






串的概念
字符串的概念很简单,就是一堆字符形成的有限序列。比如 "看到这里的都是帅哥","abcdef"等都是字符串。而字符串字符的个数就是字符串的长度。通常一个字符串的结束标识是'\0'。
对串的操作通常都是针对子串进行的,子串可以理解为就是一个字符串的子集,比如"帅哥"就是"看到这里的都是帅哥"的子串,而"看到这里的都是帅哥"又是"帅哥"的主串。
串的存储结构
对于字符串的存储,大家也不陌生了,通常都是定义一个静态数组,这是因为我们一般都是对字符串进行查询或者单独取一个字符。但是如果要对字符串进行修改,最好是使用动态数组,进行修改时几乎都会用到字符串长度来作为结束条件,在我们学习动态数组时我们就知道最好不用采取遍历的方式求长度,因为此时的时间复杂度是O(n),而是直接定义一个长度length记录,此时时间复杂度是O(1)。
typedef struct
{
char *str; //字符串
int length; //记录长度
}Str;串的基本操作
串的基本操作大家主要还是重在理解就行了,考试的时候一般不会考,应用时直接使用字符串函数就行了,这里学习主要还是为了更好的理解底层原理(也没必要深研其中代码,觉得熟练可以直接跳过)。
串的基本操作有字符串赋值、比较、连接、求子串等。
字符串赋值
在C语言中,字符串赋值不能直接用 '=' 实现,不过在python等其它高级编程语言可以(考试一般都是C/C++,就不多说了)。而我们通常会定义一个数组然后通过不断遍历进行单个字符赋值来实现。字符串函数实现就用strcpy()。
