







项目要求
根据电商日志文件,分析:
- 统计页面浏览量(每行记录就是一次浏览)
- 统计各个省份的浏览量 (需要解析IP)
- 日志的ETL操作(ETL:数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程)
为什么要ETL:没有必要解析出所有数据,只需要解析出有价值的字段即可。本项目中需要解析出:ip、url、pageId(topicId对应的页面Id)、country、province、city
项目初始文件
已知文件
1. 纯真数据库 qqwry.dat
纯真数据库(QQWry.dat)是一种IP地址数据库文件,用于将IP地址转换为相应的地理位置信息。它由纯真网络开发,广泛用于中国地区的网络应用和服务。以下是关于纯真数据库的详细信息:
纯真数据库的主要功能
- IP地址解析:将一个IP地址解析为地理位置,包括国家、省份、城市等信息。
- 地理位置查询:通过IP地址查询,可以知道访问者的大致位置,便于统计和分析。
- 网络安全:在某些网络安全应用中,可以通过IP地址定位来分析潜在的威胁来源。
使用场景
- 网站分析:网站运营者可以通过解析访问者的IP地址,了解用户的地理分布情况,从而进行更精准的市场营销和内容分发。
- 个性化服务:根据用户的地理位置提供定制化的内容或服务,例如推荐本地新闻、天气预报等。
- 网络安全监控:通过分析IP地址来源,可以识别和阻止来自某些高风险地区的访问请求,提高网络安全性。
- 广告投放:广告商可以根据用户的地理位置,进行精准的广告投放,提高广告效果。
使用方法
已经提供工具类utils,可以直接调用方法,即可根据ip映射对应的国家、省份、城市
具体代码放后面
2. 工具类utils
提供四个工具类
GetPageId.java
调用getPageId方法,可从一个url中提取topicId
例如:“http://www.yihaodian.com/cms/view.do?topicId=14572”
返回结果为字符串类型:14572
没有topicId则返回空
package com.task.ds.utils;
import org.apache.commons.lang.StringUtils;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetPageId {
public static String getPageId(String url) {
String pageId = "";
if (StringUtils.isBlank(url)) {
return pageId;
}
Pattern pat = Pattern.compile("topicId=[0-9]+");
Matcher matcher = pat.matcher(url);
if (matcher.find()) {
pageId = matcher.group().split("topicId=")[1];
}
return pageId;
}
}
–
IPParser.java
提供解析ip,映射成对应的国家、省份、城市的方法: analyseIp(ip)
package com.task.ds.pro;
import com.task.ds.utils.IPParser;
import com.task.ds.utils.LogParser;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Map;
/**
* 省份浏览量统计
*/
public class ProvinceStatApp {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(configuration);
Path outputPath = new Path("E:\\IdeaProject\\hadoop\\project\\src\\main\\java\\com\\data\\trackInfo_out");
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath, true);
}
Job job = Job.getInstance(configuration);
job.setJarByClass(ProvinceStatApp.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path("E:\\IdeaProject\\hadoop\\project\\src\\main\\java\\com\\data\\trackinfo_20130721.txt"));
FileOutputFormat.setOutputPath(job, new Path("E:\\IdeaProject\\hadoop\\project\\src\\main\\java\\com\\data\\trackInfo_out"));
job.waitForCompletion(true);
}
static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private LongWritable ONE = new LongWritable(1);
private LogParser logParser;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
logParser = new LogParser();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String log = value.toString();
Map<String, String> info = logParser.parse(log);
String ip = info.get("ip");
if (StringUtils.isNotBlank(ip)) {
IPParser.RegionInfo regionInfo = IPParser.getInstance().analyseIp(ip);
if (regionInfo != null) {
String provine = regionInfo.getProvince();
if (StringUtils.isNotBlank(provine)) {
context.write(new Text(provine), ONE);
} else {
context.write(new Text("-"), ONE);
}
} else {
context.write(new Text("-"), ONE);
}
} else {
context.write(new Text("-"), ONE);
}
}
}
static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
System.out.println(context);
for (LongWritable value : values) {
count++;
}
context.write(key, new LongWritable(count));
}
}
}
–
IPSeeker.java
解析纯真数据库 qqwry.dat 源代码
代码太长,可暂时跳过
