








MybatisPlus的使用
前言
mybatis是持久层框架,对数据库进行增删改查。
mybatis-plus简称MP,MP是对mybatis(MB)的一个增强工具,在MB的基础上增强功能,不会对MB的原有代码做修改。
一、特性:
-
无侵入。在MB的基础上增强功能,不会对MB的原有代码做修改
-
损耗小:启动即会自动注入基本 CURD(就是对数据库表的操作代码和第三条一样),性能基本无损耗
-
强大的 CRUD 操作:内置通用 Mapper、通用 Service。对于寻常、条件简单的 增删改查单表操作不用写代码。
-
支持 Lambda 形式调用:可以用 Lambda 表达式编写各类查询条件
-
主键自动生成:四种主键(id)的生成策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解 决主键问题
-
内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
-
内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码, 支持模板引擎
-
支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、 SQLServer2005、SQLServer 等多种数据库
-
支持 XML 热加载:Mapper 对应的 XML 支持热加载,对于简单的 CRUD 操作,甚至可以无 XML 启动
提示:以下是本篇文章正文内容
一、MP快速入门
使用步骤
- 引入MP依赖,该依赖还集成了MB和MP的所有功能,只需要引入这个就可以同时使用MP和MB
<!-- mybatis-plus插件依赖 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus</artifactId>
<version>3.1.1</version>
</dependency>
- 定义mapper
自定义mapper继承MybatisPlus提供的BaseMapper接口,这是可以直接调用UserMapper的方法(MP会基于动态代理实现BaseMapper接口方法)
//泛型使用你想进行增删改查的po类
public interface UserMapper extends BaseMapper<User> {
}
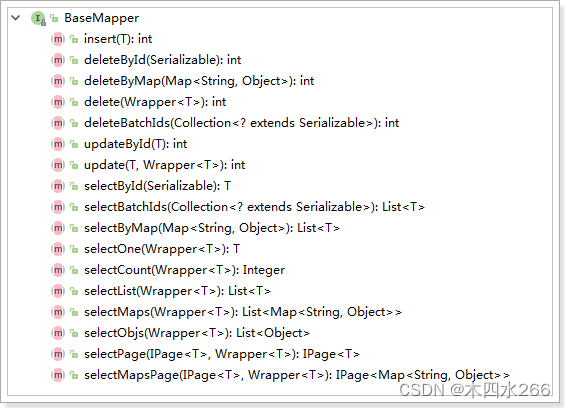
BaseMapper接口里面有很多已经实现了的CRUD方法
新增:insert
删除:delete
查询:select
- 在启动类或者配置类上上加上包扫描
@MapperScan("*.mapper")
- 问题:MP怎么实现单表的增删改查,什么也没写MP怎么知道要访问那张表,字段是什么?
常用注解
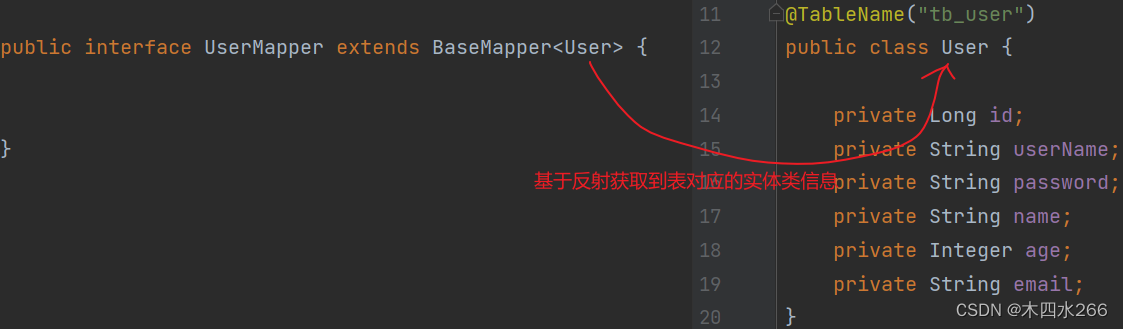
MP通过扫描实体类(是你自定义mapper继承BaseMapper时指定的泛型),并基于反射来获取实体类信息来作为数据库表信息
