







一、实验目的
(1)通过实验掌握Spark SQL的基本编程方法;
(2)熟悉RDD到DataFrame的转化方法;
(3)熟悉利用Spark SQL管理来自不同数据源的数据。
二、实验平台
操作系统:Ubuntu20.04
Spark版本:3.4.0
Python版本:3.8.3
数据库:MySQL
三、实验内容和过程
1.Spark SQL基本操作
将下列JSON格式数据复制到Ubuntu系统中,并保存命名为employee.json。
| { "id":1 , "name":" Ella" , "age":36 } { "id":2, "name":"Bob","age":29 } { "id":3 , "name":"Jack","age":29 } { "id":4 , "name":"Jim","age":28 } { "id":4 , "name":"Jim","age":28 } { "id":5 , "name":"Damon" } { "id":5 , "name":"Damon" } |
为employee.json创建DataFrame,并写出Python语句完成下列操作:
- 查询所有数据;
- 查询所有数据,并去除重复的数据;
- 查询所有数据,打印时去除id字段;
- 筛选出age>30的记录;
- 将数据按age分组;
- 将数据按name升序排列;
- 取出前3行数据;
- 查询所有记录的name列,并为其取别名为username;
- 查询年龄age的平均值;
- 查询年龄age的最小值。
实验步骤:
首先在目录/usr/local/spark/mycode/sparksql下,用命令“gedit employee.json”创建文件,并把数据复制进去。然后调用 Builder 对象的 getOrCreate() 方法,创建一个 SparkSession 实例,最后创建DataFrame。
| >>> from pyspark.sql import SparkSession >>> spark = SparkSession.builder.getOrCreate() >>> df = spark.read.json("file:///usr/local/spark/mycode/sparksql/employee.json") |
基于上面的数据,用Python语句完成下列操作:
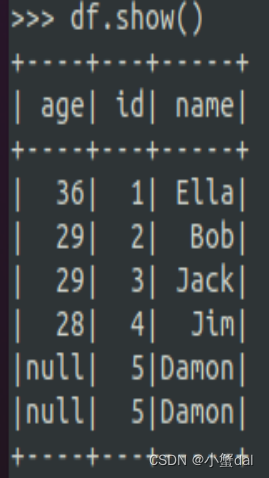
(1)查询所有数据
| >>> df = spark.read.json("file:///usr/local/spark/mycode/sparksql/employee.json") |
运行结果:
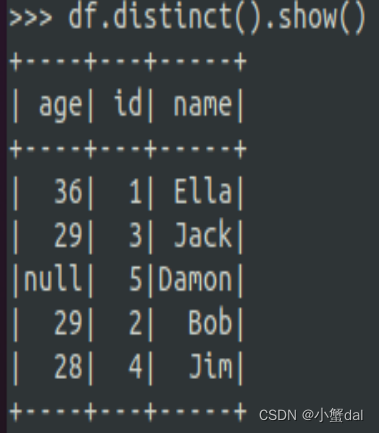
(2)查询所有数据,并去除重复的数据
| >>> df.distinct().show() |
运行结果:
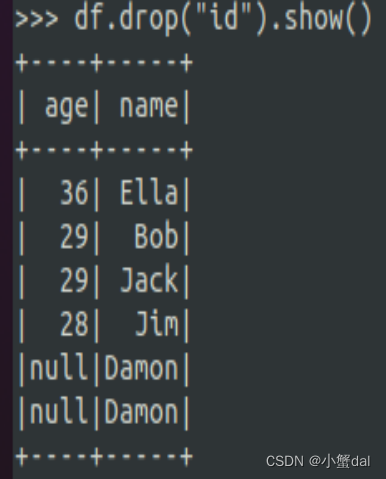
(3)查询所有数据,打印时去除id字段
| >>> df.drop("id").show() |
运行结果:
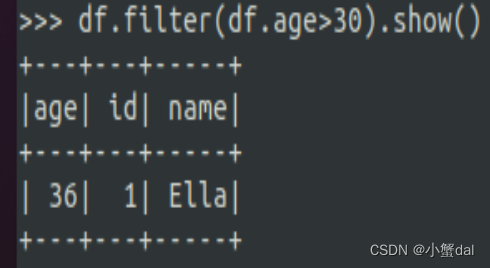
