







这一篇博客主要是对于刚学完request库想要找实战练习的小伙伴的,同时也希望大家取学习一下异步的概念,本次代码还运用到了线程池和xpath,有人说为啥不用协程,协程的话当时欧还没学,所以就拿线程池练练手了,现在分享给大家,希望对你们有所帮助。
1 获取笔趣阁小说网站
本次的笔趣阁小说网站为https://www.biqg.cc,我们选取一个小说作为我们爬取的目标,这里我选择《不科学御兽》了,大家也可以根据自己的需求进行修改。
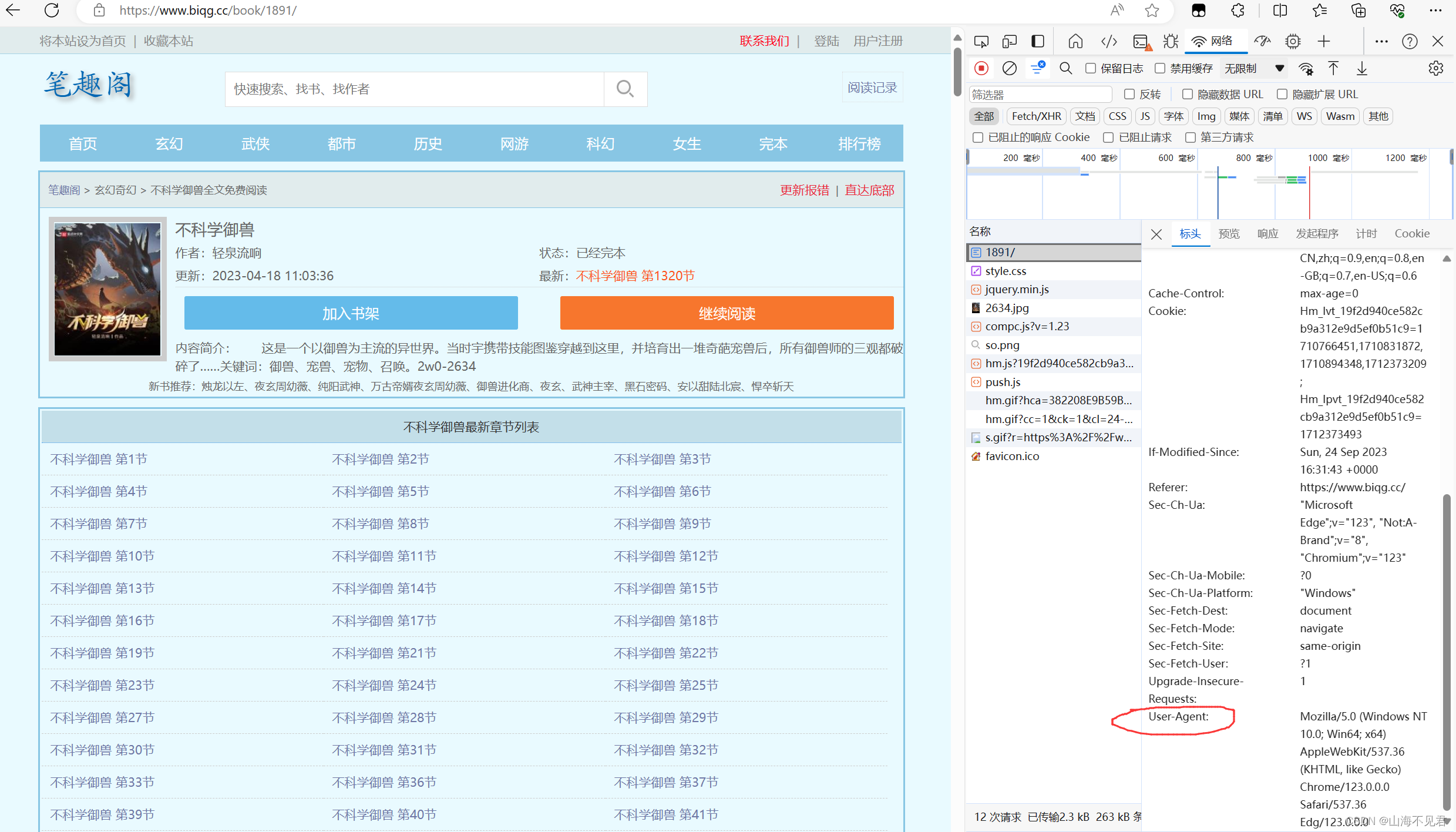
然后我们开始获取本网页的UA,为UA伪装做准备。
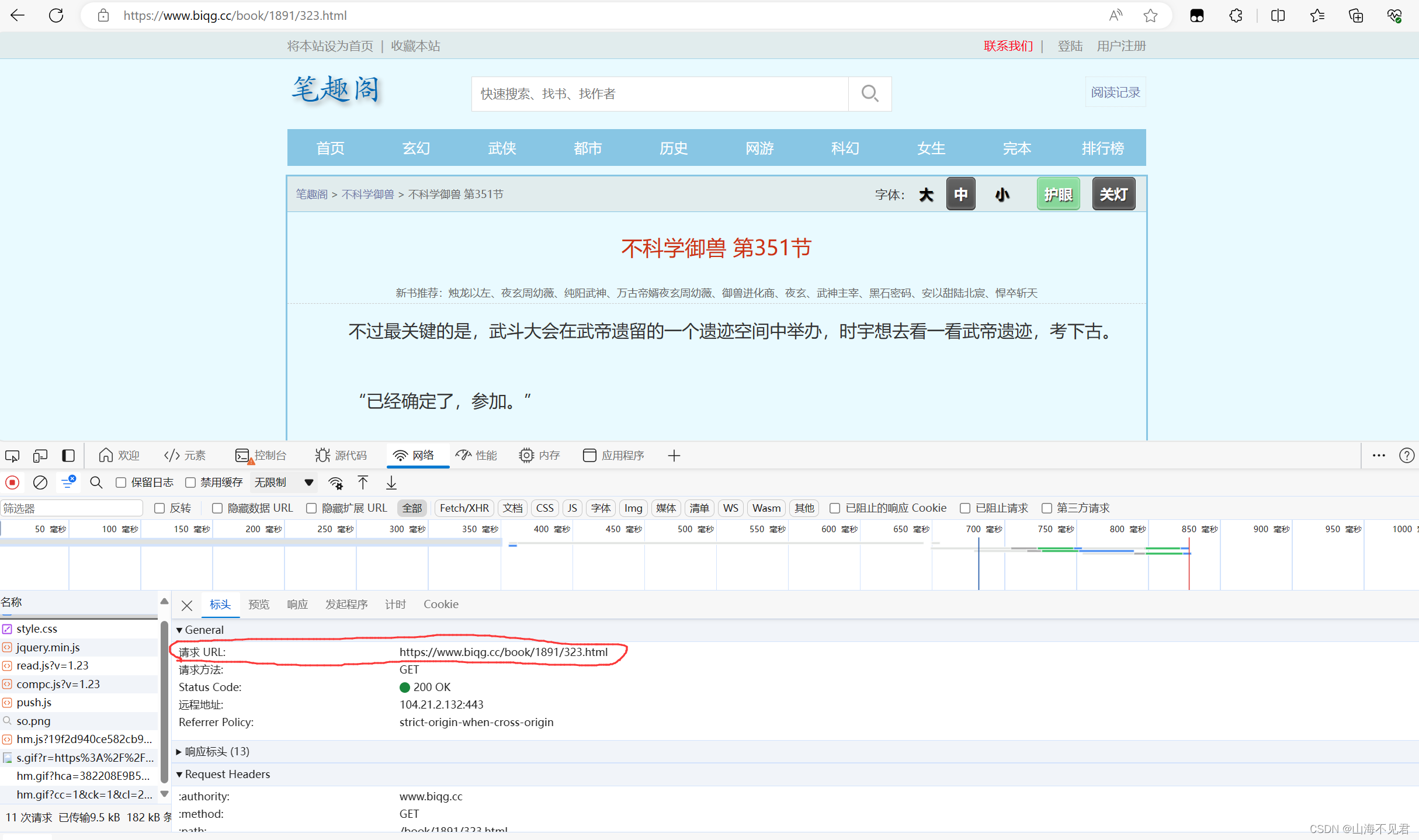
