






一开始依然是对上次所学进行简单归纳,上一次我们了解到了链式结构以及单链表。它最大的特点就是跟线性表相比能够实现动态的增删查改,但是它的空间利用率会稍微低一点,因为它会多存储指向下一个节点地址的指针。另外我们在学习过程中也可以很容易的发现它的一个缺点,就是我们在访问一个单链表的节点时只能知道它以及它后面的节点,对于在它前面的节点一概不知,形象的比喻就是,我们往往对上周学习的内容还记得,但是对上上周学的可能就忘完了,而上周就是我们的遗忘节点。所以友情提醒一下,你还记得顺序表学了什么吗?

双链表的概念
为了解决单链表的缺陷,今天就先学习它的plus版——双链表。
你心里是不是嘀咕,我上回的链表还没学明白,怎么还来个plus版,听着名字好高级。但是呢,其实它提升的也就是在节点上多了个指针域指向上一个节点。
| 前驱节点prior | 数据域data | 后继节点next |
双链表的定义
你也可以理解成单行道变成了双行道,其他的没变。
typedef struct Dnode
{
int data;
struct Dnode *next,*prior; //prior指向上一个节点
}Dnode,*Dlinklist;定义好了依然要对其初始化
void initsize(DLinklist *L)
{
*L= (Dnode *)malloc(sizeof(Dnode));
(*L)->next = NULL; //与单链表一样头节点的下一节点指向空
(*L)->prior = NULL; //头节点没有前驱节点
}双链表的插入和删除
头插法插入

void insertbyhead(Dlinklist *L,int array[],int n)
{
Dnode *p = *L;
for(int i=0;i<n;i++)
{
Dnode *q = (Dnode *)malloc(sizeof(Dnode));
q->data = array[i];
q->next = p->next;
if(p->next!=NULL) //需要判断插入的后继节点是否为空
{
p->next->prior = q; //不为空前驱节点指向新插入节点
}
p->next = q;
q->prior = p; //插入节点的前驱节点指向头节点
}
}尾插法插入

可以看到与单链表的尾插法相比只是每一次插入多加了一个前驱节点。
void insertbytail(Dlinklist *L,int array[],int n)
{
Dnode *p = *L;
for(int i=0;i<n;i++)
{
Dnode *q = (Dnode *)malloc(sizeof(Dnode));
q->data = array[i];
p->next = q;
q->prior = p; //与单链表相比只是多了这一句
