







ASCII、UTF-8等常见编码知识扫盲
前言
对于每个接触过计算机相关知识的人来说,字符编码应该多少有些了解。我现在是本科三年级,也是学习计算机的第三个年头,大概了解一些字符编码的规则。然而若要当场讲出个所以然来,我恐怕难以完成。在补自然语言处理的实验作业——文本聚类的过程中,我突然对字符编码好奇了起来。于是直接翘了作业,去查阅相关资料,好在不用花太多功夫,收获颇丰,于是在此总结。
简介
我们知道,在计算机内部,所以信息都是以二进制编码的形式存在,1个二进制位称为1个比特(bit),可以表示2种状态,而8个比特又称为1个字节(Byte)。整体来看,无论是RAM还是ROM,都是一大堆的0、1信号。在此基础上的各种编码和解码,不过是对这些二进制串进行不同的分割以及对分割后的字串采用相应的规则进行识别。例如:在C语言中int类型数据将4个字节也就是32个比特作为一个整体识别,最高位作为符号位,剩下31个比特表示整数大小;而在float类型中,虽然也是将32个比特作为整体处理,但是其采用IEEE 754标准进行编码和解码,最高位为符号位,中间8位为指数位,后23位为尾数位;而char类型将1个字节(8个比特)进行处理,数值大小即为代码点,对照ASCII码标准查找相应字符即可。
自计算机诞生以来,如何有效地将信息输入传递给计算机,以及如何转化计算机处理后的输出结果成人类能理解的形式,一直是值得研究和改进的问题。一开始,计算机采用最原始的打孔纸带输入输出,于是我们不得不使用最让人头疼的机器语言,然后是汇编语言与LISP等早期高级语言,之后是ALGOL等高级语言,再然后是C、Pascal等结构化编程语言,到后来的面向对象编程、和现在的静态类型和新兴语言,从代码到文本,从文本到语音,我们和计算机交互变得越来越便捷、轻松。这种趋势也是字符编码所遵循的。
这篇文章将介绍常见的字符编码及标准,着重了解他们出现的动机和解决的需求,并介绍一些背景故事。计算机的知识若是只有理论,那永远只是停留在概念的理解,本文也将挑出其中具有一些有趣的点进行简单实验。
另外关于中文编码的介绍、为什么计算机硬件通常以8个比特当作1字节、如何使用Unicode私人使用区平面的实验等内容,我将放在下篇文章中进行介绍。
推荐对字符编码感兴趣的同学可以前往unicode.org官网、symbl.cc网站查阅相关信息,然后可以使用ultraedit工具查看想要编码的文档。好啦,话不多说,进入正文。
正文
一、ASCII码——美国信息交换标准代码
在20世纪50年代和60年代早期,不同的计算机制造商使用不同的字符编码方案,这直接导致了兼容性问题,使用者之间的信息传输极为不便,需要一个统一的标准来促进不同计算机系统之间的数据交换。1963年,美国国家标准协会(ANSI)的X3.2小组提出了一种使用7位二进制数表示字符,共计128个字符((包括32个不能打印出来的控制符号))。比如空格"SPACE"是32(二进制00100000),大写的字母A是65(二进制01000001)。在实际应用中考虑到了未来可能的扩展等原因,最终ASCII码在存储和处理时使用8个比特(计算机硬件通常以8个比特当作1字节为单位进行数据的存储和操作)。现在ASCII码最前面的1位统一规定为0。
ASCII的出现提供一种标准化的字符编码方案,涵盖基本的英文字母、数字和控制字符,便于数据交换和文本处理,这给字符编码领域开创了一个成功的先例。
二、非ASCII字符编码
ASCII在美国成功之后,其他国家也开始研究、制定本国语言的编码规则,如法国、中国等。可是有两个问题需要解决:
一是英语用128个符号编码就足够了,但是对于很多其他语言,这是远远不够的。比如,在法语中,字母上方有注音符号,它就不止128个。至于亚洲国家的文字,符号就更多了。拿汉字来说,大约将近十万个(北京国安咨询设备公司汉字字库收入有出处汉字91251个)。为了解决这个问题,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。而亚洲国家的文字符号普遍较多,一个字节256远远不够,必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是在1980年由中国国家标准总局提出并发布的GB2312(中华人民共和国国家标准汉字信息交换码,没错,就是你写word要用的那个字体格式),使用两个字节表示一个汉字,所以理论上最多可以表示256x256=65536个符号。并且在1980年代,由日本和中国等国家的计算机制造商和标准化组织提出和开发了DBCS(Double Byte Character Set),用来提供一种混合使用单字节和双字节编码的方案,以表示东亚语言中的大量字符。