这里我们发现小说的每一章的网址都有一个共同的特征,就是后面的值都是x.html,其中x为小说的章节。
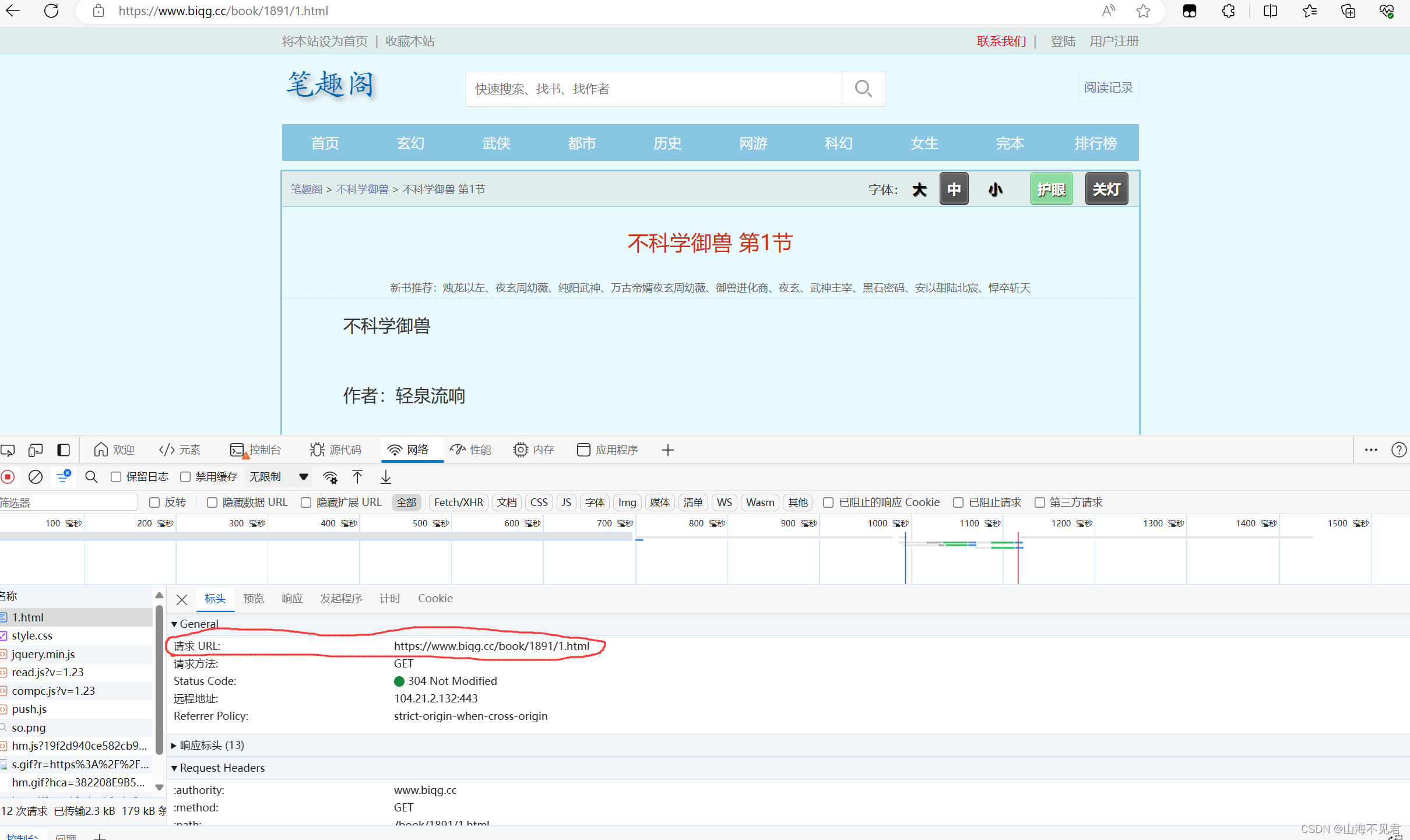
我们要获取所有章节共1320节,也就是说一共有1320个网址,我们要获取里面的内容,这里我将这些网址全部放在一个列表中,代码如下所示。
headers = {
"User-Agent": '......'
