






本文一二部分是概念部分的讲解,对于考试重点笔记可直接跳转至第三部分
一、模电课程讲解
模拟电子技术是一门深入探讨电子电路如何处理连续变化的模拟信号的课程。它不仅涵盖了电子元件的基础知识,还深入到了半导体器件的特性和应用,以及复杂电路的设计和分析。这门课程对于电子工程、通信工程、自动化等专业的学生来说至关重要,因为它为他们提供了理解和设计现实世界中广泛使用的电子系统的基础。
课程从基础电子元件开始,比如电阻、电容和电感,这些都是构建更复杂电路的基本组成部分。电阻器控制电流流动,电容器存储电荷并在电路中起到滤波和能量存储的作用,而电感器则在电路中存储磁能并限制电流变化的速率。这些元件的特性和相互作用是理解更复杂电路行为的关键。
- 电阻:学习电阻的定义、单位、特性以及在电路中的作用。
- 电容:了解电容的定义、单位、充放电特性以及在电路中的应用。
- 电感:掌握电感的定义、单位、特性以及在电路中的作用。
随后,课程转向半导体器件,这是模拟电子技术的核心。二极管、晶体管和场效应管等半导体器件构成了现代电子电路的基石。二极管允许电流单向流动,而晶体管则可以作为放大器或开关使用,极大地增强了电路的功能。场效应管则提供了另一种控制电流流动的方式,它们在现代电子设备中非常常见。
放大电路是模拟电子技术中的一个关键概念,它们能够增强信号的幅度。课程中会详细讲解不同类型的放大器,如共射、共集和共基放大器,以及它们的特性、设计和应用。多级放大电路则涉及到如何将多个放大器级联起来,以实现更高的增益和更宽的频率响应。
功率放大电路是另一个重要的主题,它们用于驱动扬声器、电机和其他需要较大电流的设备。课程会介绍不同类型的功率放大器,如甲类、乙类和甲乙类放大器,以及它们的设计和效率问题。
- 共射放大器:学习共射放大器的原理、特性以及设计方法。
- 共集放大器:了解共集放大器的特点和应用。
- 共基放大器:掌握共基放大器的原理和应用。
信号处理电路是模拟电子技术的另一个重要领域,包括滤波器和振荡器。滤波器用于选择性地通过或阻止某些频率的信号,而振荡器则能够产生稳定的频率信号。这些电路在通信系统、音频设备和信号生成中都有广泛的应用。
模拟集成电路是现代电子设计中不可或缺的一部分。运算放大器是模拟集成电路中的一个典型例子,它们可以用于实现各种数学运算和信号处理功能。此外,还有许多专门的信号处理集成电路,如滤波器、比较器和调制解调器,它们在现代电子系统中扮演着重要角色。
反馈是模拟电子技术中的另一个重要概念,它涉及到电路输出对输入的影响。负反馈可以提高电路的稳定性、线性和增益。通过学习反馈,学生可以更好地理解电路的动态行为。
最后,模拟-数字转换(ADC)和数字-模拟转换(DAC)是模拟电子技术与数字电子技术之间的桥梁。ADC和DAC电路使得模拟信号可以被数字系统处理,反之亦然。这些转换器在数据采集、信号处理和数字通信中起着至关重要的作用。
二、南邮期末考试资源爬虫
首先申明爬虫的使用需要遵守相关网站的使用条款和法律法规。在大多数情况下,未经授权爬取网站数据是不合法的,也可能违反网站的服务条款。此处提供一个合法使用爬虫技术的示例,比如爬取公开API的数据。下面是一个使用Python和requests库从一个公开API获取数据的简单示例:
import requests
from bs4 import BeautifulSoup
import json
import time
from urllib.parse import urlencode
# 设置请求头,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
# 设置API的基础URL和参数
base_url = 'https://api.github.com/users/kimi/repos'
params = {
'per_page': 100, # 每页显示的仓库数量
'page': 1 # 当前页码
}
# 存储获取到的数据
repos_data = []
def fetch_repos(url, params):
try:
response = requests.get(url, headers=headers, params=params)
response.raise_for_status() # 如果请求返回了一个错误状态码,将抛出HTTPError异常
return response.json()
except requests.exceptions.HTTPError as e:
print(f"HTTP error occurred: {e}") # 打印HTTP错误
except requests.exceptions.RequestException as e:
print(f"Error fetching repos: {e}") # 打印请求错误
return None
def save_data(data):
with open('repos.json', 'w') as f:
json.dump(data, f, indent=4) # 将数据写入文件
def main():
global params
while True:
print(f"Fetching page {params['page']}...")
