






《大数据开发语言Scala入门》
Scala
1 基础
Scala中使用方法而不是强制类型转换来做数值类型之间的转换
没有++,——因为Int类是不可变的
a 方法 b 与 a.方法(b) 一样
数学函数位于 scala.math 中,可以像函数一样使用,实际上应该是伴生对象的方法
一般情况下,没有参数并不改变当前对象的方法不带圆括号
apply
使用伴生对象的apply方法是scla中构建对象的常用方法
2 控制结构和函数
条件表达式是有值的,可以分支的类型不一样,其结果类型为分支的公共超类型。
:paste 用以REPL中粘贴多行代码,避免短视
if (x>0) 1 else -1
if (x>0) 1 // if (x>0) 1 else ()
跨行:可以使用括号,未结束的操作符
块语句是指位于 {} 中的语句序列,包含一系列表达式,结果也是表达式,最后一个表达式的值就是语句块的值
赋值本身是没有值的,其值是 Unit 类型的 () 值
输入输出:print println printf, readLine readInt
while / do while 循环:
while (n>0){...}
for 循环
for (i <- 1 to 6) ..
for (i <- 1 to 6; from = 4-i;j <- from until 9
if i!=j ;)
for (...) yield {}`
对于递归函数,必须指定返回类型
默认参数,带名参数与Python接近
变长参数: def sum(args:Int*) …
使用: sum(1 ot 5:_*)
函数体包含在花括号中但没有等号的返回类型是Unit,称为过程,不返回值,调用它只是为了副作用
当val被声明为lazy时,初始化将被推迟,直到首次对它取值
懒值也有开销,访问时都有线程安全方式检查该值是否已经被初始化
val words = //当时初始化lazy val wrods = //第一次使用时初始化def words = //每次使用时均求值
异常表达式的类型是Nothing,在if/else中,则返回类型是非Nothing分支的类型
异常捕获使用模式匹配
tray catch finally
3 数组相关操作
若长度固定使用Array,可能有变化使用ArrayBuffer
-
val nums = new Array[Int](10) -
val nums2 = Array(1,2,3);nums(0)=4 -
import scala.collection.mutable.ArrayBuffer -
val b = ArrayBuffer[Int]() / new ArrayBuffer[Int] -
b += 1 -
b += (1,3,4) -
b ++= Array(4,5,6) -
b.trimEnd(5) -
b.insert(2, x)/insert(2, x,y,z) -
b.remove(2)/remove(2,3) -
b.toArray / a.toBuffer
提供初始值时不要使用new
用()来访问元素
用for (elem <- arr) 来遍历数组
(0 until (a.length,2)).reverse
用 for (elem <- arr if …) yield …来将数组转变为新数组
集合类型与原集合相同,Array to Array,Buffer to Buffer
可以使用 .filter().map() 替换
var first = trueval indexes = for (i <- 0 until array.length if first || array(i)>=0) yield {if (array(i)<0) first=false;i}for (i <- 0 until indexes.length) {a(i)=a(indexs(i))}a.trimEnd(a.length - indexs.length)
常见函数
sum /max /min /b.sorted(\_ < \_)(返回排序后的)
scala.util.Sorting.quickSort(a) (不能使用在ArrayBuffer)
a.mkString( str )/ .mkString(a,b,c)
多维数组:数组的数组来实现
val m = Array.ofDimInt
m(3)(4) = 7
val t = new ArrayArray\[Int\]
for (i <- 0 to 9){t(i)=new ArrayInt}
Scala数组和Java数组可以互操作;用ArrayBuffer,使用scala.collection.JavaConversions中的转换函数
4 映射和元组
对偶是n=2的元组
创建、查询和遍历映射
-
val m = Map('a'->3, 'b'->2, 'c'->4) //->构建对偶 -
val m = Map(('a',3),('b',2), ('c',4)) -
val m = scala.collection.mutable.Map(...) -
val m = new scala.collection.mutable.HashMap[String,Int] -
m('a') -
if (m.contains('a')) m('a') else 0 -
m.getOrElse('a', 0) -
m.get('a') //返回一个Option对象,值或者None -
m += ('c'->4, 'e'->7) -
m -= 'a' -
val m3 = m1 + ('c'->3...) //新旧结构会共享 -
for ((k,v) <- m) .... -
for (k <- m.keySet) ... -
for (v <- m.values) ... -
for ((k,v) <- m) yield (v,k) -
scala.collection.immutable.SortedMap //树Map -
scala.collection.mutable.LinkedHashMap //按插入顺序处理
需要从可变和不可变的映射中作出选择
默认情况下获得哈希映射,可以指明要树形映射
可以很容易在scala与java映射之间切换
import scala.collection.JavaConversions.mapAsScalaMap
元组可以用来聚集值
元组是通过将单个的值包含在圆括号中构成的,可用于返回不止一个值的情况
val t = new Tuple3[Int,Int,String]t._1, t._2, t._3val (first, sencond, _) = t//匹配模式获得值
zip操作
zip将Array合并成元组的Array
keys.zip(values).toMap
5 类
所有类都具有公有可见性
带getter和setter的属性
getter和setter分别叫做 x 和 x_=,可以自己重定义
def age = privateAgedef age_=(age: Int) {privateAge = age}
统一访问原则:某个模块提供的所有服务都应该是通过统一的表示法访问到,不管其是存储还是通过计算实现的
- 字段是私有的,则getter和setter方法也是私有的
- 字段是 val ,则只生成getter
- 不需要getter和setter,则可以设置 private[this]
- 自己可更改,外界不可改,则实现私有变量,访问函数
方法可以访问该类的所有对象的私有变量,包括其他实例
使用 private[this] … 则只能访问本实例this的字段
将字段标注为 @BeanProperty 可生成Java的默认访问方法getXX, setXX
import scala.reflect.BeanPropertyclass Person{-
`@BeanProperty var name: String = _` }
辅助构造器的名字为 this;每个辅助构造器都必须以一个先前已经定义的其他辅助构造器或主构造器的调用开始。没有显式定义主构造器则自动拥有一个无参数的主构造器
def this(name: String){
this()
this.name = name
}
主构造器:与类定义交织在一起,参数直接放在类名之后。参数被编译成字段,其值被初始化成构造时传入的参数。主构造器会执行类定义中的所有语句
class Person(val name:String,private val age:Int){...}
不带val或var的参数如果在类中至少被一个方法使用,则其升级为字段,相当于private[this] val。否则就仅是一个普通参数,供主构造器中代码访问。
可以在任何语法结构中内嵌任何语法结构。类中定义类。
每个实例都有它自己的内嵌类(泛型导致,实例有可能是不一样类型,其内嵌类也有可能不一样),进行操作时需要注意。需要公用,则可将其移入伴生对象中。或者使用类型投影。 外部类.this 访问外部类的 this 引用。
class NetWork(val name:Int){ outer => //指向 NetWork.this`
class Member(){
... // use outer.name
}
}
6 对象
用对象作为单例或存放工具方法/常量或高效共享不可变实例
使用object创建单例,对象的构造器在其首次调用时指向。如果从未被使用,则其构造器不会被执行。其本质上可拥有类的所有特性,除了不能提供构造器参数。
类可以拥有一个同名的伴生对象
类与其伴生对象可以相互访问私有特性,必须存在同一个源文件中。
对象可以扩展类或者特质
其结果是一个扩展了指定类以及特质的类的对象,同时拥有在对象定义中给出的所有特性。
对象的apply方法通常用来构造伴生类的新实例
通常会定义和使用对象的apply方法,遇到如下形式的表达式,apply方法会被调用。返回的是伴生类的对象。可以省略使用 new
object(para1, ... paran)
如果不想显式定义main方法,可以扩展App特质的对象
执行程序必须从某个对象的main方法开始
object Hello{
def main(args:Array[String]){
...
