






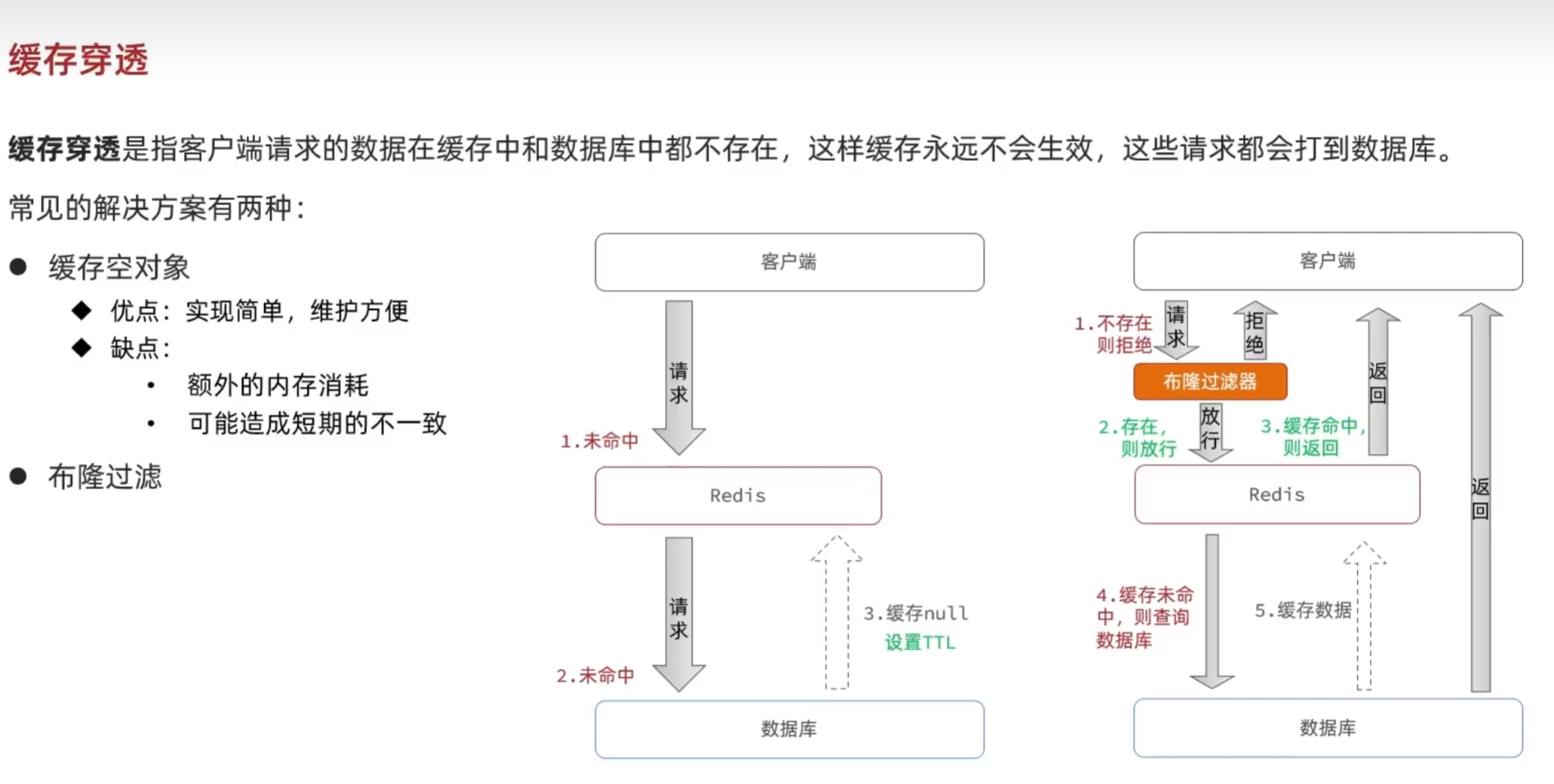
缓存穿透
1.缓存空对象
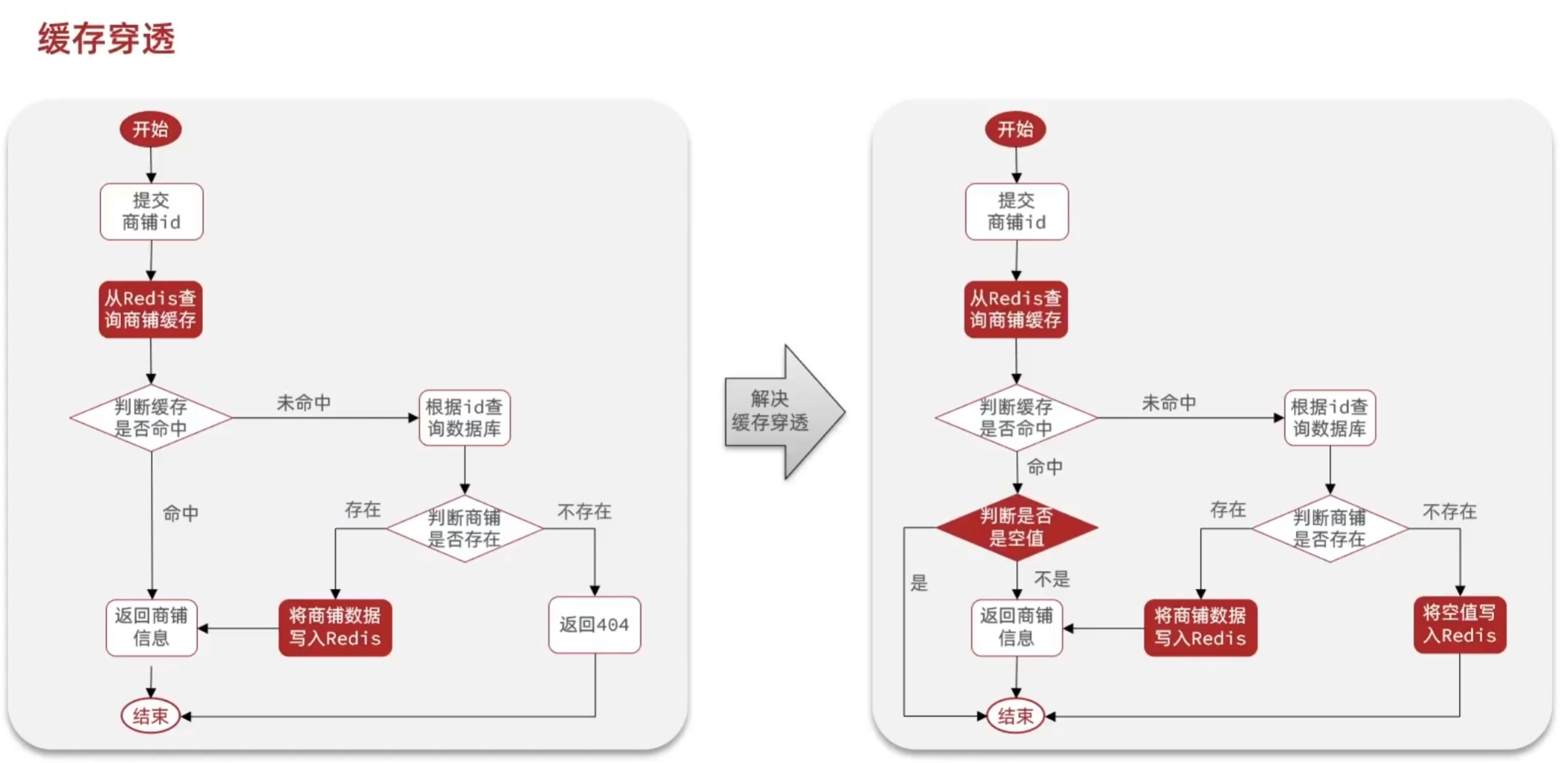
/**
* 缓存空值解决缓存穿透
* @param id
* @return
*/
@Override
public Result queryById(Long id) {
String cacheShopKey = CACHE_SHOP_KEY + id;
// 1.从Redis中查询id
String shopJson = stringRedisTemplate.opsForValue().get(cacheShopKey);
if (StrUtil.isNotBlank(shopJson)) {
// 2.命中返回商铺信息
return Result.ok(JSONUtil.toBean(shopJson, Shop.class));
}else if(shopJson != null){
// 2.1.缓存为空直接返回错误信息
return Result.fail("店铺信息不存在!");
}
// 3.未命中查询数据库
Shop shop = getById(id);
// 4.商铺不在数据库
if(shop == null){
// 4.1.缓存空值
stringRedisTemplate.opsForValue().set(cacheShopKey, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
// 4.2.返回错误信息
return Result.fail("店铺不存在");
}
// 5.商铺在数据库
// 5.1.保存到Redis中
stringRedisTemplate.opsForValue().set(cacheShopKey, JSONUtil.toJsonStr(shop));
stringRedisTemplate.expire(cacheShopKey, CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 5.2.返回商铺信息
return Result.ok(shop);
}2.布隆过滤器