}
url_list = []
for k in range(1, 1321):
url = 'https://www.biqg.cc/book/1891/{}.html'.format(k)
url_list.append(url)2 获取小说内容
这里我们依旧使用xpath来进行抓包定位,首先我们开始创建一个xpath对象,其中url为url_list的一个元素。
rex = requests.get(url=url, headers=headers).text
tree = etree.HTML(rex)我们右击文章内容,进行抓包。

这里我们可以发现,第一节的小说内容全部放在div这个标签下面。
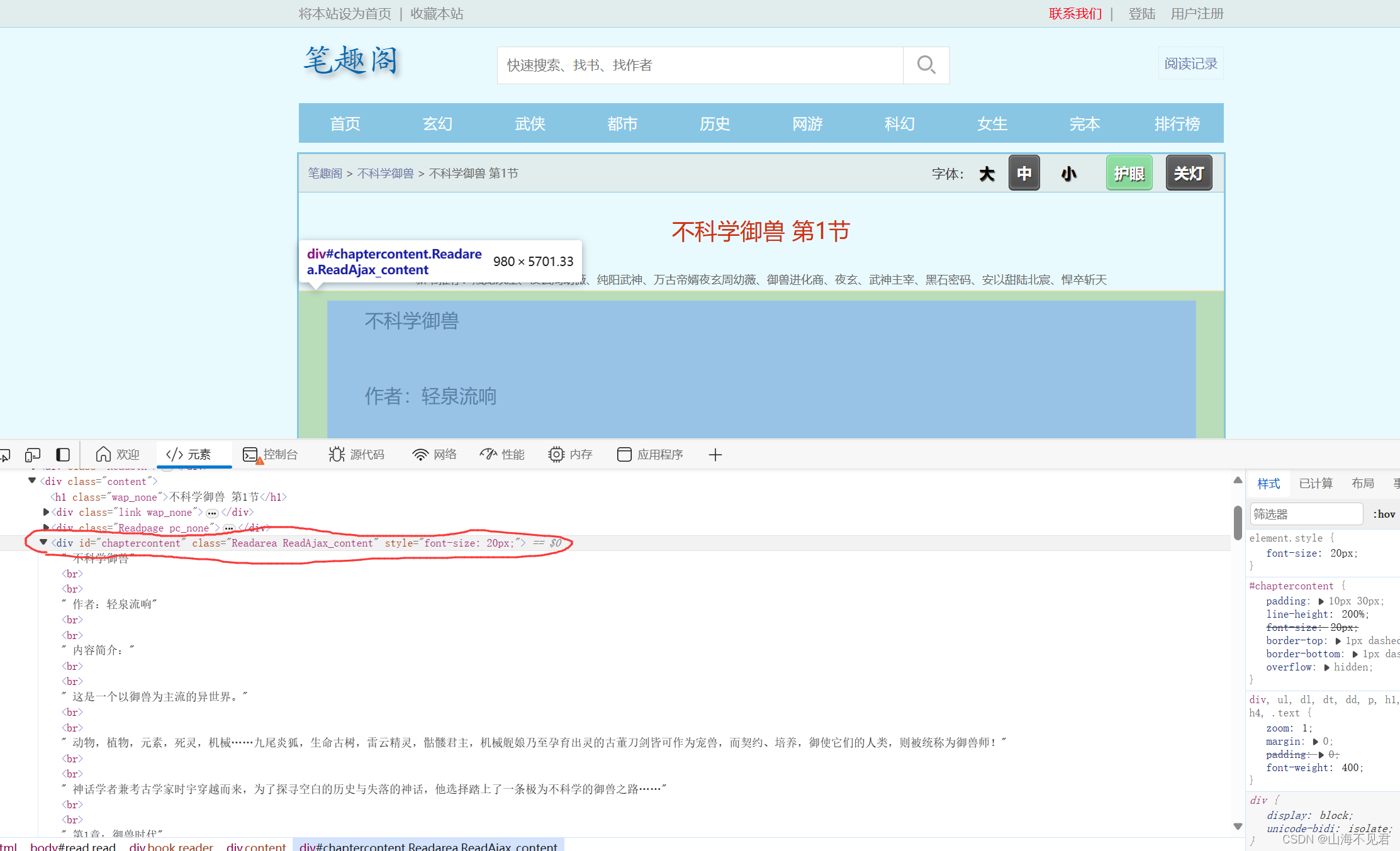
这里用xpath有两种方法,一种上篇讲过就是利用鼠标右键复制xpath路径,这里我们发现div标签有唯一标识id,所以我们利用id进行定位,然后用text()获取div下面的小说内容。
x = tree.xpath('//div[@id="chaptercontent"]//text()')然后我们打印x里面的小说内容,打印结果如下。

\u3000是一个全角的空白符,在文本中起到间隔和缩进的作用,所以不需要担心对文本有什么特别的影响,就是首行缩进两字符,到这里呢我们的小说内容也就获取完成了。
3 小说的保存
到这里我们利用os创建文件夹。
os.mkdir('不科学御兽')通过字符串操作获取其中的章节,然后对x进行遍历,将里面的内容打印到文件中去。
a = url[url.rfind('/') + 1:url.rfind('.')]
