






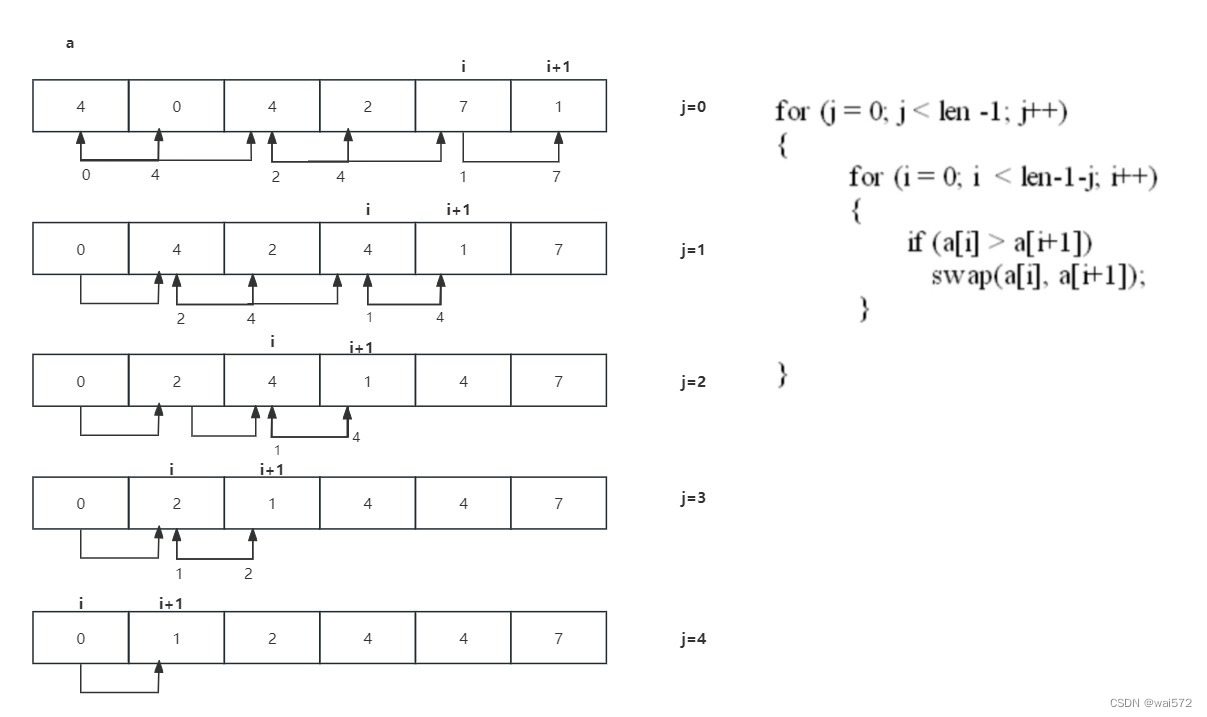
1.冒泡排序:
这个算法就是因其中数字从列表的开始向顶部移动的方式就像水泡从水中冒出的样子而得名,将较大的元素逐步"冒泡"到数组的顶部,从而实现排序。
主要思想是两两相互比较,大的数字向一边移动,小的数字向另一边移动。如图j为要排序的次数,i为每次排序要比较的次数。
可以看出冒泡排序的时间复杂度为O(n²)。
排序算法的稳定性:对于待排记录中,两个相同元素在排序过程和排序完成后相对位置没有发生变化,即为稳定排序算法。如历程中两个4的相对位置没有发生变化, 所以冒泡排序为稳定的排序算法。
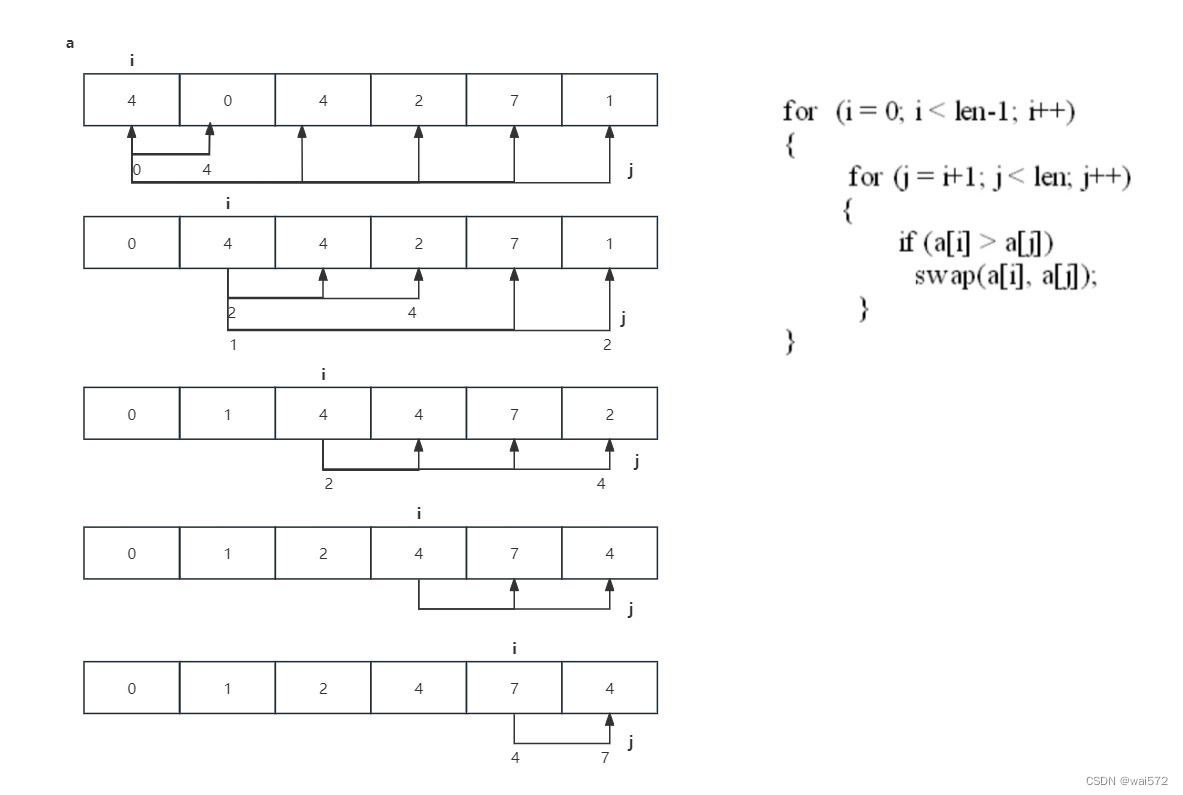
2.选择排序:
将待排位置的数据和后续的数据挨个进行比较,最终会先确定最小值。
可以看出选择排序的时间复杂度为O(n²)。
排序算法的稳定性:不稳定的排序算法(两个4的相对位置发生改变)
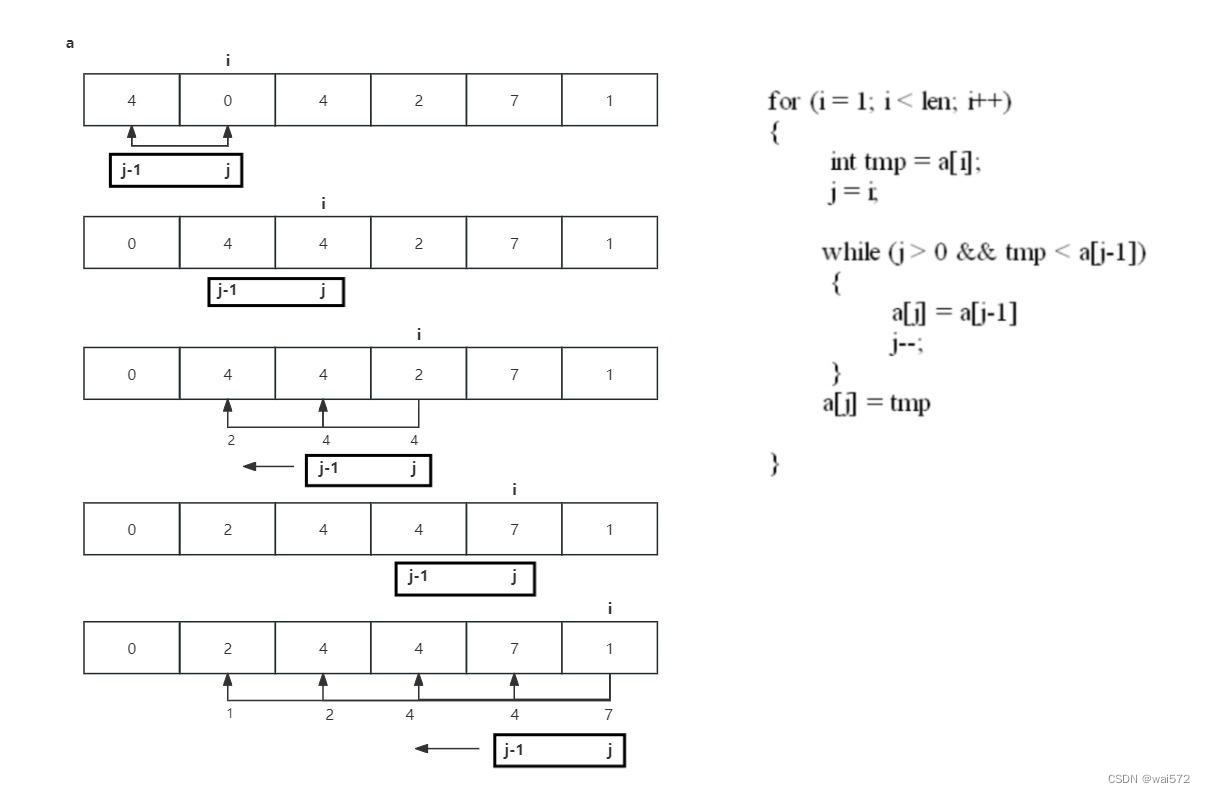
3.插入排序:
将待排数据插入到对应的序列中,确保插入后的序列仍然有序。
可以看出插入排序的时间复杂度为O(n²)。
排序算法的稳定性:稳定的排序算法(两个4的相对位置没有发生改变)
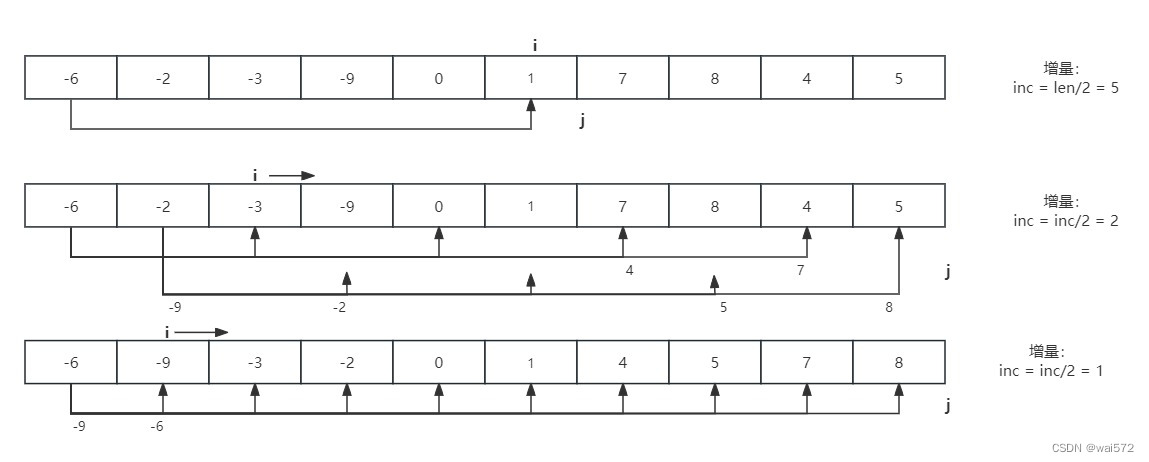
4.希尔排序:
首次突破O(n²)复杂度的排序算法。在插入排序的基础上,让while循环执行的次数越少,尽可能让序列更有序。
将一个待排序列划分成若干个子序列,对每一个子序列进行插入排序,每个子序列用增量划分。