(4)筛选age>30的记录
| df.filter(df.age > 30 ).show() |
运行结果:
(5)将数据按“name”分组
| >>> df.groupBy("name").count().show() |
运行结果:
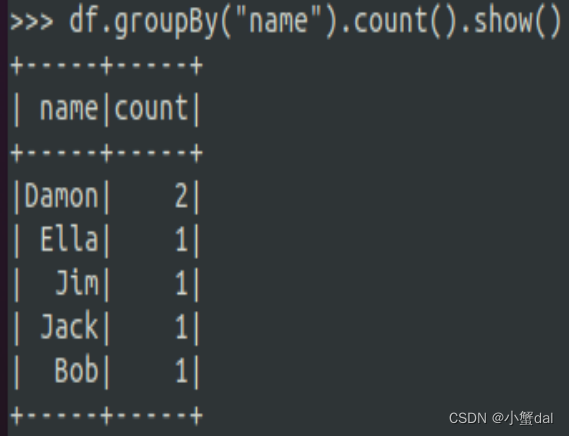
(6)将数据按name升序排列
| >>> df.sort(df.name.asc()).show() |
运行结果:
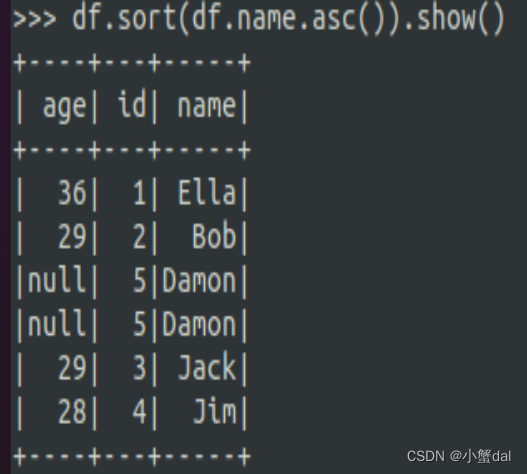
(7)取出前3行数据
| >>> df.take(3) 或python> df.head(3) |
运行结果:

(8)查询所有记录的name列,并为其取别名为username
| >>> df.select(df.name.alias("username")).show() |
运行结果:
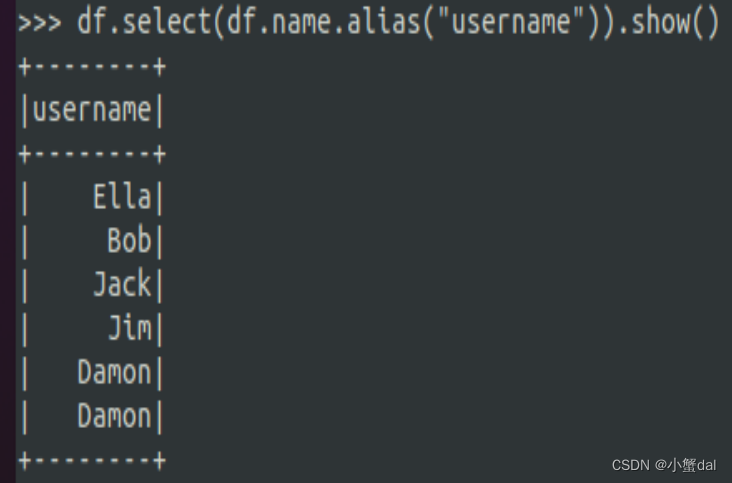
(9)查询年龄age的平均值
| >>> df.agg({"age": "mean"}).show() |
运行结果:
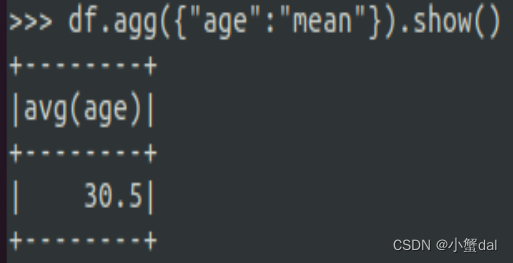
(10)查询年龄age的最大值
| >>> df.agg({"age": "max"}).show() |
运行结果:
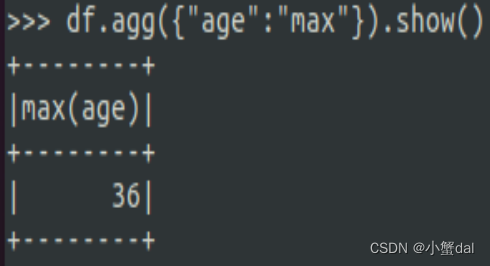
2.编程实现将RDD转换为DataFrame
源文件内容如下(包含id,name,age):
| 1,Ella,36 2,Bob,29 3,Jack,29 |
先将数据复制保存到Ubuntu系统中,命名为employee.txt,实现从RDD转换得到DataFrame,并按“id:1,name:Ella,age:36”的格式打印出DataFrame的所有数据。请写出程序代码。
实验过程:
假设当前目录为/usr/local/spark/mycode/rddtodf,在当前目录下新建一个目录mkdir -p src/main/python,然后在目录/usr/local/spark/mycode/rddtodf/src/main/python下新建一个rddtodf.py,复制下面代码;(下列两种方式任选其一)
方法一:利用反射来推断包含特定类型对象的RDD的schema,适用对已知数据结构的RDD转换;
| from pyspark.sql import SparkSession from pyspark import SparkContext from pyspark.sql.types import Row
if __name__ == "__main__": # 创建 SparkSession 实例 spark = SparkSession.builder.appName("Simple App").getOrCreate() sc = spark.sparkContext # 获取当前 SparkSession 的 SparkContext
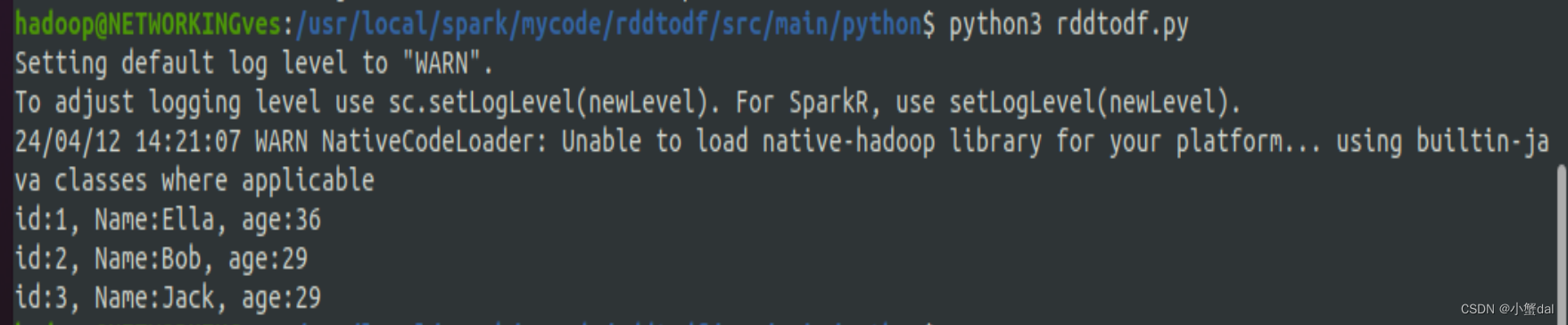
