






部分图片参考转载自大佬的KMP讲解
一、为什么需要KMP
KMP是一种字符串模式匹配算法,目的是快速的帮助我们找到字符串b是否是字符串a的连续子串。
暴力解法(朴素BF)
规定i是主串的下标,j是想要被匹配的字符串的下标。
- 双重for循环,用遍历的方式去一个一个匹配,当匹配成功的时候就i ++, j ++
- 如果匹配失败的话,i就应该回溯到本次起始坐标的下一个,j回到0。
下面是代码
int bf(char S[], char s[])
{
int i = 0, j = 0;
while (S[i] != '\0' && s[j] != '\0')
{
if (S[i] == s[j]) i ++, j ++;
else
{
i = i - j + 1;
// 因为j是从0开始,所以j的数值就是i移动过的距离
j = 0;
}
}
if (s[j] == '\0') return i - j;
return -1;
}
通过分析我们发现复杂度是O((n-m+1)*m) ~ O(nm) n和m分别是两字符串的长度
乘法的复杂度对我们来说是不能够接受的,因此就需要KMP算法
二、KMP(O(n + m))
介绍KMP之前,首先先看一张图片,这张图片会帮你理解KMP是怎么来运行的。

基本思路
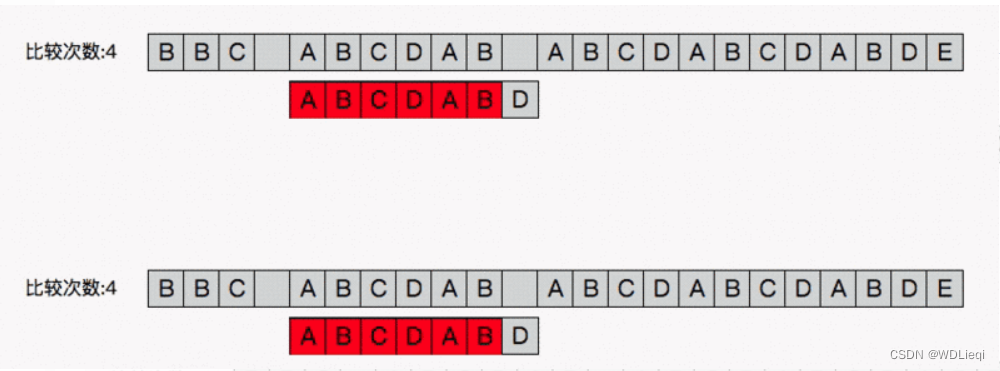
我们可以看到前面的步骤是和朴素算法一样的,关键就是找到不匹配的下一个起始点
应该选择的地方

可以看见KMP跳过了很远的距离,这也就是KMP算法的关键:next数组。
next数组记录的是一个字符串前缀和后缀相同的最大的长度。
例子:字符串abababca,长度为6
f(1) = 0; 因为 a 没有前缀和后缀,根据规定为 0
f(2) = 0; 因为 ab 无相等的前缀和后缀
f(3) = 1; 因为 aba 有长度为一的前缀和后缀 a
f(4) = 2; 因为 abab 有长度为二的前缀和后缀:ab
f(5) = 3; 因为 ababa 有长度为三的前缀和后缀:aba
f(6) = 4; 因为 ababab 有长度为四的前缀和后缀:abab

next数组的求法
对于next数组我们可以用双指针的方法来进行求解。
我们可以把next数组看成自己对自己进行一个匹配的过程,只是两个数组变成了原数组的前缀和后缀。我们还是以abababca来进行举例。我们取 i 是原字符串的末尾下标,取 j 是被匹配的字符串的末尾下标。 next数组的求法过程中也是对next数组的不断调用过程。
我们可以知道,长度为3的后缀就是下标从n - 2 ~ n 的字符串(我这里是从1开始),前缀就是从1 ~ 3 的字符串,所以可以想如果我们去求next[3],那么我们就用next[2]来进行定位,假设是next[2] = 1,那么我前面一定有一个前后缀相等的串,我们把位置j 移到next[j]上,最后我们再去比较s[i] 是否等于 s[j],不等就继续移,相等则在next[2] 的基础上加1。具体如下:

这里 j + 1 也可以看成是前后缀的长度。
next 数组代码
void next()
{
for (int i = 2, j = 0; i <= n; i++)
{
while (j && s[i] != s[j + 1]) j = ne[j];
if (s[i] == s[j + 1]) j++;
ne[i] = j;
}
}
匹配过程
匹配过程上图已经阐述的非常明显了,就是用next数组来记录位置,然后读取进行节省时间
void match()
{
for (int i = 1, j = 0; i <= m; i ++)
{
while (j && q[i] != s[j + 1]) j = ne[j];
if (q[i] == s[j + 1]) j ++;
if (j == n)
{
cout << i - n << ' ';
j = ne[j];
}
}
}
例题:
https://www.luogu.com.cn/problem/P3375
AC代码:
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 10;
int ne[N];
char p[N], s[N];
int n, m;
int main()
{
cin >> p + 1 >> s + 1;
n = strlen(s + 1);
m = strlen(p + 1);
for (int i = 2, j = 0; i <= n; i ++)
{
while (j && s[i] != s[j + 1]) j = ne[j];
if (s[i] == s[j + 1]) j ++;
ne[i] = j;
}
for (int i = 1, j = 0; i <= m; i ++)
{
while (j && p[i] != s[j + 1]) j = ne[j];
if (p[i] == s[j + 1]) j ++;
if (j == n)
{
cout << i - n + 1 << '\n';
j = ne[j];
}
}
for (int i = 1; i <= n; i ++) cout << ne[i] << ' ';
return 0;
}















 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