package com.task.ds.utils;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.io.UnsupportedEncodingException;
import java.nio.ByteOrder;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.util.ArrayList;
import java.util.Hashtable;
import java.util.List;
public class IPSeeker {
public static final String ERROR_RESULT = "错误的IP数据库文件";
// 一些固定常量,比如记录长度等等
private static final int IP_RECORD_LENGTH = 7;
private static final byte AREA_FOLLOWED = 0x01;
private static final byte NO_AREA = 0x2;
// 用来做为cache,查询一个ip时首先查看cache,以减少不必要的重复查找
private Hashtable ipCache;
// 随机文件访问类
private RandomAccessFile ipFile;
// 内存映射文件
private MappedByteBuffer mbb;
// 单一模式实例
private static IPSeeker instance = null;
// 起始地区的开始和结束的绝对偏移
private long ipBegin, ipEnd;
// 为提高效率而采用的临时变量
private IPLocation loc;
private byte[] buf;
private byte[] b4;
private byte[] b3;
/** */
/**
* 私有构造函数
*/
protected IPSeeker(String ipFilePath) {
ipCache = new Hashtable();
loc = new IPLocation();
buf = new byte[100];
b4 = new byte[4];
b3 = new byte[3];
try {
ipFile = new RandomAccessFile(ipFilePath, "r");
} catch (FileNotFoundException e) {
System.out.println("IP地址信息文件没有找到,IP显示功能将无法使用");
ipFile = null;
}
// 如果打开文件成功,读取文件头信息
if (ipFile != null) {
try {
ipBegin = readLong4(0);
ipEnd = readLong4(4);
if (ipBegin == -1 || ipEnd == -1) {
ipFile.close();
ipFile = null;
}
} catch (IOException e) {
System.out.println("IP地址信息文件格式有错误,IP显示功能将无法使用");
ipFile = null;
}
}
}
/** */
/**
* @return 单一实例
*/
public static IPSeeker getInstance(String ipFilePath) {
if (instance == null) {
instance = new IPSeeker(ipFilePath);
}
return instance;
}
/** */
/**
* 给定一个地点的不完全名字,得到一系列包含s子串的IP范围记录
*
* @param s
* 地点子串
* @return 包含IPEntry类型的List
*/
public List getIPEntriesDebug(String s) {
List ret = new ArrayList();
long endOffset = ipEnd + 4;
for (long offset = ipBegin + 4; offset <= endOffset; offset += IP_RECORD_LENGTH) {
// 读取结束IP偏移
long temp = readLong3(offset);
// 如果temp不等于-1,读取IP的地点信息
if (temp != -1) {
IPLocation loc = getIPLocation(temp);
// 判断是否这个地点里面包含了s子串,如果包含了,添加这个记录到List中,如果没有,继续
if (loc.country.indexOf(s) != -1 || loc.area.indexOf(s) != -1) {
IPEntry entry = new IPEntry();
entry.country = loc.country;
entry.area = loc.area;
// 得到起始IP
readIP(offset - 4, b4);
entry.beginIp = IPSeekerUtils.getIpStringFromBytes(b4);
// 得到结束IP
readIP(temp, b4);
entry.endIp = IPSeekerUtils.getIpStringFromBytes(b4);
// 添加该记录
ret.add(entry);
}
}
}
return ret;
}
/** */
/**
* 给定一个地点的不完全名字,得到一系列包含s子串的IP范围记录
*
* @param s
* 地点子串
* @return 包含IPEntry类型的List
*/
public List getIPEntries(String s) {
List ret = new ArrayList();
try {
// 映射IP信息文件到内存中
if (mbb == null) {
FileChannel fc = ipFile.getChannel();
mbb = fc.map(FileChannel.MapMode.READ_ONLY, 0, ipFile.length());
mbb.order(ByteOrder.LITTLE_ENDIAN);
}
int endOffset = (int) ipEnd;
for (int offset = (int) ipBegin + 4; offset <= endOffset; offset += IP_RECORD_LENGTH) {
int temp = readInt3(offset);
if (temp != -1) {
IPLocation loc = getIPLocation(temp);
// 判断是否这个地点里面包含了s子串,如果包含了,添加这个记录到List中,如果没有,继续
if (loc.country.indexOf(s) != -1 || loc.area.indexOf(s) != -1) {
IPEntry entry = new IPEntry();
entry.country = loc.country;
entry.area = loc.area;
// 得到起始IP
readIP(offset - 4, b4);
entry.beginIp = IPSeekerUtils.getIpStringFromBytes(b4);