二是虽然每个国家内的兼容性问题可以通过本国内的标准解决,但是不同国家之间依旧不兼容。哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0--127表示的符号是一样的,128--255的这一段却不一样。说明他们均对ASCII码兼容,但是互相不兼容。这个问题的解决就要引出今天的重点介绍的一种编码标准:Unicode。
三、Unicode
世界上存在着多种编码方式,这就意味着同一个二进制数字可以被解码成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?为什么一个文件用其他软件打开容易出现乱码?就是因为发信人和收信人使用的编码方式不一样,文件和不对应的软件编码方式通常也不一样。随着互联网的普及,不同国家之间的数据交换越来越常见,很多需要服务多个国家的个人和公司不得不保存对应国家所采用的编码工具并记住他的编码方式以便保证不出现乱码。可以想象,如果有一种编码标准,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,就像它的名字所表示的,每个符号都有其独一无二的代码点。
1991年,由包括微软、苹果、IBM 等组成的 Unicode 联盟提出和开发的一种能够表示全球所有语言的所有字符,简化多语言文本处理的统一的编码方案Unicode(Universal Character Set)面世。Unicode是一个很大的集合,到目前为止,Unicode 包含超过 150 种书写系统,并支持数百种语言。现在的规模实际上可以容纳1,112,064个字符,并且可以随着 Unicode 标准的不断更新和扩展而增加。截至目前最新的 Unicode 标准版本(Unicode 15.1.0,发布于 2023 年 9 月 12 日,每年大概这个时候更新标准)总共包含149,813个字符。每个字符的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字"严"。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
在Unicode中,将所有字符划分成17个平面:
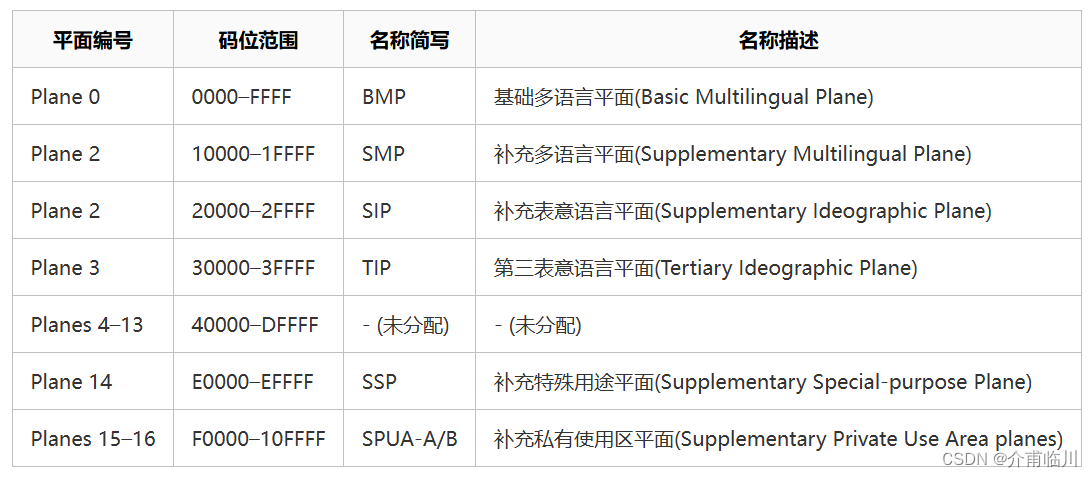
1.基本多语言平面 (BMP):
- 范围:U+0000 至 U+FFFF
- 包含字符:65,536 个
- 特点:涵盖了大多数常用字符,包括基本拉丁字母、汉字、阿拉伯字母、希腊字母、表情符号等。
2.辅助平面 (Supplementary Planes):
- 辅助多语言平面 (SMP, Supplementary Multilingual Plane):U+10000 至 U+1FFFF
- 包含历史文字和现代但较少用的字符。
- 辅助表意文字平面 (SIP, Supplementary Ideographic Plane):U+20000 至 U+2FFFF
- 包含扩展的汉字字符。
- 第三表意文字平面 (TIP, Tertiary Ideographic Plane):U+30000 至 U+3FFFF
- 主要为汉字的进一步扩展保留。
- 补充特殊用途平面 (SSP, Supplementary Special-purpose Plane):U+E0000 至 U+EFFFF
- 包含标签字符和一些特殊用途字符。
- 私人使用区平面 (PUA, Private Use Area):U+F0000 至 U+10FFFF
