










前言
在这篇文章中,荔枝整理了初步了解Redis的一些基础知识和常见指令。通过这篇文章我们可以弄懂Redis具体是什么以及主要的功能、基本数据类型和操作指令。这里注意如果标题后面带*则是仅需要了解就行的知识点哈。
文章目录
一、Redis概述和配置
1.1 概述
Redis中间件,有两大类功能:一个叫做cache缓存,一个叫做store存储,更常用的就是用作缓存。Redis是完全开源的,使用C语言编写并遵循BSD协议的一个高性能的Key-Value内存数据库,它的数据是存在内存中的,同时支持事务、持久化、LUA脚本、发布/订阅、缓存淘汰、流技术等多种功能特性,提供了主从模式、Redis Sentinel和Redis Cluster集群架构方案。
特点:
- 内存在运行时维护数据,因此速度快,性能极高,适用于秒杀等高并发场景
- 分布式缓存,基于key-values键值对存储数据
基本数据结构:
- String
- Lists
- Sets
- Sorted Sets
- Hashes
- Streams
- HyperLogLogs
- Bitmap
工作机理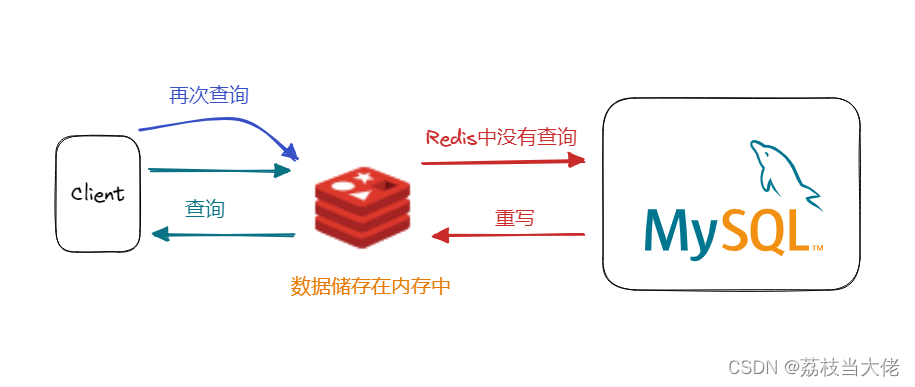
简单来理解其实Redis是在高并发场景下帮助关系型数据库减负,因为其自身独有的内存存储数据的模式比起MySQL的IO访问更快,性能更好。
需要注意的是:Redis是支持自身数据持久化到硬盘的(RDB+AOF),在意外中断后可以从磁盘IO中去将数据重新加载进内存
1.2 环境配置
下载地址:https://redis.io
使用Redis默认最好是在Linux系统中进行,将压缩包直接通过FTP传输到自己的Linux服务器中,tar -xvzf解压缩并进入redis-7.2-rc2,执行make && make install编译安装即可。切换到默认的安装路径可以看到如下的几个文件:
- redis-benchmark:性能测试工具,服务启动后运行该命令,看看自己设备的性能
- redis-check-aof:修复有问题的AOF文件
- redis-check-dump:修复有问题的dump.rdb文件
- redis-cll:客户端,操作入口
- redis-sentinel:redis集群使用
- redis-server:Redis服务器启动命令
注意:需要cp一下redis.conf文件到一个自定义的文件夹并修改配置文件,修改daemonize属性为yes,protected-mode属性为yes,注释掉bind 127.0.0.1,添加一下requirepass为自己设置的密码。
指定redis的配置文件
//启动服务
redis-server /myredis/redis7.conf
//检查端口的占用情况
ps -ef|grep redis|grep -v grep
这里荔枝出现了一个内存不足的报错
 解决方案是先执行:
解决方案是先执行:
echo 1 > /proc/sys/vm/overcommit_memory连接服务
redis-cli -a 123456 -p 6379这样就可以看到连接上redis服务器了

退出Redis连接客户端:quit
设置键:set k1 helloword
关闭Redis服务
单实例关闭:redis-cli -a 111111 shutdown
多实例关闭,指定端口关闭:redis-cli -p 6379 shutdown二、Redis的十大数据类型
一般来说redis的十大数据类型指的是values的数据类型,而key的数据类型一般是字符串类型。
2.1 十大数据模型概述
- String 字符串:一个key对应一个value
- List 列表:双端链表
- Hash 哈希:一个string类型的field(字段)和value(值)的映射表,hash特别适合用于存储对象。
