







目录
1.问题思考
观察以下代码
#include <string>
#include <map>
int main()
{
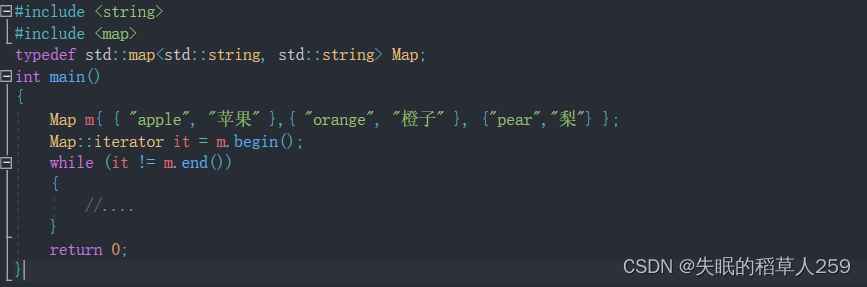
std::map<std::string, std::string> m{ { "apple", "苹果" }, { "orange",
"橙子" },
{"pear","梨"} };
std::map<std::string, std::string>::iterator it = m.begin();
while (it != m.end())
{
//....
}
return 0;
}上述代码中定义哈希表map的方式看起来很复杂且繁琐,在实际的程序中往往会遇到很多这种变量类型较为复杂的情况。一方面是类型难于拼写,另一方面是含义不明确导致容易出错。比如std::map<std::string, std::string>::iterator 是一个类型,但是该类型太长了,缺乏可读性与可写性。当然,我们很容易想到用typedef给这一类型取别名。比如:
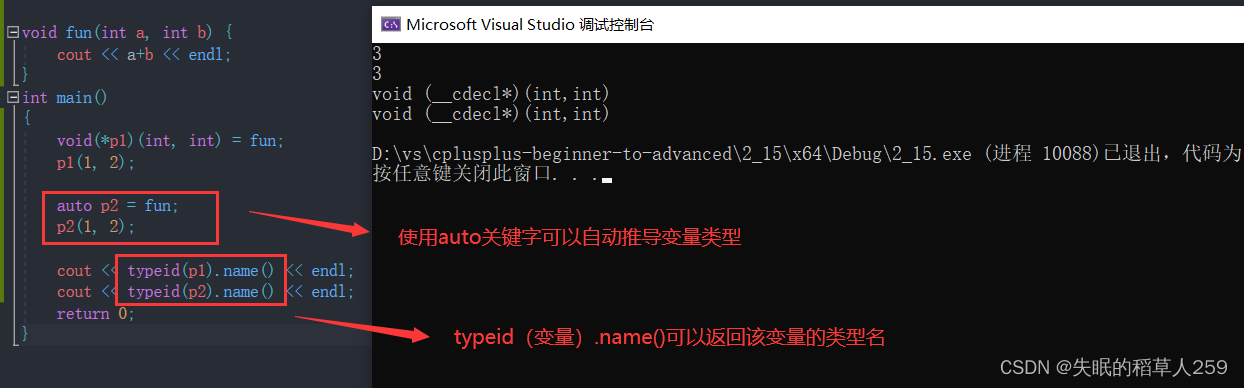
但是在我们的日常编程中,常常需要把表达式的值赋值给变量,这就需要我们清楚的知道表达式的类型。然而有时候要做到这点并非那么容易。
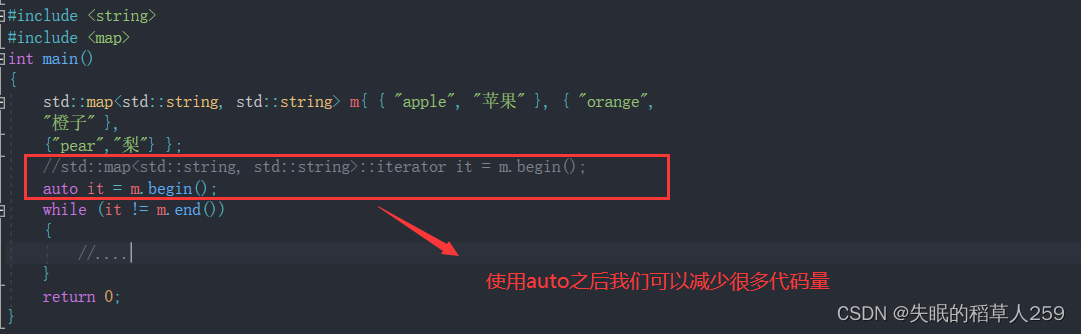
为了减少代码中的显式类型声明,提高代码的简洁性和可读性,我们可以使用auto关键字
我们发现,使用auto我们可以非常方便的自动推导其类型

2.auto关键字介绍