// 得到结束IP
readIP(temp, b4);
entry.endIp = IPSeekerUtils.getIpStringFromBytes(b4);
// 添加该记录
ret.add(entry);
}
}
}
} catch (IOException e) {
System.out.println(e.getMessage());
}
return ret;
}
/** */
/**
* 从内存映射文件的offset位置开始的3个字节读取一个int
*
* @param offset
* @return
*/
private int readInt3(int offset) {
mbb.position(offset);
return mbb.getInt() & 0x00FFFFFF;
}
/** */
/**
* 从内存映射文件的当前位置开始的3个字节读取一个int
*
* @return
*/
private int readInt3() {
return mbb.getInt() & 0x00FFFFFF;
}
/** */
/**
* 根据IP得到国家名
*
* @param ip
* ip的字节数组形式
* @return 国家名字符串
*/
public String getCountry(byte[] ip) {
// 检查ip地址文件是否正常
if (ipFile == null)
return ERROR_RESULT;
// 保存ip,转换ip字节数组为字符串形式
String ipStr = IPSeekerUtils.getIpStringFromBytes(ip);
// 先检查cache中是否已经包含有这个ip的结果,没有再搜索文件
if (ipCache.containsKey(ipStr)) {
IPLocation loc = (IPLocation) ipCache.get(ipStr);
return loc.country;
} else {
IPLocation loc = getIPLocation(ip);
ipCache.put(ipStr, loc.getCopy());
return loc.country;
}
}
/** */
/**
* 根据IP得到国家名
*
* @param ip
* IP的字符串形式
* @return 国家名字符串
*/
public String getCountry(String ip) {
return getCountry(IPSeekerUtils.getIpByteArrayFromString(ip));
}
/** */
/**
* 根据IP得到地区名
*
* @param ip
* ip的字节数组形式
* @return 地区名字符串
*/
public String getArea(byte[] ip) {
// 检查ip地址文件是否正常
if (ipFile == null)
return ERROR_RESULT;
// 保存ip,转换ip字节数组为字符串形式
String ipStr = IPSeekerUtils.getIpStringFromBytes(ip);
// 先检查cache中是否已经包含有这个ip的结果,没有再搜索文件
if (ipCache.containsKey(ipStr)) {
IPLocation loc = (IPLocation) ipCache.get(ipStr);
return loc.area;
} else {
IPLocation loc = getIPLocation(ip);
ipCache.put(ipStr, loc.getCopy());
return loc.area;
}
}
/**
* 根据IP得到地区名
*
* @param ip
* IP的字符串形式
* @return 地区名字符串
*/
public String getArea(String ip) {
return getArea(IPSeekerUtils.getIpByteArrayFromString(ip));
}
/** */
/**
* 根据ip搜索ip信息文件,得到IPLocation结构,所搜索的ip参数从类成员ip中得到
*
* @param ip
* 要查询的IP
* @return IPLocation结构
*/
public IPLocation getIPLocation(byte[] ip) {
IPLocation info = null;
long offset = locateIP(ip);
if (offset != -1)
info = getIPLocation(offset);
if (info == null) {
info = new IPLocation();
info.country = "未知国家";
info.area = "未知地区";
}
return info;
}
/**
* 从offset位置读取4个字节为一个long,因为java为big-endian格式,所以没办法 用了这么一个函数来做转换
*
* @param offset
* @return 读取的long值,返回-1表示读取文件失败
*/
private long readLong4(long offset) {
long ret = 0;
try {
ipFile.seek(offset);
ret |= (ipFile.readByte() & 0xFF);
ret |= ((ipFile.readByte() << 8) & 0xFF00);
ret |= ((ipFile.readByte() << 16) & 0xFF0000);
ret |= ((ipFile.readByte() << 24) & 0xFF000000);
return ret;
} catch (IOException e) {
return -1;
}
}
/**
* 从offset位置读取3个字节为一个long,因为java为big-endian格式,所以没办法 用了这么一个函数来做转换
*
* @param offset
* @return 读取的long值,返回-1表示读取文件失败
*/
private long readLong3(long offset) {
long ret = 0;
try {
ipFile.seek(offset);
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/**
* 从当前位置读取3个字节转换成long
*
* @return
*/
private long readLong3() {
long ret = 0;
try {
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/**
* 从offset位置读取四个字节的ip地址放入ip数组中,读取后的ip为big-endian格式,但是
* 文件中是little-endian形式,将会进行转换
*
* @param offset
* @param ip
*/
private void readIP(long offset, byte[] ip) {
try {
ipFile.seek(offset);
ipFile.readFully(ip);
byte temp = ip[0];
ip[0] = ip[3];
