







什么是ResNet
首先我们来看什么是ResNet,其全称为Residual Network(残差网络),是一种深度学习的网络结构,由微软研究院的何凯明等人于2015年提出。ResNet最大的创新在于引入了“残差模块”(Residual Block),有效地解决了深度神经网络训练中的梯度消失和表示瓶颈问题,使得网络的层数可以达到前所未有的深度,如1000层以上。
- 核心:残差模块的核心思想是通过引入跨层链接(skip connections),将输入直接传递到输出,从而形成一种“残差学习”的机制。这种设计允许反向传播的梯度直接流过整个网络,缓解了深度网络训练中的梯度消失问题。因为ResNet的出现,让深度学习从而变成了可能,真正的实现了深度的概念。
- 有效性:ResNet在多个计算机视觉任务上取得了显著的性能提升,包括图像分类、目标检测和语义分割等,并成为了后续许多先进网络结构设计的基础。ResNet的成功也促进了深度学习在更广泛领域的研究和应用,是深度学习发展史上的一个重要里程碑。在2015年的ImageNet图像识别挑战赛中,ResNet取得了冠军,进一步证明了其有效性。
本文将会带大家深度解析ResNet原理,其实现的步骤以及为什么只是一个简单的链接就可以起到如此大的作用。后续也将会给大家实现并讲解resnet的具体应用。ResNet的原论文地址 Deep Residual Learning for Image Recognition,大家有兴趣的可以去看看原论文。
提出背景
首先我们来看看当时的研究处于个什么情况,当时盛行的vgg网络,最多也就是到了19层,为什么不继续加深网络的结构呢?是不想吗,当然不是,按道理来说,当网络加深的时候,模型应该会表现的越来越好,能够学习到更多的特征呐,所以表现精度应该会更加优秀才对,但是实际上并不是,当网络加深的时候,表现反而不如浅层的原因,这是为什么呢?
梯度爆炸/梯度消失:
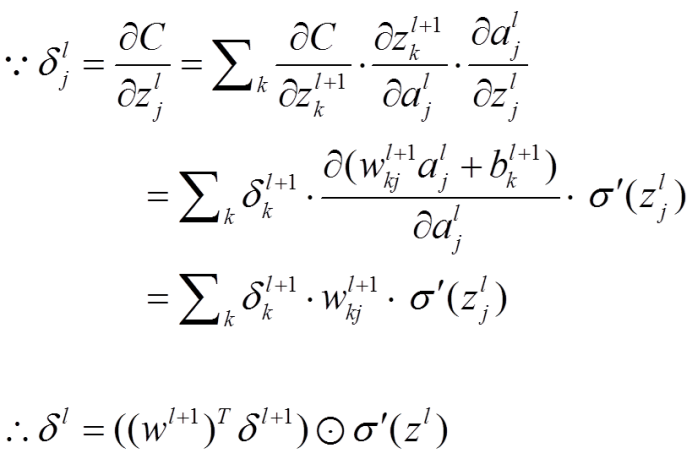
首先一个很重要的原因就是当网络层数不断增加的时候,会很容易出现梯度保证与梯度消失的问题。因为我们更新网络的方式是通过反向传播的方式,其是通过链式求导的方式进行的,而当网络层数越深,连乘的项不断增多,所以这就是会导致很容易梯度爆炸或者梯度消失。就会导致靠近输入层的网络层,计算的到的偏导数极其大,更新后W变成一个很大的数(爆炸)或者靠近输入层的网络层,计算的到的偏导数近乎零,W几乎无法得到更新。
解决方法:首先来看看为什么会梯度爆炸梯度消失,因为梯度要么过大所以一直乘导致爆炸,要么过小接近于0,一直连乘导致消失。那么我们能不能通过控制梯度在一定的范围内变化,这样就不会出现梯度爆炸/梯度消失的现象呐。当然是可以的,首先可以将数据归一化进行处理,这样我们可以避免量纲不同带来的影响,其次对于神经网络的各层,我们可以通过加入BN层让每层的输入也现在在相同的范围内,通过这样的方式,我们可以有效的避免梯度爆炸/梯度消失。并且ResNet正是通过进行数据的归一化的BN层的设置来处理梯度爆炸与梯度消失的问题。
退化现象:
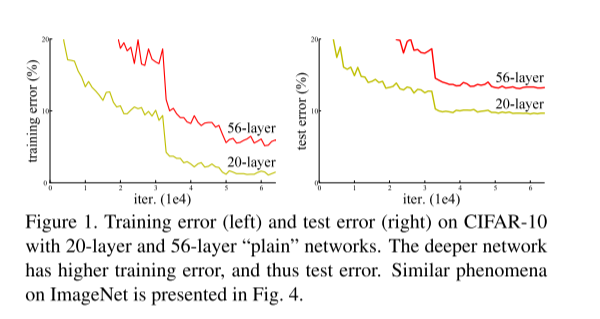