并且约定大于配置
- 类名驼峰转下划线作为表名
- 名为ID的字段作为主键
- 变量名驼峰转下划线作为表的字段名
当类名、变量名和表名、字段名不一致时,可以使用以下注解来指定
MybatisPlus中比较常用的几个注解如下:
- @TableName:用来指定表名
@TableName("tb_user")
public class User{}
- @Tableld:用来指定表中的主键字段信息
@TableId(type = IdType.AUTO)
private Long id;
MP实现id生成策略
ldType枚举:
-
AUTO: 数据库自增长
-
INPUT: 通过set方法程序员自行输入
-
ASSIGN_ID: MP分配ID。接口ldentifierGenerator的方法nextld来生成id,默认实现类为DefaultldentifierGenerator雪花算法,也可以自定义
- @TableField:用来指定表中的普通字段信息
需要使用@TableField的几种特殊情况
@TableField(value = "email") //变量名和字段名不一致
private String mail;
@TableField(exist = false)
private String address; //在数据库表中是不存在的
@TableField("is_married")
private Boolean isMarried;//变量名以is开头且是布尔值
@TableField("`order`")
private Integer order;//成员变量名与数据库关键字冲突
// 插入数据时进行填充
@TableField(select = false, fill = FieldFill.INSERT) //查询时不返回该字段的值
private String password;
常用配置
这些配置除了别名扫描包都是默认的
mybatis-plus:
type-aliases-package: com.itheima.mp.domain.po #别名扫描包:在定义map.xml写实体类类型时不用写全路径,写类简化名就行
mapper-locations: "classpath* :/mapper/**/*.xml" # Mapper.xml文件地址,默认值
configuration:
map-underscore-to-camel-case: true #是否开启下划线和驼峰的映射
cache-enabled: false #是否开启二级缓存
global-config:
db-config:
id-type: assign_id # id为雪花算法生成
update-strategy: not_null #更新策略:只更新非空字段
快速入门总结
MyBatisPlus使用的基本流程
- 引入起步依赖
- 自定义Mapper基础BaseMapper
- 在实体类上添加注解声明表信息
- 在application.yml中根据需要添加配置
二、核心功能
1.SQL条件构造器
- 前言:
由于很多业务增删改查的条件都很复杂,基于MP基本的增删改查方法(一般是基于ID)无法完成业务,所以需要使用条件构造器来构造条件
条件构造器类关系图:
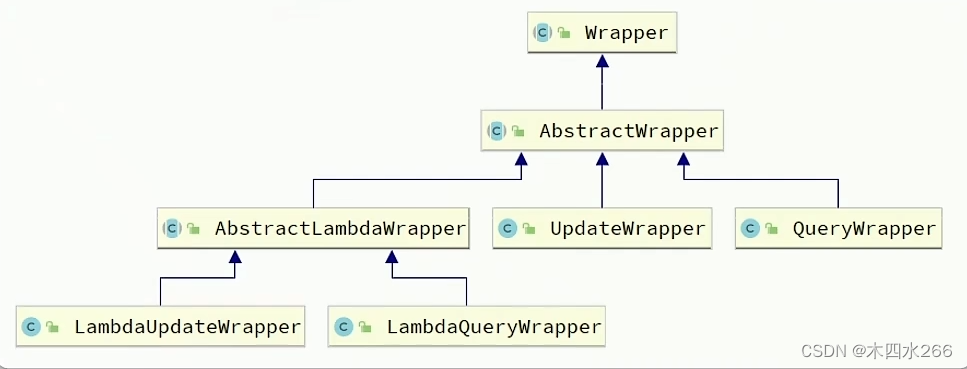
AbstractWrapper类:
where条件
- eq():等于
- ne():不等于
- gt():大于
- ge():大于等于
- lt():小于
- le():小于等于
- like():模糊
- nolike():非模糊
- in():在…内,如(1,2,3)
- between():如(1~3)
等
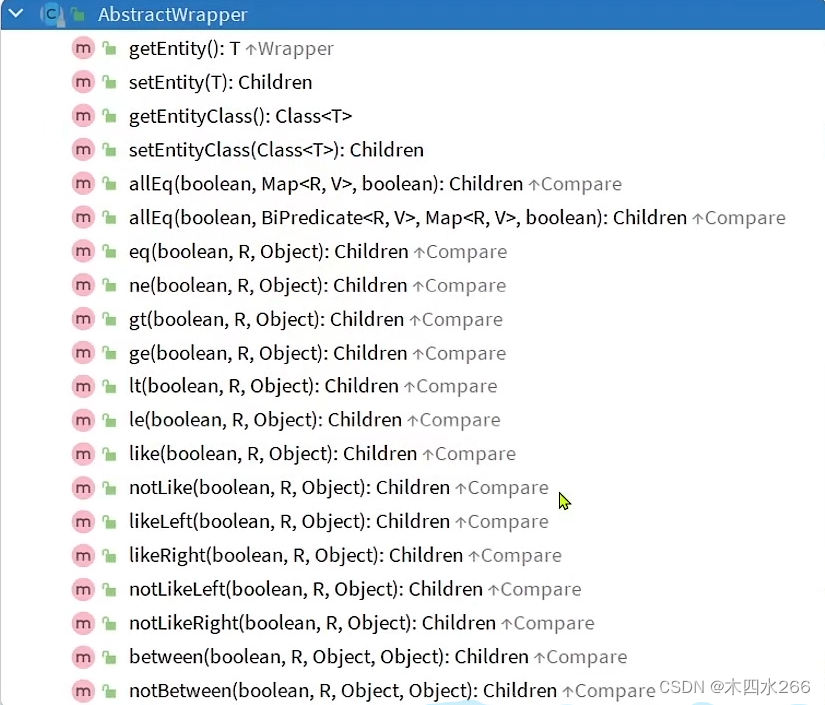
QueryWrapper类和UpdateWrapper类都继承了AbstractWrapper类所以都可以使用where条件的构造
事例:
QueryWrapper<User> wrapper = new QueryWrapper<>();
//查询条件
wrapper.eq("password", "123456");//password等于123456记录
wrapper.ge("age","10");//age大于等于10记录
wrapper.like("name","李");//name里有李的记录
wrapper.in("id","1,2,3");//ID在1,2,3内的记录
// 查询的数据超过一条时,会抛出异常
User user = this.userMapper.selectOne(wrapper);
- QueryWrapper类:
select部分
select哪些字段:
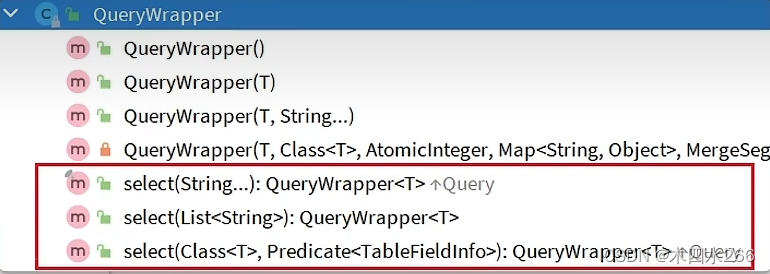
事例:
wrapper.select("id","name","age"); //指定查询的字段
- UpdateWrapper类
set部分
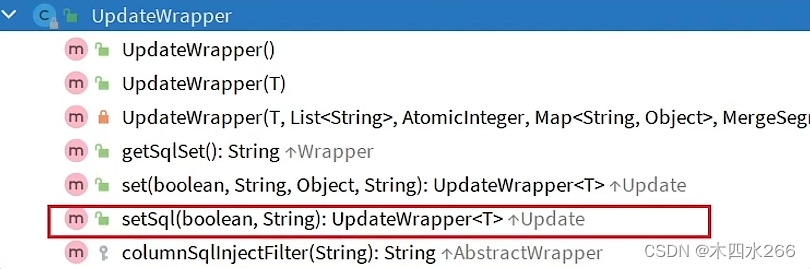
事例:
UpdateWrapper<User> wrapper = new UpdateWrapper<>();
wrapper.set("age", 21).set("password", "999999") //更新的字段
.eq("user_name", "zhangsan"); //更新的条件
//根据条件做更新
int result = this.userMapper.update(null, wrapper);
由于这些条件构造器类都是硬编码,直接写字符串魔法值,不符合规范,所以一般使用LambdaAbstractWrapper类
LambdaAbstractWrapper类
这些类用法和AbstractWrapper类 一样,不过是使用Lambda来构造条件,不在硬编码
- LambdaAbstractWrapper类 和LambdaQueryWrapper类
事例:
LambdaQueryWrapper<User> queryWrapper = new LambdaQuerWrapper<>();
queryWrapper