布隆过滤器(Bloom Filter)是一种空间效率高的概率数据结构,用于测试一个元素是否属于一个集合。它可以有效地表示一个集合,并快速判断某个元素是否在集合中。布隆过滤器的核心思想是通过多个哈希函数对数据进行多次映射,从而减少存储空间,并提供快速的查询操作。
工作原理:
- 初始化: 初始化一个大小为 m 的位数组,每个位置初始值为 0。选择 k 个独立的哈希函数,每个哈希函数将输入元素映射到 [0, m-1] 范围内的一个位置。
- 添加元素:
-
- 对于要加入集合的每个元素,用 k 个哈希函数对该元素进行哈希运算,得到 k 个哈希值。
- 将这 k 个哈希值对应的位数组中的位置设为 1。
- 查询元素:
-
- 对于要查询的元素,同样使用 k 个哈希函数对该元素进行哈希运算,得到 kkk 个哈希值。
- 检查位数组中这 k 个位置,如果其中有任何一个位置为 0,则该元素一定不在集合中。
- 如果这 k 个位置全部为 1,则该元素可能在集合中。
布隆过滤器的优缺点:
优点:
- 空间效率高: 相比于直接存储所有元素,布隆过滤器使用的存储空间更少。
- 插入和查询速度快: 插入和查询操作的时间复杂度都是 O(k),其中 k 是哈希函数的个数。
缺点:
- 存在误判率: 布隆过滤器只能告诉你一个元素“可能在”集合中,或者“肯定不在”集合中。它会有一定的误判率,即可能会误认为一个不在集合中的元素在集合中。
- 删除操作困难: 一旦元素插入布隆过滤器后,就很难删除它们,因为无法确定某个位上的 1 是否是由多个元素共同设置的。
实现:
- 添加Guava依赖
在 pom.xml 中添加 Guava 依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
</dependency>- 定义布隆过滤器
在你的服务类中定义和初始化布隆过滤器:
/**
* 布隆过滤器解决缓存穿透
* @param id
* @return
*/
private BloomFilter bloomFilter;
@PostConstruct
public void init(){
// 初始化布隆过滤器,假设最多有1000000个店铺,误判率为0.01
bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8),