}
}
object Hello extends App{
if (args.length ...)...
}
可以通过扩展Enumeration对象来实现枚举
object TrafficLightColor extends Enumeration{
val Red, Yellow, ... = Value
val Red = Value(0, "stop")
val Red = Value(10) //类型为TrafficLightColor.Value
val Red = Value("Stop") //每次调用Value都返回新实例
type TrafficLightColor = Value //类型别名
}
import TrafficLightColor._
for (c <- TrafficLightColor.values) ...
TrafficLightColor(0)
TrafficLightColor.withName("Stop")
7 包和引入
包可以像内部类那样嵌套
源文件的目标与包之间没有强制的关联关系。可以在一个文档中定义多个包中的内容。
包路径不是绝对路径
包支持嵌套,可以访问上层作用域中的名称。如果需要访问非直接嵌套域中的包,则可以使用绝对包名 root. …
包声明链x.y.z并不自动将中间包x和x.y变成可见
package com.horstman.xx.xx{
// com._, horstman_, xx_ 是不可见的
}
位于文件顶部不带花括号的包声明在整个文件范围内有效
package x.y.z
package m
//相当于
package x.y.z{
package m{
...
}
}
包对象可以持有函数和变量
包可以包含类、对象和特质,但不能包含函数或变量的定义。Java虚拟机的限制。每个包可以有一个包对象,需要在父包中定义,且名字与子包一样
package x.y.x
package object m{
val xname =...
} //Java虚拟机将其编译成带有静态方法和字段的JVM类,名为package.class
package m{
class P{
var name = xname
}
}
可以通过private[packageName]来设置可见性
引入语句的目的是使用更短的名称而不是较长的名称
引入语句可以引入包、类和对象
引入语句可以出现在任何位置,将其放入需要的地方,可以减少可能的名称冲突
引入语句可以重命名和隐藏特定成员
选取器 .{A, B}
重命名 .{A=>Z, C}
隐藏 .{A=>_, _}
java.lang、scala、Predef总是被引入,每个文件默认以以下代码开头
import java.lang._
import scala._ //可覆盖前面一个,与用户引入不同
import Predef._
8 继承
8.1 扩展类
使用extends
可以将类声明为final,这样它就不会被扩展
8.2 重写方法
重写非抽象方法必须使用override修饰符
- 避免拼写错误
- 避免新方法中使用错误的参数类型
- 在超类中引入新的方法时,可以检查是否与子类方法相冲突
调用超类方法与Java一样,使用super
8.3 类型检查和转换
使用isInstanceOf方法测试类型
if (p.isInstanceOf[Boss]) {
val s = p.asInstanceOf[Boss]
}
- p为该类或者其子类,返回true 成功
- P为null,返回false null
- P非该类或其子类,返回false 异常
判断一个对象只是某类而非子类
if (p.getClass == classOf[Boss])
使用模式匹配
p match{
case s:Boss =>
case _ =>
}
8.4 受保护字段和方法
将字段或则方法声明为protected,成员可以被任何子类访问
还提供了protected[this],访问权限制在当前对象
8.5 超类的构造
只有主构造器才可以调用超类的构造器
class A(name:string, age:Int) extends B(name, age)
8.6 重写字段
可以用同名的val字段重写一个val(或不带参数的def)
- def只能重写另一个def
- val只能重写另一个val或不带参数的def
- var只能重写另一个抽象的var
8.7 匿名子类
var alien = new Person("Fred"){
def greeting = "....."
}
//创建一个结构类型的对象,新类型为 Person{def greeting:String}
8.8 抽象类
省区方法体的方法,抽象方法
只要存在一个抽象方法,就必须声明为abstract
重写超类的抽象方法时,不需要使用override方法
8.9 抽象字段
抽象字段是指没有初始值的字段
var id: Int //生成了抽象的getter/setter方法,不带字段
class B(var id:Int) extends AbstractClass {...}
8.10 构造顺序和提前定义
子类重写超类构造时所需的变量,则可以出现异常。
构造器中不应该依赖val的值
- 将val声明为final,安全不灵活
- 超类中将val声明为lazy,安全不高效
- 在子类中使用提前定义语法
class Ant extends{override val range=2} with Creature`
C++中构造函数虚表先是基类然后才是子类,因此无法改变基类行为,Java允许在超类的构造方法中调用子类的方法。
8.11 继承层级
Any AnyVal Unit/Int/Float…
Any AnyRef …
Null 类型唯一实例 null
Nothing 类型无实例, Nil的类型是List[Nothing]
8.12 对象相等性
AnyRef的eq方法比较两个引用是否指向同一个对象,equals调用eq。确保方法参数为Any。
9 文件与正则表达式
9.1 读取行
source = scala.io.Source.fromFile(...)
iters = source.getLines //迭代器
iters.toArray/ toBuffer
source.mkString
9.2 读取字符
for (c <- source)
iter = source.buffered
while (iter.hasNext){
if (iter.head)... iter.next()
}
9.3 读取词法单元和数字
val tokens = source.mkString.split("\\S+")val numbers = for (w <- tokens) yield w.toDoubelval numbers = tokens.map(_.toDouble)ReadInt
9.4 从URL或其他源读取
Source.fromURL(....)Source.fromString(....)Source.stdin
9.5 读取二进制文件
通过Java库读取
val file = new File(filename)val in = new FileInputStream(file)val bytes = new Array[Byte](file.length.toInt)in.read(bytes)in.close()
9.6 写入文本文件
val out = new PrintWriter(...)
or (i <- 1 to 100) out.println(i)
out.close()
使用printf需要将其转为AnyRef,可以使用string的format方法
9.7 访问目录
import java.io.File
def subdirs(dir: File):Iterator[File] = {
val children = dir.listFiles.filter(_.isDirectory)
children.toInterator ++ children.toInterator.flagmap(subdirs _)
}
9.8 序列化
9.9 进程控制
import sys.process._
"ls -al .."!
sus.process包含一个从字符串到ProcessBuilder对象的隐式转换,!就是执行的该对象。!!使用字符串的形式返回,#|作为管道。#>重定向 #>> #<
9.10 正则表达式
使用字符串.r方法构造Regex类对象
.findAllIn方法返回所有匹配项的迭代器,可以在for循环中使用
.findAllIn.tpArray
.findFirstIn
.findPrefixOf
.replaceFirstIn
.replaceAllIn
9.11 正则表达式组
val pattern = "(..) (..)".r
pattern(x, b) = "...."
for (pattern(x,b) <- pattern.findAllIn(....)