void strassign(Str *a,char b[]) //将字符串b赋值给a
{
int len = 0;
while(b[len]) //先求出字符串的长度
{
len++;
}
if(a->str!=NULL) //a->str一开始最好初始化为空
{
free(a->str);
}
if(len == 0) //如果给其赋值的字符串为空
{
a->str = NULL;
a->length = 0;
}
else
{
a->str = (char *)malloc(sizeof(char)*(len+1)); /*申请内存,+1
是为了存储\0*/
for(int i=0;i<=len;i++) //逐一赋值,<=是为了将\0也保存
{
a->str[i] = b[i];
}
a->length = len;
}
}字符串比较
字符串的比较都是比较字符的ASCII码。两个字符串A和B进行比较,会从两个字符串的第一个字符开始比较,比较两个字符的ASCII码大小从而判断大小,如果两个字符相同就会比较下一个字符。如果直到一个字符串遍历完了都是相等的,长的那一方会被认定为较大。字符串函数实现就用strcmp()。

int strcompare(Str a,Str b)//a<b返回值小于0,a>b返回值大于0,a=b返回值等于0
{
int i = 0;
while(a.str[i]!='\0'&&b.str[i]!='\0')//两个字符串不为空
{
if(a.str[i]!=b.str[i])//两者不同直接比较