在上面的例子中我们可以看到,auto关键字提高了C++代码的可读性和灵活性,同时减少开发者在类型声明上的冗余,但是在早期c/c++中的auto含义是指自动存储器的局部变量,其作用过于狭隘,导致少有人使用。
3. 早期auto的缺陷:
默认存储类别: 在早期的 C 语言中,默认的存储类别就是自动存储器,因此没有必要显式使用
auto来声明变量的存储类别。可移植性差: C 语言标准并没有要求编译器支持
auto关键字,因此在不同的编译器中可能会有不同的行为,这降低了代码的可移植性。可读性差: 由于
auto的含义不够清晰,可能导致代码的可读性降低。使用auto来表示自动存储器的局部变量并没有提供很大的语义上的优势
4.什么叫自动存储器?
自动存储器(automatic storage)是指在函数内部或块内部声明的变量的存储方式。这种存储方式的特点是变量的生命周期与其所在的函数或块的执行周期相关。
在 C 和 C++ 中,当在函数内或块内声明变量时,如果没有使用
static关键字或extern关键字,变量就被默认分配为自动存储器类型。自动存储器的变量在程序执行到其声明点时被创建,当程序执行离开声明该变量的函数或块时,该变量会被销毁。也就是说,实际上在函数内部的所有变量默认都是自动存储器。早期的auto就显得非常多余。用不用auto都是自动存储器,那就没有必要使用auto了。
5. c++标准auto关键字
C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto
的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译期会将auto替换为变量实际的类型。意思就是说,auto在编译之前会给这个类型名留一定的空间,等到编译阶段推导实际类型的时候,再将实际类型替换。
5.1auto的使用细节
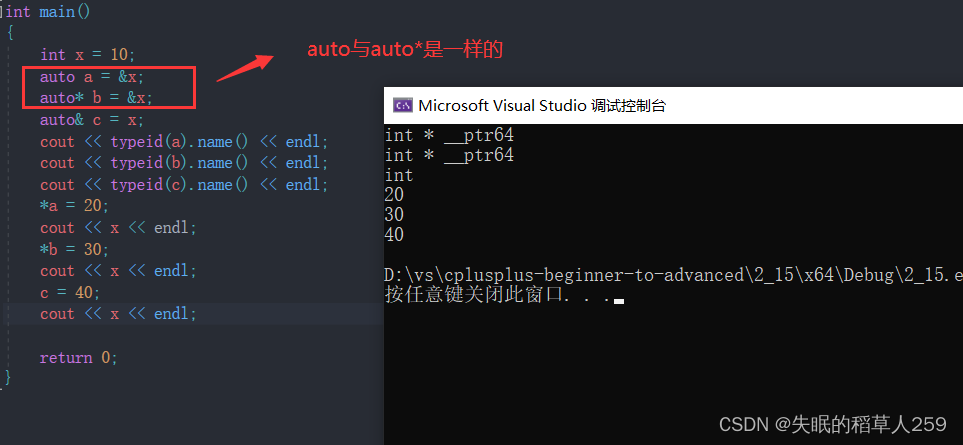
1. auto与指针和引用结合起来使用
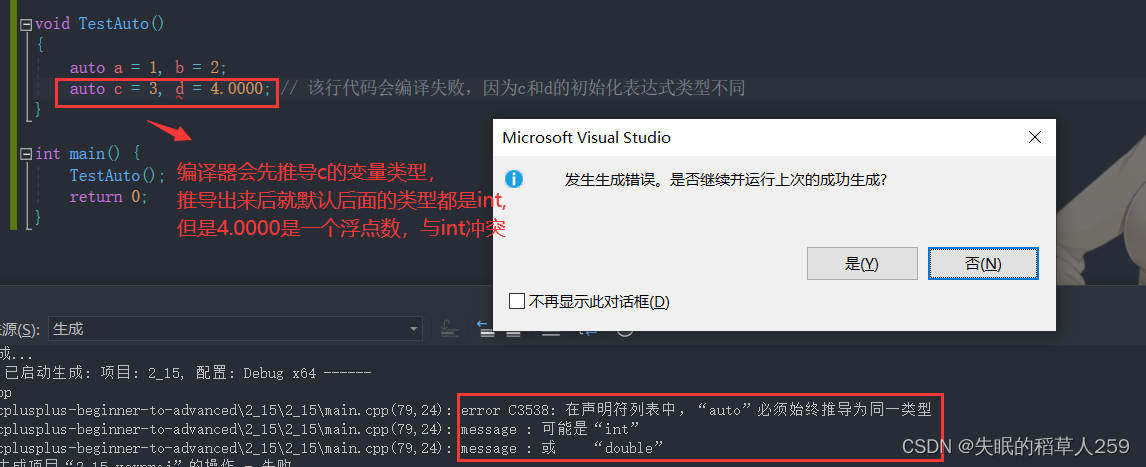
用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须加&2. 在同一行定义多个变量
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译
器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
5.2 auto什么时候不能推导变量的类型呢?
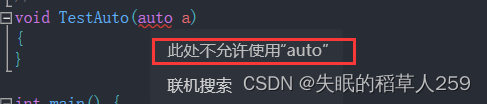
1. auto不能作为函数的参数
这一点很容易理解,在函数声明时,参数的类型需要在编译期前确定,而
auto是一个在编译期间进行类型推导的关键字。函数参数需要在声明时指定类型,以便编译器能够正确地进行参数传递和生成相应的调用代码。
2.auto不能直接用来声明数组
对于上面这个例子,在初始化myArray时,arr会退化为首元素的地址。这一点在我之前关于指针的博客里其实就已经写了,数组名只有在两中情况下作为整个数组的指针,一个是sizeof(arr)的时候,一个是 &arr 的时候。其余情况数组名都是表示数组首元素的地址。所以,我们在使用auto声明一个数组时,