10 特质
10.1 为什么没有多重继承
多基类中共同的元素
虚拟基类
10.2 当做接口使用的特质
特质中未被实现的方法默认就是抽象的,需要特质不止一个,可以使用with关键字来添加额外的特质
trait Logger{
def log(msg:String) //抽象方法
}
10.3 带有具体实现的特质
特质中的方法也可以是具体的
如果特质中有具体的方法,当特质发生改变时,所有混入该特质的类都必须重写编译
10.4 带有特质的对象
可以在类定义时添加特质
而在对象中混入具体实现
class X extends Y with Logged{...}
val x = new X with BetterLogged
10.5 叠加在一起的特质
可以为类或对象添加多个互相调用的特质,从最后一个开始
- 子类会调用父类的同名函数
- 从右到左
10.6 在特质中重写抽象方法
写的时候往往会调用父类的同名函数,因为不知道实际调用时的次序,如果父类是抽象方法,则编译会出错
abstract override def log(msg:String){
super.log(new .....)
}
10.7 当做富接口使用的特质
在特质中使用具体和抽象方法十分普遍
10.8 特质中的具体字段
特质中的字段可以是具体的也可以是抽象的,混入该特质的类自动获得一个字段与之对应。该字段不是继承,只是简单加入子类中。由于Java限定; 超类只有一个,因此特质的字段,就相当于处于子类的。
10.9 特质中的抽象字段必须重写
1)可以将抽象字段定义到类中
2)也可以将其定义到具体的对象中
不需要写 override
10.10 特质构造顺序
构造器顺序
- 首先调用超类的构造器
- 特质构造器在超类构造器之后、类构造器之前执行
- 特质由左到右被构造
- 每个特质当中,父特质先被构造
- 如果多个特质共有一个父特质,而那个父特质已经被构造,则不会被再次构造
- 所有的特质构造完毕,子类被构造
构造器的顺序是类的线性化的反向
10.11 初始化特质中的字段
特质不能有构造器参数。
采用抽象字段可能会有问题,如果构造器中需要使用该字段的话,其初始化在子类。
-
提前定义
val x = new {val filename = ...} with Account with FileLogger
class X extends {val filename = ...} with Account with FileLogger{} -
使用懒值
将通过变量值生成对象的对象设置为lazy,则会在第一次调用时创建,缺点不高效
10.12 扩展类的特质
特质也可以扩展类,该类会自动成为所有混入该特质的超类。同时如果其中有多个超类,如特质的超类和子类的超类是超类关系,则没有问题。
10.13 自身类型
当特质代码以如下代码开头定时,它就只能被混入指定类型的子类
trait ... {this: 类型 => ...}
自身类型也可以处理结构类型,这种结构只给出类必须拥有的方法,而不是类的名称
trait xx extends Logged{
this: {def getmessage():String} =>
...
}
10.14 背后发生了什么
- 只有抽象方法被简单变成Java接口
- 有具体方法,则除了接口外,Java生成一个伴生类,该类用静态方法存放特质的方法
- 字段对应到接口中的抽象的getter和setter方法,当类实现该特质时,字段被自动加入
11 操作符
11.1 标识符
变量、函数、类等的名称统称为标识符
可以使用很多字符
反引号中包含几乎任何字符序列
11.2 中置操作符
a 标识符 b, 标识符代表一个带有两个参数的方法(一个隐式参数和一个显式参数)。
11.3 一元操作符
a 操作符,为后置操作符
+-!~可以作为前置(prefix)操作符,被转换为unary\_操作符的方法调用
11.4 赋值操作符
a 操作符= b / a = a 操作符 b
11.5 优先级
11.6 结合性
所有操作符都是左结合的,除了以:结尾的操作符和赋值操作符
1::2::Nil是右结合的,用于构造列表
右结合的二元操作符是其第二个参数的方法
2::Nil === Nil.::(2)
11.7 apply和update方法
如果f不是函数和方法则可将其扩展到apply方法上
f(arg1, arg2 ..) ---> f.apply(arg1, arg2 ..)
如果其出现在赋值语句的等号左边,则有如下,用于数组与映射
f(arg1...) = value ---> f.update(arg1 ... ,value)
apply方法同样被经常用在伴生对象中,用来构造对象而不用显式地使用new
object F(){def apply(n:Int) = new F(n)}
11.8 提取器
提取器是带有unapply方法的对象,可以将unapply方法当做是伴生对象中apply方法的反向操作。接受对象,并从中提取值,而这些值是当初用来构建该对象的值
val F(x, y) = ... // F.unapply(...)
case Currency(amount, "USD") => ...
11.9 带单个参数或无参数的提取器
没有单值,只能放回一个目标类型的Option
def unapply(intput:string):Option\[Int\]=...
object IsCompound{
def unapply(input:String) = input.contain("....")
}
author match{
case Name(first, last @ IsCompound()) =>
case Name(first, last) =>
}
11.10 unapplySeq方法
def unapplySeq(input:String):Option\[Seq\[String\]\]
author match{
case Name(first,last) =>
case Name(f,m,l)=>
case Name(f,'xx','yy',l)=>
}
12 高阶函数
12.1 作为值的函数
import scala.math.\_
val fun = ceil \_ // \_表示确实指的杉树,而不是碰巧忘记给参数
可以调用
可以传递,fun是一个包含函数的变量
12.2 匿名函数
val trip = (x:Double)=>3\*x
与 def trip(x:Double) = 3\*x一样
12.3 带函数参数的函数
def valueAtOne(f:(Double)=>Double)) = f(2.5) //((Double)=>Double)=>Double
valueAtOne(ceil \_) / valueAtOne(sqrt \_)
12.4 参数(类型)推断
valueAtOne((x)=>3\*x)
valueAtOne(x=>3\*x)
valueAtOne(3\*\_)
val fun = 3\*(*: Double)
val fun:(Double)=>Double = 3\**
12.5 一些有用的高阶函数
foreach/map/filter/reduceLeft/sortWith
12.6 闭包
12.7 SAM转换
12.8 柯里化 currying
将原来接受两个参数的函数变成新的接受一个参数的函数的过程。新的函数返回一个以原有第二个参数作为参数的函数
scala支持简写来定义柯里化函数
def mulOneAtTime(x:Int)(y:Int) = x*y
12.9 控制抽象
def runInThread(block:()=>Unit){
new Thread{
override def run(){block()}
}.start()
}
runInThread{()=> println....}
def runInThread(block:=>Unit){ //换名调用表示法
new Thread{
override def run(){block}
}.start()
}
runInThread{ println....}
def until(condition:=>Blooean)(block:=>Unit){
if (!condition){
block
until(condition)(block)
}
}
var x = 10
until (x == 0){
x -= 1
...
