






背景
云计算课程实践——基于华为云的Flink实践
知识点
概述
- 分布式计算:多个通过网络互联的计算机都具有一定的计算能力,他们相互之间传递数据,实现信息共享,协作共同完成一个处理任务。
- 优势:稀有资源实现共享; 在多台计算机上平衡计算负载; 将程序放在最适合它的计算机上运行
- 分布式系统:是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。
- 系统拥有多种通用的物理和逻辑资源,可以动态的分配任务,分散的物理和逻辑资源通过计算机网络实现信息交换。
- 分布式计算的一般步骤:
- 设计分布式计算模型,实现分布式系统
- 通过分布式系统实现分布式任务分配
- 依照分布式系统编写并执行分布式程序
理论基础
- CAP理论:一个分布式系统最多能够同时满足一致性(consistency)、可用性(Availability)、分区容错性(Partition tolerance)中的两项
- 一致性:一次操作之后,所有节点同一时间的数据完全一致。
- 可用性:服务一直可用且在正常的响应时间内。
- 分区容错性:分布式系统遇到某节点或网络分区故障时,仍然能够正常运行并对外提供服务。
- 对于大多数大型互联网服务而言,节点故障、网络故障是常态,均采取保证AP和最终一致性的策略
- BASE理论:追求最终一致性
- Basically Available:基本可用-系统出现故障时,允许损失部分可用性,保证核心可用
- Soft State:软状态,允许系统存在中间状态,但中间状态不会影响系统的整体可用性
- Eventual Consistency:最终一致性-所有数据副本经过一定时间后,能最终达到一致的状态
- 一致性算法/共识算法:需要在每一条指令上执行一个“一致性算法”以保证每个节点看到的指令一致。
- 一台机器中多个进程/线程达成数据一致
- 分布式文件系统或者分布式数据库中多客户端并发读写数据
- 分布式存储中多个副本响应读写请求的一致性。
- 一致性算法Paxos
- 普通哈希算法
分布式系统特性
- 容错性
- 高可拓展性
- 开放性
- 并发处理能力
- 透明性
分布式系统类型
- 结构化存储:MySQL
- 非结构化存储:HDFS,GFS
- 半结构化存储:NoSQL,Key-Value Store,对象存储
- 基于内存存储:利用Redis等作缓存
- NewSQL
分布式计算系统类型
- 基于消息的系统:MPI
- DataFlow系统:
- Hadoop
- Spark
分布式资源管理系统
- Yarn:Hadoop 2.0版本,解决了原来Hadoop扩展性较差的问题
- Apache Mesos
- Spark Standalone:Spark自带的简单的资源管理系统,负责跟踪集群状态并调度计算任务
- Kubernets:Google开发的一个强大的容器编排框架,用户通过Kubernets管理容器,不需要和底层交互
案例1
问题
现有A、B、C三台机器和f1、f2、f3三个文件,如何进行分布式存储(对外显示它们存于同一硬盘空间,对外显示依旧为一个完整文件);实现分布式存储以后如何进行分布式计算(统计f1里每个单词出现的次数);如何实现分布式系统的可靠性(机器宕机了如何保证数据不丢失)
实现
- 分布式存储:
- 将多台机器硬盘以某种方式连接到一起
- 采用客户-服务器模式构建分布式存储集群 让A管理B,C
- DFS:
- 对内:随意添加“客户”,硬盘无限扩大
- 对外:整个集群就像是一台机器、一片云,硬盘显示为统一存储空间,文件接口统一
- 分布式计算:
- 取新机器D作为服务器,采用客户-服务器模式构建由机器B、C和D组成的分布式计算集群

- A明确知道每一份数据都存储在多个地方;D会要求存有待计算数据的机器都参与计算,并选择先结束的机器计算结果;冗余存储不仅提高了分布式存储的可靠性,也提高了分布式计算的可靠性
- 取新机器D作为服务器,采用客户-服务器模式构建由机器B、C和D组成的分布式计算集群
工具
Hadoop
- Hadoop 1.0
- Hadoop Common:支持其他两个模块的公用组件
- Hadoop DFS:分布式文件系统
- Hadoop MapReduce:分布式计算框架
- Hadoop 2.0
- 分布式存储HDFS
- 分布式操作系统Yarn
- 通过调用程序库,可使用简单的编程模型处理分布在不同机器上的大规模数据
- 采用客户-服务器模式
- 整体架构