.ge(User::getAge,"10")// age>=10
.like(User::getUserName,"l")// %l%
.select(User::getUserName,User::getAddress);// 查询username和address字段
//.selectOne();这是条件不能直接写crud方法,可以用lambdaQuery或lambdaUpdate类这些类不用new Wrapper条件
- LambdaUpdateWrapper类
事例:
LambdaUpdateWrapper<User> updateWrapper = new LambdaUpdateWrapper<>();
updateWrapper
.set(User::getPassword,"123")//设置密码为123
.setSql("age = age - 10");//将age-10 自定义set
2.自定义SQL
原因:
一条SQL语句有多个部分(select、set、where等)组成,在一些复杂的业务场景中使用MP生成SQL语句是要在业务层上编写SQL语句(如setSql()这个方法就是),不符合规范。只允许在map或者map.xml中定义SQL,此时就得自定义SQL
如: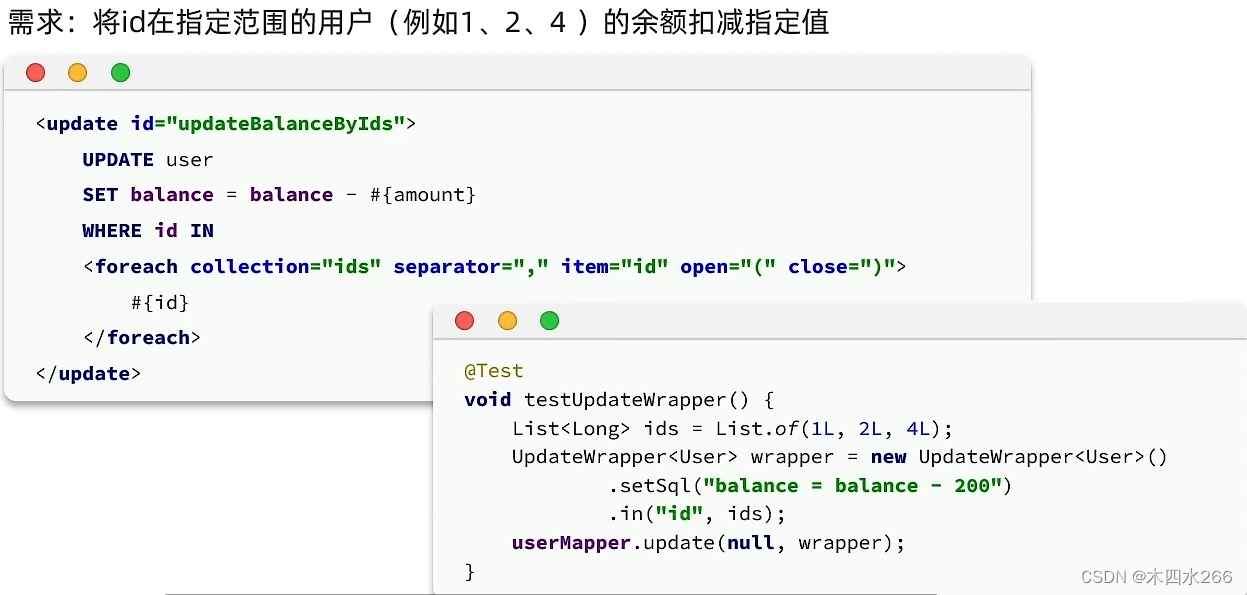
这就是在业务层编写SQL语句
LambdaUpdateWrapper<User> updateWrapper = new LambdaUpdateWrapper<>();
updateWrapper
.set(User::getPassword,"123")//设置密码为123
.setSql("age = age - 10");//将age-10 自定义set
解决:
用MP(业务层上写)构建复杂where条件,剩下的SQL语句自定义,然后在map或map.xml文件上拼接
使用步骤:
需求: 将id在指定范围的用户(例如1、2、4)的余额扣减指定值
- 基于Wrapper构建where条件,在业务层
List<Long> ids = List.of(1L,2L,3L);
int amount = 200;
//1.构建where条件
LambdaQueryWrapper<User> Wrapper = new LambdaQueryWrapper<User>().in(User::getId,ids);
//2.自定义SQL方法调用
userMapper.updateBalanceByIds(Wrapper,amount);
- 在mapper方法参数中用Param注解声明变量名称,wrapper条件参数必须是"ew",其他参数根据业务定义,持久层
void updateBalanceByIds(@Param("ew") LambdaQueryWrapper<User> wrapper, @Param("amount") int amount);
- 在map.xml(map)自定义SQL,并使用Wrapper条件,用${ew.customSqlSegment}拼接
<update id="updateBalanceByIds">
