从而实现真正的位置互换
arr[$c]=$tmp
fi
done
done
echo "排序后的数组为" ${arr[*]}

排序结果输出:
4.插入排序
插入排序的工作方式像许多人排序一手扑克牌。开始时,我们的左手为空并且桌子上的牌面向下。然后,我们每次从桌子上拿走一张牌并将它插入左手中正确的位置。为了找到一张牌的正确位置,我们从右到左将它与已在手中的每张牌进行比较。拿在左手上的牌总是排序好的,原来这些牌是桌子上牌堆中顶部的牌 。
插入排序是指在待排序的元素中,假设前面n-1(其中n>=2)个数已经是排好顺序的,现将第n个数插到前面已经排好的序列中,然后找到合适自己的位置,使得插入第n个数的这个序列也是排好顺序的。按照此法对所有元素进行插入,直到整个序列排为有序的过程,称为插入排序 。
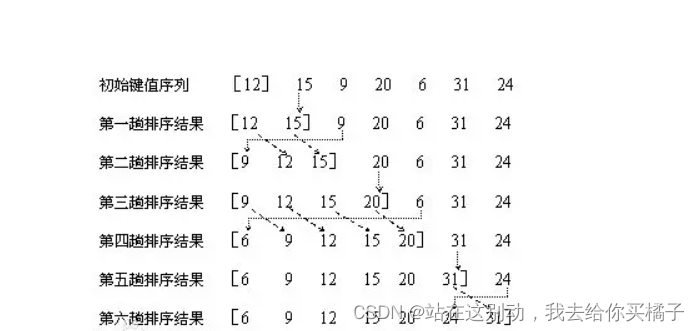
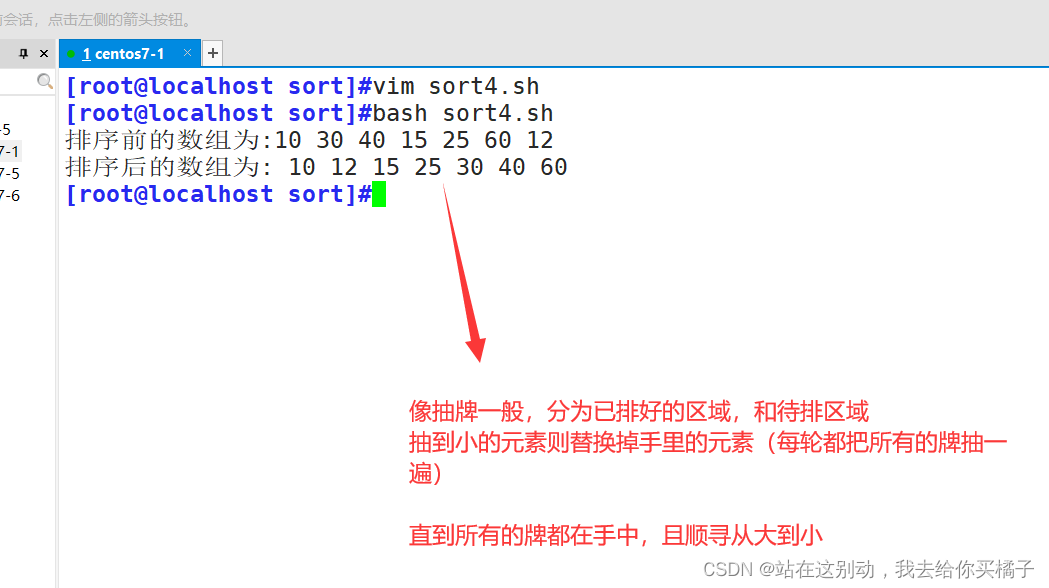
需求:运用插入排序对 arr=(10 30 40 15 25 60 12)进行升序排序
#!/bin/bash
#插入排序,实现升序
arr=(10 30 40 15 25 60 12)
echo "排序前的数组为:"${arr[@]}
lenth=${#arr[@]}
#定义排序的轮数,为数组长度减1,且轮数变量i从第一轮开始计数
#并且变量i也可以作为待排序元素的下标
for ((i=1;i<lenth;i++))
do
#变量b从下标0开始,默认为已经排序好的元素
for ((b=0;b<i;b++))
do
#拿已排序好的元素与未待排序的元素进行元素值比较,如果待排序中有比已排序好的元素小,则待排序元素取代已排序元素
#被取代的元素放置在待排序的元素中,等待下一轮的比较
if [ ${arr[$i]} -lt ${arr[$b]} ];then
#用tmp变量获取已经排序好的元素值,进行备份
tmp=${arr[$i]}
#将待排序且比较过后小于已排序元素的元素值赋予已排序元素,从而取代它的位置
arr[$i]=${arr[$b]}
#将备份的的已排序元素值赋予取代它的元素的原位置上,等待下一轮比较
arr[$b]=$tmp
fi
done
done
echo "排序后的数组为:" ${arr[@]}