- Set 集合:Redis的Set是String类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,集合对象的编码可以是intset或者hashtable。
- Sorted Set(ZSet) 有序集合:Redis zset和set一样也是string类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数score,redis正是通过分数来为集合中的成员进行从小到大的排序,Z-set集合是通过哈希表来实现的。
- GEO 地理空间:主要用于存储地理位置信息,并对存储的信息进行操作,包括添加地理位置的坐标、获取地理位置的坐标、计算两个位置之间的距离、根据用户给定的经纬度坐标来获取指定范围内的地理位置集合
- HyperLogLog 基数统计:HyperLogLog是用来做基数统计的算法,HyperLogLog的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定且是很小的。在Redis里面,每个HyperLogLog键只需要花费12KB内存,就可以计算接近2^64个不同元素的基数。
- bitmap 位图:bit数组
- bitfield 位域:通过bitfield命令可以一次性操作多个比特位域(指的是连续的多个比特位),它会执行一系列操作并返回一个响应数组,这个数组中的元素对应参数列表中的相应操作的执行结果。
- Stream 流:消息中间件,主要用于消息队列(MQ),提供了消息持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失
2.2 key操作命令
- keys:查看当前库所有的key
- exists key:判断某个key是否存在
- type key:查看你的key是什么类型
- del key:删除指定的key数据
- unlink key:非阻塞删除,仅仅将keys从keyspace元数据中删除,真正删除是在异步中实现的
- ttl key:查看还有多少秒过期,-1表示永不过期,-2表示已过期,默认是永不过期
- expire key:秒钟,为给定的key设置过期时间
- move key dbindex【0-15】:将当前数据库的key移动到给定的数据库,一个redis中默认带有16个库,默认访问0号库
- select dbindex:切换数据库【0-15】,默认为0
- dbsize:查看当前数据库key的数量
- flushdb:清空当前库
- flushall:通杀全部库
注意:
命令是不区分大小写的,但是key是区分大小写的。
help @类型,永远的帮助命令
2.3 String命令
set和get
所有的配置选项
set key value [NX|XX] [GET] [EX seconds|PX milliseconds|EXAT unix-time-seconds|PXAT unix-time-milliseconds|KEEPTTL]set可选的配置参数:
- EX seconds:以秒为单位设置过期时间
- PX mil1 iseconds:以毫秒为单位设置过期时间
- EXAT timestamp:设置以秒为单位的UNIX时间戳所对应的时间为过期时间
- PXAT milliseconds-timestamp:设置以毫秒为单位的UNIX时间戳所对应的时间为过期时间
- NX:键不存在的时候设置键值
- XX:键存在的时候设置键值
- KEEPTTL:保留设置前指定键的生存时间
- GET:返回指定键原本的值,若键不存在时返回ni1
set k1 v1xx
set k1 v1
//输出:(nil)
set k1 v1 get
//输出:"v1xx"
get k1
//输出:"v1"同时设置/获取多个键值
MSET key value [key value ...]
//一次性设置多个键值对进行存储
MGET key [key ...]
