









初始代码(接上篇+double提高随机数范围和N的范围)
#include <cuda_runtime.h>
#include <iostream>
#include <stdlib.h>
#include <time.h>
#include <cstdlib>
#include <ctime>
// 定义用于计时的重复次数
#define NUM_REPS 100
__global__ void reduceSumKernel(double *src, double *dest, long long int n,int nreps) {
extern __shared__ double lSum[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int idx_loc = threadIdx.x;
// 外层循环,重复nreps次
for (int r = 0; r < nreps; r++) {
// 线程内归约
lSum[idx_loc] = 0;
for (int i = idx; i < n; i += gridDim.x * blockDim.x) {
lSum[idx_loc] += src[i];
}
__syncthreads();
}
// 线程块内归约展开
if (idx_loc < 128) {
lSum[idx_loc] += lSum[idx_loc + 128];
}
__syncthreads();
if (idx_loc < 64) {
lSum[idx_loc] += lSum[idx_loc + 64];
}
__syncthreads();
if (idx_loc < 32) {
lSum[idx_loc] += lSum[idx_loc + 32];
}
__syncthreads();
if (idx_loc < 16) {
lSum[idx_loc] += lSum[idx_loc + 16];
}
__syncthreads();
if (idx_loc < 8) {
lSum[idx_loc] += lSum[idx_loc + 8];
}
__syncthreads();
if (idx_loc < 4) {
lSum[idx_loc] += lSum[idx_loc + 4];
}
__syncthreads();
if (idx_loc < 2) {
lSum[idx_loc] += lSum[idx_loc + 2];
}
__syncthreads();
if (idx_loc < 1) {
lSum[idx_loc] += lSum[idx_loc + 1];
}
__syncthreads();
//线程块间归约
if (idx_loc == 0) {
atomicAdd(dest, lSum[0]);
}
}
int main() {
#define NUM_CU 72
#define NUM_BLOCK_PER_CU 1
const long long int N = 1024LL * 1024LL * 256LL;
// const long int N = 1024 * 1024 * 256 * 256;
const int blockSize = 256;
const int numBlocks = NUM_CU * NUM_BLOCK_PER_CU;
//const int numBlocks = 4;
//const int element_per_thread=(N+N-1)/numBlocks/blockSize;
// 主机端数据
double *src;
double *dest;
src = new double[N];
dest = new double[1];
srand(static_cast<unsigned int>(time(nullptr)));
// 初始化数据为随机数
for (int i = 0; i < N; i++) {
src[i] = static_cast<double>(rand() % 10000001 - 5000000);
}
dest[0] = 0.0;
// 设备端内存分配
double *d_src;
double *d_dest;
cudaMalloc(&d_src, N * sizeof(double));
cudaMalloc(&d_dest, sizeof(double));
// 数据传输到设备
cudaMemcpy(d_src, src, N * sizeof(double), cudaMemcpyHostToDevice);
cudaMemcpy(d_dest, dest, sizeof(double), cudaMemcpyHostToDevice);
// CUDA 事件,用于计时
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
// 预热以避免计时启动延迟
reduceSumKernel<<<numBlocks, blockSize, blockSize * sizeof(double)>>>(d_src, d_dest, N ,1);
// 测量循环调用核函数的时间
cudaEventRecord(start, 0);
for (int i = 0; i < NUM_REPS; i++) {
// 在每次调用内核函数之前将 d_dest 设置为 0.0f
cudaMemcpy(d_dest, dest, sizeof(double), cudaMemcpyHostToDevice);
reduceSumKernel<<<numBlocks, blockSize, blockSize * sizeof(double)>>>(d_src, d_dest, N ,1);
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float outerTime;
cudaEventElapsedTime(&outerTime, start, stop);
// 测量核函数内部循环的时间
cudaEventRecord(start, 0);
// 在每次调用内核函数之前将 d_dest 设置为 0.0f
cudaMemcpy(d_dest, dest, sizeof(double), cudaMemcpyHostToDevice);
