






本文已同步更新于博主个人博客:blog.buzzchat.top
一、目标分析
目标网站:8684郑州地铁线路图 (郑州地铁线路图新版 - 郑州地铁图 - 郑州地铁线路)
- 爬取内容:
- 所有地铁线路的名称
- 每条线路的站点信息
- 数据存储:将爬取到的数据存储到 CSV 文件中,方便后续查看和分析。
二、项目准备
必要的 Python 库:
requests: 用于发送 HTTP 请求,获取网页内容。lxml: 用于解析 HTML 文档,提取所需信息。csv: 用于处理 CSV 文件,将数据写入文件。
2.1 第三方库介绍:
2.1.1 requests 库:
💡 作用:
requests是一个简洁且易于使用的 HTTP 库,用于发送 HTTP 请求,例如 GET 和 POST 请求,并处理服务器的响应。💡 优点:
- 简洁易用:
requests的 API 设计简洁明了,易于理解和使用。- 功能强大:
requests支持各种 HTTP 方法,包括 GET、POST、PUT、DELETE 等,以及各种身份验证、代理、Cookie 处理等功能。- 速度快:
requests底层使用 urllib3,具有高效的 HTTP 连接池和连接复用机制,能够快速处理大量请求。💡 选择理由: 在爬虫项目中,
requests是获取网页内容的首选库,因为它能够高效、可靠地处理 HTTP 请求和响应。
2.1.2 lxml 库:
💡 作用:
lxml是一个高效的 XML 和 HTML 处理库,支持 XPath 和 CSS 选择器,用于解析 HTML 文档,定位和提取所需信息。💡 优点:
- 高效快速:
lxml基于 C 库 libxml2 和 libxslt,解析速度非常快,尤其是在处理大型 HTML 文档时。- 功能强大:
lxml支持 XPath 1.0、XSLT 1.0、DTD 验证、 RelaxNG 验证等功能,能够处理复杂的 HTML 结构。- 易于使用:
lxml提供了简洁的 API,方便使用 XPath 和 CSS 选择器定位和提取 HTML 元素。💡 选择理由:
lxml是解析 HTML 文档的理想选择,因为它能够快速、准确地定位和提取所需信息,并且支持 XPath,方便处理复杂的 HTML 结构。
2.1.3 csv 库:
💡 作用:
csv是 Python 内置的 CSV 文件处理库,用于读取和写入 CSV 文件。💡 优点:
- 简单易用:
csv库提供了简洁的 API,方便读取和写入 CSV 文件。- 支持多种格式:
csv库支持多种 CSV 格式,包括标准 CSV、Excel CSV 等。💡 选择理由:
csv库是处理 CSV 文件的标准库,能够方便地将爬取到的数据存储到 CSV 文件中,方便后续查看和分析。
三、XPath 结构分析与爬取逻辑
3.1 XPath 结构分析:
首先,我们需要分析目标网站的 HTML 结构,找到包含线路和站点信息的元素,并确定其 XPath 表达式。
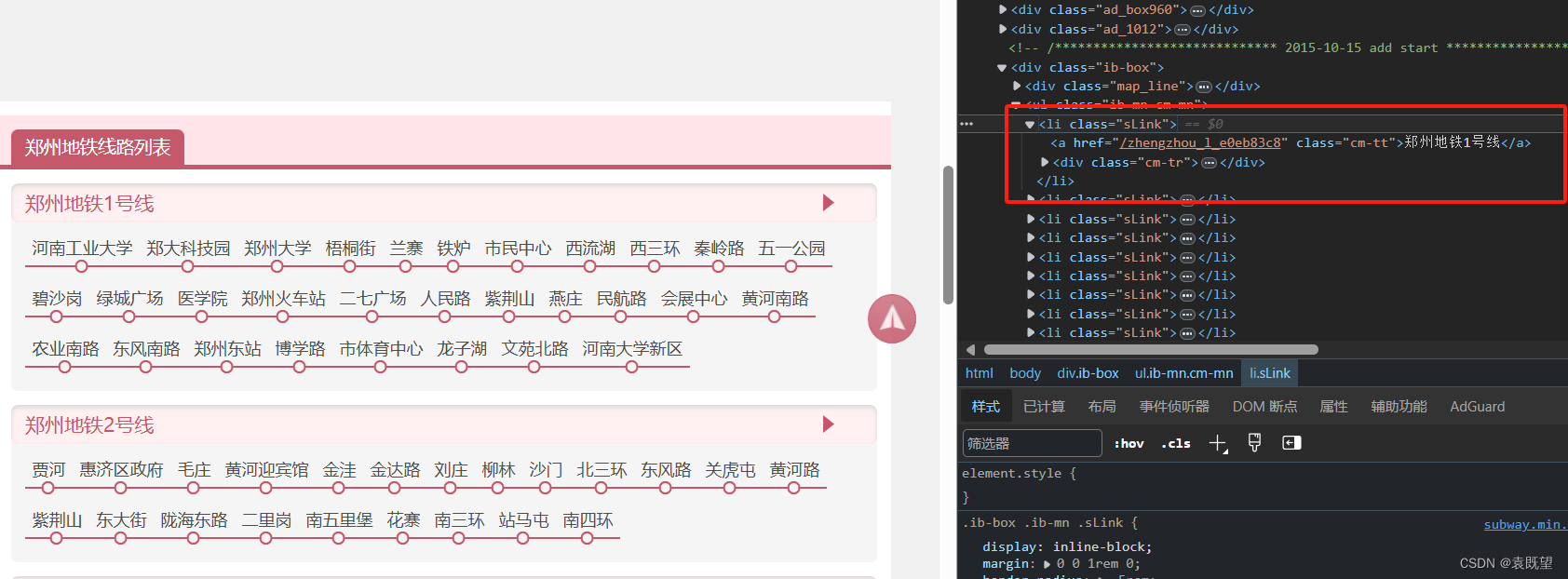
