







二叉搜索树的概念和结构
二叉搜索树的概念
二叉搜素树是在一颗普通的二叉树上面加入了特殊的限制条件。
首先我们以前的二叉树的结构包含:根节点,左子树和右子树,左子树和右子树又可以分成根节点和左右子树。
所以说二叉树是递归构建的。
二叉搜索树就是左子树的所有节点都小于根节点,右子树的所有节点都大于根节点这样一棵树。
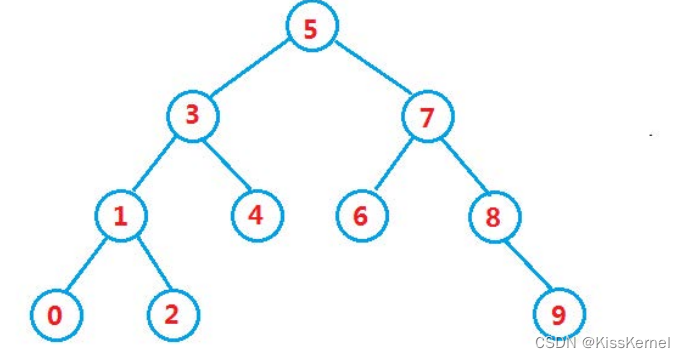
这张图就是一颗二叉搜索树,顾名思义,这棵树是用来搜索,也就是查找的。
二叉搜索树的查找
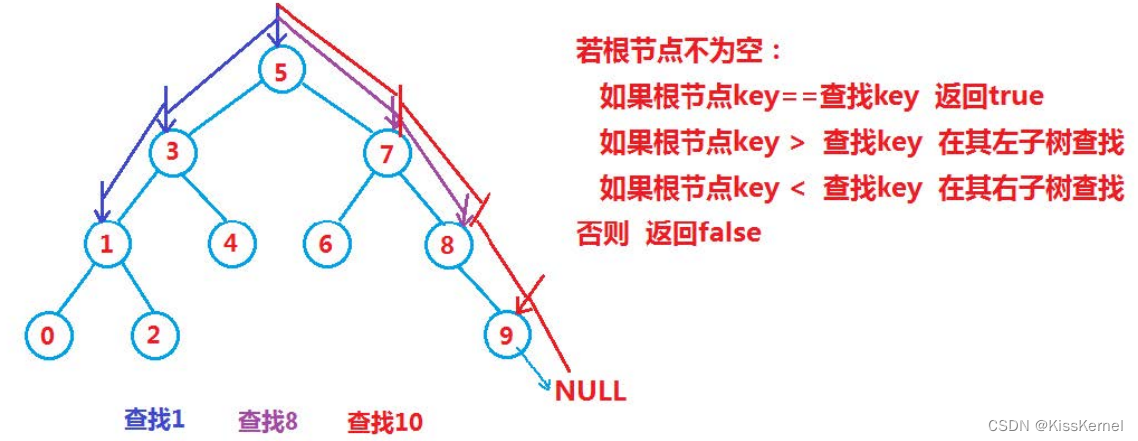
二叉搜索树的搜索效率很高。如果在最优的情况下是O(logN),因为只需要最多比较高度次就可以搜索完毕。
这里用查找8,来举例子。首先8 > 5所以8肯定不在左子树,应该去右子树查找。8 > 7 再次去7的右子树查找。找到了8.