ip[3] = temp;
temp = ip[1];
ip[1] = ip[2];
ip[2] = temp;
} catch (IOException e) {
System.out.println(e.getMessage());
}
}
/**
* 从offset位置读取四个字节的ip地址放入ip数组中,读取后的ip为big-endian格式,但是
* 文件中是little-endian形式,将会进行转换
*
* @param offset
* @param ip
*/
private void readIP(int offset, byte[] ip) {
mbb.position(offset);
mbb.get(ip);
byte temp = ip[0];
ip[0] = ip[3];
ip[3] = temp;
temp = ip[1];
ip[1] = ip[2];
ip[2] = temp;
}
/**
* 把类成员ip和beginIp比较,注意这个beginIp是big-endian的
*
* @param ip
* 要查询的IP
* @param beginIp
* 和被查询IP相比较的IP
* @return 相等返回0,ip大于beginIp则返回1,小于返回-1。
*/
private int compareIP(byte[] ip, byte[] beginIp) {
for (int i = 0; i < 4; i++) {
int r = compareByte(ip[i], beginIp[i]);
if (r != 0)
return r;
}
return 0;
}
/**
* 把两个byte当作无符号数进行比较
*
* @param b1
* @param b2
* @return 若b1大于b2则返回1,相等返回0,小于返回-1
*/
private int compareByte(byte b1, byte b2) {
if ((b1 & 0xFF) > (b2 & 0xFF)) // 比较是否大于
return 1;
else if ((b1 ^ b2) == 0)// 判断是否相等
return 0;
else
return -1;
}
/**
* 这个方法将根据ip的内容,定位到包含这个ip国家地区的记录处,返回一个绝对偏移 方法使用二分法查找。
*
* @param ip
* 要查询的IP
* @return 如果找到了,返回结束IP的偏移,如果没有找到,返回-1
*/
private long locateIP(byte[] ip) {
long m = 0;
int r;
// 比较第一个ip项
readIP(ipBegin, b4);
r = compareIP(ip, b4);
if (r == 0)
return ipBegin;
else if (r < 0)
return -1;
// 开始二分搜索
for (long i = ipBegin, j = ipEnd; i < j;) {
m = getMiddleOffset(i, j);
readIP(m, b4);
r = compareIP(ip, b4);
// log.debug(Utils.getIpStringFromBytes(b));
if (r > 0)
i = m;
else if (r < 0) {
if (m == j) {
j -= IP_RECORD_LENGTH;
m = j;
} else
j = m;
} else
return readLong3(m + 4);
}
// 如果循环结束了,那么i和j必定是相等的,这个记录为最可能的记录,但是并非
// 肯定就是,还要检查一下,如果是,就返回结束地址区的绝对偏移
m = readLong3(m + 4);
readIP(m, b4);
r = compareIP(ip, b4);
if (r <= 0)
return m;
else
return -1;
}
/**
* 得到begin偏移和end偏移中间位置记录的偏移
*
* @param begin
* @param end
* @return
*/
private long getMiddleOffset(long begin, long end) {
long records = (end - begin) / IP_RECORD_LENGTH;
records >>= 1;
if (records == 0)
records = 1;
return begin + records * IP_RECORD_LENGTH;
}
/**
* 给定一个ip国家地区记录的偏移,返回一个IPLocation结构
*
* @param offset
* @return
*/
private IPLocation getIPLocation(long offset) {
try {
// 跳过4字节ip
ipFile.seek(offset + 4);
// 读取第一个字节判断是否标志字节
byte b = ipFile.readByte();
if (b == AREA_FOLLOWED) {
// 读取国家偏移
long countryOffset = readLong3();
// 跳转至偏移处
ipFile.seek(countryOffset);
// 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向
b = ipFile.readByte();
if (b == NO_AREA) {
loc.country = readString(readLong3());
ipFile.seek(countryOffset + 4);
} else
loc.country = readString(countryOffset);
// 读取地区标志
loc.area = readArea(ipFile.getFilePointer());
} else if (b == NO_AREA) {
loc.country = readString(readLong3());
loc.area = readArea(offset + 8);
} else {
loc.country = readString(ipFile.getFilePointer() - 1);
loc.area = readArea(ipFile.getFilePointer());
}
return loc;
} catch (IOException e) {
return null;
}
}
/**
* @param offset
* @return
*/
private IPLocation getIPLocation(int offset) {
// 跳过4字节ip
mbb.position(offset + 4);
// 读取第一个字节判断是否标志字节
byte b = mbb.get();
if (b == AREA_FOLLOWED) {
// 读取国家偏移
int countryOffset = readInt3();
// 跳转至偏移处
mbb.position(countryOffset);
// 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向
b = mbb.get();
if (b == NO_AREA) {
loc.country = readString(readInt3());