}
12.10 return表达式
不需要使用return语句来返回函数值,函数的返回值就是函数体的值
如果需要在带名函数中使用return的化,则必须给出其返回类型
def indexOf(str:String, ch:Char):Int = {
var i = 0
until (i == str.length){
if (str(i) == ch) return i
i += 1
}
return -1
}
13 集合
13.1 主要集合特质
val iter = coll.iterator
while (iter.hasNext){
dowith(iter.next())
}
13.2 可变与不可变集合
13.3 序列
Vector是ArrayBuffer的不可变版本
13.4 List
13.5 可变列表
LinkedList
13.6 集合
13.7 流
21 隐式转换和隐式参数
21.1 隐式转换
是指哪种以implicit关键字声明的单个参数的函数,将被自动应用,将值从一种类型转换为另一种类型,最好采用长命名 oldtype2newtype
21.2 利用隐式转换丰富现有类库的功能
21.3 引入隐式转换
- 位于源或目标类型的伴生对象中的隐式函数
- 位于当前作用域可以以单个标识符指代的隐式函数
- 可以引入局部化以尽量避免不想要的转换发生
implicits查看所有引入的隐式成员
21.4 隐式转换规则
- 当表达式的类型与预期的类型不同时
- 当对象访问一个不存在的成员时
- 当对象调用某个方法,而该方法的参数声明与传入参数不匹配时
以下情况不会尝试考虑隐式转换
- 如果代码能够在不使用隐式转换的前提下通过编译,则不会使用隐式转换
- 编译器不会尝试同时执行多个转换 c1(c2(a))*b
- 存在二义性性的换行是个错误, c1(a)*b a*c2(b)都是合法的,二义性规则只适用于被尝试转换的对象
21.5 隐式参数
如果在参数列表中设置了隐式参数,则当调用时不传递该参数,则会自动寻找为该类型的隐式值
- 在当前作用域所有可以用单个标识符指代的满足类型要求的val和def
- 与所要求类型相关联的类型的伴生对象。相关联的类型包括所要求类型本身以及它的类型参数(如果它是一个参数化的类型的话)
def x(implicit delims:String, x:String)
21.6 利用隐式参数进行隐式转换
order是隐式参数,省略情况下可以直接比较
def smaller[T](a:T,b:T)(implicit order: T => Order[T]) = if (order(a)<b) a else b
order是隐式函数,且单个参数,单标识符出现,则其可以用于隐式转换,因此函数调用中可以去掉
def smaller[T](a:T,b:T)(implicit order: T => Order[T]) = if (a<b) a else b
21.7 上下文界定
类型参数可以有一个形式为T:M的上下文界定,其中M为泛函类型,要求作用域中存在一个类型为M[T]的隐式值,可以使用在该类中
class Pair[T:Ording](val first:T,val second:T){
def smaller(implicit ord:Ording[T]) = {
if (ord.compare(first, second)<0) first else second
}
}
// 可以通过Predef中的implicitly获取该值,代替上面的ord
// implicitly[Ording[T]]
// 定义如下 def implicitly[t](implicit e:T) = e
class Pair[T:Ording](val first:T,val second:T){
def smaller = {
import Ordered._
if (first < second) first else second
}
}
implicit object PonitOrdering extends Ordering[Point]{
def compare(...)
}
21.8 备注
大数据工程师系列专栏: 面试真题、开发经验、调优策略
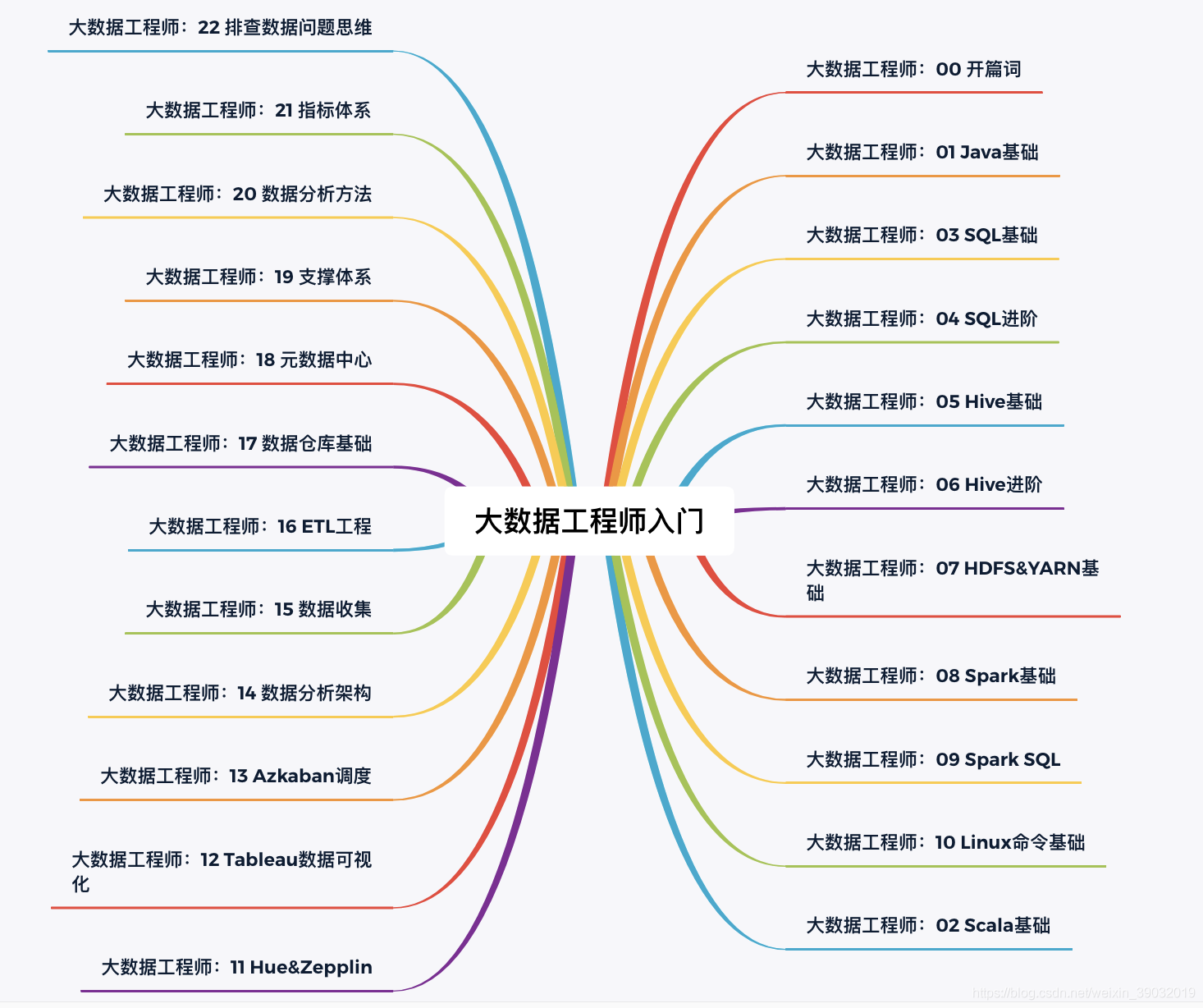
大数据工程师知识体系:
大数据时代已经到来
最近几十年,高速发展的互联网,渗透进了我们生活的方方面面,整个人类社会都已经被互联网连接为一体。身处互联网之中,我们无时无刻不在产生大量数据,如浏览商品的记录、成交订单记录、观看视频的数据、浏览过的网页、搜索过的关键词、点击过的广告、朋友圈的自拍和状态等。这些数据,既是我们行为留下的痕迹,同时也是描述我们自身最佳的证据。
2014年3月,马云曾经在北京的一次演讲中说道:“人类正从IT时代走向DT时代”。7年过去了,正如马云预想的那样,大数据时代已经到来了。
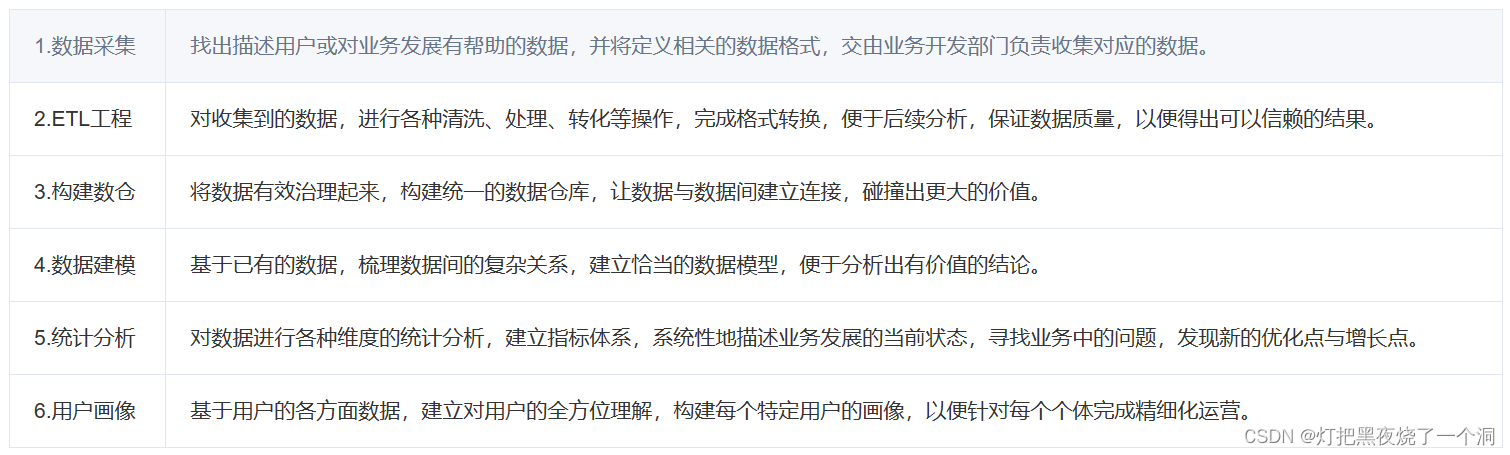
大数据工程师的工作内容是什么?
而大数据时代,有一个关键性的岗位不得不提,那就是大数据工程师。想必大家也会好奇,大数据工程师,日常是做什么的呢?
大数据工程师必备技能
那么,问题来了,如果想成为一名大数据工程师,胜任上述工作内容,需要具备什么样的条件?拥有什么样的知识呢?

Scala为什么会如此重要,作者觉得主要有以下三点原因:
1、因为spark
大部分从事大数据的工程师是先了解Spark进而再去选择学习Scala的,因为Spark是用Scala开发的。现在Spark是大数据领域的杀手级应用框架,只要搭建了大数据平台,都会大量使用Spark来处理和分析数据,而要想学好Spark,Scala这一关必须是要过的。顺便说一句,Kafka也是基于Scala开发的。
2、无缝对接大数据生态组件
众所周知,大数据生态的大部分组件都是java语言开发的。而Scala是一门基于JVM的语言,可以与java无缝混编,因此可以很好地融合到大数据生态圈。
3、适合大数据处理与机器学习
Scala的语法简洁而富有表达力,更容易掌握。Scala将面向对象与函数式编程相结合,功能强大且简练,非常适合用于处理各种数据。因此,在大数据处理与机器学习中占有重要的地位。
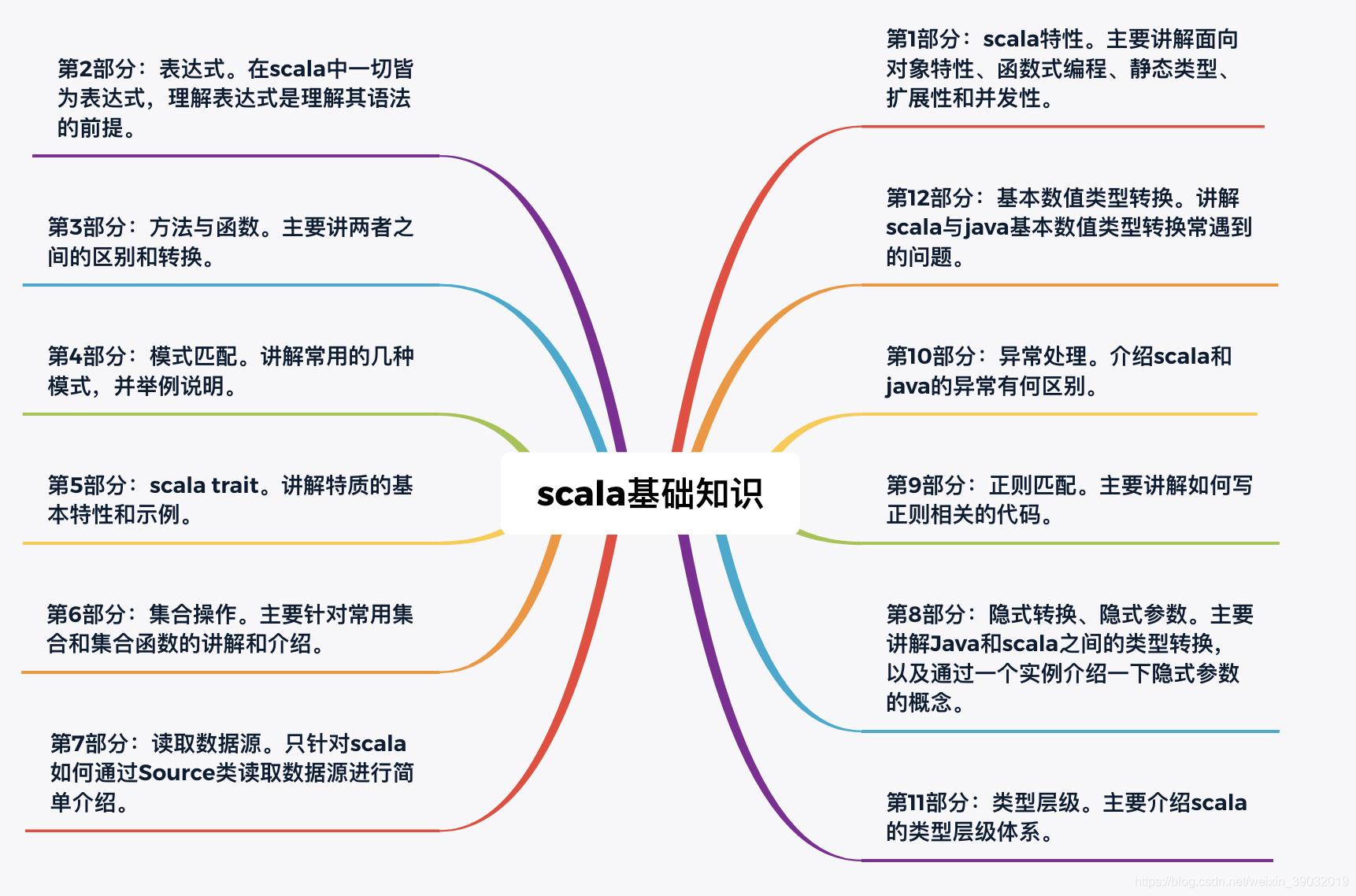
针对大数据分析师必须掌握的scala基础知识,本文的讲解思路如下:
第1部分:scala特性 主要讲解面向对象特性、函数式编程、静态类型、扩展性和并发性。
第2部分:表达式 在scala中一切皆为表达式,理解表达式是理解其语法的前提。
第3部分:方法与函数 主要讲两者之间的区别和转换。
第4部分:模式匹配 讲解常用的几种模式,并举例说明。
第5部分:scala trait 讲解特质的基本特性和示例。
第6部分:集合操作 主要针对常用集合和集合函数的讲解和介绍。
第7部分:读取数据源 只针对scala如何通过Source类读取数据源进行简单介绍。
第8部分:隐式转换、隐式参数 主要讲解Java和scala之间的类型转换,以及通过一个实例介绍一下隐式参数的概念。
第9部分:正则匹配 主要讲解如何写正则相关的代码。
第10部分:异常处理 介绍scala和java的异常有何区别。
第11部分:类型层级 主要介绍scala的类型层级体系。
第12部分:基本数值类型转换 讲解scala与java基本数值类型转换常遇到的问题。
scala基础知识
一、Scala特性
面向对象特性
Scala是一种纯面向对象的语言,彻底贯彻万物皆对象理念。对象的类型和行为是由类和特质来描述的。Scala引入特质(trait)来改进Java的对象模型,使得可以通过混入特质的方式,扩展类的功能。
函数式编程
Scala也是一种函数式语言,函数也能当成值来传递。Scala提供了轻量级的语法用以定义匿名函数,支持高阶函数,允许嵌套多层函数,并支持柯里化。Scala的case class及其内置的模式匹配相当于函数式编程语言中常用的代数类型。
静态类型
Scala拥有一个强大表达能力的类型系统,通过编译时检查,保证代码的安全性和一致性。Scala具备类型推断的特性,这使得开发者可以不去额外标明重复的类型信息,让代码看起来更加整洁易读。
扩展性
Scala的设计秉承一项事实,即在实践中,某个领域特定的应用程序开发往往需要特定于该领域的语言扩展。Scala提供了许多独特的语言机制,可以以库的形式轻易无缝添加新的语言结构。
二、表达式
在scala中,一切皆为表达式。scala非常推崇表达式语法,因为表达式语法,对函数式编程是非常友好的。对开发者而言,表达式语法,使得代码非常简洁易读。
举个例子,我们在定义方法时,会和声明变量一样,使用等号(=)连接,等号左侧是函数名、参数列表和返回值类型(可以省略),而等号右边便是一个由大括号({})包裹的多行表达式。
表达式,是一定会有返回值的。在java中使用void来声明无返回值的方法,而在scala里,这种情况也会有返回值,会返回一个Unit,这是一个特定的值,表示忽略方法的返回值。
三、方法与函数
初学scala时,往往会觉得方法和函数的概念有些模糊,在使用中可能会搞不清楚到底该使用方法还是函数。那怎么区分呢?关键是看这个函数是否在类中定义,在类中定义就是方法,所以Scala 方法是类的一部分。Scala 中的函数则是一个完整的对象,可以赋给一个变量。不过,在scala中,方法和函数是可以相互转化的。下面我们重点说下,如何把方法转为函数。
方法转函数
上文中提到任何方法都是在声明一个表达式,所以将方法转为函数也就非常简单了,相当于是把方法指向的表达式,又重新赋给了一个函数变量,这就是显式转化。还有另外一种写法,是通过偏应用函数的方式,将方法转化为一个新的函数,称作隐式转化。
1)隐式转化
2)显式转化
val f2: (Int) => Int = f1
四、模式匹配
模式匹配是检查某个值是否匹配某一个模式的机制。它是Java中的switch语句的升级版,同样可以用于替代一系列的 if/else 语句,以下介绍几种常用的模式匹配:常量模式、变量模式、通配符模式。
常量模式
常量模式匹配,就是在模式匹配中匹配常量。
object ConstantPattern{ def main(args:Array[String]) :Unit = { //模式匹配结果作为函数返回值 def patternShow(x : Any) = x match { //常量模式 case 5 => "五" case true => "真" case "test" => "字符串" case null => "null值" case Nil => "空列表" //变量模式 case x => "变量" //通配符模式 case _ => "通配符" } }}
变量模式和通配符模式,都可以匹配任意值,他们之间的区别是,变量模式匹配成功后,该变量中会存储匹配成功的值,在后续的代码中还可以引用,而通配符模式匹配成功后,不能再引用匹配到的值。另外要注意的是,由于模式匹配是按顺序匹配的,因此变量模式和通配符模式要写在表达式的最后面。
类型匹配模式
可以匹配输入变量的类型。
object TypePattern{ def main(args:Array[String]) :Unit = { //类型匹配模式 def typePattern(t : Any) = t match { case t : String => "String" case t : Int => "Intger" case t : Double => "Double" case _ => "Other Type" } }}
case class模式
构造器模式指的是,直接在case语句后面接类构造器,匹配的内容放置在构造器参数中。
object CaseClassPattern{ def main(args:Array[String]) :Unit = { //定义一个Person实例 val p = new Person("nyz",27) //case class 模式 def constructorPattern(p : Person) = p match { case Person(name,age) => "name =" + name + ",age =" + age case _ => "Other" } }}
模式守卫
为了让匹配更加具体,可以使用模式守卫,也就是在模式后面加上if判断语句。
object ConstantPattern{ def main(args:Array[String]) :Unit = { //模式匹配结果作为函数返回值 def patternShow(x : Any) = x match { //模式守卫 case x if(x == 5) => "守卫" //通配符模式 case _ => "通配符" } }}