update tb_user set balance = balance - #{amount} ${ew.customSqlSegment}
</update>
3.使用Service接口
原因:
平时service接口还需要自定义增删改查方法来调用map的方法。而对于基本的增删改查service方法也可以不用编写,可以使用MP的Service接口的方法直接调用
使用步骤
####1. 自定义Service接口继承IService接口(MP的)
继承了MP的Service方法没有实现,所以在自定义Service实现类再继承MP的ServiceImpl类
//泛型为实体类类型
public interface ITbUserService extends IService<TbUser> {
}
-
自定义Service实现类,实现自定义接口并继承ServiceImpl类(MP的)
指定泛型自定义map是Service底层自己调用
@Service
// 继承MPServiceImpl 自定义map 实体类类型 实现自定义Service
public class TbUserServiceImpl extends ServiceImpl<TbUserMapper, TbUser> implements ITbUserService {
}
}
- 在Controller类中注入使用
一般在Controller中注入都是使用@AutoWrite注解,但这样的方式spring不推荐,spring推荐使用构造函数注入。
不想写构造函数,用lombok的注解来生成构造函数
在使用Controller时先思考MP有没有提供对应的Service方法给我们调用,没有在自己写
@RestController
@RequestMapping("/open")
//@AllArgsConstructor//该注解构造函数所有成员变量都注入
@RequiredArgsConstructor//部分参数注入,如加了final的常量成员变量
public class CourseOpenController {
//lombok注解构造函数注入
private final CourseBaseInfoService courseBaseInfoService;
//自动注入
//@Autowired
//private CourseBaseInfoService courseBaseInfoService;
}
IService接口各类方法
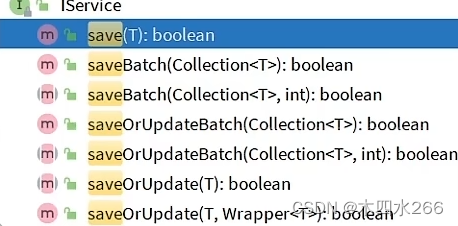
- 新增
saveOrUpdate()在传入的参数中有ID时为更新,没有为新增
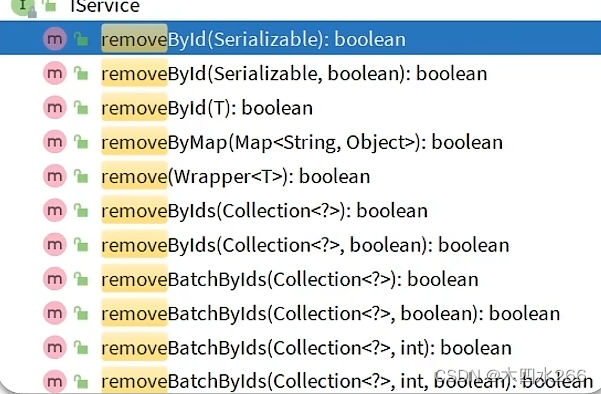
- 删除
- removeByIds()和removeBatchByIds()区别:
removeByIds()是使用delete 条件 in()来一个个删除
removeBatchByIds()是使用delete 条件 id = 来,但gdbc的批处理来批量提交批量删,在数据量大时效率更高
