






redis缓存击穿透题解决
1、为什么用redis作为缓存
使用缓存我们主要是保证系统的高性能和高并发(单机mysql 能承受的最大2000qps 超过容易报警,而使用redis作为缓存,它是基于内存操作的天然支持高并发,而mysql是基于磁盘操作的,单机redis支持三万到十万的qps单机承载量很高)
2、使用redis作为缓存会导致哪些问题
缓存穿透:
概念:用户需要查询一个数据,缓存中没有,也就是没有命中,于是向数据库中发起请求,发现也没有。当用户很多的时候,缓存都没有命中,于是都去请求数据库,这给数据库造成很大的压力。
解决方案:
- 布隆过滤器:是一种数据结构,对所有可能查询的参数以 hash 方式存储,先在控制层进行校验,不符合则丢弃,避免了过多访问数据库。
- 缓存空对象:当存储层没有命中时,即使返回空对象也将其缓存起来。(意味着更多的空间存储,即使设置了过期时间,缓存和数据库还是有段时间数据不一致。)
缓存击穿:
概念:当一个 key 非常热点时,在不断扛高并发,集中对这个热点数据进行访问,当这个 key 失效的瞬间,请求直接到达数据库,给数据库瞬间的高压力。
解决方案:
- 设置热点数据永不过期
- 加分布式锁:保证每个 key 同时只有一个线程去查询后端服务。
缓存雪崩:
概念:某个时间段,缓存集中失效
解决方案:
- 增加 Redis 集群的数量
- 缓存过期时间的时候,错峰设置
- 限流降级:在缓存失效后,通过加锁和队列来控制数据库写缓存的线程数量
- 数据预热:正式部署之前,将数据预先访问一遍,让缓存失效的时间尽量均匀
3、布隆过滤器
缓存空对象存在的问题:如果遇到黑客利用不存在的key进行攻击,我们还是缓存空值,那么缓存将会失去意义
将所有可能的查询key 先映射到布隆过滤器中,查询时先判断key是否存在布隆过滤器中,存在才继续向下执行,如果不存在,则直接返回。布隆过滤器将值进行多次哈希bit存储,布隆过滤器说某个元素在,可能会被误判。布隆过滤器说某个元素不在,那么一定不在。
布隆过滤器的原理:当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组中的 K 个点(offset),把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了:如果这些点有任何一个 0,则被检元素一定不在;如果都是 1,则被检元素很可能在。这就是布隆过滤器的基本思想。
简单来说就是准备一个长度为 m 的位数组并初始化所有元素为 0,用 k 个散列函数对元素进行 k 次散列运算跟 len(m)取余得到 k 个位置并将 m 中对应位置设置为 1。
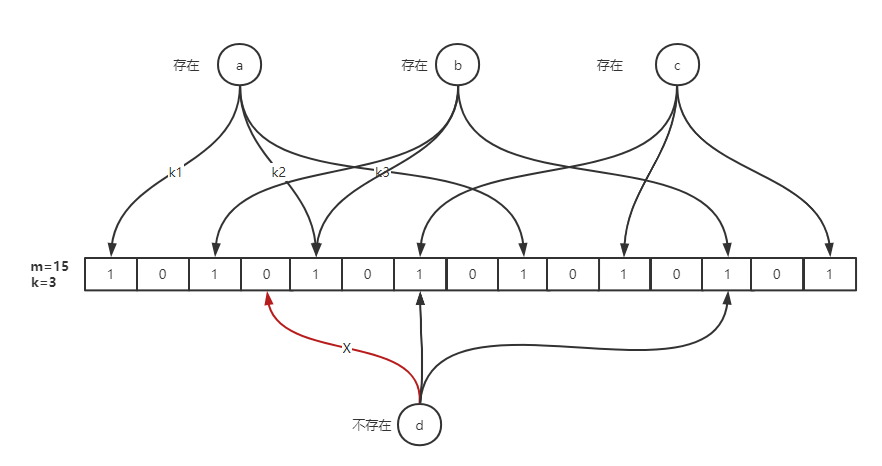
优缺点: 布隆过滤器 空间占用极小插入和查询速度是非常快 ,但存在误差(哈希冲突导致误判)
4、实现
1、将数据告知布隆过滤器
应用启动时初始化布隆过滤器
RBloomFilter<SomeObject> bloomFilter = redisson.getBloomFilter("sample");
// 初始化布隆过滤器,预计统计元素数量为55000000,期望误差率为0.03
bloomFilter.tryInit(55000000L, 0.03);
bloomFilter.add(new SomeObject("field1Value", "field2Value"));
bloomFilter.add(new SomeObject("field5Value", "field8Value"));
bloomFilter.contains(new SomeObject("field1Value", "field8Value"));
springboot提供两个接口:IOC容器创建完成后,初始化一些内容 用CommandlineRunner或者 ApplicationRuner
@Override
public void run(String... args) throws Exception {
RBloomFilter<Object> rbloomFilter = redissonClient.getBloomFilter(RedisConst.SKU_BLOOM_FILTER);
// 初始化布隆过滤器,预计统计元素数量为100000,期望误差率为0.01
rbloomFilter.tryInit(100000, 0.01);
}
添加到布隆过滤器
//添加布隆过滤
RBloomFilter<Long> rbloomFilter = redissonClient.getBloomFilter(RedisConst.SKU_BLOOM_FILTER);
rbloomFilter.add(skuInfo.getId());
2、布隆过滤器判断是否存在(过滤)
用户发来请求时,使用布隆过滤器来判断是否包含
//添加布隆过滤
RBloomFilter<Long> rbloomFilter = redissonClient.getBloomFilter(RedisConst.SKU_BLOOM_FILTER);
//不包含
if(!rbloomFilter.contains(skuId)) return map;
如果包含就去读redis,如果redis没有就去读数据库















 917
917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