for i in x:
data = './不科学御兽/第{}章.txt'.format(a)
with open(data, 'a+', encoding='utf-8') as fp:
fp.write(i + '\n')
print('第{}章已经下载完成'.format(a))4 线程池操作
对于正常的操作,我们可以打印出来下完一本小说所需要的时间,结果如下。

这里我们可以看到平常的写法,下完一本小说一共需要1726秒的时间,这种方法耗时长,那我们利用线程池来进行操作看看效果如何,首先我们导入Pool包,创建线程对象。
from multiprocessing.dummy import Pool
pool = Pool()其中Pool()里可以添加线程池里面的线程数,这里默认为你计算机的最大值,我这里是192线程。然后封装对每一页网址的操作。
def fun(url):
rex = requests.get(url=url, headers=headers).text
tree = etree.HTML(rex)
x = tree.xpath('//div[@id="chaptercontent"]//text()')
a = url[url.rfind('/') + 1:url.rfind('.')]
for i in x:
y = i[2:]
data = './不科学御兽/第{}章.txt'.format(a)
with open(data, 'a+', encoding='utf-8') as fp:
fp.write(y + '\n')
print('第{}章已经下载完成'.format(a))最后利用pool.map()方法运行线程池,运行结束后关闭线程池。
pool.map(fun, url_list)
pool.close()
pool.join()运行结果如下。

这里我们可以发现运行时间119秒,比正常代码快乐16倍,大大提高了小说下载的效率。
这里小说获取情况也发一下截图。
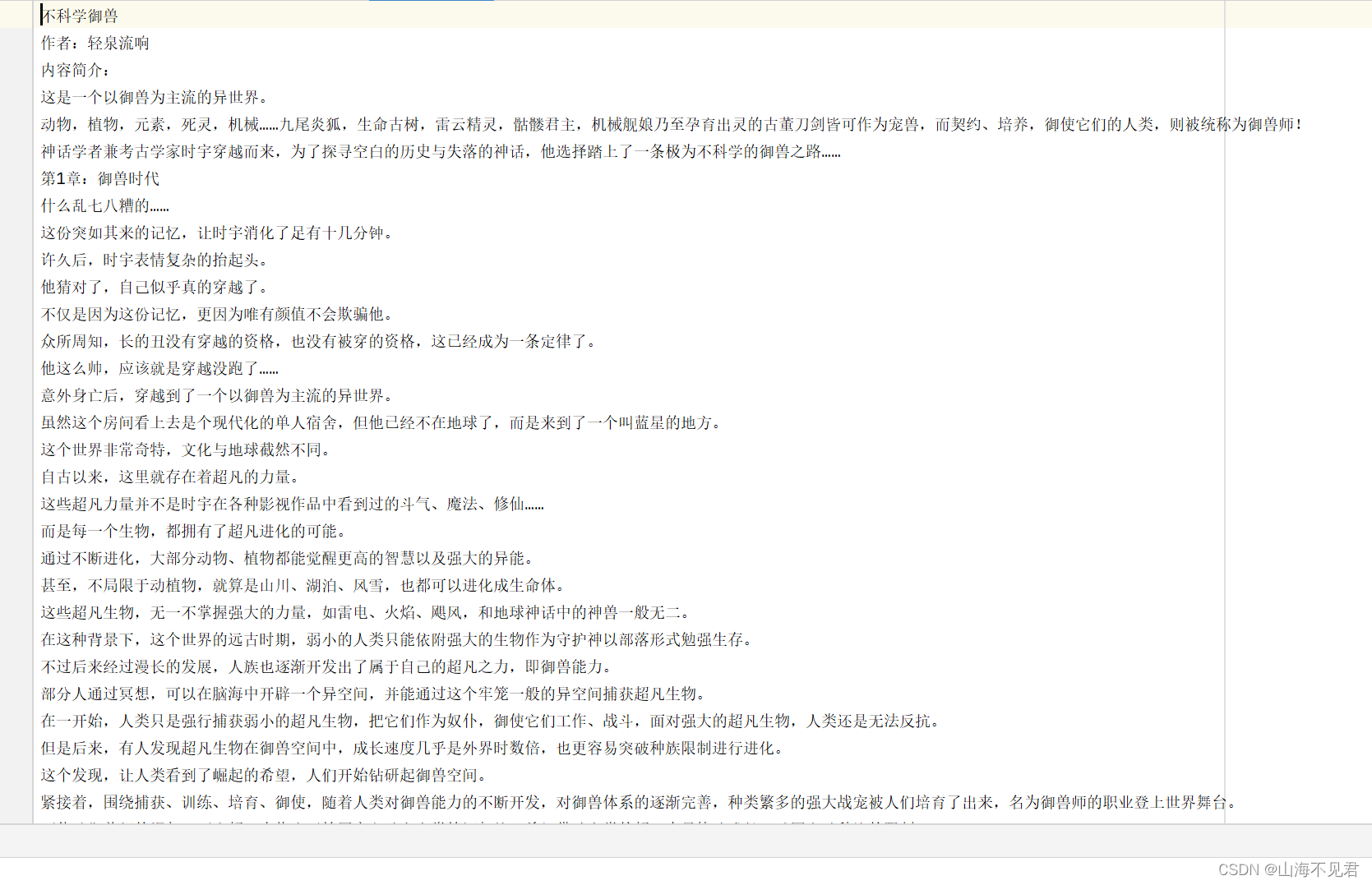
可以发现获取成功,到这里本博客的内容已经结束了,希望这一篇博客对大家有所帮助!
5 代码
5.1 正常代码
import os
import time
import requests
from lxml import etree
from multiprocessing.dummy import Pool
if __name__ == '__main__':
start_time = time.time()
os.mkdir('不科学御兽')
headers = {
"User-Agent": '......'
}
url_list = []
for k in range(1, 1321):
url = 'https://www.biqg.cc/book/1891/{}.html'.format(k)
url_list.append(url)