二叉搜索树的插入
如果是空树的话,直接new一个节点就行
如果不是空树,就需要先查找到插入位置,这里的二叉搜索树是不可以在一棵树里面有同样的元素的。如果有就返回false插入失败即可。所以这里的二叉搜索树还有去重的作用。
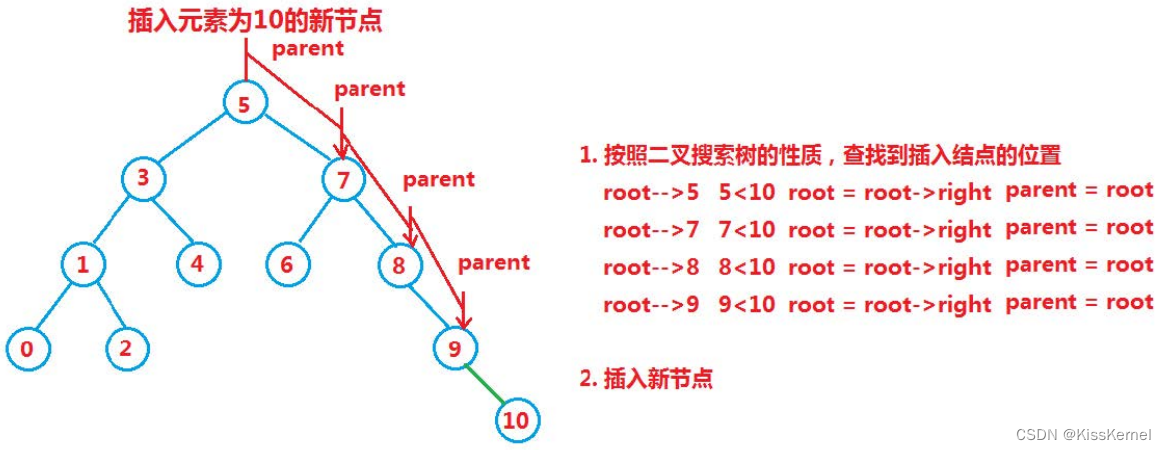
走到空的时候就new一个节点然后连接起来。
二叉搜索树的删除
二叉搜索树的删除分为四种情况。
1.要删除的节点是叶子节点
2.要删除的节点左子树为空
3.要删除的节点右子树为空
4.要删除的节点左右子树都不为空
对应的删除思路,如果是叶子节点,直接删掉,然后让他的父亲指向该节点的指针指向空即可。
二三种情况可以合并,如果是被删除节点的左子树为空,直接删掉该节点然后让被删除节点的父亲节点指向该节点的右子树。如果被删节点是右子树为空的时候相反。
要删除节点的左右子树都不为空的时候是最复杂的。
首先要在被删节点的左子树里面找到最大的节点(也就是左子树的最大节点)或者是在右子树里面找到最左边的节点(也即是右子树里面的最小节点)
这里假设是在右子树里面找最左节点假设叫做min节点,将该节点的值与被删除的节点的值交换。然后删除这个min节点即可,删除min节点的时候很简单,如果是递归,只需要再次调用删除节点的函数删掉min节点。即可,如果是迭代删除,只需查找min节点的时候保存min节点的parent节点,然后删除min节点就变成了上面的第2种情况的删除。
二叉搜索树的代码实现
#pragma once
#include<iostream>
#include<string>
#include<algorithm>
using namespace std;
namespace K
{
template<class K>
struct BSTNode
{
K _val;
struct BSTNode* _left;
struct BSTNode* _right;
BSTNode(const K& val = K())
:_val(val)
,_left(nullptr)
,_right(nullptr)
{}
};
template<class K>
struct BSTree
{
typedef BSTNode<K> Node;
BSTree()
:_root(nullptr)
{}
private:
Node* _root;
};
}
这是二叉搜索树的框架结构。
//迭代方式插入
bool insert(const K& x)
{
if (_root == nullptr)
{
_root = new Node(x);
return true;
}
Node* prev = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_val > x)
{
prev = cur;
cur = cur->_left;
}
else if (cur->_val < x)
{
prev = cur;
cur = cur->_right;
}
else
{
return false;
}
}
cur = new Node(x);
if (prev->_val < x)
prev->_right = cur;
else
prev->_left = cur;
return true;
}
//递归方式插入
bool insertR(const K& val)
{
return _insert(_root, val);
}
//递归插入节点的子函数
bool _insert(Node*& root, const K& val)
{
if (root == nullptr)
{
root = new Node(val);
return true;
}