-
更新
-
查询一个
-
查询多个
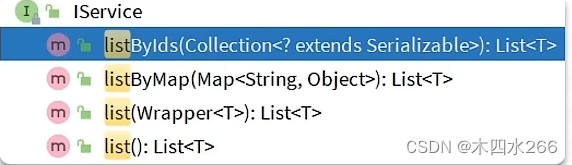
-
查询数量
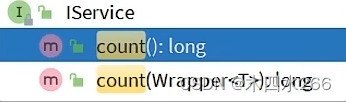
-
分页查询
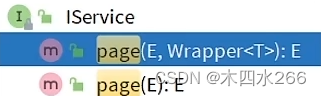
9. lambda链式编程实现查询条件,不用再new wrapper条件
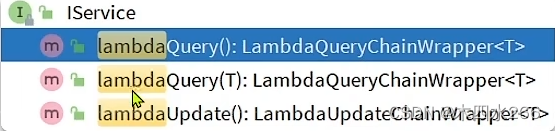
例:

用MB,xml文件写的SQL语句
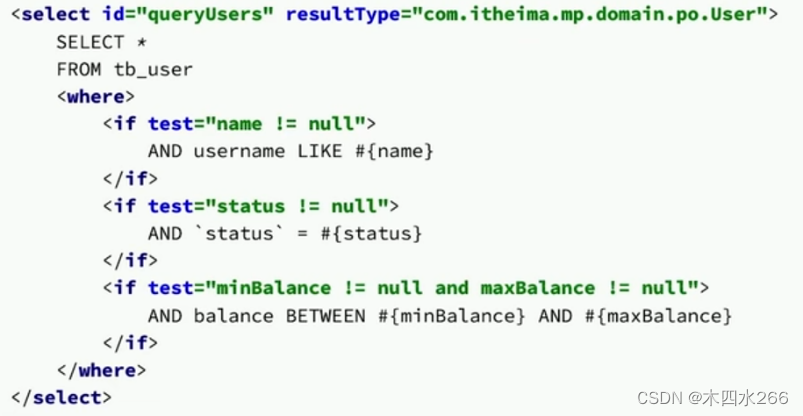
使用lambdaQuery():
返回值类型 返回值 = lambdaQuery()
.where条件(条件,参数类型,参数)
多个.list()一个.one(),分页查询.page(),是否存在.exists(),计数.count();
@Service
// 继承MPServiceImpl 自定义map 实体类类型 实现自定义Service
public class TbUserServiceImpl extends ServiceImpl<TbUserMapper, TbUser> implements ITbUserService {
@Override
public List<TbUser> queryUsers(String name,Integer status,Integer minBalance,Integer maxBalance) {
List<TbUser> list = lambdaQuery()
.like(name != null, TbUser::getUsername, name)
.eq(status != null, TbUser::getStatus, status)
.ge(minBalance != null, TbUser::getMinBlance, maxBalance)
.le(maxBalance != null, TbUser::getMaxBalance, maxBalance)
.list();//一个.one(),分页查询.page(),是否存在.exists(),计数.count()
return list;
}
}
使用lambdaUpdate():
lambdaUpdate()
.set(条件,参数类型,参数)
.where条件(条件,参数类型,参数)
.update();
//.update();是一定要加的要不不能更新。
批处理方案
1.普通for循环逐条插入速度极差﹐不推荐
- 每一次请求只提交一条SQL语句,数据量越多,网络请求就越多,耗时就越多
- 每一条SQL都是逐条执行的,执行性能也差
2.MP的批量新增·基于预编译的批处理·性能不错
- 比如一次性编译1000条SQL一次性提交,减少网络请求的次数
- 但每次也只是一条SQL执行一行数据,不是真正的批处理,只是批提交
3.MySql数据库配置jdbc参数,开启预编译rewriteBatchedStatements=true参数