- 构建大型分布式集群,提供海量存储和计算服务
- 存储半结构化业务数据
分布式存储HDFS
- 内部特性:冗余备份、副本存放、副本选择、心跳检测 数据完整性检测、元数据磁盘失效 简单一致性模型、流式数据访问、客户端缓存 流水线复制、架构特征、超大规模数据集
- 对外功能:
- Namenode高可靠性:配置多个NameNode,一个失效时立即替换
- HDFS快照:当数据损坏时,支持回滚到正确的时间节点
- 元数据管理与恢复工具:通过命令hdfs oiv和hdfs oev管理修复fsimage和edits
- HDFS安全性:用户和文件级别安全认证、机器和服务级别安全认证
- HDFS配额功能:管理目录或文件配额大小 HDFS C语言接口:使用C语言操HDFS的接口
- HDFS Short-Circuit功能:客户端可以绕开Datanode直接读取本机数据,加快map操作 WebHdfs:通过Web方式操作HDFS(插、删、改、查)
分布式操作系统Yarn
管理计算机资源、提供用户和程序访问系统资源的API
- 包含实体:
- Client:客户端,负责向集群提交作业。
- ResourceManager:集群主进程,仲裁中心,负责集群资源管理和任务调度。
- Scheduler:资源仲裁模块。
- ApplicationManager:选定,启动和监管ApplicationMaster。
- NodeManager:集群从进程,管理监视Containers,执行具体任务
- Container:本机资源集合体,如某Container为4个CPU,8GB内存。
- ApplicationMaster:任务执行和监管中心。

- 自带两种策略
- 容量调度算法CapacityScheduler:按照配置好的资源配比为不同层级的用户分配最大可用资源
- 公平调度算法FairScheduler:任务公平使用集群资源,短任务在合理时间内完成;长任务不至于永远等待
- 资源管理——Yarn是可编程的,不仅仅支持自带的MapReduce,还可以自定义算子
- 一套编程协议 Client负责提交任务,ApplicationMaster负责执行任务 Client中与RM通信;ApplicationMaster与RM通信;ApplicationMaster与NM通信 编写符合协议的Client和ApplicationMaster即可
Zookeeper
- 提供通用的分布式协调服务,管理物理分布的子进程(如资源、任务分配等
- 由多个Server组成的集群;一个Leader,多个Follower
- 每个Server都保存了一份数据副本
- 全局数据一致;分布式读写 更新请求转发,由Leader实施
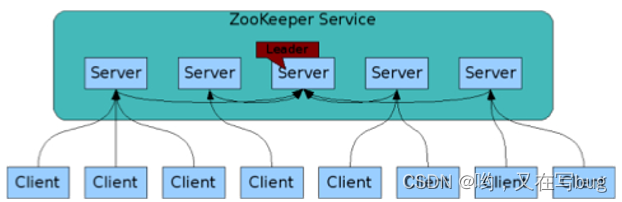
- 使用约定:
- 更新请求顺序执行:来自同一个Client的更新请求按其发送顺序依次执行
- 数据更新原子性:一次数据更新要么成功,要么失败。
- 全局唯一数据视图:Client无论连接哪个Server,数据视图都是一致的
- 实时性:在一定时间范围内,Client能读到最新数据

- 统一命名服务、配置管理服务
Hbase
基于Hadoop的开源分布式数据库,以Google BigTable为原型
Pig
构建在Hadoop之上,用来处理大规模数据集的脚本语言平台,将根据业务逻辑写好的数据流脚本翻译成多个HDFS、Map和Reduce的操作。类似于MapReduce的另一个编程入口
Pig Latin-->MapReduce-->cluster
Hive
MapReduce的一个高层抽象,像是一个数据库接口,使用类SQL的HSQL提供查询和操作服务
Flume
分布式高性能、高可靠地数据传输工具
实践--基于华为云的Flink实践
手册链接:链接:https://pan.baidu.com/s/1GqLBSiRy6slHiier0A_UXQ?pwd=i0ym
提取码:i0ym
遇到的问题:
在worker1、worker2、worker3中执行/usr/local/zookeeper/bin/zkServer.sh start
/usr/local/zookeeper/bin/zkServer.sh status时报错:"Error contacting service. It is probably not running."
分析:在前面的配置环节中修改了配置文件zoo.cfg,修改了数据目录,添加了以下内容
server.1=worker1:2888:3888server.2=worker2:2888:3888server.3=worker3:2888:3888admin.enableServer=truequorumListenOnAllIPs=true
server.1=worker1:2888:3888:这一行表示 Zookeeper 集群中的第一个服务器,其中worker1:2888:3888表示服务器的信息,包括 hostname 或 IP 地址、用于选举(election)的端口(2888)和用于数据传输(data transfer)的端口(3888)。
server.2=worker2:2888:3888和server.3=worker3:2888:3888:这两行表示集群中的第二个和第三个服务器,具有类似的格式,分别对应不同的服务器信息。
admin.enableServer=true:这行配置表示启用了 Zookeeper 集群中的管理员服务,该服务用于管理和监控集群的状态和配置。
quorumListenOnAllIPs=true:这行配置表示在 quorum 通信时 Zookeeper 服务将监听所有的 IP 地址,包括本地和外部 IP 地址,以进行集群之间的通信和数据同步。
在网上查找了很多解决错误的方法,参考:Zookeeper启动显示成功,zkServer.sh status报错:Error contacting service. It is probably not running.-CSDN博客
但我的问题还是没解决,不确定服务是否启动可以使用这个命令在前台运行,通过报错信息排查:
zkServer.sh start-foreground最后我发现我的服务能够成功启动,但是一直无法连接其他worker,最后我在每个worker的安全组里面加上2888端口和3888端口成功解决问题。














 1777
1777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