if (root->_val > val)
return _insert(root->_left, val);
else if (root->_val < val)
return _insert(root->_right, val);
else
return false;
}
这是插入节点的函数,
迭代插入的思想:用一个cur节点进行遍历整个树,prev保存cur的父节点方便连接,当cur走到空的时候就是找到了插入位置,将节点插入然后和prev连接起来,即可。如果找到了和插入的值相同的节点则说明插入失败。
递归插入的思想:通过root进行遍历二叉树,如果root的val大于插入值则递归去左子树插入,小于则递归去右子树插入。等于就是插入失败。如果走到了空,就直接将root置为新的节点,因为这里使用的是指针的引用。所以这里root是nullptr,也是上一个栈帧里面root的left或者right,因为root为引用,所以root改变了,上一个栈帧的left或者right就改变了。所以这里就完成了连接。
//find 迭代版本
Node* find(const K& x)
{
Node* cur = _root;
while (cur)
{
if (cur->_val < x)
cur = cur->_right;
else if (cur->_val > x)
cur = cur->_left;
else
return cur;
}
return nullptr;
}
//find递归版本
Node* findR(const K& x)
{
return _find(_root, x);
}
//查找递归子函数
Node* _find(Node* root, const K& x)
{
if (root == nullptr)
return nullptr;
if (root->_val > x)
{
return _find(root->_left, x);
}
else if (root->_val < x)
{
return _find(root->_right, x);
}
else
return root;
}
查找的思路很简单,查找的值比根节点大,就去右子树继续查找。比根节点小就去左子树查找。
//1.没有孩子直接删除
//2.一个孩子直接删除
//3.两个孩子替换法删除
//erase迭代版本
bool Erase(const K& val)
{
Node* cur = _root;
Node* prev = nullptr;
while (cur)
{
if (cur->_val > val)
{
prev = cur;
cur = cur->_left;
}
else if (cur->_val < val)
{
prev = cur;
cur = cur->_right;
}
else
{
//找到了准备删除
if (cur->_left == nullptr)
{
//此时cur就是_root
if (prev == nullptr)
_root = cur->_right;
else
{
if (prev->_left == cur)
prev->_left = cur->_right;
else
prev->_right = cur->_right;
}
delete cur;
}
else if (cur->_right == nullptr)
{
if (prev == nullptr)
_root = cur->_left;
else
{
if (prev->_left == cur)
prev->_left = cur->_left;
else
prev->_right = cur->_left;
delete cur;
}
}
else