//一次性获取多个指定key的value值
msetnx
//保证完整性,要么全部成功,要么失败
获取指定区间的值
//相当于java中的substring(),针对字符串操作
setrange
getrange数值的增减
一定是数值型的字符才能进行加减。
set k1 101
INCR k1 //递增数字
INCRBY k1 步长 //按照步长增加数字
DECR K1 //递减数字
DECRBY K1 步长 //按照步长减小数字获取字符串长度及内容追加
//获取字符串长度
STRLEN k1
//内容追加
append k1 xxxxx分布式锁
setnx key value
setex(set with expire) 键 过期时间 值 |setnx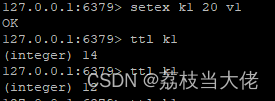
getset
先get再set
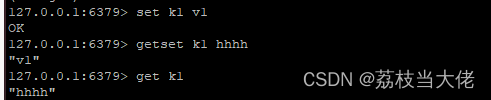
应用场景:点赞、关注等计数功能
2.4 List命令
Redis中的List数据结构是一种双端链表,主要的功能是push和pop,一般用在栈、队列、消息队列等场景。对两端的操作性能很高,中间的性能会弱一点。
- Ipush/rpush/Irange:lpush和rpush分别是先list链表的左端或者是右端插入元素,lrange是遍历的命令(lrange list1 0 -1);
- Ipop/rpop:左右弹出操作;
- lindex:按照索引下标获得元素(从上到下)
- llen:获取列表中元素的个数
- Irem key N v1:删除N个值等于v1的元素;
- Itrim key:开始index结束index,截取指定范围的值后再赋值给key;
- rpoplpush 源列表 目的列表:源列表的最右边的元素弹出并加到目的列表最左边;
- Iset key index value:修改指定的列表中指定索引的元素的值;
- linsert key before/after:己有值插入的新值

应用场景:微信公众号订阅消息
2.5 Hash
具体的命令操作如下:
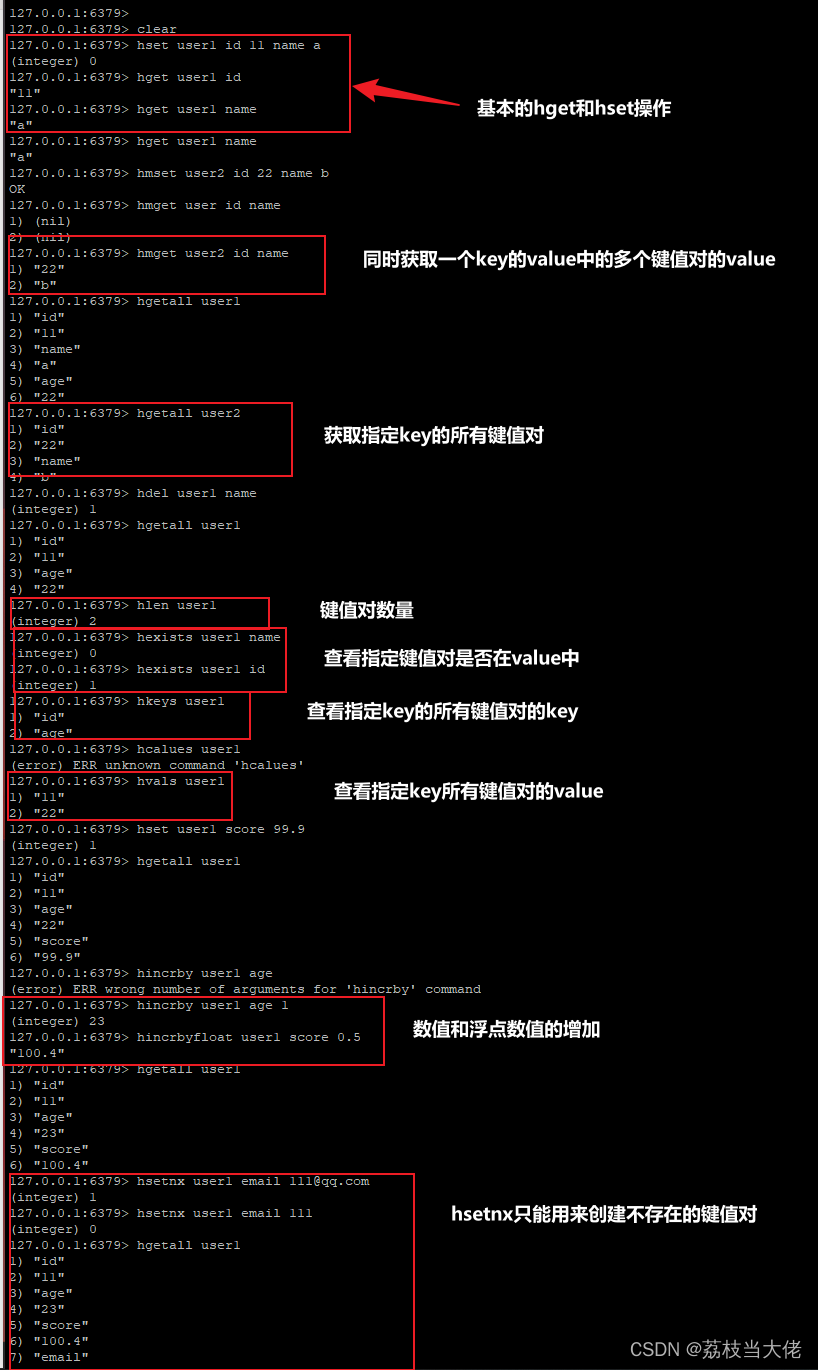
应用场景:早期设计中的中小型购物页面的的购物车。
2.6 Set和ZSet
2.6.1 set集合
单值多value,且无重复。
基本操作
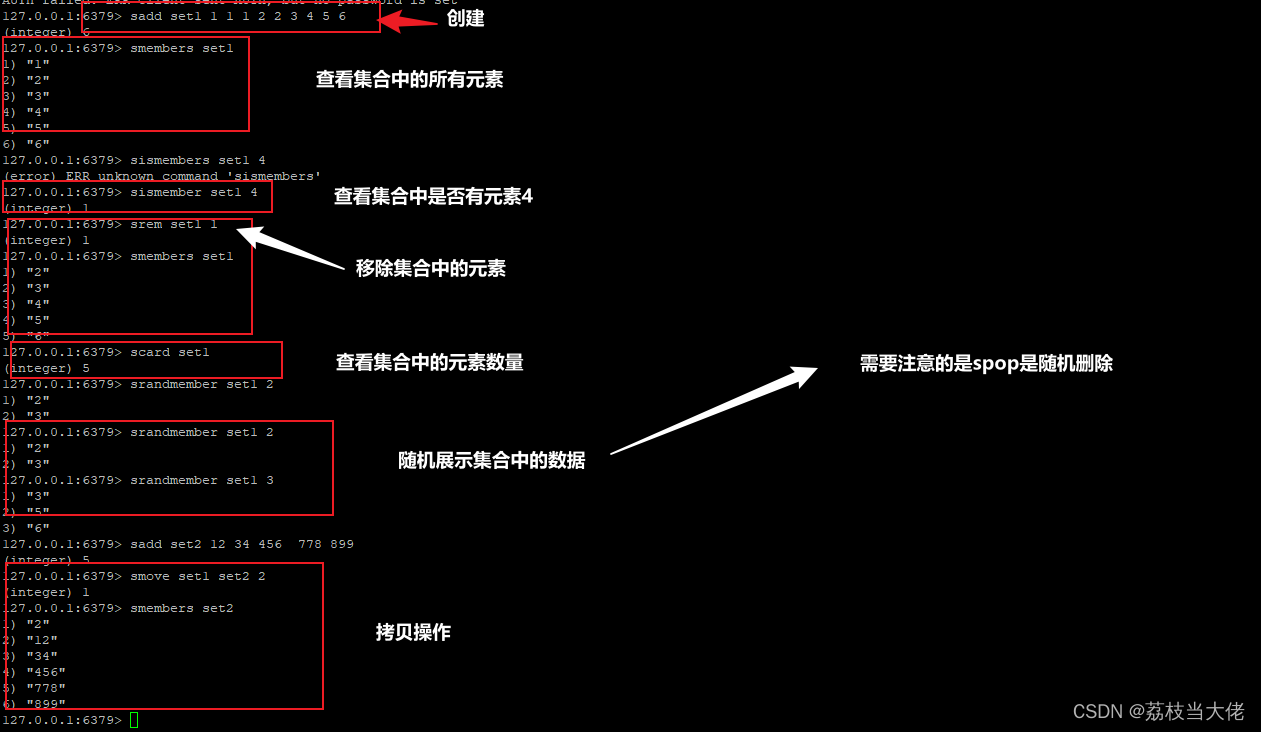
集合运算

//redis7新增
SINTERCARD set1 set2 [limit N]
不像sinter那样返回结果集,而是返回结果的基数,可以限制显示的key应用场景:社交应用、抽奖程序
2.6.2 ZSet
ZSet是一个有序集合,在set基础上,在每一个value前面加上一个排序分数score:zset k1 score v1,常见的zset指令如下图所示:
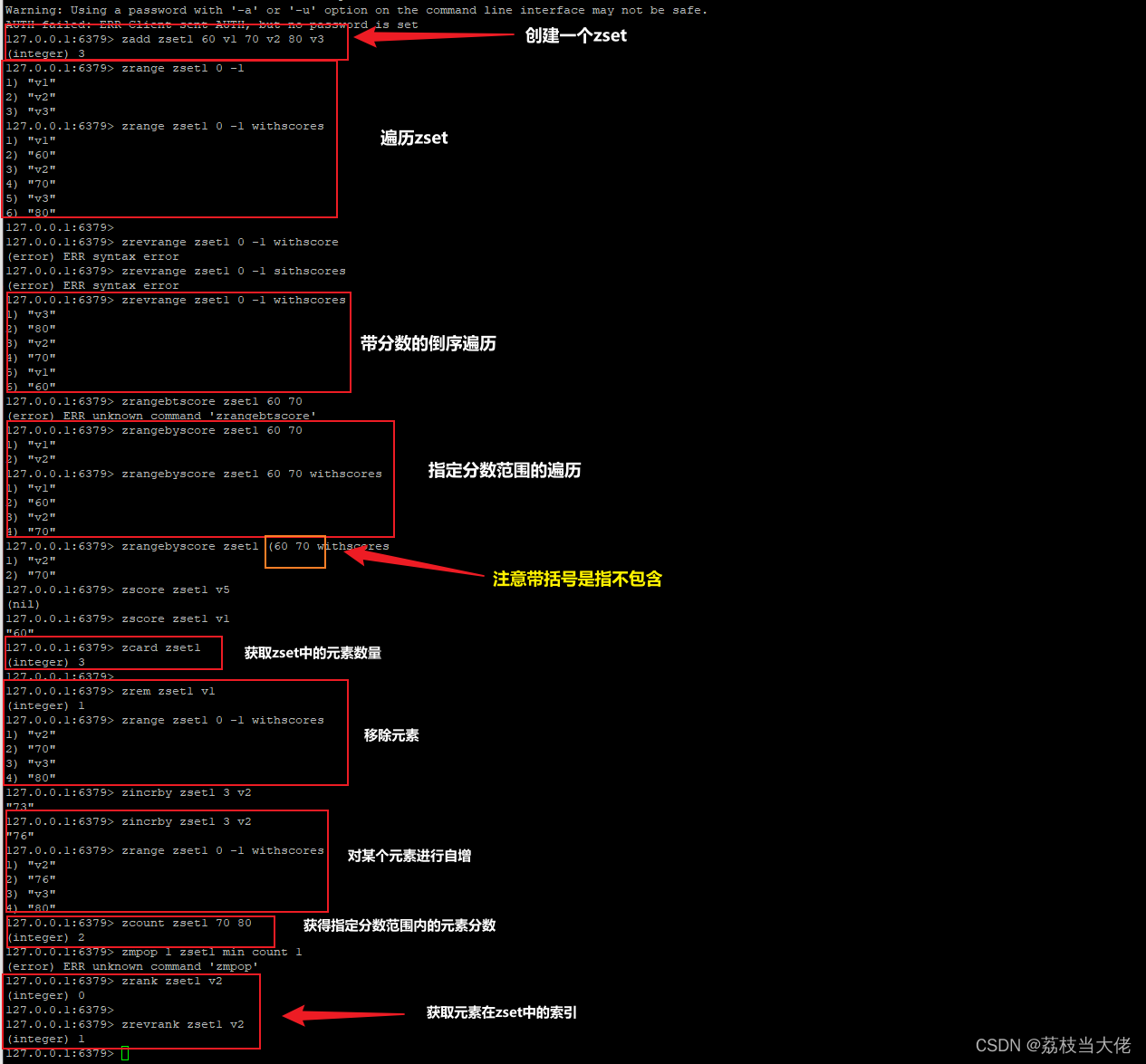
ZMPOP:从键名列表中的第一个非空排序集中弹出一个或多个元素,它们是成员分数对
zmpop 1 zset1 min count 1应用场景:对商品销售对商品进行排序显示
2.7 Bitmap位图
bitmap是用String类型作为底层数据结构实现的一种统计二值状态的数据类型位图,本质是数组,它是基于String数据类型的按位的操作。该数组由多个二进制位组成,每个二进制位都对应一个偏移量(我们称之为一个索引)。简单理解bitmap就是由0和1状态表示的二进制数组, 应用可以用在考勤、签到等场景。
- setbit:将二进制数组指定的index下的bit位置1或0,setbit key index 0|1;
- getbit:获取二进制数组指定的index下的bit位的值;
- strlen:获取的不是字符串长度而是占据几个字节,超过8位之后一组一byte再进行扩容;
- bitcount:全部键里面含有1的有多少个
- bitop:位运算操作命令and/or/not/xor:bitop operation destkey key
bitop and destkey k1 k2
对k1和k2中的bitmap数组进行与操作并给出同时为1的个数应用场景:查看某个用户的活跃度、点击率分析、广告、签到等
