







文章目录
前言
提出时间:2021年
作者单位:旷视科技
旷视官方代码:https://github.com/Megvii-BaseDetection/YOLOX
论文下载地址:https://arxiv.org/abs/2107.08430
论文题目:《YOLOX: Exceeding YOLO Series in 2021》
本文带大家走进YOLOX,常用于深度学习中的目标检测领域,其隶属于YOLO系列。YOLO系列以其快速、准确的目标检测能力而闻名,而YOLOX在此基础上进行了多方面的改进和优化,旨在提供一个更灵活、可扩展且性能更强的检测框架。本文将会带大家来看看YOLOX当时所使用的黑科技,详细解读YOLOX的原理,当然后续也会给大家带来相关的实际应用的,敬请期待!
简介
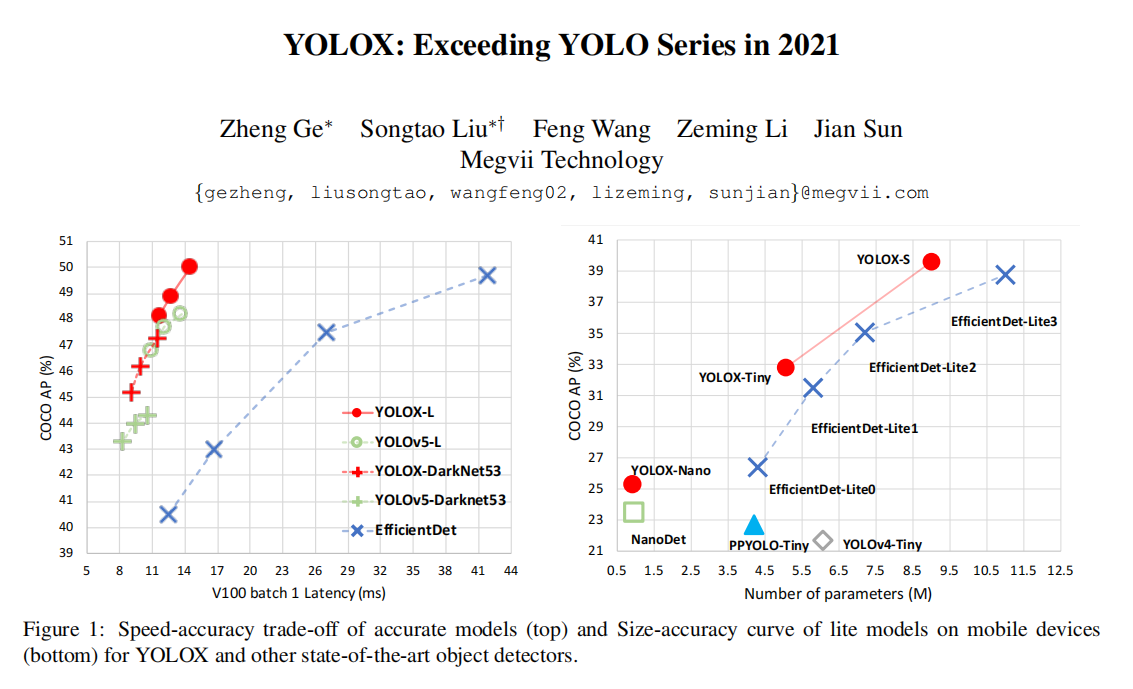
看YOLOX当时发表的论文标题,特别的张狂,号称超越当时所有的YOLO系列模型。
首先YOLOX其是基于YOLOv5的基础上进行设计的,像YOLOv5一样设计了一个统一的基础网络结构,使得模型可以在训练和推理阶段共享相同的网络架构,这简化了模型的部署流程并提高了效率。并且通过模块化设计,使得我们可以更换或者替换不同的组件比如 Backbone(主干网络)、Neck(颈部网络)以及Head(头部网络),以适应不同任务需求或进行算法创新。
YOLOX核心贡献突破:
- Decoupled Head:YOLOX引入了解耦头的设计通过设计不同的分支来进行分类任务和回归任务。
- **anchor free:**不在使用以往YOLO系列所使用的基于anchor的策略,能更好的减少模型参数同时能够带来较强的鲁棒性。
- **Mosaic Data Augmentation:**采用马赛克数据增强技术,随机分割组合图片,增加数据的多样性,提升模型的泛化能力。
- SimOTA (Similarity-based One-Stage Object Detection Assignment):解决传统目标检测方法中手工设置阈值的问题,通过动态分配正负样本,提高训练效率和检测精度。其核心思想是根据预测框与真实框之间的相似度来分配样本,从而优化模型性能。这部分比较难,后续讲解的时候比篇幅会有点长。