repos = fetch_repos(base_url, params)
if not repos:
break
repos_data.extend(repos)
if len(repos) < params['per_page']: # 如果当前页的仓库数量小于每页的数量,说明已经到最后一页了
break
params['page'] += 1 # 准备下一页的请求
time.sleep(1) # 休眠1秒,避免过快请求导致IP被暂时封禁
save_data(repos_data)
print(f"Total repos fetched: {len(repos_data)}")
if __name__ == "__main__":
main()这个示例展示了如何使用Python进行基本的网络爬虫操作,包括处理分页、异常处理、用户代理的使用,以及数据的持久化存储。此外,爬虫技术还可以用于更复杂的场景,如爬取动态加载的内容,这通常需要使用Selenium等工具来模拟浏览器行为。在处理这类内容时,你需要考虑更多的因素,如JavaScript的执行、页面的DOM结构变化等。
除此之外,还需要进行网络的抓包。网络抓包通常是指捕获和分析网络上的数据包,这在网络安全、性能分析和调试网络应用程序时非常有用。在Python中,可以使用scapy库来实现网络抓包。scapy是一个强大的Python库,用于网络包的发送、嗅探和分析。下面是一个使用scapy进行网络抓包的简单示例。使用scapy库。这个脚本将捕获网络数据包,分析TCP和UDP流量,过滤特定端口,统计各种协议的数据包,并将捕获的数据包保存到文件中。