for url in url_list:
rex = requests.get(url=url, headers=headers).text
tree = etree.HTML(rex)
x = tree.xpath('//div[@id="chaptercontent"]//text()')
a = url[url.rfind('/') + 1:url.rfind('.')]
for i in x:
data = './不科学御兽/第{}章.txt'.format(a)
with open(data, 'a+', encoding='utf-8') as fp:
fp.write(i + '\n')
print('第{}章已经下载完成'.format(a))
end_start = time.time()
print('总耗时{}秒'.format(end_start - start_time))5.2 线程池代码
import os
import time
import requests
from lxml import etree
from multiprocessing.dummy import Pool
def fun(url):
rex = requests.get(url=url, headers=headers).text
tree = etree.HTML(rex)
x = tree.xpath('//div[@id="chaptercontent"]//text()')
a = url[url.rfind('/') + 1:url.rfind('.')]
for i in x:
y = i[2:]
data = './不科学御兽/第{}章.txt'.format(a)
with open(data, 'a+', encoding='utf-8') as fp:
fp.write(y + '\n')
print('第{}章已经下载完成'.format(a))
if __name__ == '__main__':
start_time = time.time()
os.mkdir('不科学御兽')
headers = {
"User-Agent": '......'
}
url_list = []
for k in range(1, 1321):
url = 'https://www.biqg.cc/book/1891/{}.html'.format(k)
url_list.append(url)
pool = Pool()
pool.map(fun, url_list)
pool.close()
pool.join()
end_start = time.time()
print('总耗时{}秒'.format(end_start - start_time))














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