mbb.position(countryOffset + 4);
} else
loc.country = readString(countryOffset);
// 读取地区标志
loc.area = readArea(mbb.position());
} else if (b == NO_AREA) {
loc.country = readString(readInt3());
loc.area = readArea(offset + 8);
} else {
loc.country = readString(mbb.position() - 1);
loc.area = readArea(mbb.position());
}
return loc;
}
/**
* 从offset偏移开始解析后面的字节,读出一个地区名
*
* @param offset
* @return 地区名字符串
* @throws IOException
*/
private String readArea(long offset) throws IOException {
ipFile.seek(offset);
byte b = ipFile.readByte();
if (b == 0x01 || b == 0x02) {
long areaOffset = readLong3(offset + 1);
if (areaOffset == 0)
return "未知地区";
else
return readString(areaOffset);
} else
return readString(offset);
}
/**
* @param offset
* @return
*/
private String readArea(int offset) {
mbb.position(offset);
byte b = mbb.get();
if (b == 0x01 || b == 0x02) {
int areaOffset = readInt3();
if (areaOffset == 0)
return "未知地区";
else
return readString(areaOffset);
} else
return readString(offset);
}
/**
* 从offset偏移处读取一个以0结束的字符串
*
* @param offset
* @return 读取的字符串,出错返回空字符串
*/
private String readString(long offset) {
try {
ipFile.seek(offset);
int i;
for (i = 0, buf[i] = ipFile.readByte(); buf[i] != 0; buf[++i] = ipFile.readByte())
;
if (i != 0)
return IPSeekerUtils.getString(buf, 0, i, "GBK");
} catch (IOException e) {
System.out.println(e.getMessage());
}
return "";
}
/**
* 从内存映射文件的offset位置得到一个0结尾字符串
*
* @param offset
* @return
*/
private String readString(int offset) {
try {
mbb.position(offset);
int i;
for (i = 0, buf[i] = mbb.get(); buf[i] != 0; buf[++i] = mbb.get())
;
if (i != 0)
return IPSeekerUtils.getString(buf, 0, i, "GBK");
} catch (IllegalArgumentException e) {
System.out.println(e.getMessage());
}
return "";
}
public String getAddress(String ip) {
String country = getCountry(ip).equals(" CZ88.NET") ? "" : getCountry(ip);
String area = getArea(ip).equals(" CZ88.NET") ? "" : getArea(ip);
String address = country + " " + area;
return address.trim();
}
/**
* * 用来封装ip相关信息,目前只有两个字段,ip所在的国家和地区
*
*
* @author swallow
*/
public class IPLocation {
public String country;
public String area;
public IPLocation() {
country = area = "";
}
public IPLocation getCopy() {
IPLocation ret = new IPLocation();
ret.country = country;
ret.area = area;
return ret;
}
}
/**
* 一条IP范围记录,不仅包括国家和区域,也包括起始IP和结束IP *
*
*
* @author gerry liu
*/
public class IPEntry {
public String beginIp;
public String endIp;
public String country;
public String area;
public IPEntry() {
beginIp = endIp = country = area = "";
}
public String toString() {
return this.area + " " + this.country + "IP Χ:" + this.beginIp + "-" + this.endIp;
}
}
/**
* 操作工具类
*
* @author gerryliu
*
*/
public static class IPSeekerUtils {
/**
* 从ip的字符串形式得到字节数组形式
*
* @param ip
* 字符串形式的ip
* @return 字节数组形式的ip
*/
public static byte[] getIpByteArrayFromString(String ip) {
byte[] ret = new byte[4];
java.util.StringTokenizer st = new java.util.StringTokenizer(ip, ".");
try {
ret[0] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF);
ret[1] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF);
ret[2] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF);
ret[3] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF);
} catch (Exception e) {