p = p->next;
}
p->next = NULL;
}按位序插入
跟单链表相比,插入的第一步仍然是先找到插入的位置,第二步就是实现插入的逻辑,插入逻辑如下图(在节点后插入):
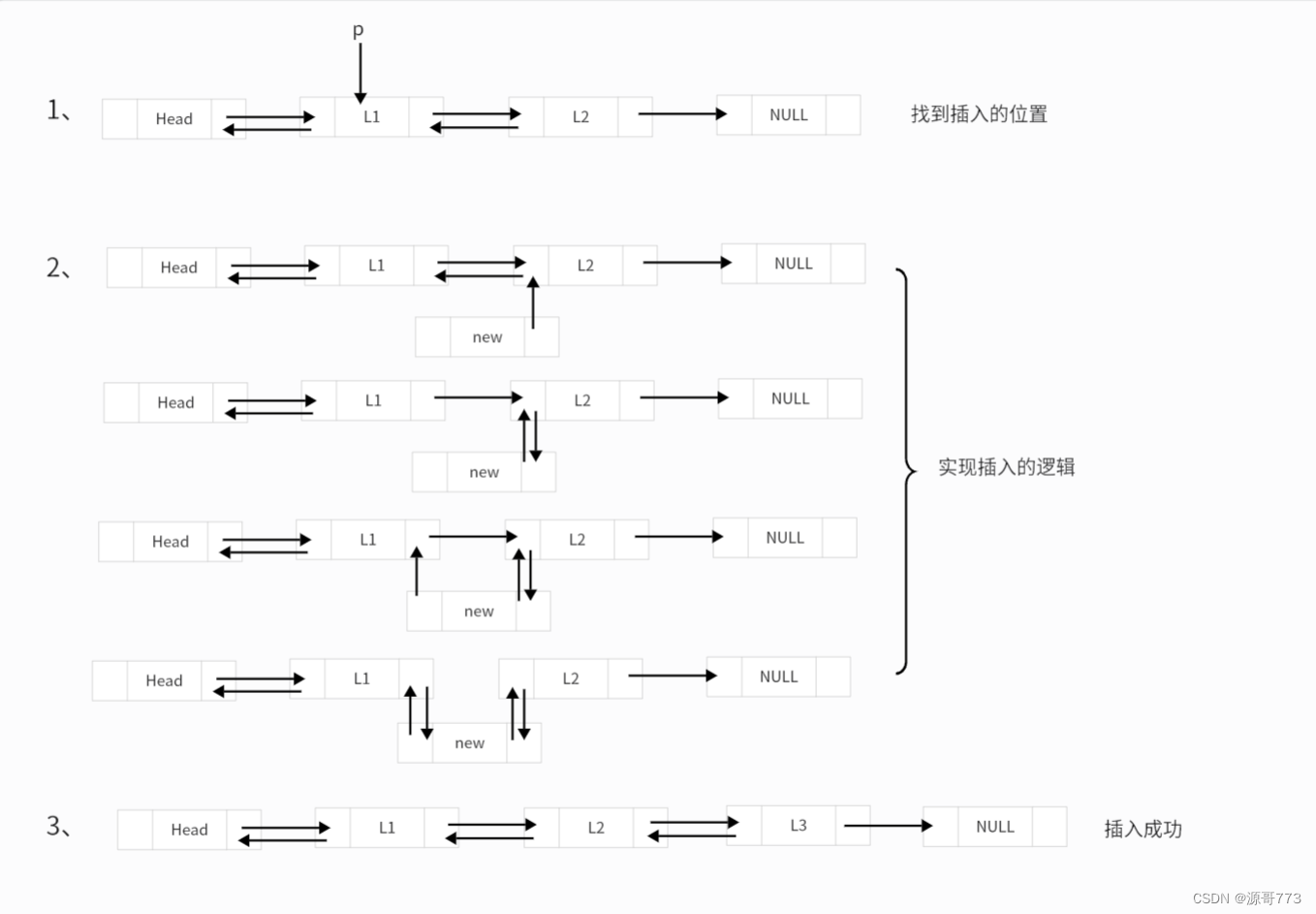
但是有一个问题就是如果插入节点是最后一个节点的时候,它的下一个节点是空,并不需要对空节点的前驱节点进行赋值。注:不一定非要按图上的插入逻辑来,因为双链表比较灵活,但是得注意插入过程中代码的顺序
bool insert(Dlinklist *L,int i,int e)
{
if(i<1)
{
return false;
}
Dnode *p = *L;//p指向头节点
while(i>1&&p!=NULL)
{
p=p->next;
i--;
}
if(p==NULL)
{
return false;
}
//实现插入逻辑
Dnode *q = (Dnode *)malloc(sizeof(Dnode)); //定义节点q为了实现插入操作
q->data = e;
q->next = p->next;
if(p->next!=NULL)
p->next->prior = q;
q->prior = p;
p->next = q;
return true;
}节点后插入
逻辑与按位序插入基本一致,不再过多赘述。
bool insertbynext(Dnode *p,int e)
{
if(p==NULL)
{
return false;
}
Dnode *q = (Dnode *)malloc(sizeof(Dnode));
q->data = e;
q->next = p->next;
if(p->next!=NULL) //如果插入位置不是最后一个节点
{
p->next->prior = q;
}
q->prior = p;
p->next = q;
return true;
}节点前插入
双链表不用再像单链表利用给节点赋值的方式来变向的实现前插操作,而是可以利用前驱节点轻松实现。
方法就是先用指针指向插入节点的上一个节点,然后对这个插入节点的上一个节点进行后插操作就OK了。
bool insertbyprior(Dnode *p,int e)//默认p节点不是头节点需要注意一下
{
if(p==NULL)
{
return false;
}
Dnode *q = p->prior;
insertbynext(q,e);
return true;
}删除节点
按位序删除其实跟单链表没有多少区别,依然是先找到删除节点的前一个节点。跟双链表插入一样要单独对是否是末尾节点进行判断。
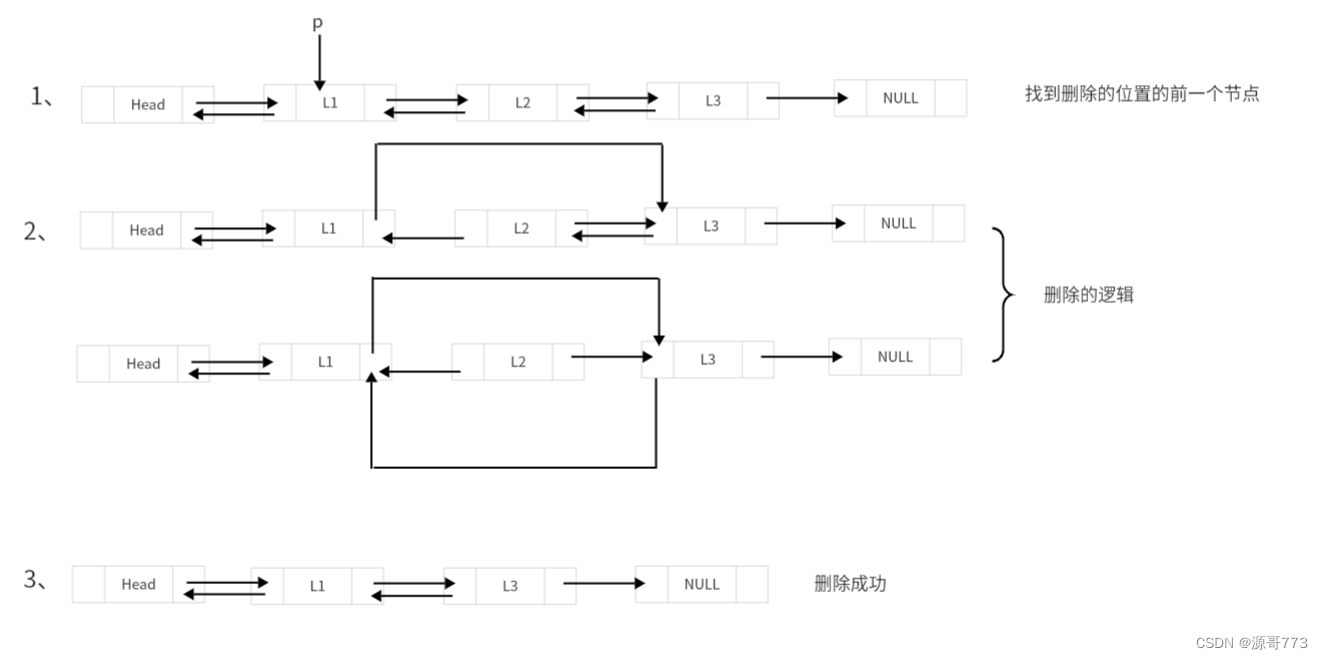