详细解读
Mosaic and Mixup
Mixup
Mixup是MIT和FAIR在ICLR 2018上发表的文章中提到的一种数据增强算法。在介绍mixup之前,我们首先简单了解两个概念:经验风险最小化(Empirical risk minimization,ERM)和邻域风险最小化(Vicinal Risk Minimization,VRM)。
经验风险最小化(ERM):“经验风险最小化”是目前大多数网络优化都遵循的一个原则,即使用已知的经验数据(训练样本)训练得到的学习器的误差或风险,也叫作“经验误差”或“训练误差”。相对的,在新样本(未知样本)上的误差称为“泛化误差”,显然,我们希望学习器的“泛化误差”越小越好。然而,通常我们事先并不知道新样本是什么样的,实际能做的是努力使经验误差越小越好。但是,过分的减小经验误差,通常会在未知样本上产生很差的结果,也就是我们常说的“过拟合”。
为了提高模型泛化性(模型在验证集的表现能力),通常可以通过使用大规模训练数据来提高,但是实际上,获取有标签的大规模数据需要耗费巨大的人工成本,甚至有些情况下根本无法获取数据。解决这个问题的一个有效途径是“邻域风险最小化”,即通过先验知识构造训练样本的邻域值。一般的做法就是传统的数据增强方法,比如加噪、翻转、缩放等,但是这种做法很依赖于特定的数据集和人类的先验知识。
其原理很简单:
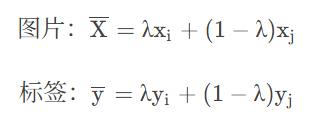
其中, ( x i x_i xi , y i y_i yi ) ( x i x_i xi, y i y_i yi ) 和 ( x j x_j xj, y j y_j yj) ( x j x_j xj, y j y_j yj)是从原始训练数据中随机选取的两个样本, λ ∈ [ 0 , 1 ] 。 λ 是mixup的超参数,控制两个样本插值的强度,当 λ → 0 或 λ → 1 时,则退化到了ERM的情况。增强的效果图如下,其实就是将一张图片和另一张图片进行融合处理。
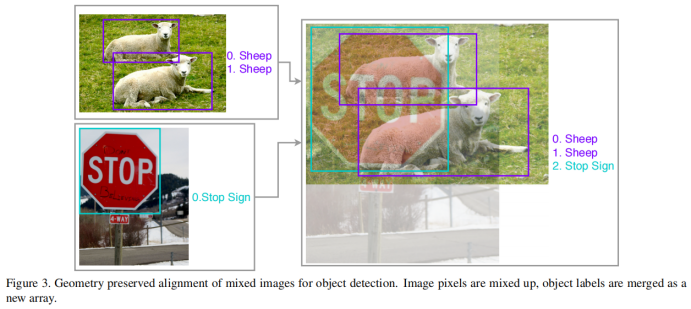