from scapy.all import sniff, Ether, IP, TCP, UDP, ICMP
from scapy.all import wrpcap, rdpcap
import datetime
import json
# 定义一个字典来存储各种协议的数据包数量
packet_counts = {'TCP': 0, 'UDP': 0, 'ICMP': 0}
# 定义一个字典来存储特定端口的数据包数量
port_counts = {}
# 定义一个列表来存储捕获的数据包
captured_packets = []
# 定义一个回调函数来处理每个捕获的数据包
def packet_callback(packet):
global packet_counts, port_counts, captured_packets
# 打印每个捕获的数据包的详细信息
print(packet.summary())
# 根据协议类型增加计数
if packet.haslayer(TCP):
packet_counts['TCP'] += 1
port = packet[TCP].dport
if port in port_counts:
port_counts[port] += 1
else:
port_counts[port] = 1
elif packet.haslayer(UDP):
packet_counts['UDP'] += 1
port = packet[UDP].dport
if port in port_counts:
port_counts[port] += 1
else:
port_counts[port] = 1
elif packet.haslayer(ICMP):
packet_counts['ICMP'] += 1
# 保存数据包到列表
captured_packets.append(packet)
# 保存数据包到PCAP文件
timestamp = datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
wrpcap(f"captured_packets_{timestamp}.pcap", captured_packets, append=True)
# 设置过滤条件,例如只捕获TCP、UDP和ICMP数据包
filter = "tcp or udp or icmp"
# 使用sniff函数捕获数据包
# 参数count表示捕获的数据包数量
sniff(filter=filter, prn=packet_callback, count=100)
# 打印各种协议的数据包数量
print("Packet counts:")
for protocol, count in packet_counts.items():
print(f"{protocol}: {count}")
# 打印特定端口的数据包数量
print("\nPort counts:")
for port, count in port_counts.items():