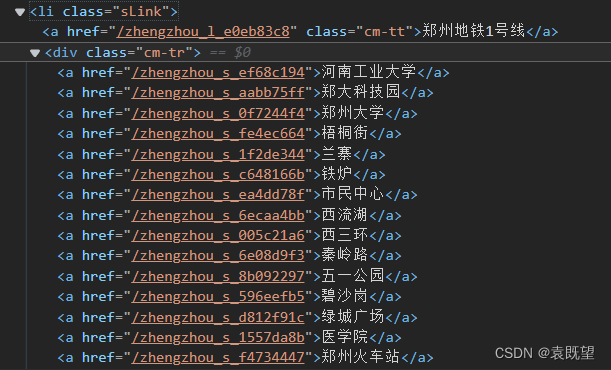
💡 通过观察郑州地铁官网的 HTML 源代码,我们可以发现:
- 所有地铁线路信息包含在
<div class="line-box">元素中。- 每条线路对应一个
<li class="sLink">元素。- 线路名称包含在
<li>元素下的<a>元素的文本内容中。- 线路下的站点信息包含在
<div class="cm-tr">元素下的多个<a>元素的文本内容中。
3.2 爬取逻辑:
1️⃣ 发送 HTTP 请求: 使用
requests库向目标网站发送 GET 请求,获取网页的 HTML 内容。2️⃣ 解析 HTML 结构: 使用
lxml库将 HTML 内容解析为 HTML 文档,方便使用 XPath 定位元素。3️⃣ 提取线路信息:
- 使用 XPath
//li[@class="sLink"]定位所有线路的<li>元素。- 对于每个
<li>元素:
- 使用 XPath
./a/text()提取线路名称。- 使用 XPath
./div[@class="cm-tr"]/a/text()提取该线路下所有站点的名称列表。4️⃣ 数据整合:
- 将站点名称列表转换为字符串,使用 "," 连接各个站点。
5️⃣ 写入 CSV 文件:
- 创建名为
ZhengZhouSubwayInfo.csv的 CSV 文件。- 写入列名 "线路" 和 "站点"。
- 将线路名称和站点信息逐行写入文件。
四、代码实现及运行结果
import requests # 导入 requests 库,用于发送 HTTP 请求
from lxml import etree # 导入 lxml 库,用于解析 HTML
import csv # 导入 csv 库,用于处理 CSV 文件
# 设置目标 URL
url = '<https://m.8684.cn/zhengzhou_dt_map>'
# 发送 GET 请求获取网页内容
response = requests.get(url)
response.encoding = 'utf-8' # 设置网页编码为 utf-8
# 使用 lxml 解析 HTML
html = etree.HTML(response.text)
# 使用 XPath 找到所有线路的 <li> 元素
lines = html.xpath('//li[@class="sLink"]')
# 指定 CSV 文件地址
csv_file = 'D:/Program/python Program/pachong/venv/ZhengZhouSubway.csv'
# 打开 CSV 文件,使用 'w' 模式写入,清空文件并重新写入数据
with open(csv_file, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile) # 创建 CSV 写入器
# 写入列名
writer.writerow(['线路', '站点'])
# 遍历每个线路
for line in lines:
# 使用 XPath 提取线路名称,并去除空格
line_name = line.xpath('./a/text()')[0].strip()
# 使用 XPath 提取站点列表
stations = line.xpath('./div[@class="cm-tr"]/a/text()')
# 将站点列表转换为字符串,并用","连接
station_str = ",".join(stations)
# 将线路名称和站点字符串写入 CSV 文件
writer.writerow([line_name, station_str])
print(f"{line_name}线路信息已爬取完毕!") # 打印提示信息
print(f"郑州地铁站点信息已写入 {csv_file} 文件中。") # 打印提示信息
运行结果:
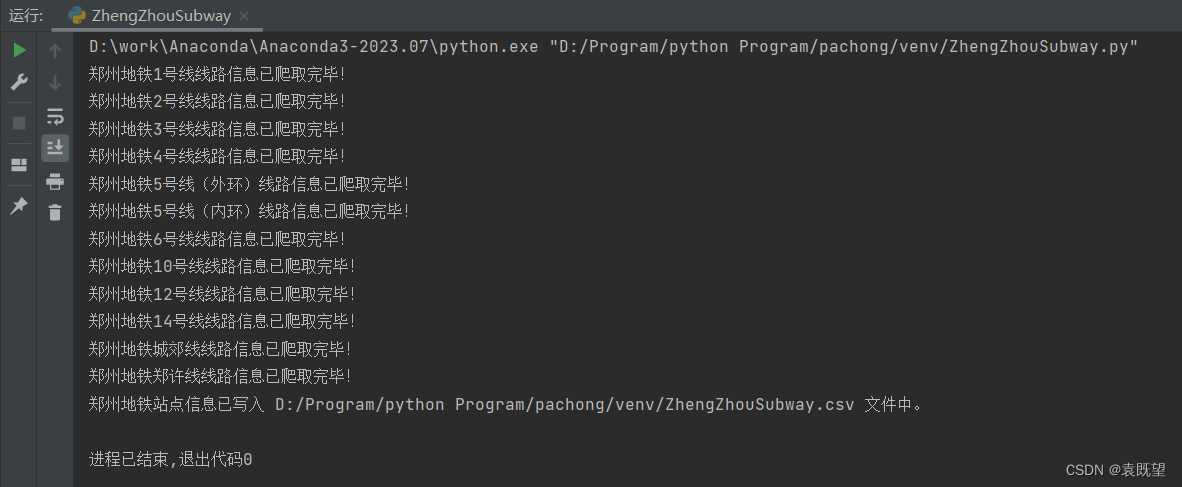
💡 添加打印提示信息,方便用户了解程序运行状态。
五、项目延伸(多层级爬取)
假设郑州地铁官网的每个线路页面都有更详细的信息,例如首末班车时间、票价等。我们可以利用多层级爬取获取这些数据:
- 获取线路链接: 在提取线路名称的同时,获取每个线路页面的链接,通常包含在
<a>元素的href属性中。 - 循环访问线路页面: 遍历线路链接,发送 HTTP 请求获取每个线路页面的内容。
- 解析线路页面: 使用 XPath 定位并提取所需信息,例如首末班车时间、票价等。
- 数据整合与存储: 将所有信息整合到一个数据结构中,例如字典或列表,并存储到 CSV 文件或数据库中。
多层级爬取代码示例:
# ... (前面的代码)
for line in lines:
# ... (提取线路名称)
# 获取线路链接
line_url = line.xpath('./a/@href')[0]
# 访问线路页面
line_response = requests.get(line_url)
line_response.encoding = 'utf-8'
line_html = etree.HTML(line_response.text)
# 提取首末班车时间
start_time = line_html.xpath('//xpath/to/start_time/text()')[0]
end_time = line_html.xpath('//xpath/to/end_time/text()')[0]
# ... (提取其他信息)
# 将线路信息整合到字典中
line_data = {
'线路': line_name,
'站点': station_str,
'首班车': start_time,
'末班车': end_time,
# ...
}
# ... (将数据写入文件或数据库)
💡 注意:
- 以上代码示例仅供参考,实际代码需要根据目标网站的结构进行调整。
- 多层级爬取需要控制爬取频率,避免对目标网站造成过大压力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