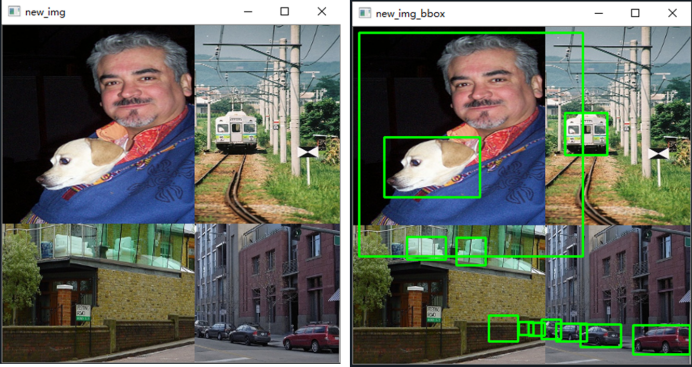
Mosaic
Mosaic技术的基本思想是将多张图像拼接成一张图像,从而在一张图像中包含更多的目标,增加目标的数量和多样性。其步骤就是首先随机选取四张图像,将每张图像缩放到相同的大小,然后通过拼接成一张大图像,形成类似于马赛克的效果。
最重要的来了,Mosaic和Mixup需要再训练结束前的15个epoch关掉。因为Mosaic+Mixup生成的训练图片,脱离自然图片的真实分布的,而且Mosaic大量的crop操作会带来很多不准确的标注框。提前关闭Mosaic和Mixup,能够使检测器避开不准确标注框的影响,在自然图片的数据分布下完成最终的收敛。
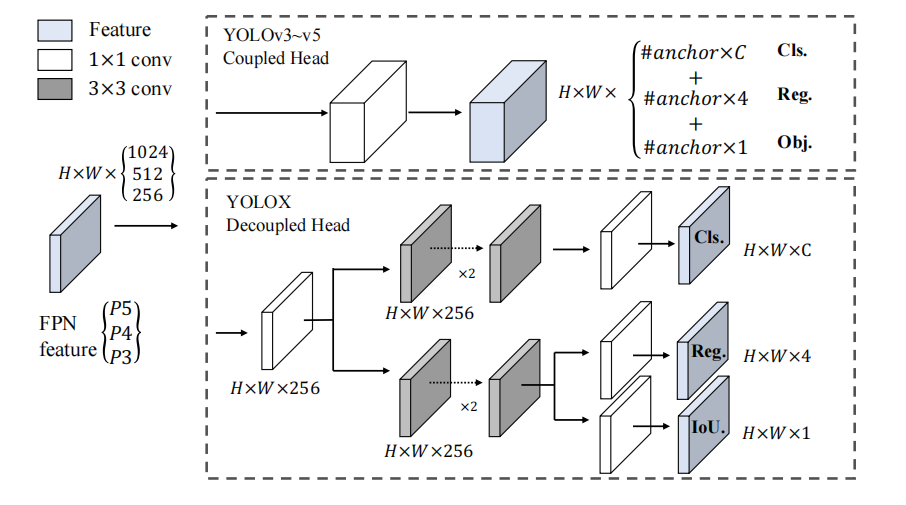
Decoupled Head
在YOLO v3-v5版本中,所使用的head头同时预测输出目标位置和类别,每个特征图的预测张量为$N × N × [ 3 ∗ ( 4 + 1 + c l a s s e s _ n u m ) ] ,其中 ,其中 ,其中N$是特征图的大小。这种被称为耦合头(Coupled head),它的设计思路简单,仅需要几个全连接层或者卷积层即可。这样虽然简单但是会影响到模型的性能,为什么,因为这样的话分类和回归任务是共用head的参数进行预测的,但是分类和回归任务是存在差异的,但是其共用同一组参数来预测不同的任务,势必会损耗性能。
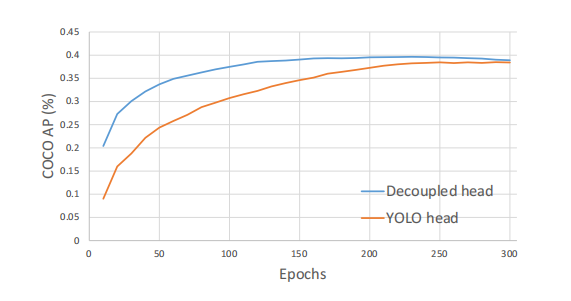
所以在YOLOX中使用的解耦合头(Decoupled head),使用不同的分支分别预测目标位置和类别信息。首先先使用一个 1 × 1 1×1 1×1的卷积减少通道维数,然后并行分类和回归两个分支,每个分支堆叠两个 3 × 3 3×3 3×3的卷积。分类分支用来预测类别信息;回归分支用来输出bbox的位置信息。在回归分支中,添加了IoU 分支。通过将两个不同的任务进行解耦,分开预测,从而提升模型的性能。
同时实验也是证明了其能够更快收敛,并且提升模型的检测精度(能带来4.2%AP提升),