print(f"Port {port}: {count}")
# 保存统计数据到JSON文件
with open('packet_stats.json', 'w') as f:
json.dump({'packet_counts': packet_counts, 'port_counts': port_counts}, f, indent=4)
# 读取并打印PCAP文件中的数据包
pcap_file = f"captured_packets_{timestamp}.pcap"
packets = rdpcap(pcap_file)
print(f"\nReading from {pcap_file}:")
for packet in packets:
print(packet.summary()) 这个示例展示了如何使用scapy进行更复杂的网络抓包,包括数据包的统计、过滤、保存和分析。你可以根据需要进一步探索scapy的高级功能,如协议分析、数据包重组等。
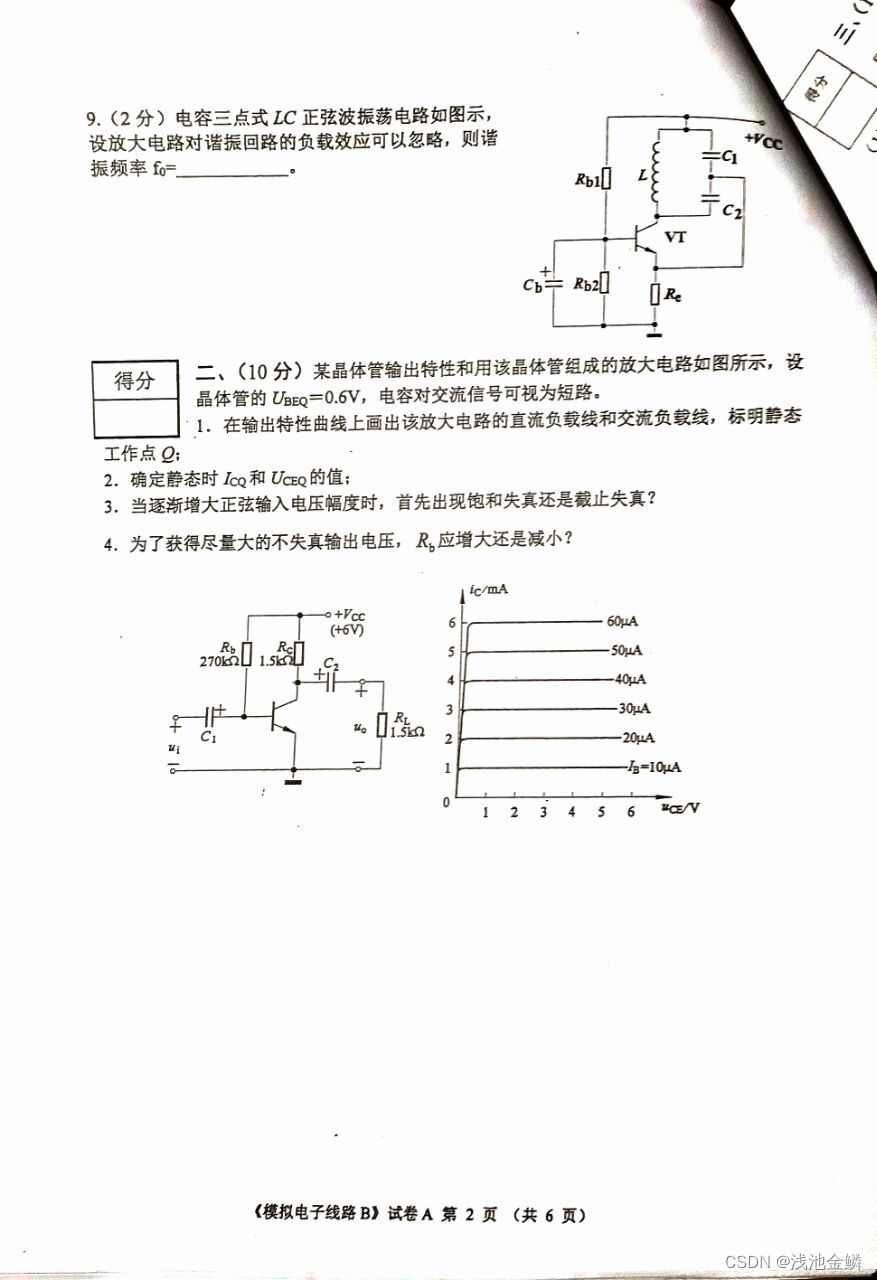
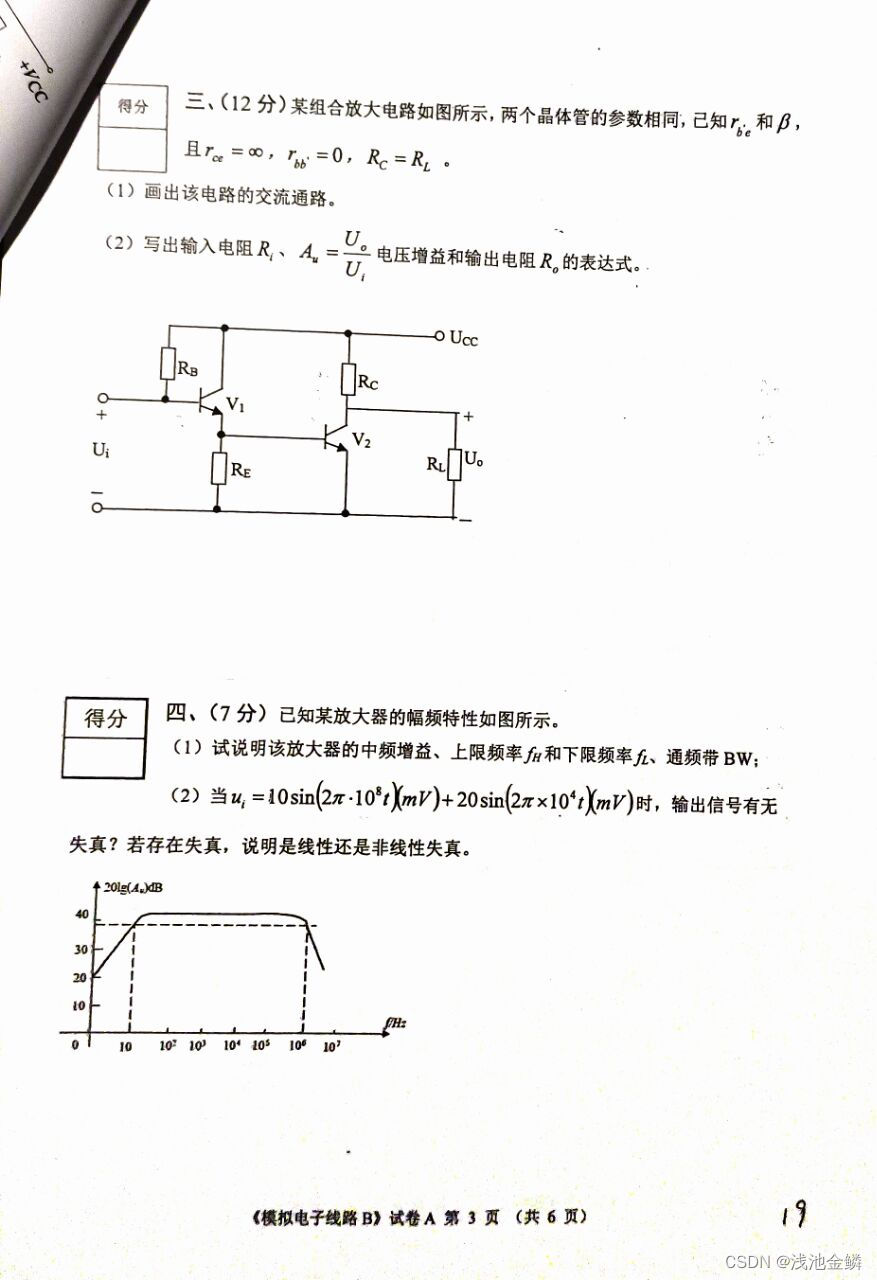
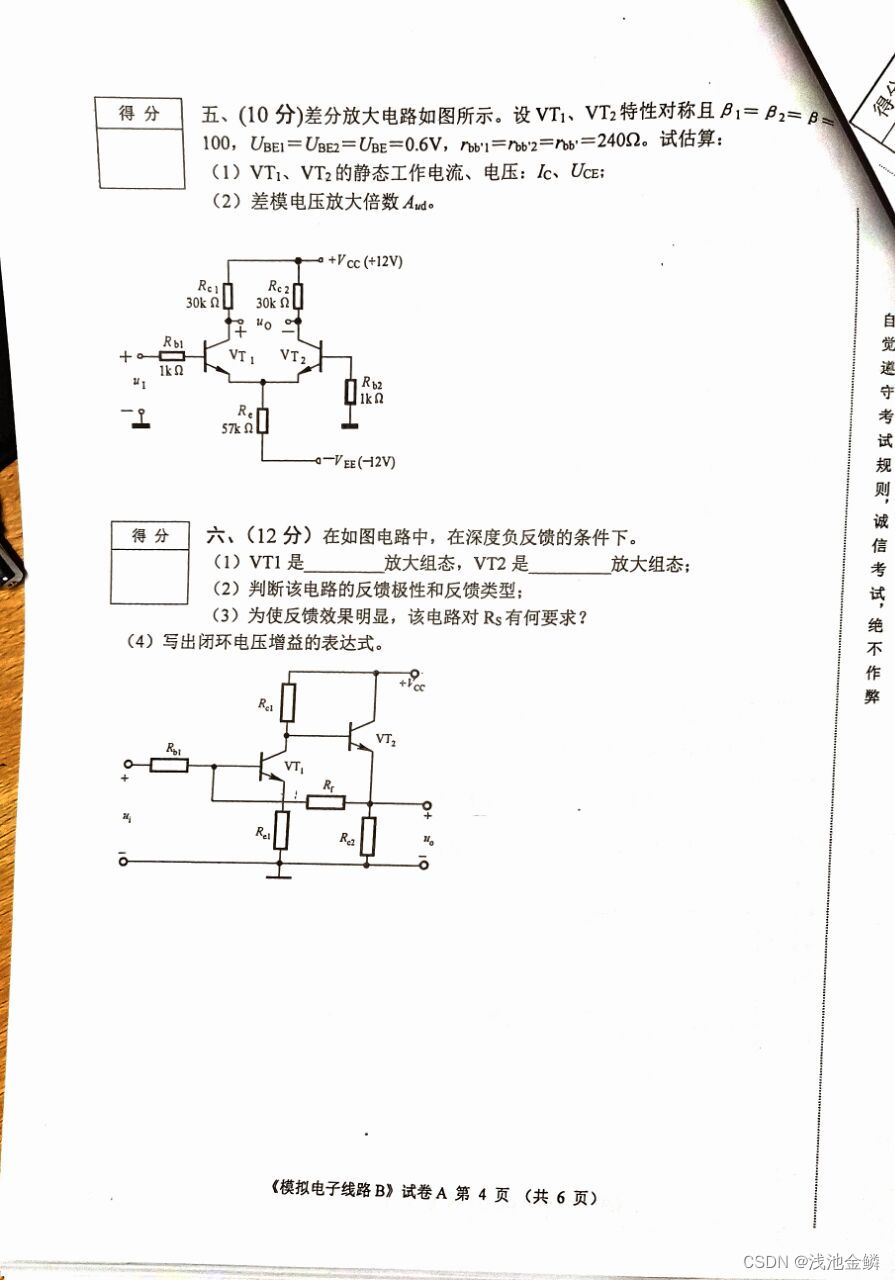
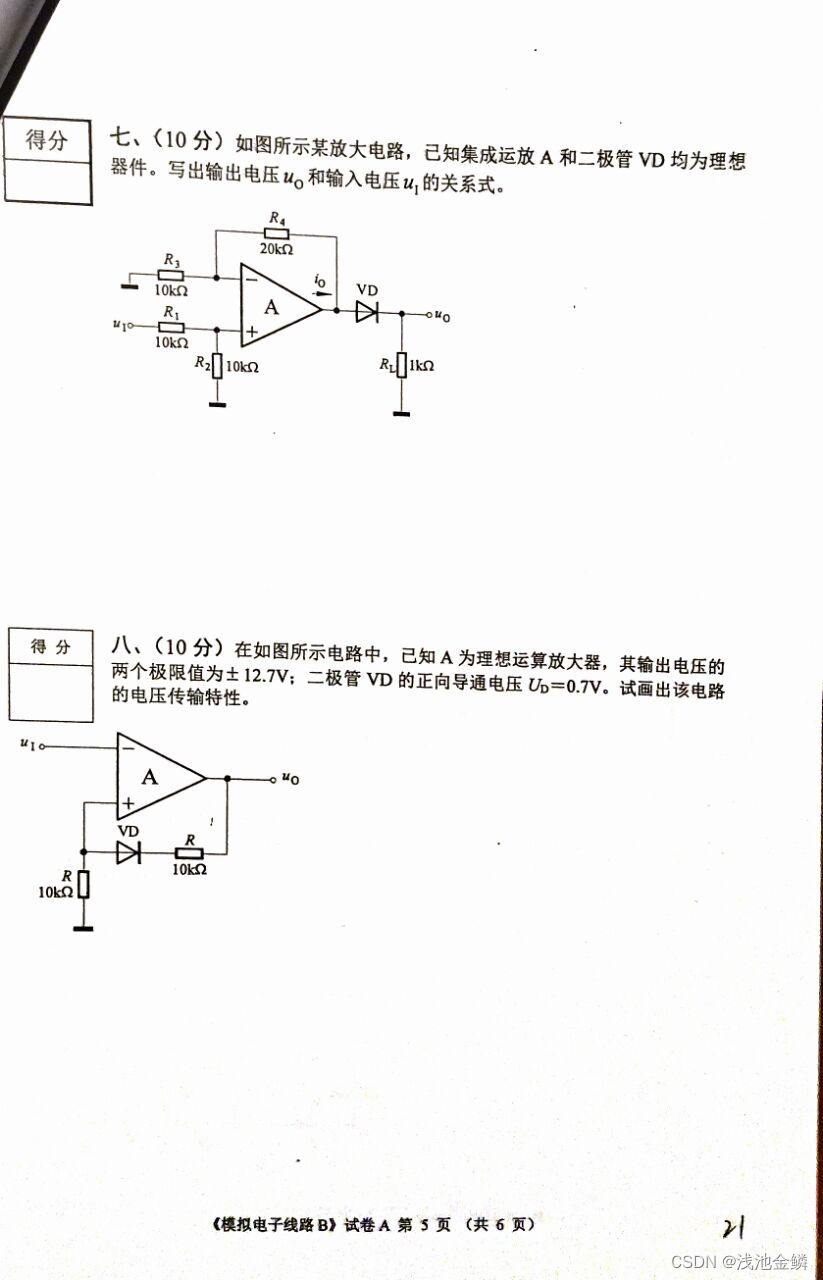
三、期末试卷






















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