myArray的类型实际上是int*而不是数组指针。而对于数组,其大小和元素类型都是数组类型的一部分,数组的类型信息不能被auto完全捕获,这导致auto不能直接用于声明数组。对数组名与指针关系还不太了解的同学可以去看我之前的博客:

3. 为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法
4. auto在实际中最常见的优势用法就是for循环,还有lambda表达式等进行配合使用。
5.3基于范围的for循环
5.3.1范围for的用法
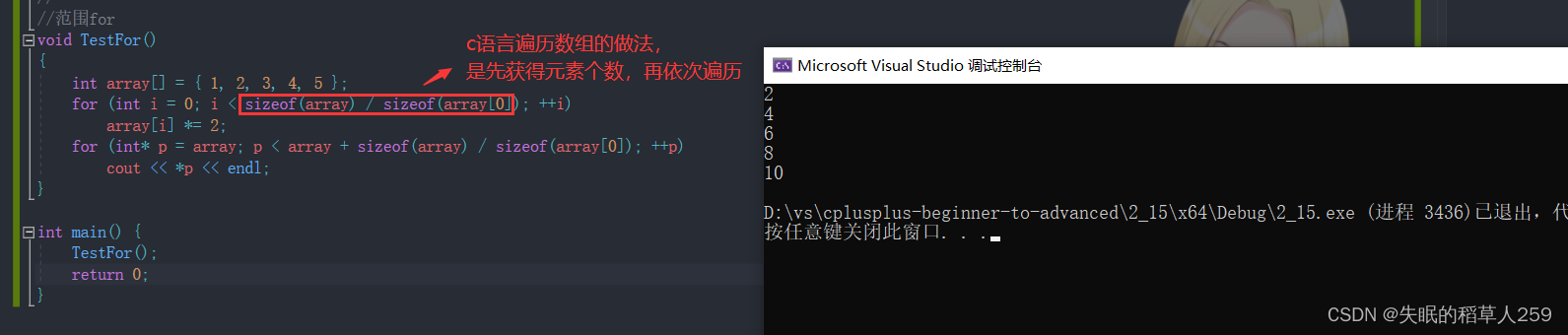
c++98或者c语言中如果要遍历一个数组,一般会这样:
如果要将数组作为参数我们还需要传数组的元素数量。
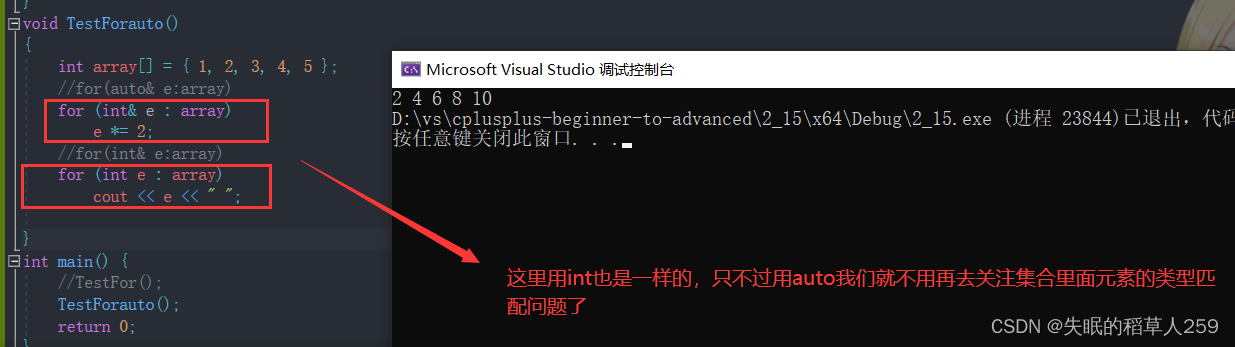
对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此C++11中引入了基于范围的for循环。for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。
这里要注意的是,auto e:array和int e:array是一样的
与普通循环类似,可以用continue来结束本次循环,也可以用break来跳出整个循环
5.3.2 范围for的使用条件
1. for循环迭代的范围必须是确定的
对于数组而言,就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供
begin和end的方法,begin和end就是for循环迭代的范围。