System.out.println(e.getMessage());
}
return ret;
}
/**
* 对原始字符串进行编码转换,如果失败,返回原始的字符串
*
* @param s
* 原始字符串
* @param srcEncoding
* 源编码方式
* @param destEncoding
* 目标编码方式
* @return 转换编码后的字符串,失败返回原始字符串
*/
public static String getString(String s, String srcEncoding, String destEncoding) {
try {
return new String(s.getBytes(srcEncoding), destEncoding);
} catch (UnsupportedEncodingException e) {
return s;
}
}
/**
* 根据某种编码方式将字节数组转换成字符串
*
* @param b
* 字节数组
* @param encoding
* 编码方式
* @return 如果encoding不支持,返回一个缺省编码的字符串
*/
public static String getString(byte[] b, String encoding) {
try {
return new String(b, encoding);
} catch (UnsupportedEncodingException e) {
return new String(b);
}
}
/**
* 根据某种编码方式将字节数组转换成字符串
*
* @param b
* 字节数组
* @param offset
* 要转换的起始位置
* @param len
* 要转换的长度
* @param encoding
* 编码方式
* @return 如果encoding不支持,返回一个缺省编码的字符串
*/
public static String getString(byte[] b, int offset, int len, String encoding) {
try {
return new String(b, offset, len, encoding);
} catch (UnsupportedEncodingException e) {
return new String(b, offset, len);
}
}
/**
* @param ip
* ip的字节数组形式
* @return 字符串形式的ip
*/
public static String getIpStringFromBytes(byte[] ip) {
StringBuffer sb = new StringBuffer();
sb.append(ip[0] & 0xFF);
sb.append('.');
sb.append(ip[1] & 0xFF);
sb.append('.');
sb.append(ip[2] & 0xFF);
sb.append('.');
sb.append(ip[3] & 0xFF);
return sb.toString();
}
}
/**
* 获取全部ip地址集合列表
*
* @return
*/
public List<String> getAllIp() {
List<String> list = new ArrayList<String>();
byte[] buf = new byte[4];
for (long i = ipBegin; i < ipEnd; i += IP_RECORD_LENGTH) {
try {
this.readIP(this.readLong3(i + 4), buf); // 读取ip,最终ip放到buf中
String ip = IPSeekerUtils.getIpStringFromBytes(buf);
list.add(ip);
} catch (Exception e) {
// nothing
}
}
return list;
}
}
–
LogParser.java
日志文件解析
给定日志文件,根据“\001”分隔符切割后返回关键字段
package com.task.ds.utils;
import org.apache.commons.lang.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.HashMap;
import java.util.Map;
public class LogParser {
private Logger logger = LoggerFactory.getLogger(LogParser.class);
public Map<String, String> parse(String log) {
Map<String, String> logInfo = new HashMap<String,String>();
IPParser ipParse = IPParser.getInstance();
if(StringUtils.isNotBlank(log)) {
String[] splits = log.split("\001");
String ip = splits[13];
String url = splits[1];
String sessionId = splits[10];
String time = splits[17];
logInfo.put("ip",ip);
logInfo.put("url",url);
logInfo.put("sessionId",sessionId);
logInfo.put("time",time);
IPParser.RegionInfo regionInfo = ipParse.analyseIp(ip);
logInfo.put("country",regionInfo.getCountry());
logInfo.put("province",regionInfo.getProvince());
logInfo.put("city",regionInfo.getCity());
} else{
logger.error("日志记录的格式不正确:" + log);
}
return logInfo;
}
}
使用mapreduce编程
运行环境搭建
- maven配置
- hadoop下载,并配置环境变量
- 导入依赖,pom.xml
<!-- 添加hadoop的依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.1</version>
</dependency>
- idea创建maven项目
编写代码
ProvinceStatApp.java
省流量统计
package com.task.ds.pro;
import com.task.ds.utils.IPParser;
import com.task.ds.utils.LogParser;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Map;
/**
* 省份浏览量统计
*/
public class ProvinceStatApp {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(configuration);