# 读取文件 peopleRDD = sc.textFile("file:///usr/local/spark/mycode/sparksql/employee.txt") # 将每一行转换为 Row 对象 rowRDD = peopleRDD.map(lambda line: line.split(",")).map(lambda attributes: Row(int(attributes[0]), attributes[1], int(attributes[2]))) # 将 RDD 转换为 DataFrame df = rowRDD.toDF() # 创建临时视图 df.createOrReplaceTempView("employee") # 执行 SQL 查询 personsDF = spark.sql("select * from employee") # 打印结果 personsDF.rdd.map(lambda t: "id:{}, Name:{}, age:{}".format(t[0], t[1], t[2])).foreach(print) |
利用命令运行程序
| python3 ./ rddtodf.py |
运行结果:
方法二:使用编程接口,构造一个schema并将其应用在已知的RDD上。
| from pyspark.sql.types import Row from pyspark.sql.types import StructType from pyspark.sql.types import StructField from pyspark.sql.types import StringType from pyspark.conf import SparkConf from pyspark.sql.session import SparkSession from pyspark import SparkContext
if __name__ == "__main__": conf = SparkConf().setAppName("Simple App").setMaster("local") sc = SparkContext(conf=conf) spark = SparkSession.builder.config(conf=conf).getOrCreate() # 创建 SparkSession 实例
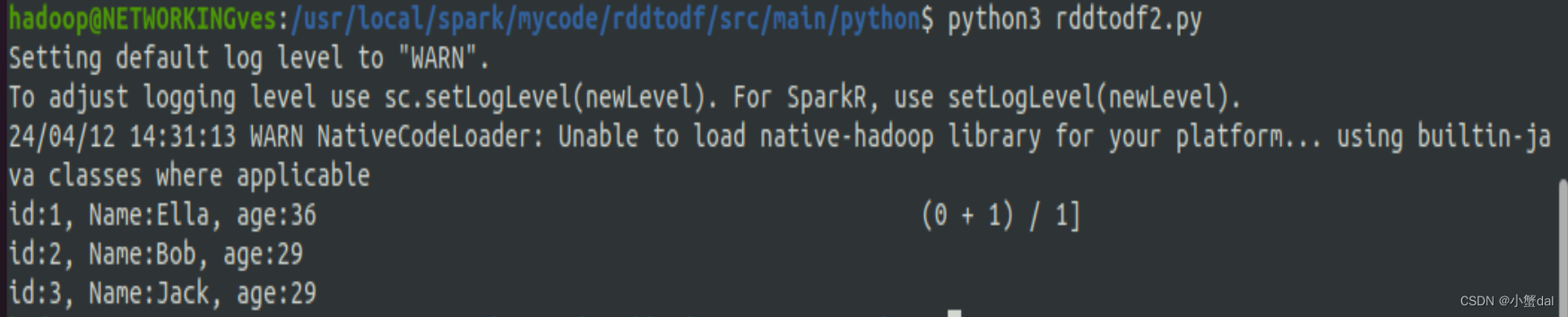
peopleRDD = sc.textFile("file:///usr/local/spark/mycode/sparksql/employee.txt") schemaString = "id name age" fields = [StructField(field, StringType(), True) for field in schemaString.split()] schema = StructType(fields) rowRDD = peopleRDD.map(lambda line: line.split(",")).map(lambda attributes: Row(id=attributes[0], name=attributes[1], age=int(attributes[2]))) employeeDF = spark.createDataFrame(rowRDD, schema) employeeDF.createOrReplaceTempView("employee") results = spark.sql("SELECT * FROM employee") results.rdd.map(lambda t: "id:{}, Name:{}, age:{}".format(t.id, t.name, t.age)).foreach(print) |
利用命令运行程序
| python3 ./ rddtodf2.py |
运行结果:
3. 编程实现利用DataFrame读写MySQL的数据
(1)在MySQL数据库中新建数据库sparktest,再创建表employee,包含如表5-2所示的两行数据。
表5-2 employee表原有数据
| id | name | gender | Age |
| 1 | Alice | F | 22 |
| 2 | John | M | 25 |
(2)配置Spark通过JDBC连接数据库MySQL,编程实现利用DataFrame插入如表5-3所示的两行数据到MySQL中,最后打印出age的最大值和age的总和。
表5-3 employee表新增数据
| id | name | gender | age |
| 3 | Mary | F | 26 |
| 4 | Tom | M | 23 |
实验过程:
(1)首先启动MySQL数据库
| sudo service mysql start # 输入虚拟机密码 mysql -u root -p #输入MySQL密码 |
在MySQL Shell环境中,新建数据库sparktest,再建表employee,并插入数据
| create database sparktest; use sparktest; create table employee (id int(4), name char(20), gender char(4), age int(4)); insert into employee values(1,'Alice','F',22); insert into employee values(2,'John','M',25); |
(2)在目录为/usr/local/spark/mycode/testmysql下,新建一个目录mkdir -p src/main/python,然后在目录/usr/local/spark/mycode/testmysql/src/main/python下新建一个testmysql.py,复制下面代码:
| from pyspark.sql import SparkSession from pyspark.sql.types import Row from pyspark.sql.types import StructType from pyspark.sql.types import StructField from pyspark.sql.types import StringType from pyspark.sql.types import IntegerType