Option匹配
在Scala中Option类型样例类用来表示可能存在或也可能不存在的值(Option的子类有Some和None)。Some包装了某个值,None表示没有值。
class OptionDemo { val map = Map (("a",18),("b",81)) //get方法返回的类型就是Option[Int] map.get("b") match { case some(x) => println(x) case None => println("不存在") }}
五、Scala Trait(特质)
Scala Trait(特质) 相当于 Java 的接口,但实际上它比接口的功能强大。与接口不同的是,它还可以定义属性和方法的实现。
一般情况下Scala的类只能够继承单一父类,但可以使用with关键字混入多个 Trait(特质) 。不过,如果一个scala类没有父类,那么它混入的第一个特质需要使用extends关键字,之后混入的特质使用with关键字。
Trait(特质) 定义的方式与类相似,但它使用的关键字是 trait,如下所示:
trait Equal { def isEqual(x: Any): Boolean def isNotEqual(x: Any): Boolean = !isEqual(x)}
以上特质(Equal)由两个方法组成:isEqual 和 isNotEqual。isEqual 方法没有定义方法的实现,isNotEqual定义了方法的实现。子类继承特质可以实现未被实现的方法。
以下演示了特质的完整实例:
trait Equal { def isEqual(x: Any): Boolean def isNotEqual(x: Any): Boolean = !isEqual(x)}
class Point(xc: Int, yc: Int) extends Equal { val x: Int = xc val y: Int = yc def isEqual(obj: Any) = obj.isInstanceOf[Point] && obj.asInstanceOf[Point].x == x}
object Test { def main(args: Array[String]) { val p1 = new Point(2, 3) val p2 = new Point(2, 4) val p3 = new Point(3, 3)
println(p1.isNotEqual(p2)) println(p1.isNotEqual(p3)) println(p1.isNotEqual(2)) }}
执行以上代码,输出结果为:
$ scalac Test.scala $ scala -cp . Testfalsetruetrue
六、集合操作
常用集合
通过下面的代码,可以了解常用集合的创建方式
// 定义整型 List,其元素以线性方式存储,可以存放重复对象。val x = List(1,2,3,4)
// 定义 Set,其对象不按特定的方式排序,并且没有重复对象。val x = Set(1,3,5,7)
// 定义 Map,把键对象和值对象映射的集合,它的每一个元素都包含一对键对象和值对象。val x = Map("one" -> 1, "two" -> 2, "three" -> 3)
// 创建两个不同类型元素的元组,元组是不同类型的值的集合val x = (10, "Bigdata")
// 定义 Option,表示有可能包含值的容器,也可能不包含值。val x:Option[Int] = Some(5)
集合函数
工作中操作 Scala 集合时,一般会进行两类操作:转换操作(transformation )和行动操作(action)。第一种操作类型将集合转换为另一个集合,第二种操作类型返回某些类型的值。
1)最大值和最小值
先从行动函数开始。在序列中查找最大或最小值是一个极常见的需求。
先看一下简单的例子。
val numbers = Seq(11, 2, 5, 1, 6, 3, 9) numbers.max //11 numbers.min //1
对于这种简单数据集合,Scala的函数式特性显露无疑,如此简单的取到了最大值和最小值。再来看一个数据集合复杂的例子。
case class Book(title: String, pages: Int) val books = Seq( Book("Future of Scala developers", 85), Book("Parallel algorithms", 240), Book("Object Oriented Programming", 130), Book("Mobile Development", 495)) //下面代码返回Book(Mobile Development,495)books.maxBy(book => book.pages) //下面代码返回Book(Future of Scala developers,85)books.minBy(book => book.pages)
minBy & maxBy方法解决了复杂数据的问题。
2)筛选-Filter
对集合进行过滤,返回满足条件的元素的新集合,比如过滤一组数据中的偶数。
val numbers = Seq(1,2,3,4,5,6,7,8,9,10) numbers.filter(n => n % 2 == 0)//上面返回Seq(2,4,6,8,10)
获取页数大于300页的书。
val books = Seq( Book("Future of Scala developers", 85), Book("Parallel algorithms", 240), Book("Object Oriented Programming", 130), Book("Mobile Development", 495))
books.filter(book => book.pages >= 300)//上面返回Seq(Book("Mobile Development", 495))
还有一个与 filter类似的方法是 filterNot,也就是筛选出不满足条件的对象。
3)Flatten
它的作用是将多个集合展开,组成一个新的集合,举例说明。