reduceSumKernel<<<numBlocks, blockSize, blockSize * sizeof(double)>>>(d_src, d_dest, N ,NUM_REPS);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float innerTime;
cudaEventElapsedTime(&innerTime, start, stop);
// 数据从设备传输回主机
cudaMemcpy(dest, d_dest, sizeof(double), cudaMemcpyDeviceToHost);
// 验证结果
double expectedSum = 0.0;
for (int i = 0; i < N; i++) {
expectedSum += src[i];
}
// 输出结果
std::cout << "Sum: " << dest[0] <<std::endl<<"expectedSum: "<<expectedSum<< std::endl;
// if (dest[0] == expectedSum)
// {
// std::cout << "Result is correct." << std::endl;
// }
// else
// {
// std::cout << "Result is incorrect." << std::endl;
// }
const float epsilon = 1e-10f;
if (std::abs(dest[0] - expectedSum) < epsilon) {
std::cout << "Result is correct." << std::endl;
} else {
std::cout << "Result is incorrect." << std::endl;
}
const char* kernelName = "reduceSumKernel";
// 计算带宽相关参数
double mem_size = N * sizeof(double);
// 报告有效带宽
double outerBandwidth = 2.0 * 1000 * mem_size / (1024 * 1024 * 1024) / (outerTime / NUM_REPS);
double innerBandwidth = 2.0 * 1000 * mem_size / (1024 * 1024 * 1024) / (innerTime / NUM_REPS);
printf("Kernel\t\tLoop over kernel\tLoop within kernel\n");
printf("------\t\t----------------\t------------------\n");
// 报告有效带宽
printf("%s\t%5.2f GB/s\t\t%5.2f GB/s\n", kernelName, outerBandwidth, innerBandwidth);
// 释放内存
delete[] src;
delete[] dest;
cudaFree(d_src);
cudaFree(d_dest);
cudaEventDestroy(start);
cudaEventDestroy(stop);
return 0;
}
正常编译会报错
(base) wkj@ubuntu-GPU2:~/wkj$ nvcc -o reduceplus reduceplus.cu
reduceplus.cu(59): error: no instance of overloaded function "atomicAdd" matches the argument list
argument types are: (double *, double)
1 error detected in the compilation of "reduceplus.cu".修改后
(base) wkj@ubuntu-GPU2:~/wkj$ nvcc -o reduceplus reduceplus.cu -arch=sm_60
(base) wkj@ubuntu-GPU2:~/wkj$ ./reduceplus
Sum: -1.23322e+12
expectedSum: -1.23322e+12
Result is correct.
Kernel Loop over kernel Loop within kernel
------ ---------------- ------------------
reduceSumKernel 822.54 GB/s 846.90 GB/s解决方案来源:CUDA atomicAdd双精度定义错误
计算一个SM(CU)最多能有几个block
#include <iostream>
#include <cuda_runtime.h>
int main() {
int deviceCount;
cudaGetDeviceCount(&deviceCount);
for (int i = 0; i < deviceCount; ++i) {
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, i);
std::cout << "Device " << i << ": " << deviceProp.name << std::endl;
std::cout << "Maximum number of threads per block: " << deviceProp.maxThreadsPerBlock << std::endl;
std::cout << "Maximum number of blocks per multiprocessor: " << deviceProp.maxBlocksPerMultiProcessor << std::endl;
}
return 0;
}输出结果:
(base) wkj@ubuntu-GPU2:~/wkj$ ./num2
Device 0: Quadro RTX 6000
Maximum number of threads per block: 1024
Maximum number of blocks per multiprocessor: 16但是一个CU最多能同时运行多少个block怎么计算呢?