Path outputPath = new Path("E:\\IdeaProject\\hadoop\\project\\src\\main\\java\\com\\data\\trackInfo_out");
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath, true);
}
Job job = Job.getInstance(configuration);
job.setJarByClass(ProvinceStatApp.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path("E:\\IdeaProject\\hadoop\\project\\src\\main\\java\\com\\data\\trackinfo_20130721.txt"));
FileOutputFormat.setOutputPath(job, new Path("E:\\IdeaProject\\hadoop\\project\\src\\main\\java\\com\\data\\trackInfo_out"));
job.waitForCompletion(true);
}
static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private LongWritable ONE = new LongWritable(1);
private LogParser logParser;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
logParser = new LogParser();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String log = value.toString();
Map<String, String> info = logParser.parse(log);
String ip = info.get("ip");
if (StringUtils.isNotBlank(ip)) {
IPParser.RegionInfo regionInfo = IPParser.getInstance().analyseIp(ip);
if (regionInfo != null) {
String provine = regionInfo.getProvince();
if (StringUtils.isNotBlank(provine)) {
context.write(new Text(provine), ONE);
} else {
context.write(new Text("-"), ONE);
}
} else {
context.write(new Text("-"), ONE);
}
} else {
context.write(new Text("-"), ONE);
}
}
}
static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
System.out.println(context);
for (LongWritable value : values) {
count++;
}
context.write(key, new LongWritable(count));
}
}
}
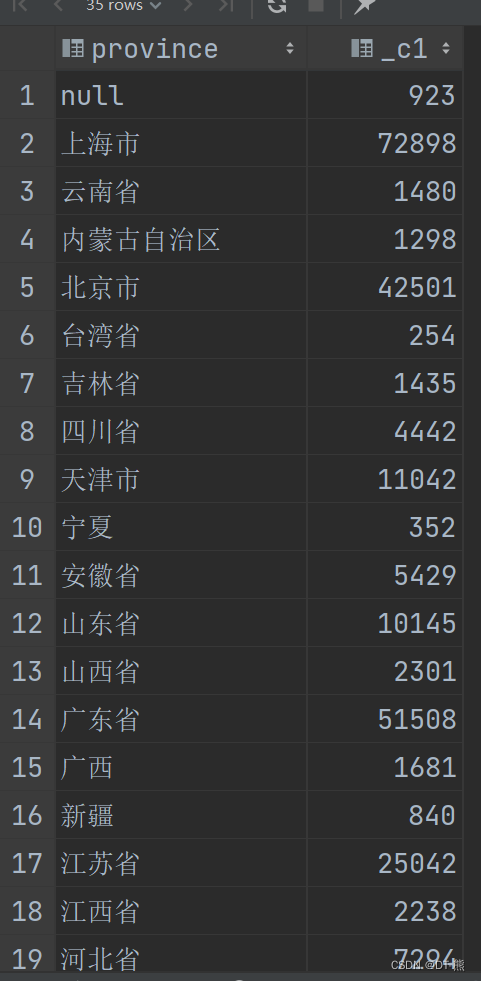
结果展示
- 923
上海市 72898
云南省 1480
内蒙古自治区 1298
北京市 42501
台湾省 254
吉林省 1435
四川省 4442
天津市 11042
宁夏 352
安徽省 5429
山东省 10145
山西省 2301
广东省 51508
广西 1681
新疆 840
江苏省 25042
江西省 2238
河北省 7294
河南省 5279
浙江省 20627
海南省 814
湖北省 7187
湖南省 2858
澳门特别行政区 6
甘肃省 1039
福建省 8918
西藏 110
贵州省 1084
辽宁省 2341
重庆市 1798
陕西省 2487
青海省 336
香港特别行政区 45
黑龙江省 1968
etl.java
提取关键信息:ip、url、pageId(topicId对应的页面Id)、country、province、city
package com.task.ds.pro;
import com.task.ds.utils.IPParser;
import com.task.ds.utils.LogParser;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Map;
/**
* etl提取关键信息
*/
public class etl {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(configuration);
Path outputPath = new Path("E:\\IdeaProject\\hadoop\\project\\src\\main\\java\\com\\data\\trackInfo_out");
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath, true);
}
Job job = Job.getInstance(configuration);
job.setJarByClass(ProvinceStatApp.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("E:\\IdeaProject\\hadoop\\project\\src\\main\\java\\com\\data\\trackinfo_20130721.txt"));
FileOutputFormat.setOutputPath(job, new Path("E:\\IdeaProject\\hadoop\\project\\src\\main\\java\\com\\data\\outInfo_out"));
job.waitForCompletion(true);
}
static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
private LongWritable ONE = new LongWritable(1);
private LogParser logParser;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
logParser = new LogParser();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String log = value.toString();
ContentUtils contentUtils = new ContentUtils();
Map<String, String> info = logParser.parse(log);
String ip = info.get("ip");
String url = info.get("url");
