






本周进行了文本转语音(tts)的后端实现。
项目结构如下:
本实现通过调用科大讯飞的语音合成技术,其通过Websocket API的方式给开发者提供一个通用的接口。Websocket API具备流式传输能力,适用于需要流式数据传输的AI服务场景,这和我们项目的目标相一致。相较于SDK,API具有轻量、跨语言的特点;相较于HTTP API,Websocket API协议有原生支持跨域的优势。
接口调用流程如下:
- 通过接口密钥基于hmac-sha256计算签名,向服务器端发送Websocket协议握手请求。
- 握手成功后,客户端通过Websocket连接同时上传和接收数据。数据上传完毕,客户端需要上传一次数据结束标识。
- 接收到服务器端的结果全部返回标识后断开Websocket连接。
然后开始对接口进行调用和实现,初步如下图
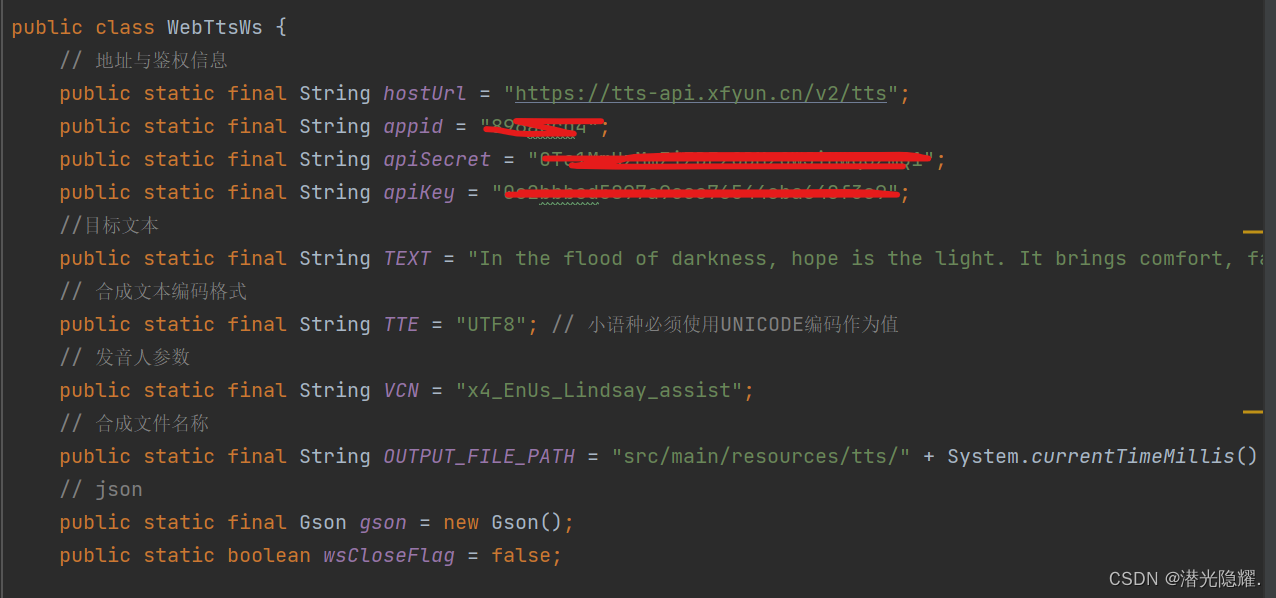
首先定义一些常量,包括tts服务对应的url,与个人请求服务相关的账号密钥,指定文本编码格式,发音人,目标文件名称及最终存储路径,然后输入想要合成的文本,最终得到想要的结果。

程序的主函数,它首先获取授权的WebSocket URL,然后创建一个FileOutputStream来保存合成的音频,并调用websocketWork方法来处理WebSocket连接。
其余部分不一一展示,程序的工作流程如下所示:
- 使用
getAuthUrl方法获取授权的WebSocket URL。 - 通过
websocketWork方法建立WebSocket连接。 - 在连接建立后,启动
MyThread线程发送请求参数和要合成的文本。 - 服务器处理请求并返回音频数据,程序将这些数据写入到文件中。
- 一旦音频合成完成,关闭WebSocket连接并释放资源。
代码中还使用了Base64编码来处理文本数据,并且使用了Gson库来解析JSON响应。此外,还使用了Java的javax.crypto包来进行HMAC-SHA256签名,使程序可靠性较好。
运行程序后,在对应目录下出现了合成完成的mp3文件,也可以顺利进行播放,调用完成。
















 599
599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