{
return a.str[i] - b.str[i];
}
else
{
i++;
}
}
return a.length - b.length; //有一方遍历完了或者都遍历完了
}字符串连接
连接其实跟赋值差不多的原理,都是每个字符进行赋值来完成的。字符串函数实现就是strcat()。
void strconcat(Str a,Str b,Str *c)//把a和b的连接串赋值给c
{
int i;
if(c->str)
free(c->str);
c->length = a.length + b.length;
c->str = (char*)malloc(sizeof(char)*(c->length+1));
for(i=0;i<a.length;i++)
{
c->str[i] = a.str[i];
}
for(i=0;i<=b.length;i++) //注意把\0赋值过来
{
c->str[a.length + i] = b.str[i];
}
c->length = a.length + b.length;
}求子串
将字符串中某一位置开始到某一位置结束的串的操作成为求子串操作。(开始位置在结束位置之前)。字符串函数实现就是strncpy()。(如果使用strncpy要手动添加\0结束符)
bool substring(Str *substr,Str str,int kaishi,int len)
{
if(kaishi<0||kaishi>str.length||len<0||len>str.length-kaishi)//不合法输入
return false;
if(substr->str) //清空原先的内存
{
free(substr->str);
substr->str = NULL;
}
if(len == 0)
{
substr->length = 0;
substr->str = NULL;
return true;
}
substr->length = len;
substr->str = (char *)malloc(sizeof(char)*(len+1));
int i;
for(i=0;i<len;i++)
{
substr->str[i] = str.str[kaishi + i];
}
substr->str[substr->length] = '\0';
return true;
}不过需要注意的是这个代码对于中文或者多字符集一旦截取长度有问题就会出现一些乱码。
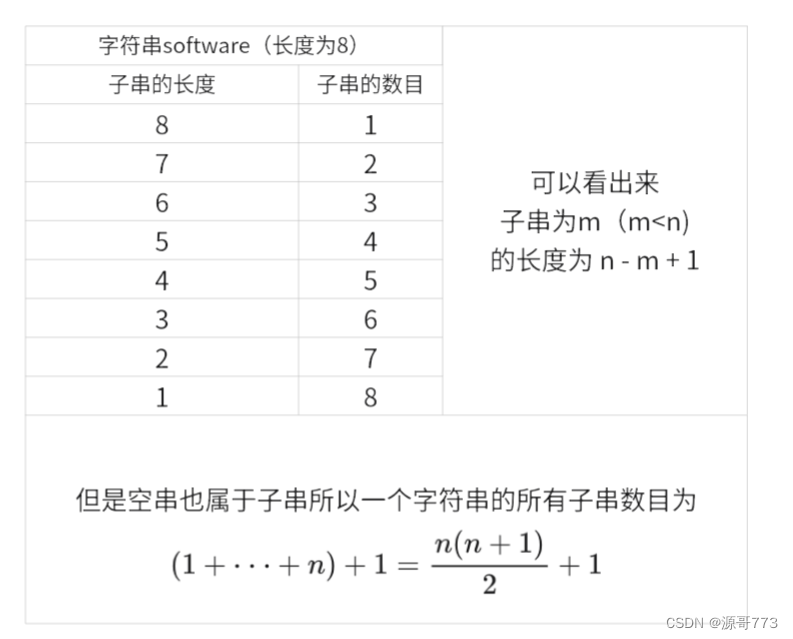
所有子串的数目:
串的模式匹配(重点)
可以说这算是这一章唯一的考点。串的模式匹配就是给一个模式串,需要在一个主串中找到与模式串相同的子串,并返回对应的数组下标。

先讲讲简单模式匹配算法,我愿称之为暴力无脑匹配算法。

int commonpipei(Str str,Str substr) //朴素匹配(我这里下标是从0开始的)
{
for(int i=0;i<=str.length - substr.length;i++) //一共匹配n-m+1次
{