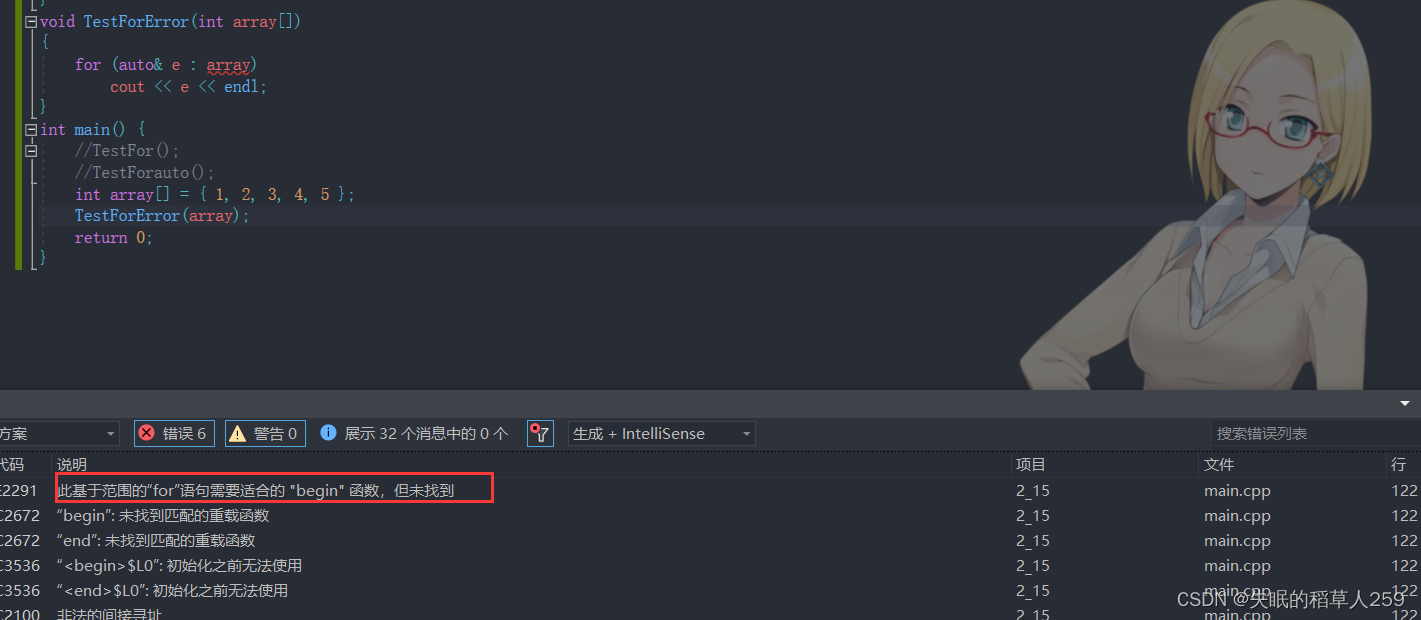
思考以下代码为什么报错
跟 auto不能直接用来声明数组 的例子一样,在TestForError函数里,array作为参数实际上是一个int*指针,在传参的过程中,array指针其实只是数组首元素的地址,所以此时将array作为循环的对象会出现循环范围不明确的问题。
2. 迭代的对象要实现++和==的操作
6.auto关键字的用法总结
1.变量声明和初始化:
auto x = 10; // 推导为int
auto y = 3.14; // 推导为double
auto z = "Hello"; // 推导为const char*
2.结合范围循环:
int numbers[] = {1, 2, 3, 4, 5};
for (auto num : numbers) {
// num的类型为int,自动推导
}
3.函数返回类型自动推导:
auto add(int a, int b) -> int {
return a + b;//auto推导出a+b的值是int类型
}
4.结合模板: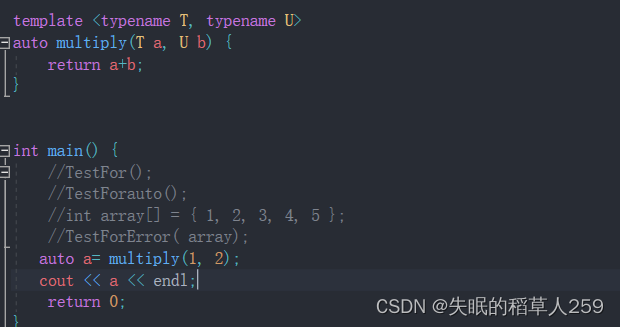
5.避免复杂的表达式: auto 并不是万能的,对于复杂的表达式,可能会导致类型推导不准确,因此需要慎重使用。
auto result = fun(); // 慎重使用,确保类型推导准确














 986
986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