val abcd = Seq('a', 'b', 'c', 'd')val efgj = Seq('e', 'f', 'g', 'h')val ijkl = Seq('i', 'j', 'k', 'l')val mnop = Seq('m', 'n', 'o', 'p')val qrst = Seq('q', 'r', 's', 't')val uvwx = Seq('u', 'v', 'w', 'x')val yz = Seq('y', 'z') val alphabet = Seq(abcd, efgj, ijkl, mnop, qrst, uvwx, yz)
alphabet.flatten
执行后返回下面的集合:
List('a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z')
4)集合运算函数
集合运算即差集、交集和并集操作。
val num1 = Seq(1, 2, 3, 4, 5, 6)val num2 = Seq(4, 5, 6, 7, 8, 9) //返回List(1, 2, 3)num1.diff(num2) //返回List(4, 5, 6)num1.intersect(num2) //返回List(1, 2, 3, 4, 5, 6, 4, 5, 6, 7, 8, 9)num1.union(num2)
//合并后再去重,返回List(1, 2, 3, 4, 5, 6, 7, 8, 9)num1.union(num2).distinct
5)map函数
map 函数的逻辑是遍历集合并对每个元素调用传入的函数进行处理。
val numbers = Seq(1,2,3,4,5,6) //返回List(2, 4, 6, 8, 10, 12)numbers.map(n => n * 2) val chars = Seq('a', 'b', 'c', 'd') //返回List(A, B, C, D)chars.map(ch => ch.toUpper)
6)flatMap
它将map & flatten组合起来,请看下面的操作。
val abcd = Seq('a', 'b', 'c', 'd') //List(A, a, B, b, C, c, D, d)abcd.flatMap(ch => List(ch.toUpper, ch))
从结果可以看出来是先做的map,然后做的flatten
7)forall & exists
forall是对整个集合做判断,当集合中的所有元素都满足条件时,返回true。而exists则是只要有一个元素满足条件就返回true。
val numbers = Seq(3, 7, 2, 9, 6, 5, 1, 4, 2) //返回turenumbers.forall(n => n < 10) //返回falsenumbers.forall(n => n > 5)
//返回truenumbers.exists(n => n > 5)
七、读取数据源
读取外部数据源是开发中很常见的需求,如在程序中读取外部配置文件并解析,获取相应的执行参数。这里只针对scala如何通过Source类读取数据源进行简单介绍。
import scala.io.Source
object ReadFile { //读取ClasPath下的配置文件 val file = Source.fromInputStream(this.getClass.getClassLoader.getResourceAsStream("app.conf"))
//一行一行读取文件,getLines()表示读取文件所有行 def readLine: Unit ={ for(line <- file.getLines()){ println(line) } } //读取网络上的内容 def readNetwork: Unit ={ val file = Source.fromURL("http://www.baidu.com") for(line <- file.getLines()){ println(line) } }
//读取给定的字符串-多用于调试 val source = Source.fromString("test") }
八、隐式转换
隐式转换是Scala中一种非常有特色的功能,是其他编程语言所不具有的,可以实现将某种类型的对象转换为另一种类型的对象。数据分析工作中,最常使用到的就是java和scala集合之间的互相转换,转换以后就可以调用另一种类型的方法。scala提供了scala.collection.JavaConversions类,只要引入此类中相应的隐式转化方法,在程序中就可以用相应的类型来代替要求的类型。
如通过以下转换,scala.collection.mutable.Buffer自动转换成了java.util.List。
import scala.collection.JavaConversions.bufferAsJavaListscala.collection.mutable.Buffer => java.util.List
同样,java.util.List也可以转换成scala.collection.mutable.Buffer。
import scala.collection.JavaConversions.asScalaBufferjava.util.List => scala.collection.mutable.Buffer
所有可能的转换汇总如下,双向箭头表示可互相转换,单箭头则表示只有左边可转换到右边。
import scala.collection.JavaConversions._
scala.collection.Iterable <=> java.lang.Iterablescala.collection.Iterable <=> java.util.Collectionscala.collection.Iterator <=> java.util.{ Iterator, Enumeration }scala.collection.mutable.Buffer <=> java.util.Listscala.collection.mutable.Set <=> java.util.Setscala.collection.mutable.Map <=> java.util.{ Map, Dictionary }scala.collection.concurrent.Map <=> java.util.concurrent.ConcurrentMap