int j;
for(j=0;j<substr.length;j++)//匹配m次
{
if(str.str[i+j]!=substr.str[j])//不匹配跳到下一个子串,否则比较下一个字符
{
break;
}
}
if(j == substr.length)//匹配成功返回数组下标
return i ;
}
return -1;
}
int commonpipei(Str str,Str substr) //朴素匹配(主串和模式串下标是从1开始的)
{
for(int i=1;i<=str.length - substr.length + 1;i++)
{
int j;
for(j=1;j<=substr.length;j++)
{
if(str.str[i]!=substr.str[j])
{
break;
}
}
if(j > substr.length)
return i;
}
return 0;
}KMP算法
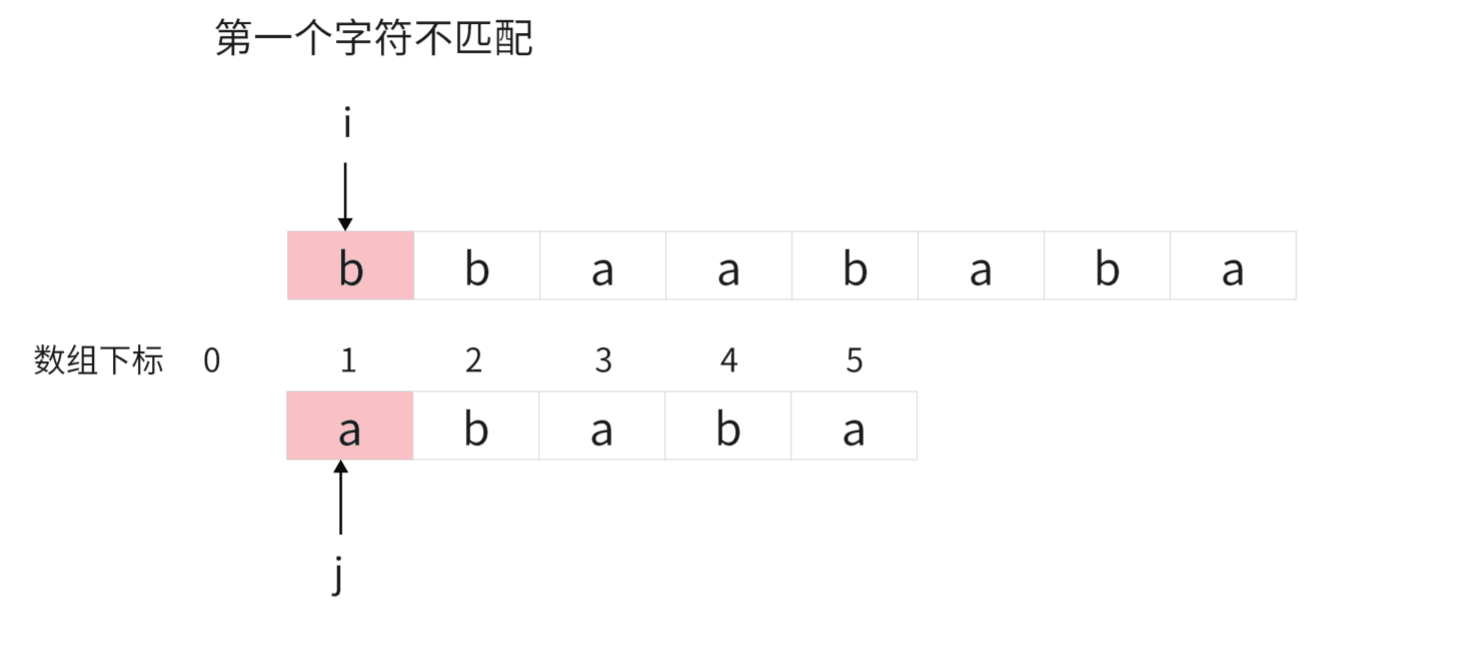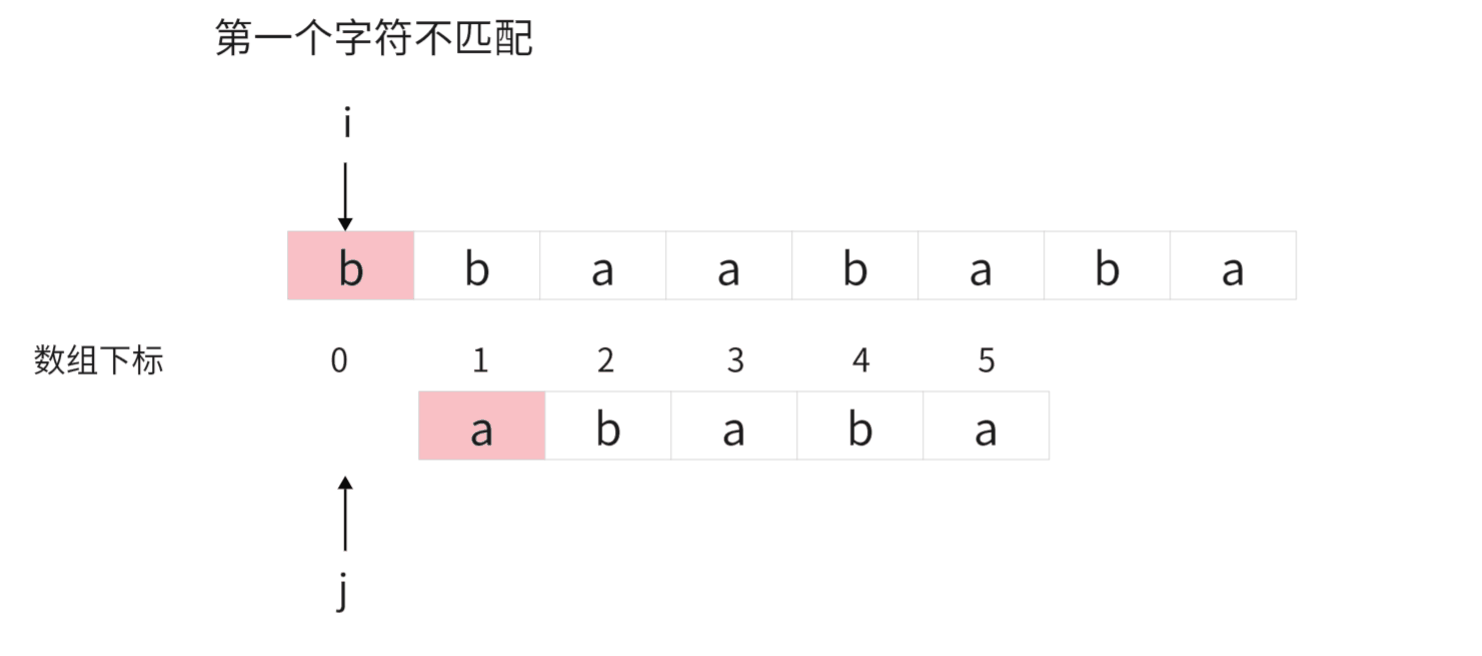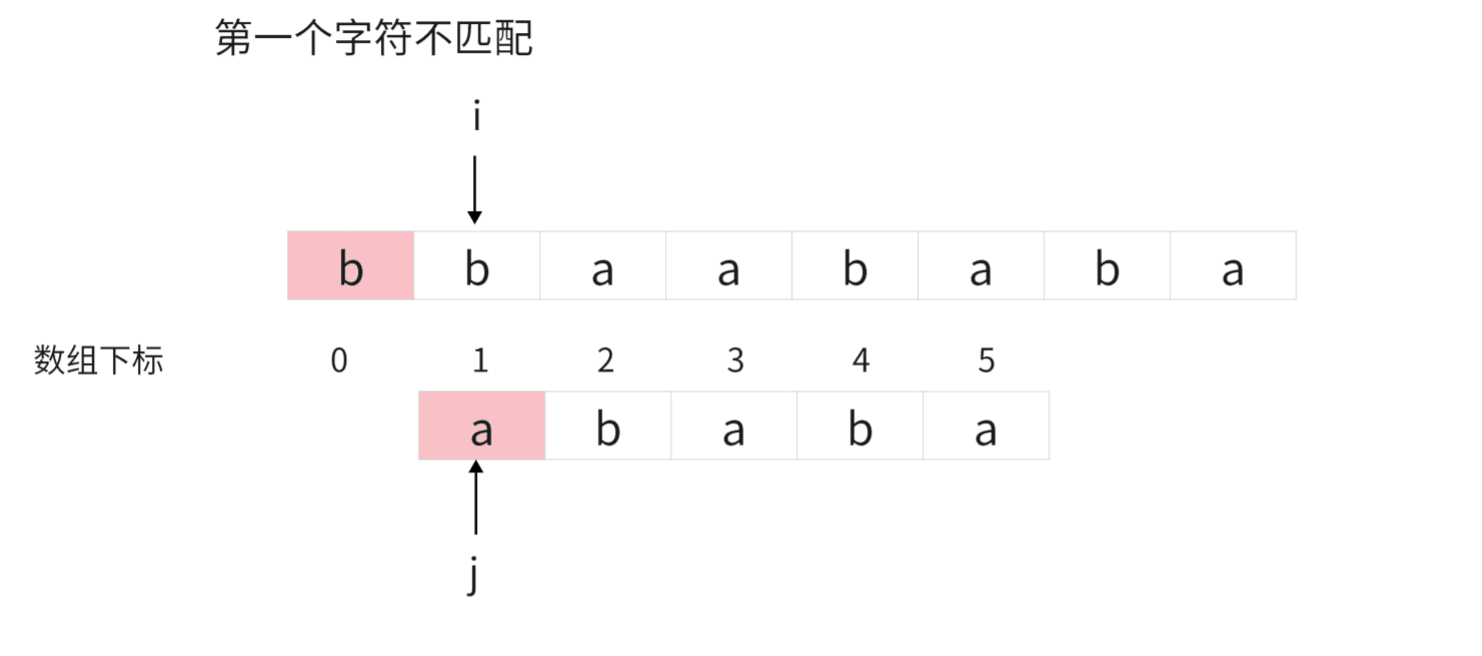
可以看出简单模式匹配是一种效率很低的匹配算法,特别是遇到有重复前缀的模式串时就非常的笨。
比如说下面这个例子:
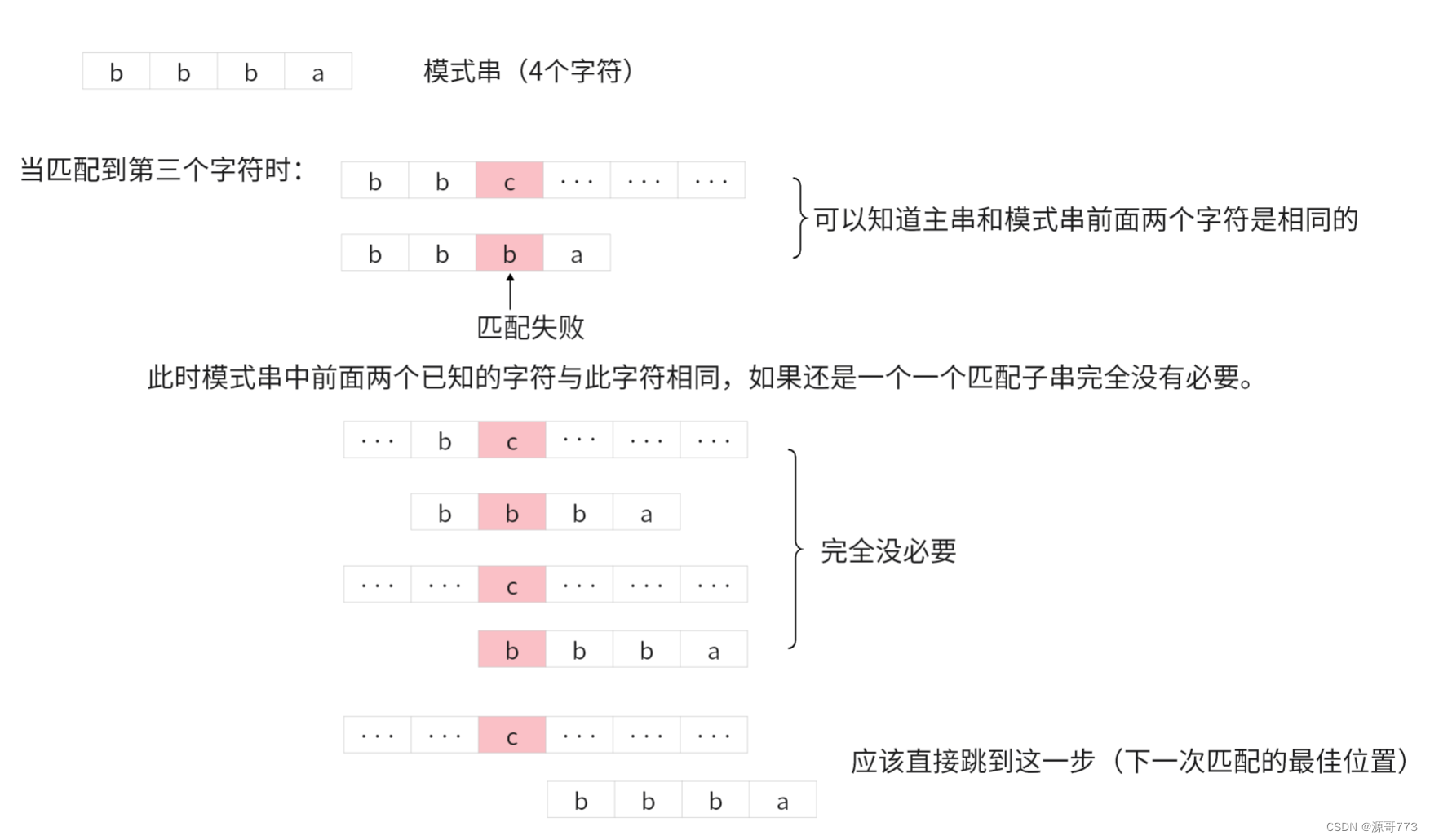
为此,我们可以知道有些没有意义的比较完全是没有那个必要的,那怎么才能够优化匹配呢?