2.8 HyperLogLog
HyperLogLog基数统计,常用在进行访问量的独立用户数统计。首先需要了解基数的概念,基数就是一个集合中去重之后的真实个数。但是,因为HyperLogLog只会根据输入元素来计算基数,而不会储存输入元素本身,所以HyperLogLog不能像集合那样,返回输入的各个元素。

2.9 GEO
主要是用来解决地理空间信息的一种数据类型,这里将地球上的所有经纬度进行编码并在访问的时候进行查找,有效解决了在打车或地图软件在使用高峰期的问题。这里的GEO底层上是一种ZSet。
解决redis-client中的中文乱码问题:
redis-cli -a 123456 --raw [-p 6379]基本的操作环境

2.10 Stream
redis中的Stream就是redis版本的MQ中间件,比较常见的消息中间件比如kafka、RabbitMQ、rocketmq。redis消息队列一般有两种方案:一种是list实现消息队列(LPUSH、RPOP)一对一;另外一种是发布和订阅(PU、SUB)一对多。即使看起来在理论上已经满足了需求,但在redis宕机、客户端断开、网络断开的时候会出现消息丢弃,同时也没有ACK机制来保证数据的可靠性,消息无法首先持久化。redis5.0版本以来就提供了Stream来实现消息队列的订阅和发布的服务,Stream简单来说就是MA消息中间件+阻塞队列。
2.10.1 用途
实现消息队列,它支持消息的持久化、支持自动生成全局唯一ID、支持ack确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠
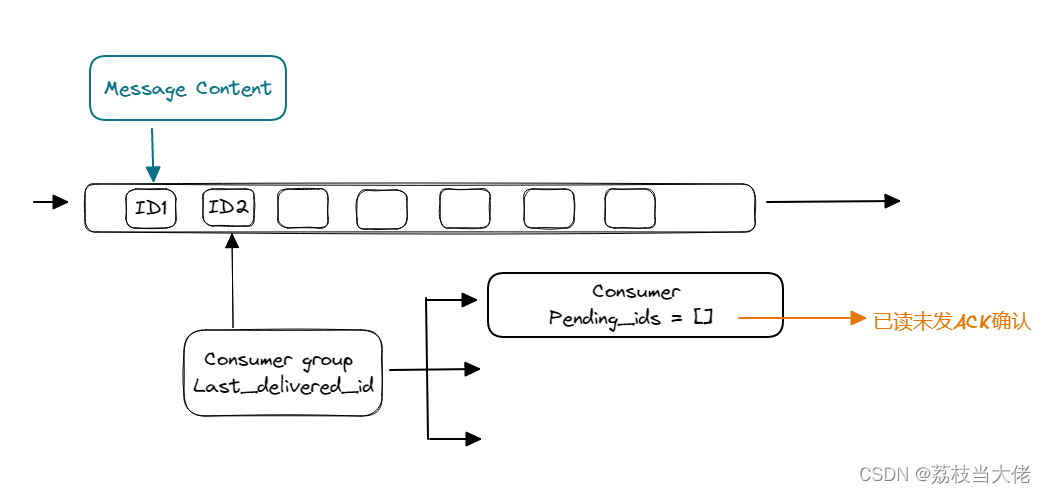
2.10.2 原理图
2.10.3 基本命令
队列相关指令
XADD:用于向Stream队列中添加消息,如果指定的Stream队列不存在,则该命令执行时会新建一个Stream队列,*号表示服务器自动生成MessageID(类似mysql!里面主键auto_increment),后面顺序跟着一堆业务key/value。rdis在增加信息条目时会检查当前id与上一条目的id,自动纠正错误的情况,一定要保证后面的d比前面大,一个流中信息条目的ID必须是单调增的,这是流的基础。