bool delete(Dlinklist *L,int i)
{
if(L==NULL||i<1)
{
return false;
}
Dnode *p=*L;
while(i>1&&p!=NULL)
{
p=p->next;
i--;
}
if(p==NULL)
{
return false;
}
Dnode *q = p->next; //q指向删除节点
if(q==NULL) //删除节点为空
{
return false;
}
p->next = q->next;
if(q->next!=NULL) //判断是否是末尾节点
{
q->next->prior = p;
}
free(q);
return true;
}指定节点删除因为可以指向前驱节点,所以只需要定义指向前一个节点的指针就可以像按位序删除一样删除节点了。
bool deletenode(Dnode *q) //删除q节点
{
if(q==NULL)
{
return false;
}
Dnode *p = q->prior; //找到前驱节点
if(p==NULL)
{
return false;
}
p->next = q->next;
if(q->next!=NULL)
{
q->next->prior = p;
}
return true;
} 双链表的查询
双链表的按值查找、按位序查找既可以向后遍历,也可以向前遍历。但是我感觉这种查找还是没啥用,因为依然还是要遍历才能查找,时间复杂度也是O(n),与单链表并没啥区别。代码过于简单就留给读者自己想了。
总而言之双链表与单链表没有太大的区别,只是多了一个指向前驱节点的指针,在插入删除时能够更加灵活,其他并没有太厉害的东西。
双链表完整代码:
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
typedef struct Dnode
{
int data;
struct Dnode *next,*prior;
}Dnode,*Dlinklist;
void initsize(Dlinklist *L)
{
*L=(Dnode *)malloc(sizeof(Dnode));
(*L)->next=NULL;
(*L)->prior=NULL;
}
void insertbyhead(Dlinklist *L,int array[],int n)
{
Dnode *p = *L;
for(int i=0;i<n;i++)
{
Dnode *q = (Dnode *)malloc(sizeof(Dnode));
q->data = array[i];
q->next = p->next;
if(p->next!=NULL) //需要判断插入的后继节点是否为空
{
p->next->prior = q; //不为空前驱节点指向新插入节点