100000, 0.1);
// 预加载布隆过滤器
List<Shop> shopList = list();
for(Shop shop : shopList){
bloomFilter.put(CACHE_SHOP_KEY + shop.getId());
}
}
@Override
public Result queryById(Long id) {
String cacheShopKey = CACHE_SHOP_KEY + id;
// 1.布隆过滤器过滤,不存在直接返回错误信息
if(!bloomFilter.mightContain(cacheShopKey)){
return Result.fail("店铺不存在");
}
// 2.可能存在,从Redis中查询id
String shopJson = stringRedisTemplate.opsForValue().get(cacheShopKey);
if (StrUtil.isNotBlank(shopJson)) {
// 2.1命中返回商铺信息
return Result.ok(JSONUtil.toBean(shopJson, Shop.class));
}
// 3.未命中查询数据库
Shop shop = getById(id);
// 4.商铺不在数据库,返回错误信息
if(shop == null){
return Result.fail("店铺不存在");
}
// 5.商铺在数据库
// 5.1.保存到Redis中
stringRedisTemplate.opsForValue().set(cacheShopKey, JSONUtil.toJsonStr(shop));
stringRedisTemplate.expire(cacheShopKey, CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 5.2.返回商铺信息
return Result.ok(shop);
}效果:


postman请求id不在数据库中的商铺时,并没有从数据库中查取,直接被过滤掉了
















 251
251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