XADD mystream * k1 v1 k2 v2 k3 v3XRANGEL:用于获取消息列表(可以指定范围),忽略删除的信息。其中start表示开始值,-代表最小值;end表示结束值,+代表最大值;count表示最多获取多少个值。
xrange mystream - +XREVRANGE:反转并获取消息队列
xrevrange mystream + 1XDEL:按照主键进行删除操作
XLEN:获取消息队列的长度
XTRIM:用于对Stream的长度进行截取,如超长会进行截取
maxlen ---允许的最大长度,对流进行修剪限制长度
xtrim mystream maxlen 2
minid ---允许的最小id,从某个id值开始比该id值小的将会被抛弃
xtrim mystream minid idXREAD:用于获取消息(阻塞/非阻塞),只会返回大于指定ID的消息。$代表特殊ID,表示以当前Stream经存储的最大的ID作为最后一个ID,当前Stream中不存在大于当前最大ID的消息,因此此时返回nil。当不指定count的话默认会返回所有的消息。阻塞和不阻塞的选择是通过block来选择的。
xread count 1 block 0 streams mystream $消费组相关指令
XGROUP:用于创建消费组。
$表示从Stream尾部开始消费,也就是消费未来的新消息
xgroup create mystream groupA $
0表示从Stream头部开始消费
xgroup create mystream groupA 0
XREADGROUP:消费组中的消费者读取消息
// A组消费者2读取该消息队列中的消息
XREADGROUP group groupA consumer2 count 1 streams mystream >