我们都知道共享内存大小为32KB,计算kernel大小blockSize * sizeof(double)=256*8=2048=2KB,所以32/2=16个,最多是16个block
计算设备的SM/CU数量
#include <cuda_runtime.h>
#include <iostream>
int main() {
// 获取当前设备ID
int device;
cudaGetDevice(&device);
// 获取每个设备的总 SM 数量
int numSMs;
cudaDeviceGetAttribute(&numSMs, cudaDevAttrMultiProcessorCount, device);
std::cout << "Number of SMs: " << numSMs << std::endl;
return 0;
}
输出结果:
(base) wkj@ubuntu-GPU2:~/wkj$ ./num
Number of SMs: 72GPU 架构与 CUDA 关系
GPU 架构与 CUDA 关系 — AI System本节会讲解英伟达 GPU 硬件的基础概念,其次会讲解 CUDA(Compute Unified Device Architecture)并行计算平台和编程模型,详细讲解 CUDA 线程层次结构,最后将讲解 GPU 的算力是如何计算的,这将有助于计算大模型的算力峰值和算力利用率。 GPU 硬件基础概念: A100 GPU 架构中 GPC(Graphic Processing Cluster)表... https://chenzomi12.github.io/02Hardware03GPUBase/03Concept.html
https://chenzomi12.github.io/02Hardware03GPUBase/03Concept.html
sm流处理器簇对blocks的调度策略
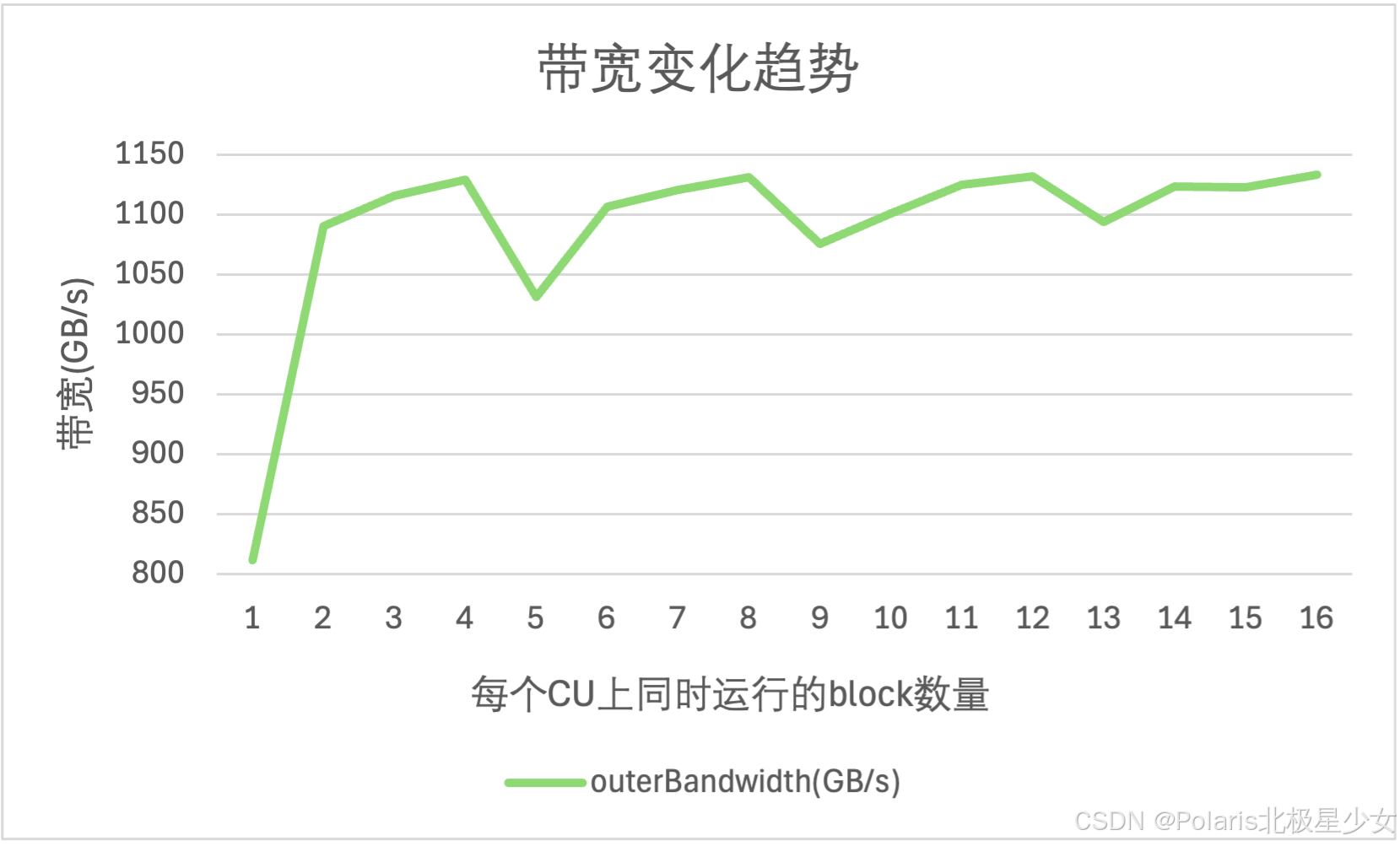
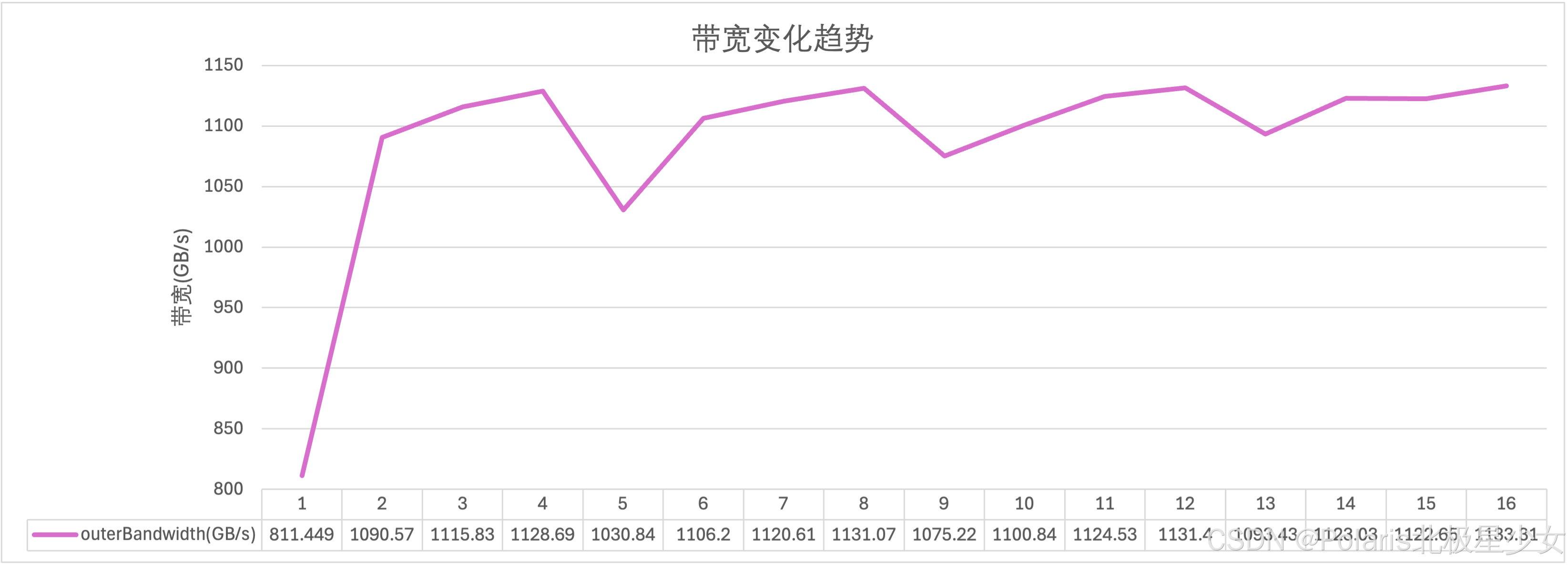
性能测试



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