}
p->next = q;
q->prior = p; //插入节点的前驱节点指向头节点
}
}
void insertbytail(Dlinklist *L,int array[],int n)
{
Dnode *p = *L;
for(int i=0;i<n;i++)
{
Dnode *q = (Dnode *)malloc(sizeof(Dnode));
q->data = array[i];
p->next = q;
q->prior = p; //与单链表相比只是多了这一句
p = p->next;
}
p->next = NULL;
}
bool insert(Dlinklist *L,int i,int e)
{
if(i<1)
{
return false;
}
Dnode *p = *L;//p指向头节点
while(i>1&&p!=NULL)
{
p=p->next;
i--;
}
if(p==NULL)
{
return false;
}
//实现插入逻辑
Dnode *q = (Dnode *)malloc(sizeof(Dnode)); //定义节点q为了实现插入操作
q->data = e;
q->next = p->next;
if(p->next!=NULL)
p->next->prior = q;
q->prior = p;
p->next = q;
return true;
}
bool insertbynext(Dnode *p,int e)
{
if(p==NULL)
{
return false;
}
Dnode *q = (Dnode *)malloc(sizeof(Dnode));
q->data = e;
q->next = p->next;
if(p->next!=NULL) //如果插入位置不是最后一个节点
{
p->next->prior = q;
}
q->prior = p;
p->next = q;
return true;
}
bool insertbyprior(Dnode *p,int e)//默认不用于头节点
{
if(p==NULL)
{
return false;
}
Dnode *q = p->prior;
insertbynext(q,e);
return true;
}
bool delete(Dlinklist *L,int i)
{
if(L==NULL||i<1)
{
return false;
}
Dnode *p=*L;
while(i>1&&p!=NULL)
{
p=p->next;
i--;
}
if(p==NULL)
{
return false;
}
Dnode *q = p->next; //q指向删除节点
if(q==NULL) //删除节点为空
{