anchor free
在YOLO v1-v5版本中,都是使用的是基于anchor的方法进行检测的。什么意思呢?就是为了能够取得更好的性能,在训练之前,通常都会通过聚类分析训练数据集的方式确定anchor box的大小,确定的anchor box一般仅仅适用于该数据集,通用性不强。而且Anchor的存在增加了检测头的复杂度以及生成结果的数量。所以在使用其进行训练前,我们都会提前使用聚类算法来分析其anchor box的大小,再进行训练。
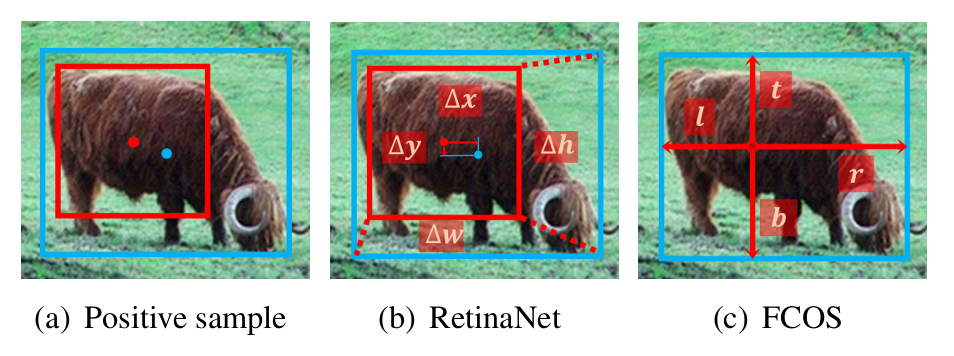
而YOLOX采用了anchor-free(无锚点)的检测方法,这是一种不同于传统YOLO系列及其他一些目标检测模型中使用固定anchor boxes的设计。在anchor-free方法中,模型直接预测目标物体的中心点及其宽高,而不是基于预设的anchor boxes进行偏移和尺寸调整。这一改变简化了模型结构,降低了超参数调优的复杂性,并有可能提升模型的灵活性和准确性。
实现机制:在anchor-based的方法中我们是通过预测相对于预设的anchor的偏移量的,但是在anchor-free中,我们直接预测其中心点(x,y),然后预测其宽和高(w,h),通过这样的方式避免了anchor-based的方法所需要来预设anchor的弊端。
并且通过anchor-free的方法能有效的减少参数量。举个例子来说,通过前面的backbone以及fpn结果,所提取出来的进入head检测头的特征图的大小分别为52×52、26 × 26 和13 × 13(三个尺度的特征图大小),使用anchor-free的方法进行预测的话,我们只需要预测1 × 3549 × 85 个结果,其中3549表示一共有3549个像素,而我们只需要对每个像素预测1个结果即可,85表示80个类别,4个bbox参数(中心点和宽高),1表示IoU。
但是对于anchor-based来说就是3 × 3549 × 85 对每个像素预测三个结果,其预测结果是anchor-free的3倍。
通过下图我们可以明显的看出二者的不同。
SimOTA
