






这里写目录标题
运用两种方法进行爬取
方法一
import requests
from lxml import etree
import random
UAlist = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',
'Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Mobile/15E148 Safari/604.1 Edg/122.0.0.0',
'Mozilla/5.0 (Linux; Android 8.0.0; SM-G955U Build/R16NW) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Mobile Safari/537.36 Edg/122.0.0.0'
]
headers = {"User-Agent":random.choice(UAlist)}
#range 包前不包后
urls = ['https://www.xswang.vip/book/59716/{}.html'.format(i) for i in range(56867870, 56867950)]
# 设置小说地址
path = r'你想要保存的路径'
#获取小说内容
def get_novel(url):
res = requests.get(url)
res.encoding = 'utf-8'
selector = etree.HTML(res.text)
# 获取文章标题
title = selector.xpath('//*[@id="main"]/div/div/div[2]/h1/text()')
# 获取小说内容
text = selector.xpath('//*[@id="content"]/p/text()')
# 下载提示
print('正在下载:',title[0])
# 写入小说
with open(path + title[0] + ".txt",'w',encoding='utf-8') as f:
for i in text:
f.write(i)
f.write('\n')
if __name__ == '__main__':
# enumerate会获取列表的索引和元素值
for index,url in enumerate(urls):
get_novel(url)
if index == len(urls)-1:
print('下载完成!')
以上为代码全图
代码详解
1.首先我们导入我们所需的库
import requests
from lxml import etree
import random
requests:用于http请求
lxml.etree:用于解析html文档
random:用于生成随机数
2.伪装请求头
UAlist = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',
'Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Mobile/15E148 Safari/604.1 Edg/122.0.0.0',
'Mozilla/5.0 (Linux; Android 8.0.0; SM-G955U Build/R16NW) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Mobile Safari/537.36 Edg/122.0.0.0'
]
headers = {"User-Agent": random.choice(UAlist)}
定义了一个UAlist的列表,其中存放了不同的User-Agent来构建一个UA池,同时引用radom随机函数可以在多个User-Agent随机选择一个,以此来达到伪装请求头的效果
3.构建爬取页面url
urls = ['https://www.xswang.vip/book/59716/{}.html'.format(i) for i in range(56867870, 56867880)]
构建url列表urls,并用推导式生成一系列的网站url,注意range函数包前不包后,因此需要往后+1,根据自己所需来填写
4.设置文件保存路径
path = r'你想要保存的路径'
定义文件保存路径,储存小说内容文件,并且以原始字符串保存,r不会使得反斜杠\被转义,避免路径被误解
5.获取小说内容与标题
def get_novel(url):
res = requests.get(url)
res.encoding = 'utf-8'
selector = etree.HTML(res.text)
首先定义get_novel(url)函数来获取小说的标题和内容,通过get请求获取内容,并将获取到的res响应文件通过utf-8进行编码,这里可以根据网页的编码模式进行更改,最后通过lxml库中的etree方法将res中的html文本构建为一个element对象,这样便可以通过XPath来定位对象中的子元素
title = selector.xpath('//*[@id="main"]/div/div/div[2]/h1/text()')
text = selector.xpath('//*[@id="content"]/p/text()')
使用XPath表达式从Element对象selector中提取特定元素的文本内容,并储存在变量title中
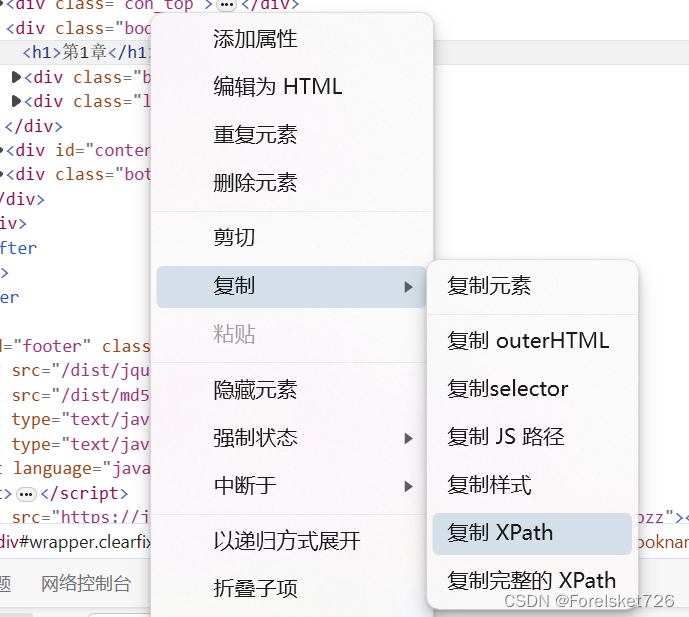
获取网页XPath的方法
首先打开网页,找到标题

按住Shift+Ctrl+C选中元素进行查看,获取到具体的位置

右键<h1>复制—>复制XPath,即可获取XPath
6.写入小说
with open(path + title[0] + ".txt",'w',encoding='utf-8') as f:
for i in text:
f.write(i)
f.write('\n')
通过for循环遍历每一行文本,将获取到的小说内容txt作为 标题.txt 的txt文件命名保存在先前设置的路径里。
7.进行主程序逻辑,多次获取不同页面
if __name__ == '__main__':
# enumerate会获取列表的索引和元素值
for index,url in enumerate(urls):
get_novel(url)
if index == len(urls)-1:
print('下载完成!')
if __name__ == ‘__main__’::这行代码表示当前模块是作为主程序执行,而不是被引入到其他模块中。当这个模块被直接执行时,下面的代码将被执行。
enumerate 函数用于同时获取列表的索引和元素值,在每次循环中,index 表示当前元素的索引,url 表示当前元素的值。由于len是从0开始的所以需要在后面-1,而当if index == len(urls)-1时则输出下载完毕
















 3569
3569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









