决策树算法
原理:根据特征作为节点来进行决策
问题:哪个特征作为根节点,下一决策又应该用哪个特征
- 利用信息信息增益(信息论中的信息熵)的方法。衡量特征之间的重要性。
- 理想情况:每一个叶节点都是理想分类
- 实际情况:使用贪心算法从全局寻找最优解
版本
| 决策树 | 模型类型 | 树结构 | 特征选择 | 连续值处理 | 缺失值处理 | 剪枝处理 |
|---|
| ID3 | 分类 | 多叉树 | 信息增益 | 不可以 | 不可以 | 不可以 |
| C4.5 | 分类 | 多叉树 | 信息增益比 | 可以 | 可以 | 可以 |
| CART | 分类与回归 | 二叉树 | 基尼系数 | 可以 | 可以 | 可以 |
优点
- 非常直观,可解释强
- 预测速度快
- 可以处理离散,连续,缺失值
缺点
- 容易过拟合(预剪枝,后剪枝根据构建完成后的来条件判断)
- 得处理样本不均衡问题。比例大更偏向
代码(鸢尾花数据集)
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasets
import numpy as np
np.random.seed(0)
iris=datasets.load_iris()
iris_x=iris.data
iris_y=iris.target
indices=np.random.permutation(len(iris_x))
iris_x_train=iris_x[indices[:-10]]
iris_y_train=iris_y[indices[:-10]]
iris_x_test=iris_x[indices[-10:]]
iris_y_test=iris_y[indices[-10:]]
from IPython.display import Image
from sklearn import tree
import pydotplus
clf=DecisionTreeClassifier(max_depth=4)
clf.fit(iris_x_train,iris_y_train)
import pydotplus
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files/Graphviz/bin/'
dot_data=tree.export_graphviz(clf,out_file=None,feature_names=iris.feature_names,class_names=iris.target_names,filled=True,rounded=True,special_characters=True)
graph=pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
iris_y_predict=clf.predict(iris_x_test)
score=clf.score(iris_x_test,iris_y_test,sample_weight=None)
print('iris_y_predict')
print(iris_y_predict)
print('iris_y_test')
print(iris_y_test)
print('Auccary',score)
决策树流程图: 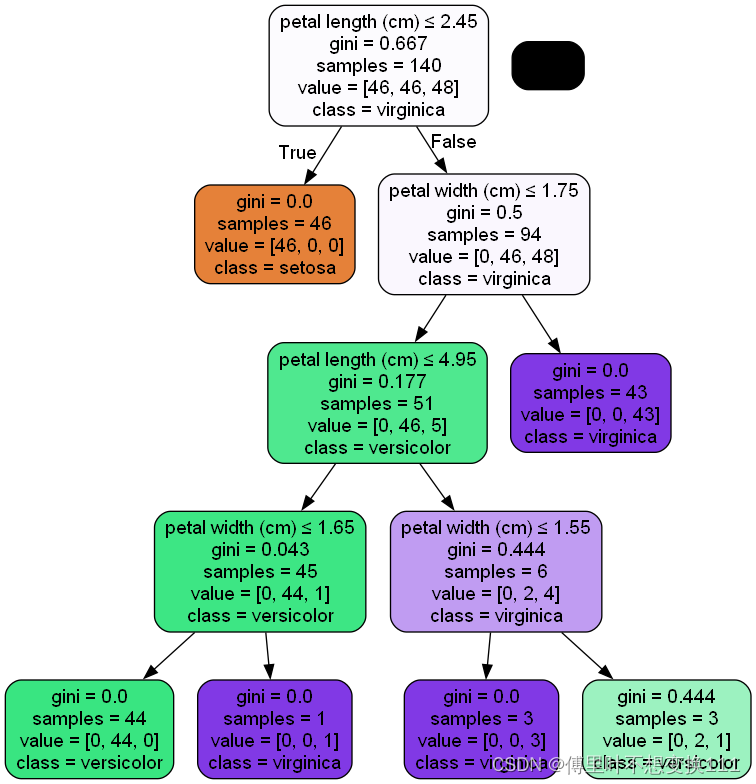























 4853
4853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