return false;
}
p->next = q->next;
if(q->next!=NULL) //判断是否是末尾节点
{
q->next->prior = p;
}
free(q);
return true;
}
bool deletenode(Dnode *q) //删除q节点
{
if(q==NULL)
{
return false;
}
Dnode *p = q->prior; //找到前驱节点
if(p==NULL)
{
return false;
}
p->next = q->next;
if(q->next!=NULL)
{
q->next->prior = p;
}
return true;
}
void linkfree(Dlinklist *L)
{
Dnode *p;
while(*L!=NULL)
{
p=*L;
*L=(*L)->next;
printf("%d\n",(*L)->data);
free(p);
p=NULL;
}
}
int main()
{
Dlinklist L;
initsize(&L);
int array[5]={2,3,4,5,6};
insertbyhead(&L,array,5);
insert(&L,1,1);
deletenode(L->next);
linkfree(&L);
}循环链表的概念
循环链表就是链表的pro max版本了,其实也没多难,就是将对应的单链表或双链表的头节点和终端节点建立联系起来。
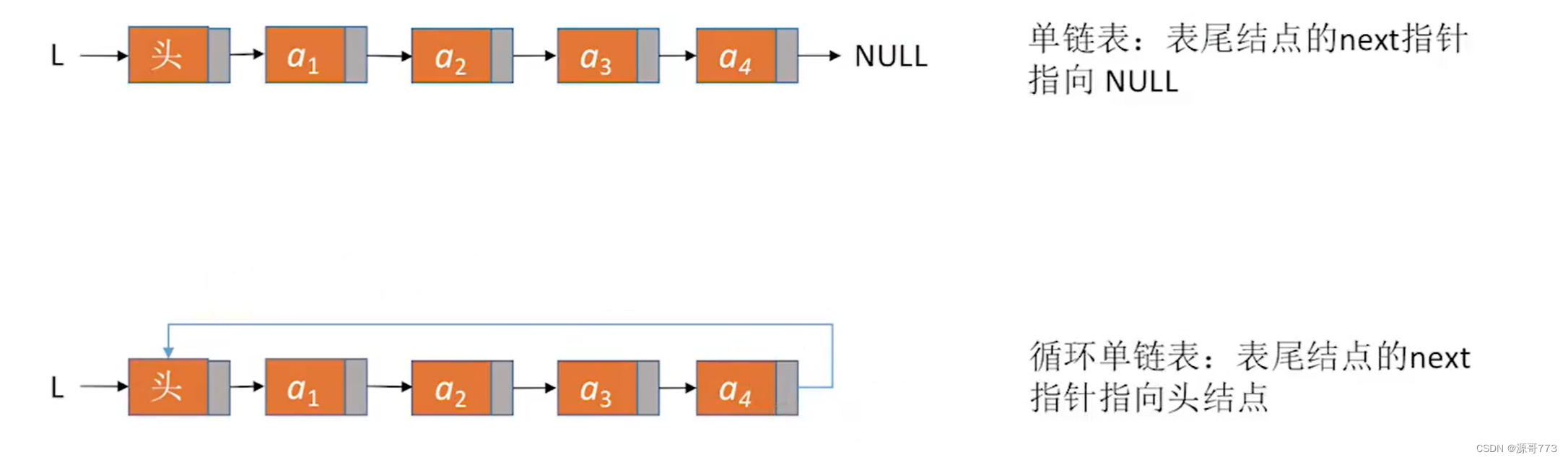
这里懒一下我就只讲解初始化时它与单链表的不同之处。
初始化时头节点的下一个指针指向头节点自己。
void initsize(Linklist *L)
{
*L = (Lnode *)malloc(sizeof(Lnode));
(*L)->next = L;
}其它增删查改跟单链表并没有区别,只是最后一个节点的下一个节点指向头节点。这只能带来一个好处:无论你从哪一个节点出发都可以遍历整个链表,而单链表只能从头节点出发才能遍历完整个链表。
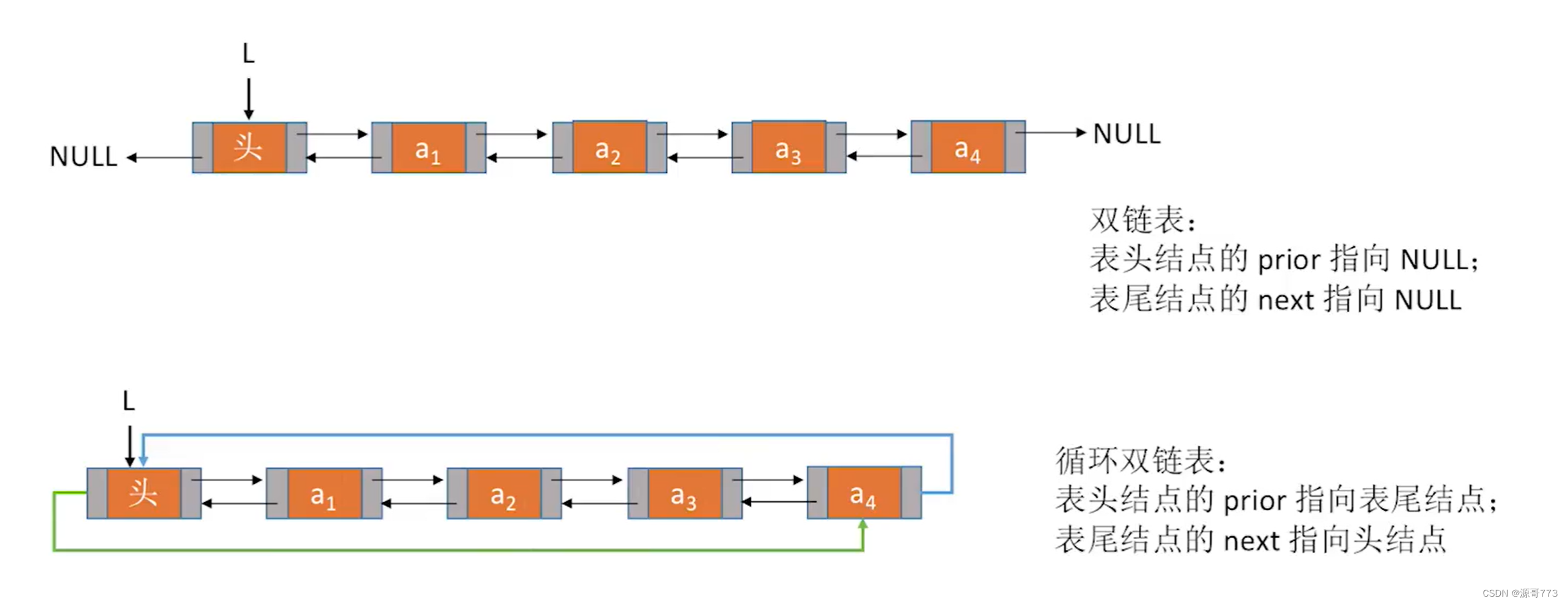
循环双链表也是类似,尾节点的下一节点指向头节点,头节点的上一节点指向尾节点。
void initsize(DLinklist *L)
{
*L= (Dnode *)malloc(sizeof(Dnode));
(*L)->next = L;
(*L)->prior = L;
}增删查改与双链表唯一的不同就是不用再判断插入或删除的后继节点是否为空。















 435
435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