在这3549个预测框中,其中有2704个预测框所对应的锚框的大小为8 × 8; 有676个预测框所对应的锚框的大小为16 × 16;有169个预测框所对应的锚框的大小为32 × 32。这3549个预测框中,只有少部分是正样本,绝大多数是负样本,那么哪些是正样本?如何将正样本预测框挑选出来呢?思路就是将这3549个预测框和图片上所有的gt框(ground truth)进行关联,从而挑选出正样本,这种关联方式,被称为标签分配。
首先通过提取落在gt bboxes 一定范围内的所有候选框。然后就是SimOTA求解。标签分配问题可以转换为标准的OTA问题,但Sinkhorn-Knopp算法需要多次迭代才能求得最优解,官方发现该算法会导致25%的额外训练时间,因此采用简化版的OTA方法,SimOTA,求解近似最优解。
接下来详细讲解什么是SimOTA。
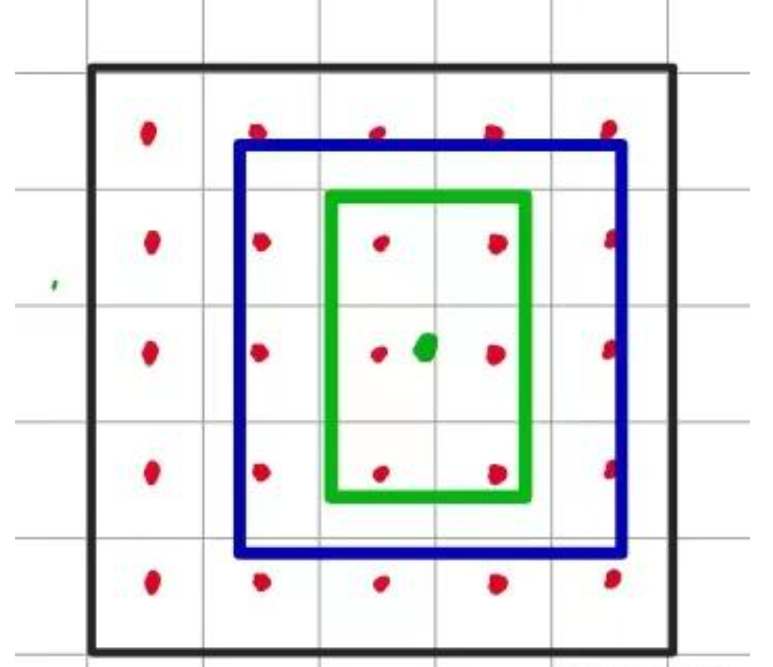
in_boxes 和 in_center
首先我们需要先来了解两个概念,什么是**in_boxes (anchor point在ground truth中)**和 in_center(anchor point在ground truth的展开域中)。如下图所示,红色的点为anchor point,绿色的框为gt,蓝色的框为gt展开域。其中落入gt中的anchor即为in_boxes,落入蓝色框中的anchor point即为in_center。
这里为方便理解我们以尺度20×20为例。在20×20的feature map上总共有400个anchor,每一个anchor都会有一个输出(num_class+4+1)。如下图所示,这张图片中总共有三个gt。
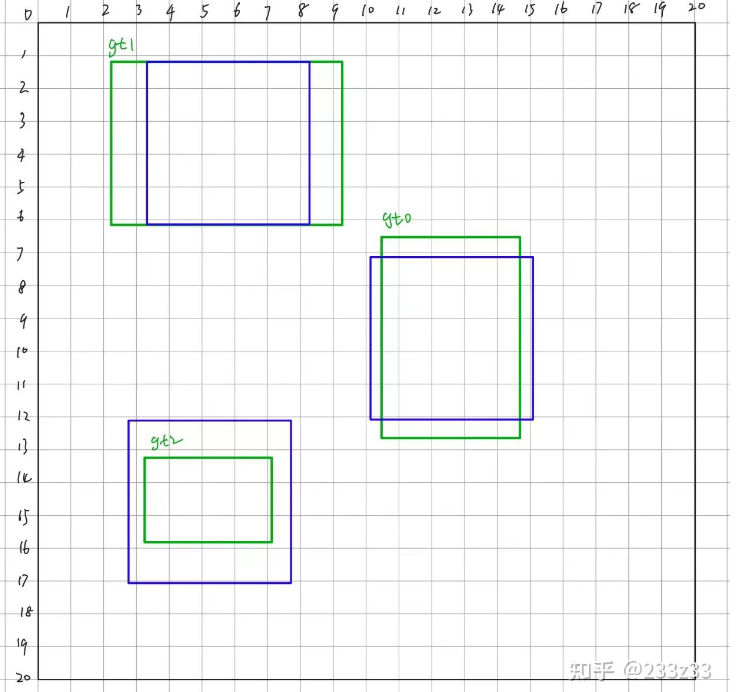
根据刚刚我们所说的in_boxes,我们可以挑选出anchor point落在gt中的网格,同理也挑选出anchor point落在gt展开域中的网格,通过取两者的并集,我们可以得到一个长度为400的Bool型的tensor–fg_mask(foreground mask,前景信息),形如[False, False, False, True, True, … ,False, False],其中有95个True,如下图所示。