需要注意的是:stream中的消息一旦被消费组里的一个消费者读取了,就不能再被该消费组内的其他消费者读取了,即同一个消费组里的消费者不能消费同一条消息。刚才的XREADGROUP命令再执行一次,此时读到的就是空值。我们可以通过一个组内的消费组同时读取不同的消息实现消费组内的负载均衡。
重点:XACK问题
基于Stream实现的消息队列,如何保证消费者在发生故障或宕机再次重启后,仍然可以读取未处理完的消息?
Streams会自动使用内部队列(也称为PENDING List)留存消费组里每个消费者读取的消息保底措施,直到消费者使用XACK命令通知Streams"消息己经处理完成"。消费确认增加了消息的可靠性,一般在业务处理完成之后,需要执行XACK命令确认消息己经被消费完成。
XPENDING:查看每个消费组内所有消费者已读取但未确认的消息
XACK:确认消息,XACK mystream group1 消息ID
XINFO:用于答应Stream/Consumer/Group的详细信息,xinfo stream mystream
2.11 bitfield*
bitfield位域,作用在于它能够将很多小的整数储存到一个长度较大的位图中,又或者将一个非常庞大的键分割为多个较小的键来进行储存,从而非常高效地使用内存,使得Reds能够得到更多不同的应用一特别是在实时分析领域:能够以指定的方式对计算溢出进行控制。简单说就是:bitfield能将一个Redis字符串看作是一个由二进制位组成的数组并能对变长位宽和任意没有字节对齐的指定整型位域进行寻址和修改。
两大作用:位域修改(对字节码的修改)、溢出控制。
总结
通过上面的阅读相信大家能够跟荔枝一样对Redis有了一个初步的认知,在了解完基本的数据类型和操作指令之后我们即将往下继续学习。希望荔枝的笔记分享能够帮助到正在学习的小伙伴哈哈哈,有需要的自取哈~~~
今朝已然成为过去,明日依然向往未来!我是小荔枝,在技术成长的路上与你相伴,码文不易,麻烦举起小爪爪点个赞吧哈哈哈~~~ 比心心♥~~~














 1154
1154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