{
//去右子树找最小的节点
Node* minParent = cur;
Node* min = cur->_right;
while (min->_left)
{
minParent = min;
min = min->_left;
}
cur->_val = min->_val;
if (minParent->_left == min)
minParent->_left = min->_right;
else
minParent->_right = min->_right;
delete min;
}
return true;
}
}
return false;
}
//Erase递归版本
bool EraseR(const K& val)
{
return _EraseR(_root, val);
}
//Erase递归的子函数
bool _EraseR(Node*& root, const K& key)
{
if (root == nullptr)
return false;
if (root->_val < key)
{
return _EraseR(root->_right, key);
}
else if (root->_val > key)
{
return _EraseR(root->_left, key);
}
else
{
Node* del = root;
if (root->_left == nullptr)
root = root->_right;
else if (root->_right == nullptr)
root = root->_left;
else
{
Node* min = root->_right;
while (min->_left)
min = min->_left;
swap(min->_val, root->_val);
return _EraseR(root->_right, key);
}
delete del;
return true;
}
}
删除这里的主要部分就是找到了节点之后如果节点的左右子树都不是空,那么使用替换法删除,递归法的替换法删除简单一点,因为只需要找到min节点交换后,递归来到被删除节点的右子树查找key值然后删掉就可以了。
迭代法,就需要在找到min节点的时候保存min节点的parent,然后可以将min节点的值与被删除节点的值交换,也可以直接用min节点的值覆盖被删除节点,然后将parent与min节点的右子树连接起来就行(min的左子树为空,所以肯定是连接右子树)
//中序遍历
void Inorder()
{
_Inorder(_root);
cout << endl;
}
//中序遍历递归子函数
void _Inorder(Node* root)
{
if (root == nullptr)
return;
_Inorder(root->_left);
cout << root->_val << " ";
_Inorder(root->_right);
}
这是中序遍历的代码,很简单,但是二叉搜索树这里为什么要使用中序遍历呢?仔细观察这颗树
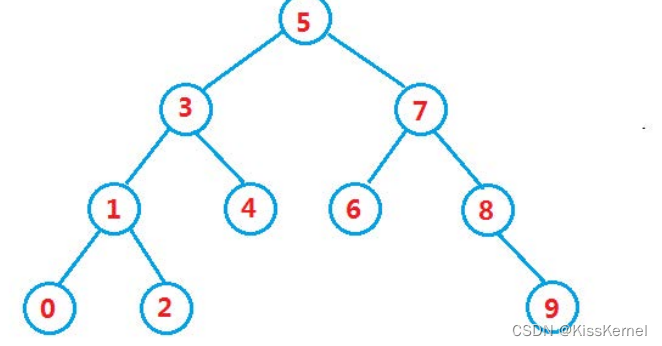
如果使用中序遍历后,结果是:0,1,2,3,4,5,6,7,8,9。搜索二叉树的中序遍历打印出来的数字是有序的。
二叉搜索树的效率问题
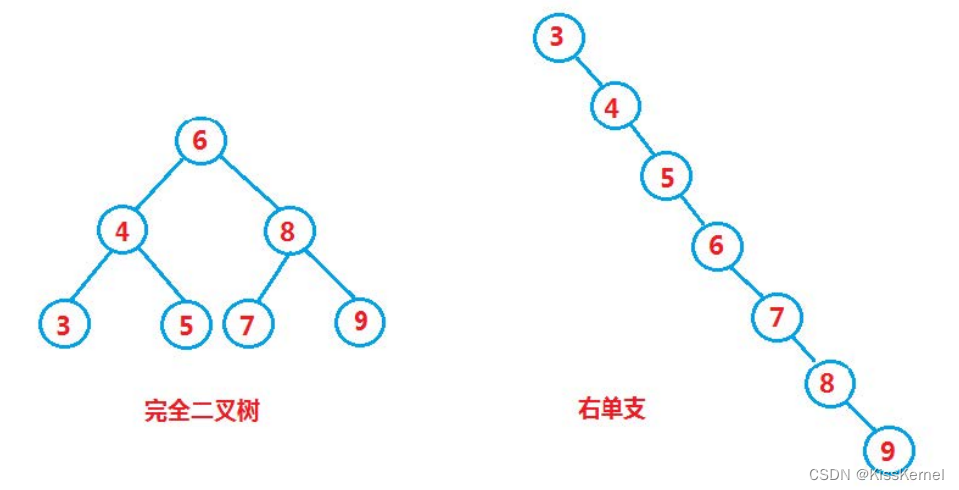
来看这两个结构,分别对应着最优情况和最坏情况。最优情况,二叉搜索树是一颗完全二叉树,那么此时的搜索效率就是logN,如果是右边的最坏情况那么此时的搜索效率和遍历所有节点的效率就一样了是O(N)。那么什么情况会导致右边这样子的二叉搜索树呢?