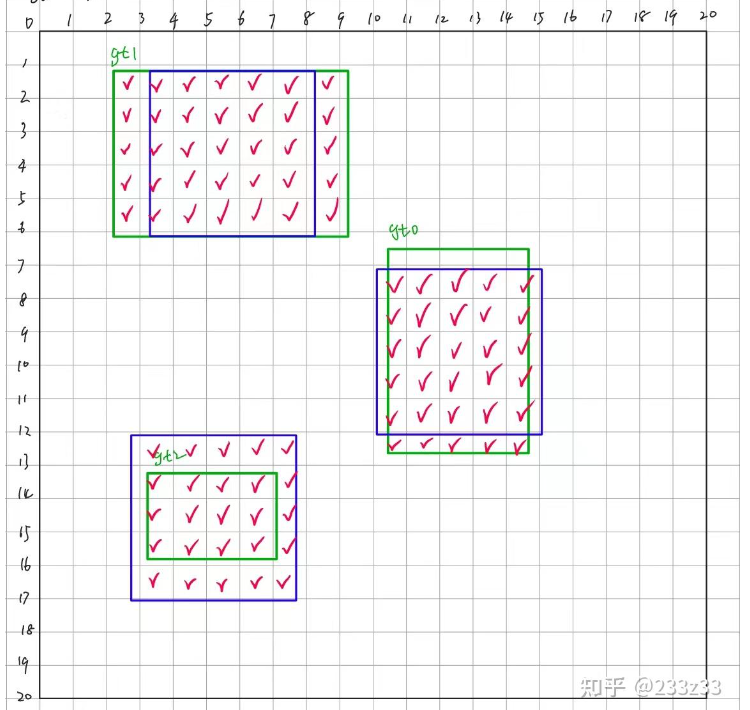
然后我们同样的按照刚才的方式,只不过这回我们取两者的交集,如下图。这样我们可以得到个shape为3×95的Bool类型的tensor–is_in_boxes_and_centers。其中is_in_boxes_and_centers[i]代表第i个gt的in_boxes & in_centers。这里可能有些人有点小疑问,为什么需要每个gt都对应着一个,不能直接一个表示不同gt的in_boxes & in_centers吗?这个图上是可以的,但是实际我们在检测中,难免会出现部分重叠的情况,那么true所表示的到底是在还是不在或者到底是表示的在哪个呢?所有我们需要每个gt对应一个才可以。
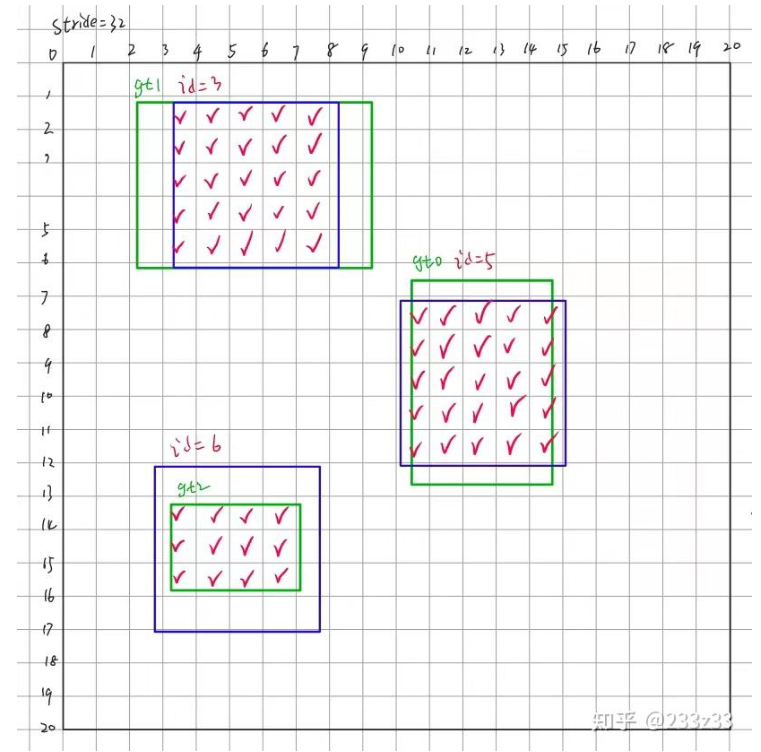
到此为止,先梳理一下,目前以COCO(80类)中某张图片为输入,得到20*20的feature map,图片中有3个gt,现在我们有以下信息:
- 网络输出的类别信息,400*80的Tensor——pred_cls;
- 网络输出的置信度信息,400*1的Tensor——pred_obj;
- 网络输出的box回归信息,400*4的Tensor——pred_box;
- 20×20 feature map上得到的前景信息,长度为400的Bool类型Tensor——fg_mask,其中为True的为前景,其余False部分为背景,有95个True
- 20×20 feature map上得到的各个gt的前景信息,3×95的Bool类型Tensor——is_in_boxes_and_centers
这边看下面的图结合理解:

现在我们需要根据前景信息fg_mask对网络输出进行初步的筛选(网路输出20*20的feature map上400个点位,每个点位都有类别信息、置信度信息、回归信息,这些信息大部分都是没有用的)
计算cost矩阵
首先来计算iou loss损失:
# 计算3个gt与95个网络输出框(pred_box)的iou
pair_wise_ious = bbox_iou(gt_bboxes, box_pred) # 得到一个3*95的iou矩阵
# 计算iou loss损失
pair_wise_ious_loss = -torch.log(pair_wise_ious + 1e-8)
# 3*95的iou loss矩阵iou矩阵如图

然后我们来计算cls loss损失:
# 先对3个gt的cls信息进行one hot编码
gt_cls = F.one_hot(gt_class,80) # 3*95*80
# 得到类别信息
cls_preds_ = cls_pred * obj_pred # 3*95*80
# 计算cls loss
pair_wise_cls_loss = F.binary_cross_entropy(cls_preds_ , gt_cls) # 3*95
然后我们计算SimOTA关键的cost矩阵:
cost = (pair_wise_cls_loss + 3.0 * pair_wise_ious_loss + 100000 * (~is_in_boxes_and_centers))
-
pair_wise_cls_loss就是每个样本与每个GT之间的分类损失
-
pair_wise_ious_loss是每个样本与每个GT之间的回归损失
-
is_in_boxes_and_center代表那些落入in_boxes 和 in_center交集内的样本,即上图中橙色勾对应的样本,然后这里进行了取反~表示不在in_boxes 和 in_center交集内的样本。接着又乘以100000.0,也就是说对于in_boxes 和 in_center交集外的样本cost加上了一个非常大的数,这样在最小化cost过程中会优先选择in_boxes 和 in_center交集内的样本。
简而言之,我们根据fg_mask得到400个anchor point里面有95个是初步认定的正样本,我们根据它们与gt box的iou、类别损失、前景背景信息得到一个3*95的cost矩阵,表示每一个gt与每一个正样本之间的成本cost(成本cost越小优先级越高)。cost矩阵如图所示。