希尔排序的时间复杂度无确切值,与增量有关,分布在O(nlogn)~O(n²)。
跳跃性比较大,不稳定
#include <stdio.h>
void print_array(int *a, int len)
{
for (int i = 0; i < len; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
void shell_sort(int *a, int len)
{
int inc = 0;
for (inc = len/2; inc > 0; inc /= 2)
{
for (int i = inc; i < len; i++)
{
int tmp = a[i];
int j = i;
while (j >= inc && tmp < a[j-inc])
{
a[j] = a[j-inc];
j = j- inc;
}
a[j] = tmp;
}
}
}
int main()
{
int a[] = {1,2,-3,-4,5,-6,7,8,-9,0};
shell_sort(a, sizeof(a) / sizeof(a[0]));
print_array(a, sizeof(a) / sizeof(a[0]));
printf("Hello World!\n");
return 0;
}
5.快速排序:
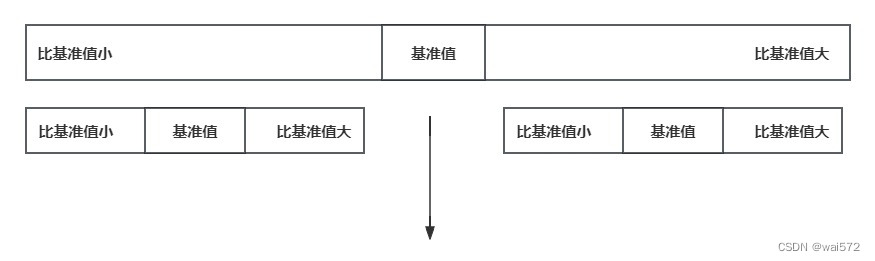
选定一个基准值,经过排序,基准值的前边都是比它小的数据,后边都是比它大的数据。
快速排序的时间复杂度为O(nlogn)
不稳定的排序算法
#include <stdio.h>
void print_array(int *a, int len)
{
for (int i = 0; i < len; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
void quick_sort(int *a, int begin, int end)
{
if (begin >= end)
{
return ;
}
int i = begin;
int j = end;
int key = a[i];
while (i < j)
{
while (i < j && key <= a[j])
{
j--;
}
a[i] = a[j];
while (i < j && key >= a[i])
{
i++;
}
a[j] = a[i];
}
a[i] = key;
quick_sort(a, begin, i-1);
quick_sort(a, i+1, end);
}
int main()
{
int a[] = {1,2,-3,-4,5,-6,7,8,-9,0};
quick_sort(a, 0, sizeof(a) / sizeof(a[0])-1);
print_array(a, sizeof(a) / sizeof(a[0]));
printf("Hello World!\n");
return 0;
}6.二分查找:
在一个有序的序列中,将序列折中,找出折中后的中间值,如果数据比中间值大,就从折中值的后半序列中找,如果数据比中间值小,就从前半序列中找。















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