虽然我们通过数据的归一化的BN层的设置来处理梯度爆炸与梯度消失的问题,但是当网络加深的时候又会带来新的问题就是退化现象。什么是退化现象,就是通俗来说是网络性能的退化现象,可以理解为随着训练轮数(epoch)的增加,精度到达一定程度后,就开始下降了。可能有些同学会有疑问,会不会是因为出现了过拟合的现象呢?其实从图中可以清晰看出,如果出现过拟合的话就会导致训练的时候的误差会很小,测试的误差会很大,即过度的拟合了训练数据。但是我们看图,训练的时候的误差56层的也是大于20层的,所以这就不会是过拟合的现象。所以网络层数越深,训练误差越高,导致训练和测试效果变差,这一现象称为退化。
解决方法:如果我们仅仅单纯地增加神经网络的深度,可能会引发网络模型的退化,进而导致网络早期层所捕获的特征丢失。可以这样理解,假设在层数达到40层时,模型已经达到了最佳状态,但继续增加层数,由于激活函数和卷积等操作的影响,只会增强整个网络的非线性,从而使性能下降。
其根本原因在于,通过多个非线性层来近似一个恒等映射(即恒等函数,一种对任何元素映射后与原元素相同的函数)可能是困难的。为什么恒等映射难以实现呢?我们可以简单设想,随着网络层数的增加,网络学习到的是更高层次的语义特征,但在这一学习过程中,由于激活函数的特性,例如ReLU函数在输入小于零时输出为零,这就可能导致在加深网络的过程中不可避免地丢失低层语义信息。这样一来,最终学习到的网络可能并不符合数据的真实信息分布,从而导致网络性能不佳。
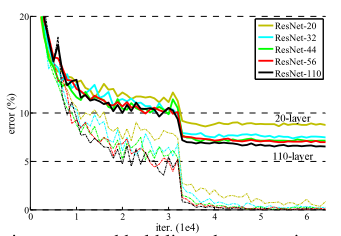
为了解决深层网络中的退化问题,可以采取一种策略,即让神经网络的某些层跳过与下一层神经元的直接连接,实现隔层相连,从而减弱每层之间的紧密联系。ResNet论文中提出的残差结构(residual结构)正是为了缓解这一问题。如下图所示,采用了残差结构的卷积网络在层数不断增加的情况下,性能并没有下降,反而有所提升。(图中虚线表示训练误差,实线表示测试误差)
原理解析
残差连接从实现来看其实是非常简单的,如下图所示。当然可能有些人要说了,这我来我也行。确实形式很简单,只不过是从原来的输出 F ( x ) F(x) F(x)变成了 F ( x ) + x F(x)+x F(x)+x,但是要说到,为什么这么简单的一个连接就能起到这么大的作用呢?可能很多人就说不出来了。
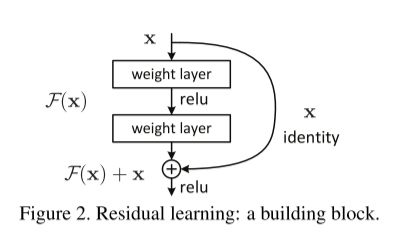
首先还是回到恒等映射,什么是恒等映射,即无论什么输入 x x x,都会有 f ( x ) = x f(x)=x f(x)=x,就是输出恒等于输入。这就是我们希望网络所能学习到的东西。以下为我自己的理解,就是我们希望网络通过一系列非线性变换,抽象提取出其所蕴含的深层语义信息,其是符合我们所学习的数据的分布的,但是当网络深了之后,其提取的信息是有偏移的,即不是原来数据的分布。因为每一次的非线性变换其是会损失数据信息的,每一层的偏移会导致最后所学习到数据分布是有问题的,从而导致模型的表现不佳。