if __name__ == "__main__": spark = SparkSession.builder \ .appName("MySQL JDBC Example") \ .config("spark.driver.extraClassPath", "/usr/local/spark/jars/mysql-connector-j-8.0.33.jar") \ #自己JDBC的路径,自行修改 .getOrCreate()
jdbcDF = spark.read.format("jdbc") \ .option("url", "jdbc:mysql://localhost:3306/sparktest") \ .option("driver", "com.mysql.cj.jdbc.Driver") \ .option("dbtable", "employee") \ .option("user", "root") \ .option("password", "自己MySQL密码") \ .load()
jdbcDF.filter(jdbcDF.age > 20).collect() # 检测是否连接成功
studentRDD = spark.sparkContext.parallelize(["3 Mary F 26", "4 Tom M 23"]).map(lambda line: line.split(" ")) schema = StructType([ StructField("id", IntegerType(), True), StructField("name", StringType(), True), StructField("gender", StringType(), True), StructField("age", IntegerType(), True) ]) rowRDD = studentRDD.map(lambda p: Row(int(p[0]), p[1].strip(), p[2].strip(), int(p[3]))) employeeDF = spark.createDataFrame(rowRDD, schema)
prop = { 'user': 'root', 'password': '自己MySQL密码', 'driver': "com.mysql.cj.jdbc.Driver" }
employeeDF.write.jdbc("jdbc:mysql://localhost:3306/sparktest", 'employee', 'append', prop)
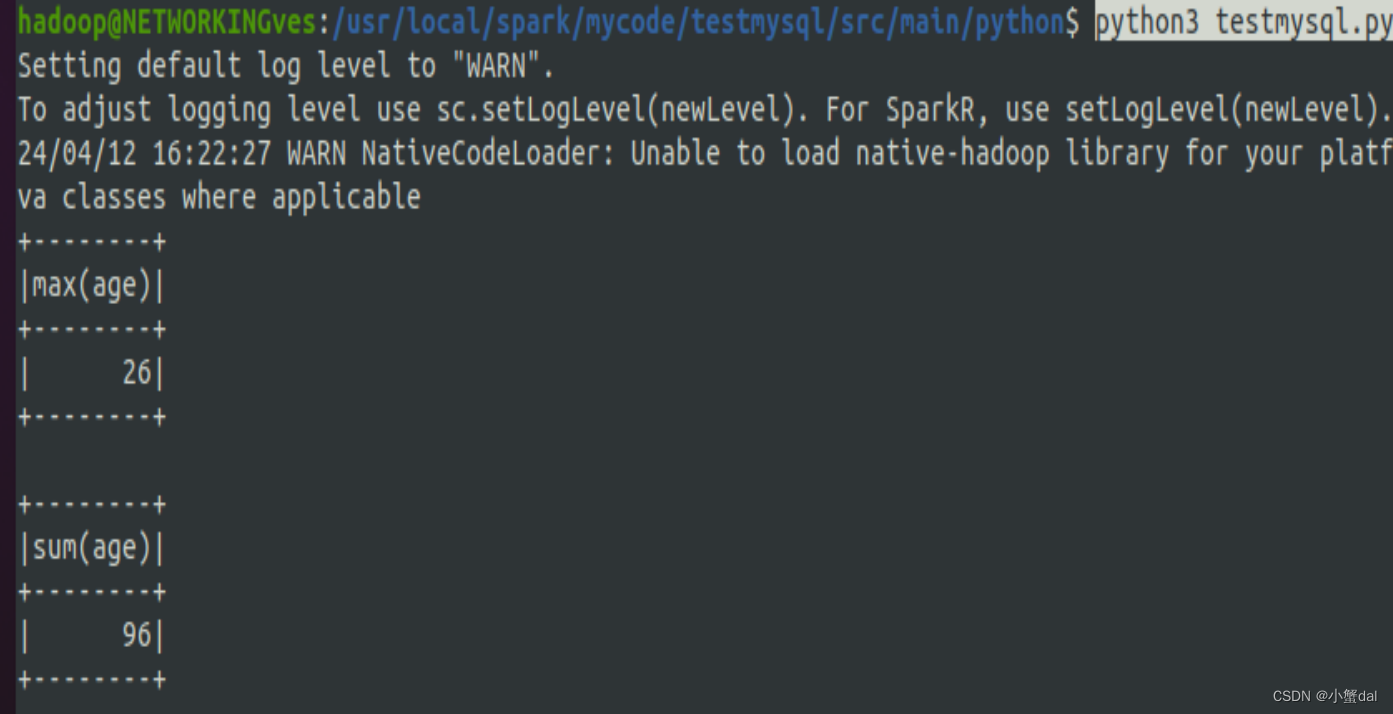
jdbcDF.collect() jdbcDF.agg({"age": "max"}).show() jdbcDF.agg({"age": "sum"}).show() |
注意:这里要下载MySQL的JDBC数据库驱动程序,确保虚拟机中有这个,才能运行,需要将代码中的SQL用户配置改成自己的,JDBC也要改成自己的路径
执行命令:
| python3 testmysql.py |
运行结果:















 7752
7752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