排序结果:
5.希尔排序
“希尔排序(Shell's Sort)是插入排序的一种又称“缩小增量排序”(Diminishing Increment Sort),是直接插入排序算法的一种更高效的改进版本。
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至 1 时,整个文件恰被分成一组,算法便终止。
运用演示:
需求: array=(10 20 15 17 22 26 28 27 11)进行分组
#!/bin/bash
#希尔排序,分组插入比较
array=(10 20 15 17 22 26 28 27 11)
echo "希尔排序前的数组" ${array[*]}
length=${#array[*]}
#把距离为gap的元素编为一个组,扫描所有组.
#每次循环减少,增量除于2,达到减少的效果,增量最小为1,当增量为1时,所有的序列被分为一组,进行插入排序
for ((gap=$length/2; gap>0; gap/=2))
do
for ((i=gap; i<$length; i++))
do
temp=${array[$i]}
#对距离为gap的元素组进行排序,每一轮比较拿当前轮次最后一个元素与组内其他元素比较,将数组大的往后放
for ((j=i-gap; j>=0&&temp<${array[$j]}; j-=gap))
do
array[$j+$gap]=${array[$j]}
done
#和最左边较大的元素调换位置
array[$j+$gap]=$temp
done
done
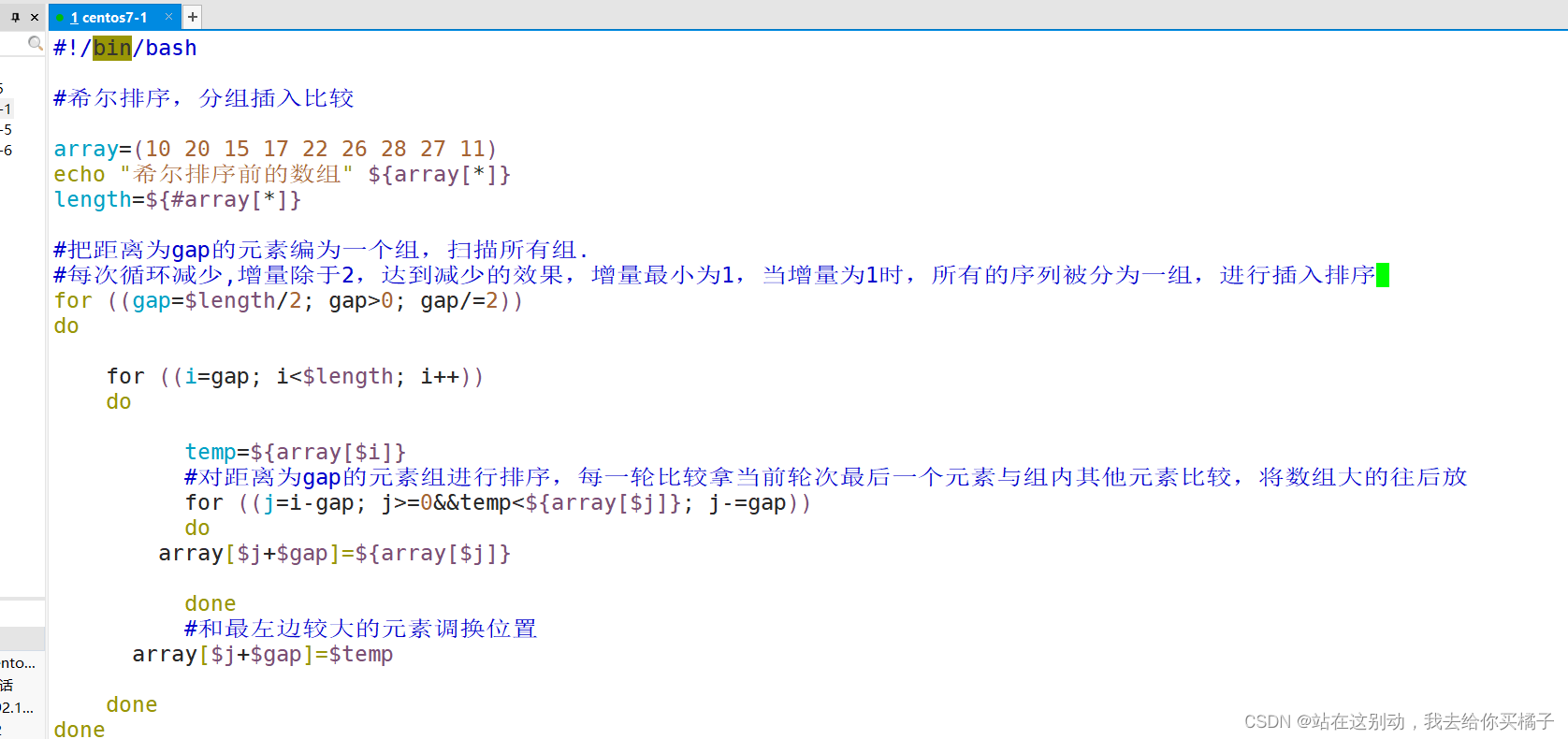
排序结果:

希尔排序对比插入排序优化的是过程,减少比较次数 和元素交换次数

总结
1. 直接选择排序,从一轮开始比出本轮最大的元素,将最大的元素放入数组最后一个下标位置,并且不参与下一轮比较,依次类推直到最后一轮
2.反转排序,以数组中间下标为对称中中心(数组长度为奇数是中间值下标为对称中心,偶数假象它俩中间存在对称中心),两边对称的元素进行交换
3.冒泡排序,相邻的两个元素比较大小,大放在后面,只要相邻就比较,一直比出本轮最大
然后进行数组长度减1的轮数比较,每次两两比较交换产生最大,排在最后(对于当前元素最后的位置)
4.插入排序,像抽扑克原理一样,将以排好的和待排的进行比较,当抽中的比自己手中的小时,就替换掉放到下一轮的比较备用堆中,将未抽中的元素,每次遍历一遍,直到该数组所有的下标排满
5.希尔排序,希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的元素越来越多,当增量减至 1 时,整个文件恰被分成一组















 1820
1820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