那么我们再来看残差网络做了什么,其实有些人可能会有疑问,明明所进行的操作是从原来的输出 F ( x ) F(x) F(x)变成了 F ( x ) + x F(x)+x F(x)+x,好像是加法,为什么叫做残差网络呢?其实原本我们所学习到的函数映射为 y = F ( x ) y=F(x) y=F(x),即我们希望 F ( x ) F(x) F(x)能够学习到数据 x x x的特征,保证其恒等映射,但是我们现在变成了 y = F ( x ) + x y=F(x)+x y=F(x)+x,从而变成了 y − x = F ( x ) y-x=F(x) y−x=F(x),我们所学习的 F ( x ) F(x) F(x)变成了这样的形式,我们去学习数据 x x x的特征容易还是去让 F ( x ) F(x) F(x)趋向于0更容易,当然很显而易见了。所以残差网络为什么叫残差的原因就是体现在这里。
网络结构
ResNet中一共有两种不同的ResNet Block。左边的用于浅层网络的ResNet叫做BasicBlock,右边的用于深层网络的ResNet叫做Bottleneck。即将两个的卷积层替换为,它通过1×1 conv来巧妙地缩减或扩张feature map维度,从而使得我们的1×1 conv的filters数目不受上一层输入的影响,它的输出也不会影响到下一层。中间的卷积层首先在一个降维卷积层下减少了计算,然后在另一个的卷积层下做了还原。既保持了模型精度又减少了网络参数和计算量,节省了计算时间。
同时很有意思的是,这两个设计具有的参数量:
左侧: (3 X 3 X 64)X 64 +(3 X 3 X 64)X 64 = 73728
右侧: (1 X 1 X 64)X 64 +(3 X 3 X 64)X 64 +(1 X 1 X 64)X 256 +(1 X 1 X 64)X 256 = 73728
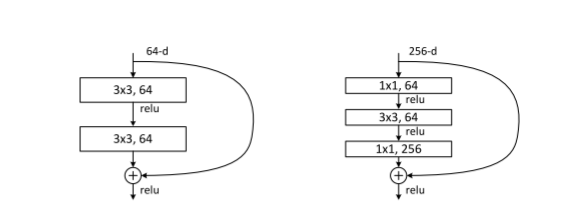
再来看整体的ResNet网络如下图,有18,34,50,101,152层的ResNet。像18和34层的ResNet所使用的就是BasicBlock结构,而之后的更深层的网络使用的就是Bottleneck了。其设计其实就是参考于VGG来进行设计的,其最重要的改变就是通过shortcut机制加入了残差单元。
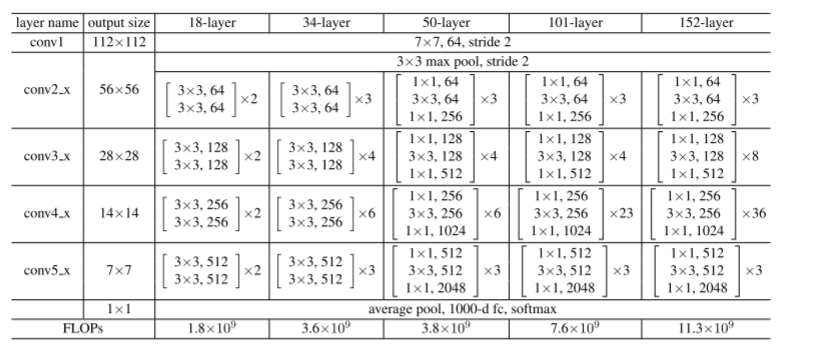
可以看到,结构大差不差。不论是18层、34层、50层、还是101层、152层。
上来都是一个7x7的卷积层,然后是一个3x3的最大池化下采样。
然后就是按照图中的conv2_x、conv3_x、conv4_x、conv5_x中的残差结构。
最后再跟一个平均池化下采样,和全连接层,sofmax输出。
首先,ResNet使用ImagesNet数据集,采用的默认输入尺寸是(224, 224, 3),RGB图像,三通道
按照表中,我们可以看到,图片输入之后,首先是一个7x7,64,stride 2
也就是一个卷积层,卷积核大小为7x7,输出通道为64(也就是卷积核个数),stride=2。
参考资料
希望这篇文章能够给大家带来些思考,让大家能够有所收获,同时以上内容有所参考下列文章进行学习,并包含了我自己的思考。后续将会给大家带来使用ResNet解决相关问题的实际应用部署。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