这就是接下来要讲的KMP算法,它是由三个大聪明的首字母命名的。
首先,KMP算法的核心思想是当我们发现两个字符不匹配的时候,我们不再采用像朴素匹配算法那样进行回溯的机制,因为在我们遍历的过程中我们已经知道主串在错误位置之前前面的字符是什么了,所以我们不再移动主串,而是让模式串跳跃到一个最佳匹配位置再进行匹配。
那我们怎么才能跳跃到最佳匹配位置呢?这就跟next数组有关了。我们先来了解什么是next数组。(这里用的是严蔚敏版的,也就是模式串和子串从1开始计数,如果是其他版的next数组定义都不同,网上讲的鱼龙混杂的,害我摸索了好几天)
next[i] 表示模式串第 i 个字符发生不匹配,下一次从模式串的第几个字符开始匹配。
特殊情况:当 next[i] = 0 时从主串的下一字符开始和模式串比较。
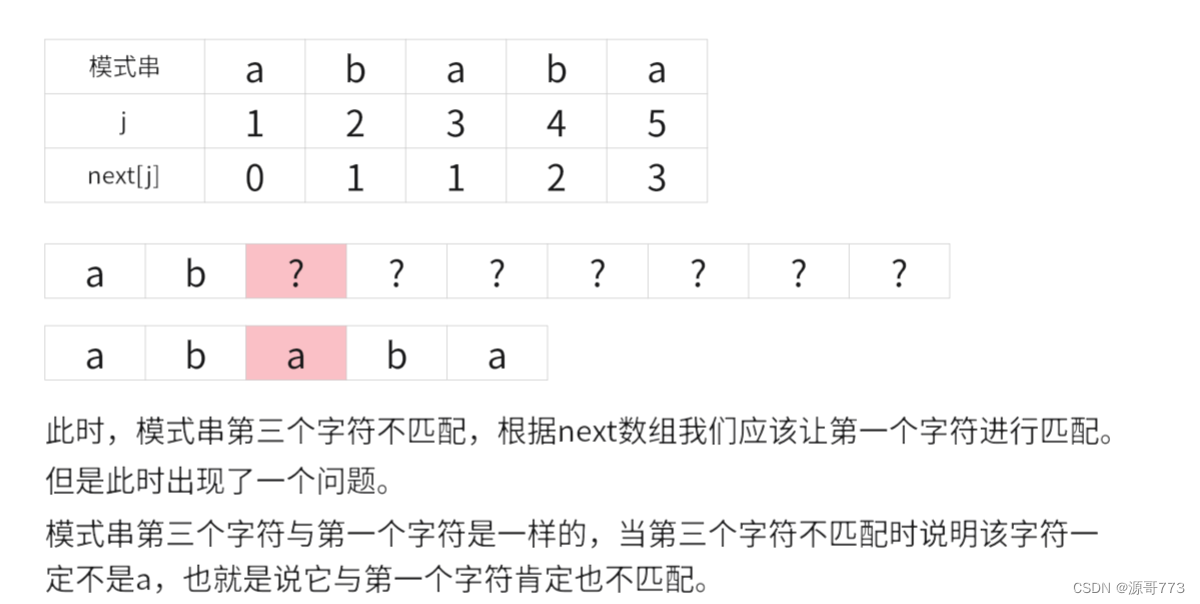
例如,假如说模式串是 ababa,

int kuaisupipei(Str str,Str substr,int next[])
{
int i,j = 1; //i是主串指针,j是模式串指针,这里都是从1开始存储
while(i<=str.length) //主串没有遍历完
{
if(str.str[i] == substr.str[j] || j==0) //如果模式串与子串匹配成功或者j指向0
{
i++; //进行下一位的匹配
j++;
}
else
{
j = next[j]; //模式串跳到相应位置
}
if(j > substr.length)//匹配完成
{
return i - substr.length; //返回下标
}
}
return 0; //找不到返回0
} 这里可能有些小伙伴不太理解为什么 j=0 时让 i 和 j 同时加1?