scala.collection.Seq => java.util.Listscala.collection.mutable.Seq => java.util.Listscala.collection.Set => java.util.Setscala.collection.Map => java.util.Mapjava.util.Properties => scala.collection.mutable.Map[String, String]
隐式参数
所谓隐式参数,指的是在函数或者方法中,定义使用implicit修饰的参数。当调用该函数或方法时,scala会尝试在变量作用域中找到一个与指定类型相匹配的使用implicit修饰的对象,即隐式值,注入到函数参数中函数体使用。示例如下:
class SayHello{ def write(content:String) = println(content)}implicit val sayHello=new SayHello
def saySomething(name:String)(implicit sayHello:SayHello){ sayHello.write("Hello," + name)}
saySomething("Scala")
//打印 Hello,Scala
值得注意的是,隐式参数是根据类型匹配的,因此作用域中不能同时出现两个相同类型的隐式变量,否则编译时会抛出隐式变量模糊的异常。
九、正则匹配
正则的概念、作用和规则都在上一篇《大数据分析工程师入门–1.Java基础》中已经完整的讲述了,这里将通过示例来讲解下在scala中正则相关代码怎么写:
定义
val TEST_REGEX = "home\\*(classification|foundation|my_tv)\\*[0-9-]{0,2}([a-z_]*)".r
使用
//path是用来匹配的字符串TEST_REGEX findFirstMatchIn path match { case Some(p) => { //获取TEST_REGEX中的第一个括号里正则片段匹配到的内容 launcher_area_code = p.group(1) //获取TEST_REGEX中的第二个括号里正则片段匹配到的内容 launcher_location_code = p.group(2) }}
十、异常处理
学习过Java的同学对异常一定并不陌生,异常通常是程序执行过程中遇到问题时,用来打断程序执行的重要方式。关于异常处理的注意事项,在上一讲《大数据分析工程师入门–1.Java基础》里已经讲过了,这里就不再赘述了。我们重点来讲下scala和java在异常这个特性的设计上的不同。
1. 捕获异常的方式略有不同
java中是通过多个catch子句来捕获不同类型的异常,而在scala中是通过一个catch子句,加上模式匹配的类型匹配方式来捕获不同类型的异常。如下图所示:

2.scala没有checked异常
在java中,非运行时异常在编译期是会被强制检查的,要么写try…catch…处理,要么使用throws关键字,将异常抛给调用者处理。而在scala中,更推崇通过使用函数式结构和强类型来减少对异常及其处理的依赖。因此scala不支持检查型异常(checked exception)。
当使用scala调用java类库时,scala会把java代码中声明的异常,转换为非检查型异常。
3.scala在throw异常时是有返回值的
在scala的设计中,所有表达式都是有返回值的。那么,自然throw表达式也不例外,throw表达式的返回值为Nothing。由于Nothing类型是所有类型的子类型,因此throw表达式可以出现在任意位置,而不会影响到类型的推断。
十一、类型层级
在scala中,所有的值都是有类型的,包括数值型值和函数,比java更加彻底地贯彻了万物皆对象的理念。因此,scala有一套自己的类型层级,如下图所示:
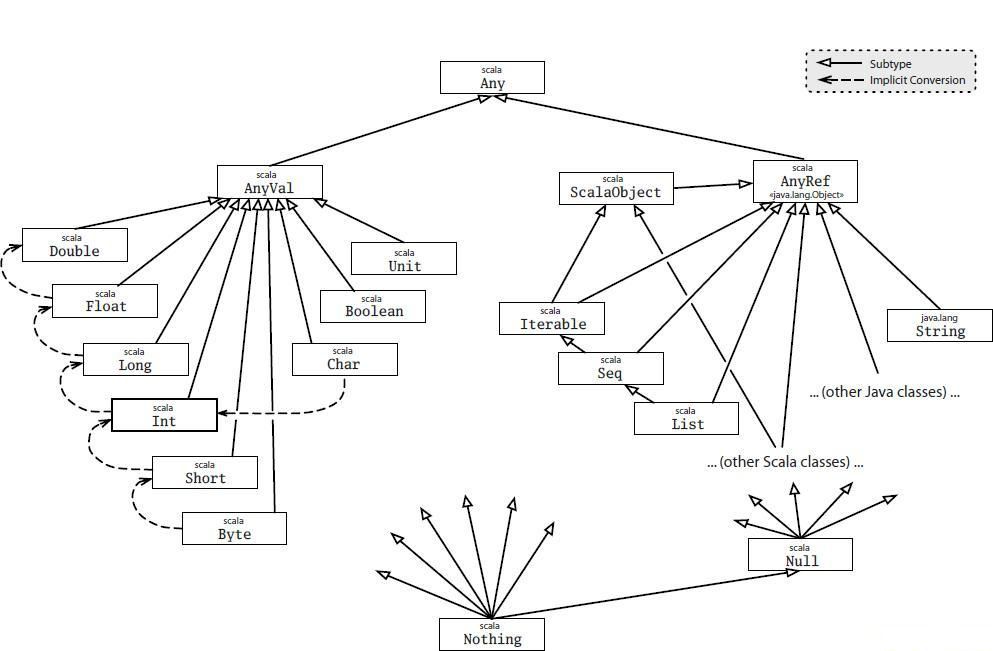
如图中所示,scala的顶级类是Any,下面包含两个子类,AnyVal和AnyRef,其中AnyVal是所有值类型的父类,其中包含一个特殊的值Unit;而AnyRef是所有引用类型的父类,所有java类型和非值类型的scala类型都是它的子类。其中,有两个比较特殊的底层子类型,一个是Null,它是所有引用类型的子类型,可以赋给任何引用类型变量;另一个是Nothing,它是所有类型的子类,因此既可以赋给引用类型变量,也可以赋给值类型变量。
十二、基本数值类型转换
在scala中,通常会自动进行java和scala之间基本数值类型的转换,并不需要单独去处理。所以,在我们的感受中,通常java和scala的基本数据类型是可以无缝衔接的。但是,有一种情况是例外的,那就是当你引用第三方的java类库,而在它的代码中接收参数是Object类型,之后又对传入对象的实际数值类型做判断时,通常会失败报错。
原因很简单,第三方java类库,使用java语言编写,它只认得java的类型。当接收参数为Object类型时,scala默认不会转换成java的数值类型,这样当判断对象的具体数值类型时,会出现不认识scala对象类型的异常。
解决方案也很简单,只需要在传入第三方类库方法前,手动包装成java类型即可。以下是代码示例,本例演示了DBUtils类库传入scala类型时的处理,只展示了部分代码:
//由于java和scala中的类型短名称重名,为避免歧义,进行了重命名import java.lang.{Long => JLong, Double => JDouble}//conn为数据库连接,sql为要执行的SQL语句queryRunner.update(conn, sql, new JLong(1L), new JDouble(2.2))
总结
本文结合实际工作经验,把scala中最常用到的一些知识点进行了梳理,要想成为一名初级大数据工程师,这些知识是必须要掌握的。

















 427
427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











