







 本文介绍了Hadoop与大数据的关系,Hadoop的诞生背景,以及Hadoop生态圈的重要组件,包括HDFS、MapReduce、Yarn、Spark、HBase、Hive、Oozie、Flume等,涵盖了数据存储、计算、资源管理和日志收集等方面,展示了Hadoop在大数据处理中的核心地位和重要作用。
本文介绍了Hadoop与大数据的关系,Hadoop的诞生背景,以及Hadoop生态圈的重要组件,包括HDFS、MapReduce、Yarn、Spark、HBase、Hive、Oozie、Flume等,涵盖了数据存储、计算、资源管理和日志收集等方面,展示了Hadoop在大数据处理中的核心地位和重要作用。
一、Hadoop与大数据之间到底是什么关系?
Hadoop是Apache下的一个开源项目。
大数据可以理解为Hadoop的生态圈或者泛生态圈。
Hadoop生态圈就如同厨房里的做饭厨具,这些厨具就类是Hadoop里的各种软件,比如:HDFS、Hive、Pig、Spark、Storm等,这些软件各有各的用途,并且相互配合,而且还具有自己独有的核心。
对于大数据运维说就要实现Hadoop生态圈各种软件的最优组合。
二、Hadoop诞生记
Hadoop的诞生可以追溯到2003年,当时,Doug Cutting和Mike Cafarella致力于构建一个可以处理海量数据的开源搜索引擎Nutch。但是,他们遇到了一个棘手的问题:如何处理数十亿个网页的索引数据?
为了解决这个问题,他们开始寻找一种适合处理大数据的分布式计算框架,但是当时市场上并没有合适的解决方案。于是,他们开始研究Google的分布式计算框架MapReduce和分布式文件系统GFS(Google File System),并试图将其应用于Nutch项目。
由于Google的技术并未公开,Doug Cutting和Mike Cafarella只能自己动手实现一个类似的系统。于是,他们开发了Hadoop分布式文件系统(HDFS)和Hadoop MapReduce计算框架,并将其作为Nutch项目的一部分发布出来。2006年,Hadoop项目成立,并加入了Apache基金会的孵化器。
Hadoop之所以能够成功,一方面是由于Doug Cutting和Mike Cafarella的努力和创新精神,另一方面是因为Hadoop可以在普通的商用硬件上构建成大规模的分布式系统,从而降低了处理大数据的成本和复杂度。随着Hadoop的不断发展和完善,它已经成为了处理大数据的事实标准,并广泛应用于各个行业和领域。
三、Hadoop生态圈
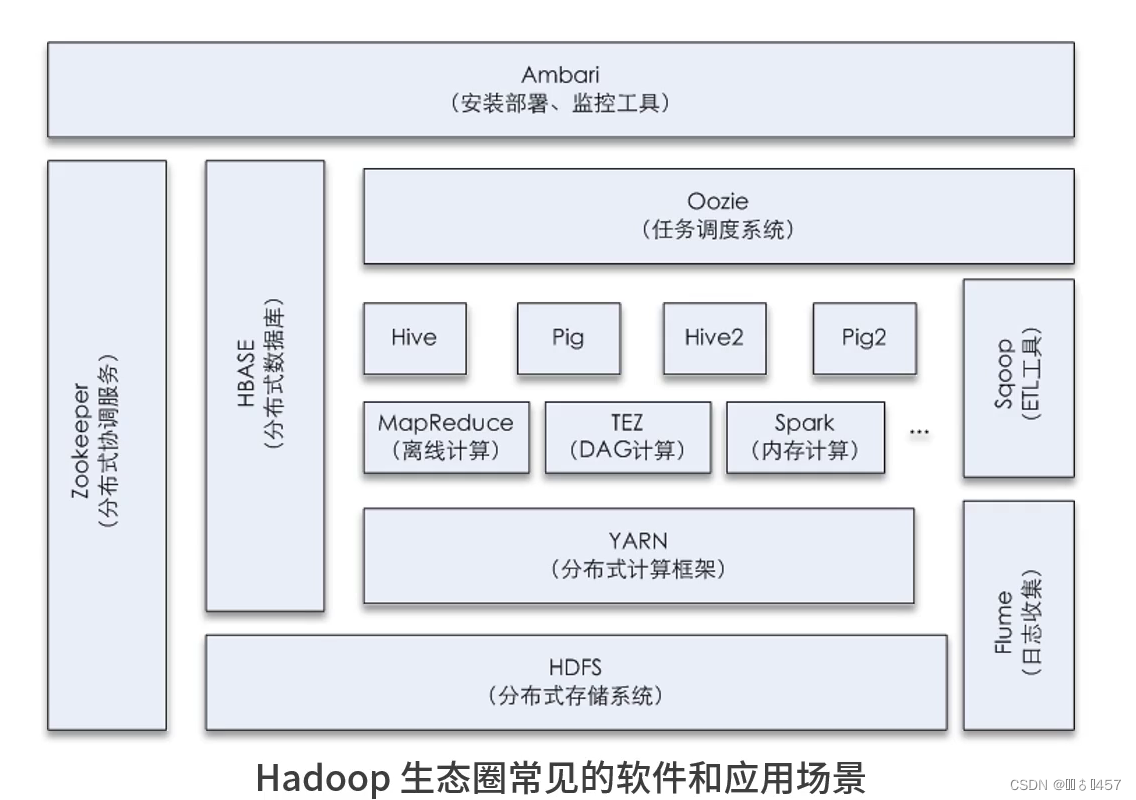
1.数据存储:HDFS(Hadoop分布式文件系统)一个分布式文件系统
HDFS是Hadoop技术体系中的核心基石,负责分布式存储数据,可理解为一个分布式的文件系统,主要特征是数据分散存储。
一个文件存储在HDFS上时会被分成若干个数据块,每个数据块分别存储在不同的服务器上,HDFS支持数据冗余备份和数据恢复功能,并且能够自动检测和修复节点故障,还保证数据的高可靠性和持久性。假如:你有一百台服务器那么所有数据会平均分担在一百台服务器上,而且为保证数据安全
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1450
1450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