我用动态图解释一下:
另外,基于这种next数组我用同样的原理设计出了模式串和主串从0开始存储的代码,可能有些人不太好理解。(当作参考看一下就行了,反正也不考)
需要注意的是:我这里的next数组也是下标从0开始存储的。
就是说如果模式串下标为1开始存储的时候 next[1] = 0,next[2] = 1,·····
模式串下标为0存储的时候 next[0] = 0,next[1] = 1,·····这些是一一对应的。
int kuaisupipei(Str str,Str substr,int next[])
{
int i,j = 0; //i是主串指针,j是模式串指针,这里都是从下标0开始
while(i<str.length) //主串没有遍历完
{
if(str.str[i] == substr.str[j]|| j == -1)//如果模式串与子串匹配成功或j=-1
{
i++;
j++;
}
else
{
j = next[j] - 1 ; /*模式串跳到第 j 个字符进行比较,之所以-1是因为第 j 个
字符的下标为 j - 1 */
}
if(j == substr.length) //全部字符都匹配成功
{
return i - substr.length; //返回下标
}
}
return -1; //找不到返回-1
} 手工求next数组
可以看到next数组是很神奇的,每回都能跳到最佳的位置,但是我们怎么得到next数组的呢?
我看了一下教材的解释,可谓是看了也看不懂,这确实也是一个难点。但是考试的时候我们知道怎么把它算出来就行了。
我借鉴了王道的方法:

KMP算法的改进
kmp算法的next数组不是已经很高效了,但是怎么还有改进呢?

还是以 ababa 为例:
于是原本操作是这样的:

我们可以优化为:

直接省略掉中间毫无意义的一步。
而怎么实现这个过程呢?
第一步肯定还是要先求出next数组的,第二步就是用改进后的next数组(nextval数组)去替换我们原本的next数组。
这时候又怎么得到nextval数组呢?
我总结了一下:
nextval[1] = next[1] = 0。
之后从左到右依次求nextval数组:若 next[ j ]对应的那个字符(假如说是 i) = j 所对应的字符(第 j 个字符),nextval[ j ] = nextval[ next[ j ] ]。
可能不太好理解,直接上实战吧。

关于求next数组和nextval数组的代码,直接粘贴在下面,因为我自己也没怎么弄懂,有没有大佬能提供一下思路的,等我有机会摸索完之后再修改:
void getnext (Str substr,int next[])
{
int i = 1,j = 0; //i代表模式串指针
next[1] = 0;
while(i<substr.length)
{
if(j == 0 || substr.str[i] == substr.str[j])
{
i++;
j++;
next[i] = j;
}
else
{
j = next[j];
}
}
}void getnextval(Str substr,int nextval[])
{
int i = 1,j = 0;
nextval[1] = 0;
while(i<substr.length)
{
if(j==0 || substr.str[i] == substr.str[j])
{
i++;
j++;
if(substr.str[i] != substr.str[j])
nextval[i] = j;
else
nextval[i] = nextval[j]; //不同的就是这一步
}
else
{
j = nextval[j];
}
}
}这里很多内容第一次看都不会太懂的,建议还是去看一下王道的原视频吧:















 2702
2702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