dynamic_k_matching算法
-
首先我们来看,cost矩阵shape为3*95,我们取n_candidate_k = min(10, 95) = 10;
-
然后我们在在iou矩阵中,根据n_candidate_k=10,取对于每一个gt,取其与95个pred box的所有iou里最大的10个并且求和,得到dynamic_k示意图如下

- 然后我们在根据dynamic_k,从cost矩阵中,GT0那一行找出4个最小的值,GT1那一行找出3个最小的值,GT2那一行找出2个最小的值,示意图如下;

上图中,A3与GT0匹配成功,A91与GT2匹配成功,A92与GT2匹配成功,A4与GT1匹配成功(为什么不是GT0? 每一个anchor只能与一个GT匹配成功,如果出现A4与GT0和GT1同时被选中的情况,取cost最小的),A5与GT0匹配成功,A6与GT0匹配成功。
- 最后我们再根据匹配成功的信息,得到matching matrix (shape与iou矩阵和cost矩阵相同),如下:
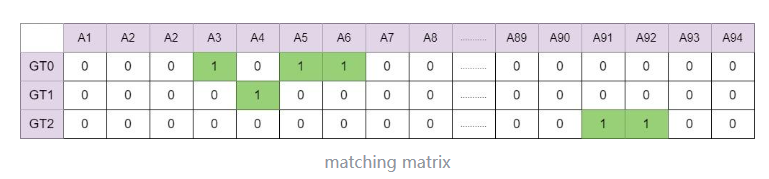
matching matrix中就是最终的样本分配的结果,从图中可以看见的部分可以得知,最终正样本为A3、A4、A5、A6、… 、A91、A92。
网络架构
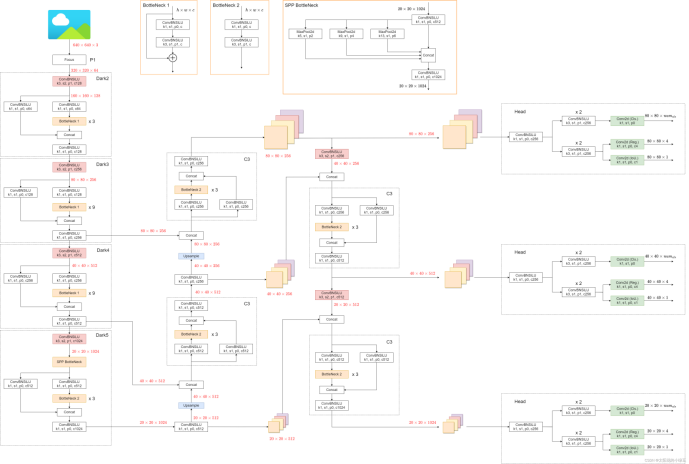
从图中我们就可以看出YOLOX的标准的模块化结构设计了,总共可分为三部分backbone(用于提取出高级语义特征),neck(双通道的FPN融合多尺度的特征),head(用于对特征图进行检测)。其中各个的部分都是可以进行更换的,比如backbone部分,想的话也可以换成别的网络,都是十分便利的。
参考资料
【YOLO v4 相关理论】Data augmentation: MixUp、Random Erasing、CutOut、CutMix、Mosic_yolo mixup-CSDN博客

















 743
743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