- 会把一批SQL语句处理成一条SQL语句
- 在配置数据库URL上添加
三、扩展功能
1.po,service,map,controller代码生成
1.使用官方提供的mybatisx,编写代码生成模版来生成代码
官方代码生成
2.使用mybatisplus插件,使用这个插件只需要简单配置就能生成代码
- 下载mybatisplus插件
在下载完成后会出现一个other标签
- 点击other标签,配置数据库信息,要选择连接的数据库

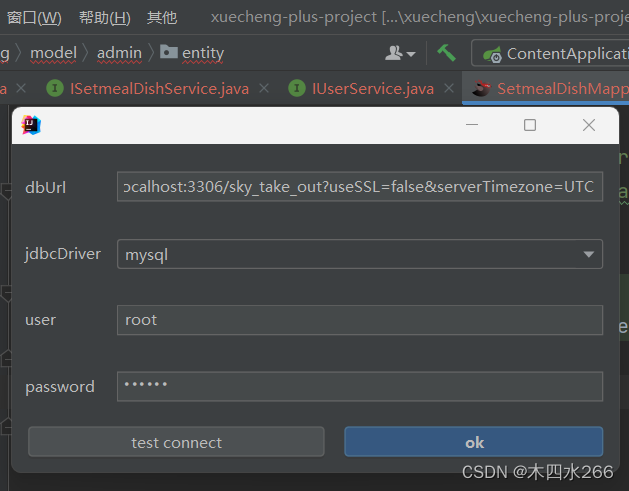
- 为生成代码填写信息
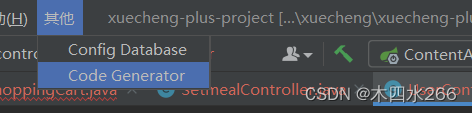
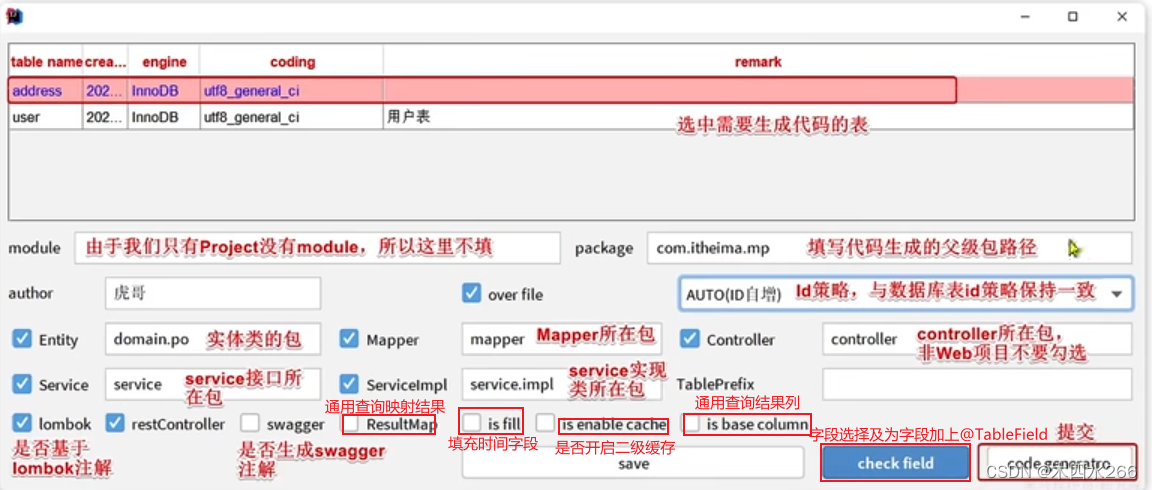
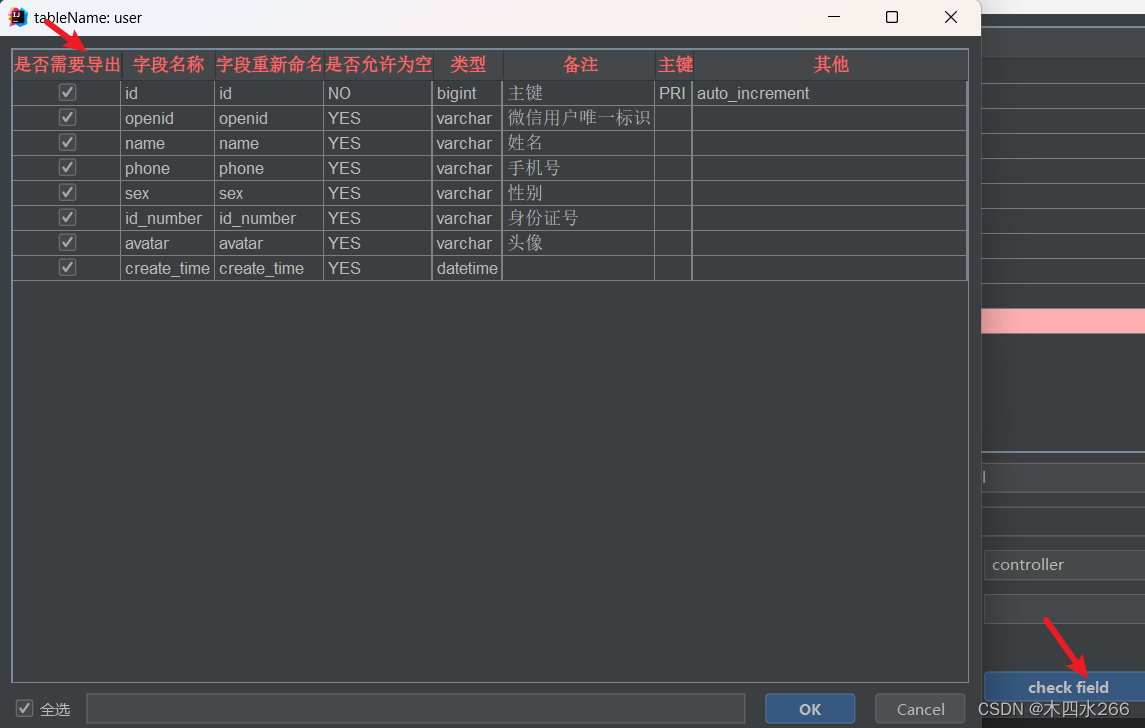
选择要查询出的字段
2.Db静态工具(IService的静态方法)
在开发业务时会出现多个Service之间互相调用,采用@AutoWrite的方式注入,那Service之间相互注入会出现循环依赖,给开发带来麻烦。所以在出现Service互相调用时,可以使用Db静态工具来去调用。
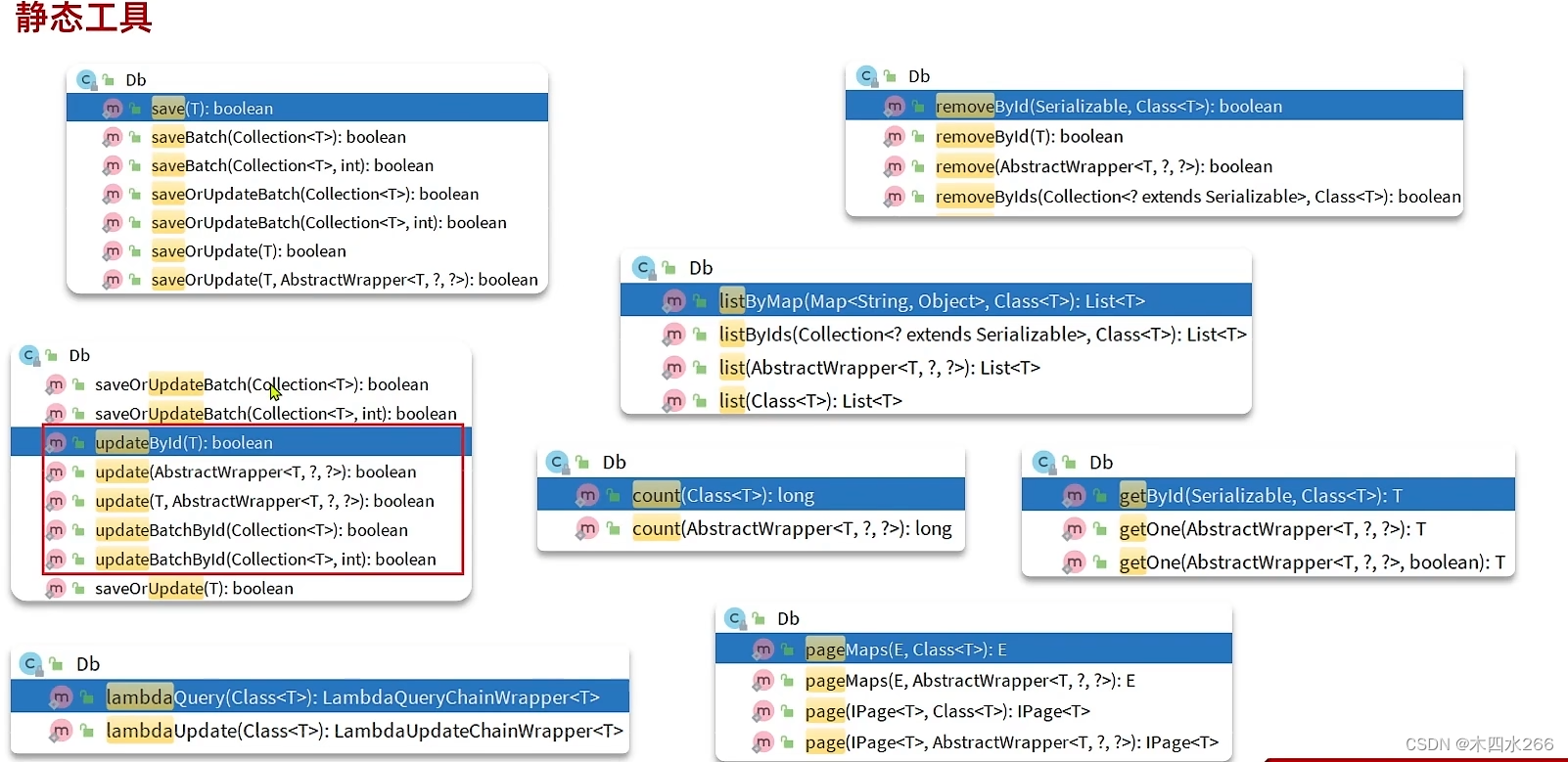
用法:
和IService的使用方法类似,不同的是在调用时要指定Class类型
Db.lambdaQuery(Setmeal.class).eq(Setmeal::getName,name).one();
3.逻辑删除
在有些业务中如:用户在购买商品后产生了订单,有使用户会把订单删除,但对于商家而言订单是重要数据,不用删除。所以这时就需要使用逻辑删除。
逻辑删除就是基于代码逻辑模拟删除效果,但并不会真正删除数据。思路如下:
- 在表中添加一个字段标记数据是否被删除
- 当删除数据时把标记置为1
- 查询时只查询标记为0的数据
//删除操作
UPDATE user SET deleted = 1 WHERE id = 1 AND deleted = 0
//查询操作
SELECT * FROM user WHERE deleted = 0
自己实现要在每条SQ语句上增加一个判断 deleted = 0,很麻烦,而MP提供了逻辑删除功能,无需改变方法调用的方式,而是在底层帮我们自动修改CRUD的语句。
MP逻辑删除方法:
- 在application.yaml文件中配置逻辑删除的字段名称和值即可:
mybatis-plus:
global-config:db-config:
logic-delete-field: flag # 全局逻辑删除的实体字段名,字段类型可以是boolean、integer
logic-delete-value: 1 #逻辑已删除值(默认为1)
logic-not-delete-value: 0#逻辑未删除值(默认为0)
- 或者在需要逻辑删除的字段上加@TableLogic即可
注意:
逻辑删除本身也有自己的问题,比如:
- 会导致数据库表垃圾数据越来越多,影响查询效率.