答案是:如果将一个升序的数列依次插入,那么搜索二叉树就会退化到右边这种情况,单支情况。
那么如何解决二叉搜索树的退化问题呢?这就需要我们学习AVL树又叫做平衡二叉树,和红黑树了。
二叉搜索树的应用
key搜索模型
什么是key搜索模型,主要的核心就是判断某个值在不在二叉树内。举例就是比如学校的学生查询系统是采用了搜索二叉树,那么只需要在这个系统内输入要查找的学号就可以判断这个学号是不是本校的学生。
还有就是比如小区门口识别业主的车牌,也可使用二叉搜索树的key搜索模型
key/value搜索模型
key/value搜索模型就是在二叉树的每个节点内存一个val值,作用就是可以通过key值来找到value值。
应用情况比如:中英字典,可以使用这种搜索模型,搜索一个单词就能一同找到这个单词对应的中文意思。
key/value搜索模型还可以用来统计次数,只需要将value设置成一个计数器,每次插入的时候遇到key相同的节点就++value即可。
同时因为二叉搜索树的中序遍历是有序的。所以我们还可以按照key进行排序
STL里面的set就是一个key搜索模型
map就是一个key/value搜索模型(只不过map底层是一颗红黑树)
下面简单看一下key/value搜索模型的代码实现
namespace KV
{
template<class K, class V>
struct BSTreeNode
{
BSTreeNode<K, V>* _left;
BSTreeNode<K, V>* _right;
K _key;
V _value;
BSTreeNode(const K& key, const V& value)
:_left(nullptr)
, _right(nullptr)
, _key(key)
, _value(value)
{}
};
template<class K, class V>
struct BSTree
{
typedef BSTreeNode<K, V> Node;
public:
BSTree()
:_root(nullptr)
{}
bool Insert(const K& key, const V& value)
{
if (_root == nullptr)
{
_root = new Node(key, value);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
return false;
}
}
cur = new Node(key, value);
if (parent->_key < key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}
Node* Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
cur = cur->_right;
}
else if (cur->_key > key)
{
cur = cur->_left;
}
else
{
return cur;
}
}
return nullptr;
}
bool Erase(const K& key)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
// 找到,准备开始删除
if (cur->_left == nullptr)
{
if (parent == nullptr)
{
_root = cur->_right;
}
else
{
if (parent->_left == cur)
parent->_left = cur->_right;
else
parent->_right = cur->_right;
}
delete cur;
}
else if (cur->_right == nullptr)
{
if (parent == nullptr)
{
_root = cur->_left;
}
else
{
if (parent->_left == cur)
parent->_left = cur->_left;
else
parent->_right = cur->_left;
}
delete cur;
}
else
{
Node* minParent = cur;
Node* min = cur->_right;
while (min->_left)
{
minParent = min;
min = min->_left;
}
cur->_key = min->_key;
cur->_value = min->_value;
if (minParent->_left == min)
minParent->_left = min->_right;
else
minParent->_right = min->_right;
delete min;
}
return true;
}
}
return false;
}
void InOrder()
{
_InOrder(_root);
cout << endl;
}
private:
void _InOrder(Node* root)
{
if (root == nullptr)
{
return;
}
_InOrder(root->_left);
cout << root->_key << ":" << root->_value << endl;
_InOrder(root->_right);
}
private:
Node* _root;
};
void TestBSTree1()
{
// 字典KV模型
BSTree<string, string> dict;
dict.Insert("sort", "排序");
dict.Insert("left", "左边");
dict.Insert("right", "右边");
dict.Insert("map", "地图、映射");
dict.Insert("hash", "哈希");
string str;
while (cin >> str)
{
BSTreeNode<string, string>* ret = dict.Find(str);
if (ret)
{
cout << "对应中文解释:" << ret->_value << endl;
}
else
{
cout << "无此单词" << endl;
}
}
}
void TestBSTree2()
{
// 统计出现次数
string arr[] = {"map","vector","hash","string","map","hash","string","map","vector","map"};
BSTree<string, int> countTree;
for (auto& str : arr)
{
//BSTreeNode<string, int>* ret = countTree.Find(str);
auto ret = countTree.Find(str);//使用auto自动识别类型
if (ret != nullptr)
{
ret->_value++;
}
else
{
countTree.Insert(str, 1);
}
}
countTree.InOrder();
}
}
实现思路与key搜索模型的完全相同,不同的就是每个节点里面多了一个val,需要根据这里改动插入函数和中序遍历函数,其他的函数不需要更改。因为查找函数和删除函数都是需要查找,查找的时候使用的是key值进行的查找。
















 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