String pageId = contentUtils.getPageId(url);
String country = info.get("country");
String province = info.get("province");
String city = info.get("city");
String time = info.get("time");
String out = "," + pageId + "," + ip + "," + country + "," + province + "," + city + "," + time;
context.write(new Text(url) , new Text(out));
}
}
static class MyReduce extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(key,value);
}
}
}
}
结果展示
http://b2b.yihaodian.com/cms/view.do?topicId=21407 ,21407,115.85.250.26,中国,甘肃省,兰州市,2013-07-21 19:25:27
http://b2b.yihaodian.com/cms/view.do?topicId=23542&tracker_u=1010825072 ,23542,101.227.253.115,中国,上海市,null,2013-07-21 05:30:27
http://b2b.yihaodian.com/cms/view.do?topicId=23704&ref=ad.12084_2108676_1 ,23704,180.155.238.184,中国,上海市,null,2013-07-21 09:12:56
http://b2b.yihaodian.com/cms/view.do?topicId=23705&ref=ad.7901_2115482_1 ,23705,119.85.21.23,中国,重庆市,null,2013-07-21 17:25:49
http://b2b.yihaodian.com/customerMessage.do ,,222.69.22.126,中国,上海市,南汇区,2013-07-21 18:59:50
http://b2b.yihaodian.com/index.do ,,222.177.67.13,中国,重庆市,null,2013-07-21 17:50:08
–
原理解析
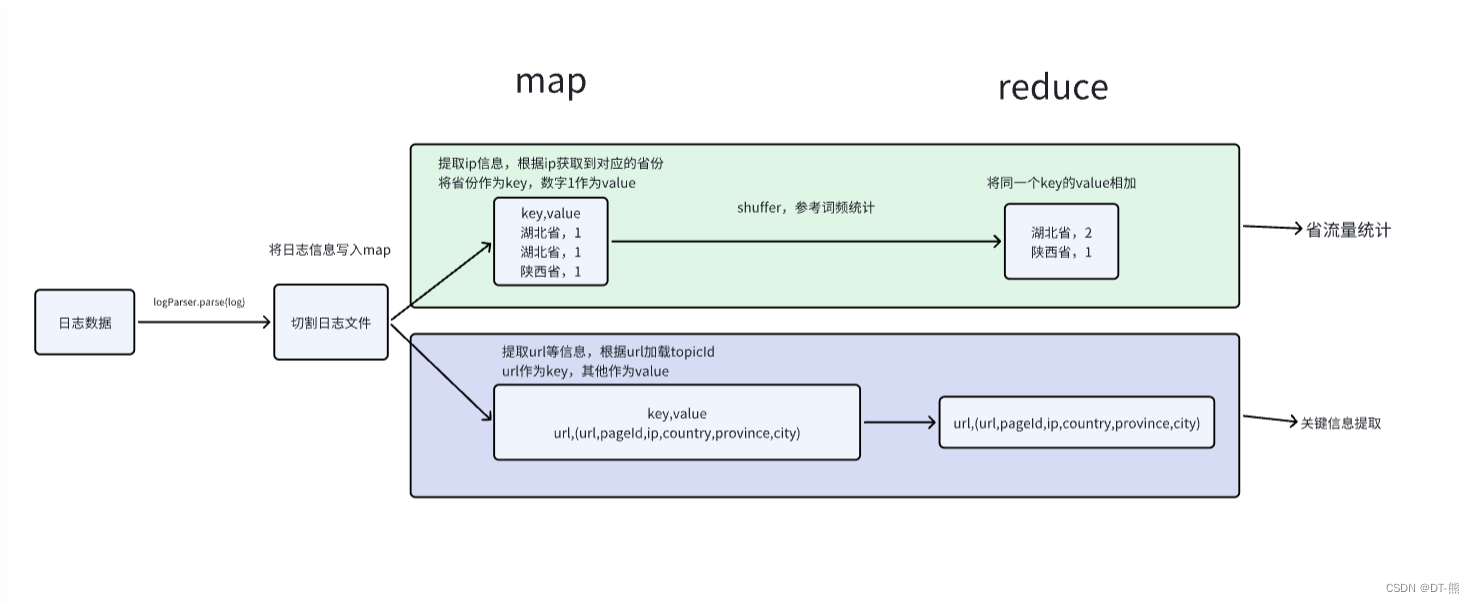
省流量统计
- 输入:一个包含日志信息的文本文件,其中每条记录包含一个IP地址。
- Mapper阶段:解析每条日志记录,提取IP地址,并通过IP地址获取对应的省份信息,然后输出键值对(省份,1)。
- Reducer阶段:接收Mapper输出的键值对,统计每个省份的访问次数,然后输出结果。
整个过程实现了从日志文件中提取IP地址,转换为地理位置,并统计每个省份的访问次数。
关键信息提取
- Mapper阶段
- 输入:读取日志文件中的每一行记录,通常每行包含一次访问的详细信息。
- LogParser:初始化日志解析器,用于解析每行日志记录,将其转换为一个包含多个字段的键值对映射。
- 解析与处理:
从解析后的日志信息中提取IP地址、URL、国家、省份、城市和访问时间。
通过URL获取页面ID。
将这些提取的关键信息拼接成一个逗号分隔的字符串。 - 输出:将URL作为键(key),拼接后的关键信息字符串作为值(value)输出。这意味着每个URL会对应一组相关的访问信息。
- Reducer阶段
- 输入:接收Mapper输出的键值对,键是URL,值是对应的关键信息字符串。
- 处理:对于每个URL,将所有相关的关键信息逐个输出,没有进行复杂的合并或统计操作。
- 输出:将URL和对应的关键信息字符串输出到最终结果文件中。
使用hive编程
搭建hive环境
- hive的下载、安装、配置
- 启动:hive是建立在hdfs之上的,先启动hdfs,再启动hive
- 进入hive客户端,或者访问web界面,端口10002
- 运行sql并测试
编写代码
使用 hive 只需编写sql
创建三张表
- 日志信息表:日志的原始字段
- ip映射表:一个ip对应的国家、省份、城市
- 结果表:关联上面两张表,映射最终结果
show databases ;
use test;
-- 创建日志信息表
describe trackinfo;
drop table if exists trackinfo;
create table trackInfo(
id string,
url string,
sessionId string,
ip string,
`time` string
)row format delimited fields terminated by ',';
load data local inpath "/root/SX_data/trackInfo.txt" overwrite into table trackinfo;
-- 创建ip映射信息表
drop table if exists ipInfo;
create table ipInfo(
ip string,
country string,
province string,
city string
)row format delimited fields terminated by ',';
load data local inpath "/root/SX_data/ipInfo.txt" overwrite into table ipInfo;
-- 创建结果信息表
truncate table track_log;
create table track_log(
url string,
pageId string,
ip string,
country string,
province string,
city string
)row format delimited fields terminated by ',';
insert into track_log
select
url,
regexp_extract(url,'topicId=(\\d{5})') as pageId,
t.ip,
i.country,
i.province,
i.city
from trackinfo t
left join ipinfo i
on t.ip = i.ip
;
-- 查询省份浏览量
select
province,
count(*)
from track_log
group by province;
select
url,
regexp_extract(url,'topicId=(\\d{5})') as pageId
from trackinfo t
where id = '20960991758'
;
select regexp_extract("http://www.yihaodian.com/cms/view.do?topicId=18970dgf",'topicId=(\\d{5})')
结果展示

















 8009
8009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