- SQL中全都需要对逻辑删除字段做判断,影响查询效率。因此,我不太推荐采用逻辑删除功能,如果数据不能删除,可以采用把数据迁移到其它表的办法。
4.枚举处理器
mybatis已经实现了其他Java数据类型和数据库中字段之间的相互转换
作用: JavaPO类中的枚举类型和数据库中字段之间的相互转换
方法:
- 给枚举中的与数据库对应value值添加@EnumValue注解
@JsonValue//用于告诉springmvc返回前端的是哪一个值,默认是枚举的名字
@Getter
public enum SexEnum implements IEnum<Integer> {
MAN(1,"男"),
WOMAN(2,"女");
@EnumValue
@JsonValue//用于告诉springmvc返回前端的是哪一个值,默认是枚举的名字
private int value;
private String desc;
SexEnum(int value, String desc) {
this.value = value;
this.desc = desc;
}
@Override
public Integer getValue() {
return this.value;
}
@Override
public String toString() {
return this.desc;
}
}
- 在配置文件中配置统一的枚举处理器,实现类型转换
mybatis-plus:
configuration:
default-enum-type-handler: com.baomidou .mybatisplus.core.handlers.MybatisEnumTypeHandler
5.JSON处理器
实现Java实体类中的成员变量(对象)和数据库中字段(JSON类型)之间的相互转换
- 为对象变量加上@TableField(TypeHandler = JacksonTypeHandler.class)
@TableField(TypeHandler = JacksonTypeHandler.class)
private UserInfo userInfo;
- @TableName加上自动映射,因为在类内使用对象成员变量会出现对象的嵌套,要在xml文件上加上ResultMap映射(通用查询映射结果)
@TableName("tb_user",autoResultMap = true)
但在一般的业务开发中,JAVA a类内还是用string来存储b类对象信息,但是JSON格式,数据库中a类对应的a表存储b类对象信息是text类型。而b类信息用另一个b表来存储,使用id逻辑外键关联a表,查出该b表信息再转为JSON。而不是对象的嵌套。
四、插件
1.分页插件
步骤:
1. 编写分页插件配置类
分页插件底层是基于拦截器来完成的,通过拦截SQL语句来实现分页
@Configuration
@MapperScan("com.xuecheng.content.mapper")
public class MybatisPlusConfig {
/**
* 定义分页拦截器
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
//核心拦截器
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
//分页插件
PaginationInnerInterceptor pageInterceptor = new PaginationInnerInterceptor(DbType.MYSQL);
//设置分页参数
pageInterceptor.setMaxLimit(1000L);//分页上限
//还可以添加MP的其他插件如乐观锁插件等
interceptor.addInnerInterceptor(pageInterceptor);
return interceptor;
}
}
2. 使用分页插件API
Page<PO> page = new Page<Setmeal>(pageNo, pageSize);
page = ServiceImpl.page(page,wrapper);
page.getTotal();
page.getPages();
例子
// 1.查询
int pageNo = 1, pageSize = 5;
//1.1.分页参数
Page<Setmeal> page = new Page<Setmeal>(pageNo, pageSize);
// 1.2.排序参数,通过orderItem来指定
page.addOrder(new OrderItem("balance", false));
// 1.3.分页查询
Page<Setmeal> p = this.page(page);
//2.总条数
System.out.println("total = " + p.getTotal());
// 3.总页数
System.out.println("pages = " + p.getPages());
//4.分页数据
List<Setmeal> records = p.getRecords();
records.forEach(System.out::println);
3. 编写通用page请求参数,page返回值
通用分页参数
@Data
@ApiModel(description = "分页查询实体")
public class PageQuery {
@ApiModelProperty("当前页码")
private Integer pageNo;
@ApiModelProperty("当前页记录数")
private Integer pageSize;
@ApiModelProperty("排序字段");
private string sortBy;
@ApiModelProperty("是否升序")
private Boolean isAsc;
/**
因为每一个分页查询都需要构建分页条件,并且和业务不相关。所以可以在通用分页参数实现方法,直接调用就能返回分页条件
*/
//构建分页条件
public<T> Page<T> toMpPage(OrderItem...items){
// 1.分页条件
Page<T> page=new Page<T>(pageNo,pageSize);
//2.排序条件
if(Strutil.isNotBlank(sortBy)){
//sortBy不为空
page.addOrder(new OrderItem(sortBy,isAsc));
}else if(items!=null){
//items不为空,默认排序
page.addorder(items);
}
return page;
}
//传入排序字段和是否升序构建分页条件
public<T> Page<T> toMpPage(String defaultSortBy,Boolean defaultAsc){
return toMpPage(new OrderItem(defaultSortBy,defaultAsc));
}
//默认以创建时间为排序字段,降序构建分页条件
public<T> Page<T> toMpPageDefaultsortByCreateTime(){
return toMpPage(new OrderItem("create_time",false));
}
//默认以更新时间为排序字段,降序构建分页条件
public<T> Page<T> toMpPageDefaultsortByUpdateTime(){
return toMpPage(new OrderItem("update_time",false));
}
}
分页查询条件,继承通用分页参数
@EqualsAndHashCode(callsuper = true)
@Data
@ApiModel(description = "用户查询条件实体")
public class userQuery extends PageQuery {
//查询条件
@ApiModelProperty("用户名关键字")
private String name;
@ApiModelProperty("用户状态:1-正常,2-冻结")
private Integer status;
@ApiModelProperty("余额最小值")
private Integer minBalance;
@ApiModelProperty("余额最大值")
private Integer maxBalance;
}
通用返回值
@Data
@ApiModel(description = "分页结果")
public class PageDTO<T> {
@ApiModelProperty("总条数")
private Long total;
@ApiModelProperty("总页数")
private Long Pges;
@ApiModelProperty("集合")
private List<T> list;
public static <PO,VO> PageDTO<VO> of(Page<PO> p,Class<VO> clazz Function<PO,VO> convertor) {
PageDTO<VO> dto = new PageDTO<>();
//1.总条数
dto.setTotal(p.getTotal());
// 2. 总页数
dto.setPages(p.getPages());
// 3. 当前数据
List<PO> records = p.getRecords();
if (CollectionUtils.isEmpty(records)) {
dto.setList(Collections.emptyList());
return dto;
}
//4. 拷贝user的vo
//dto.setList(BeanUtil.copyToList(records,clazz));
/ / 4.拷贝user 的VO
dto.setList(records.stream().map(convertor).Collect(collectors.tolist()));
//5. 返回
return dto;
}
}
/ /3.封装Vo结果
I
return PageDTo.of(p,user -> {
// 1.拷贝基础属性
Uservo vo = Beanutil.copyProperties(user,Uservo.class);
//2.处理特殊逻辑
vo.setUsername(vo.getUsername( ).substring(0,vo.getUsername().length() - 2) + "**");
return vo;
});
of()方法是别的对象转为当前对象
to*()方法是把当前对象转为别的对象















 1405
1405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