- 为用户定义字符保留,不被 Unicode 标准定义。
Unicode中,私人使用区(PUA)是一系列代码点,根据定义,Unicode 联盟不会为其分配字符,定义了二个私人使用区域:一个位于基本多语言平面( U+E000-U+F8FF)共有 6,400 个码位可供用户自定义字符和特殊用途字符,一个位于并几乎覆盖平面 15 和 16(U+F0000-U+FFFFD ,U+ 100000-U+10FFFD )即SPUA。这些区域中的代码点不能被视为 Unicode 本身的标准化字符,所以这些区域可以供个人进行DIY(但比较麻烦)。
需要注意的是,Unicode只是一个字符编码标准,它只规定了不同符号的二进制代码,却没有规定这个二进制代码应该如何存储。比如,汉字"严"的unicode是十六进制数4E25,转换成二进制数足足有15(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别Unicode和ASCII?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:1)出现了Unicode的多种存储方式,可以用来表示Unicode,最基本的就是可以分为定长编码和边长编码两种方式。2)Unicode在很长一段时间内无法推广,直到互联网的普及。
四、Unicode实现方式
1.UCS-2
1990年,由国际标准化组织(ISO)提出和开发出了一种使用固定的 16 位比特(2个字节)表示字符的字符编码UCS-2(Universal Character Set - 2)。作为 Unicode 的早期实现,UCS-2 提供了一种固定长度的字符编码方案,它简化了字符处理,能够涵盖基本多语言平面(BMP)的字符。但是,对于超出基本多语言平面(BMP)的字符无能为力。
2.UTF-8
随着互联网的不断发展,对于高效、向后兼容的 Unicode 编码方案的需求越来越强烈,而已有的UCS-2很明显不能胜任。于是1993年,贝尔实验室的 Ken Thompson 和 Rob Pike 提出了一种使用 1 到 4 个字节表示字符,与 ASCII 向后兼容,同时能够高效表示所有 Unicode 字符的边长编码方案——UTF-8(8-bit Unicode Transformation Format)。
UTF-8的编码规则很简单,只有2条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
例如下表:
- 1 字节:0xxxxxxx(适用于 U+0000 到 U+007F)
- 2 字节:110xxxxx 10xxxxxx(适用于 U+0080 到 U+07FF)
- 3 字节:1110xxxx 10xxxxxx 10xxxxxx(适用于 U+0800 到 U+FFFF)
- 4 字节:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx(适用于 U+10000 到 U+10FFFF)
因此在UTF-8编码中每个字符的高位和低位字节的顺序在编码过程中是不变的,所以不用讨论字符串采用的是大端序(BE)还是小端序(LE),其他编码基本需要考虑大小端。这比较特殊,于是在此强调。
下面,还是以汉字"严"为例,演示如何实现UTF-8编码。已知"严"的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此"严"的UTF-8编码需要三个字节,即格式是"1110xxxx 10xxxxxx 10xxxxxx"。然后,从"严"的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,"严"的UTF-8编码是"11100100 10111000 10100101",转换成十六进制就是E4B8A5。
UTF-8 与 ASCII 兼容,0x00 到 0x7F 的 ASCII 字符在 UTF-8 中使用相同的单字节编码。这意味着纯 ASCII 文本在 UTF-8 中不会有任何变化。另外UTF-8还是一种无字节顺序问题(byte order independent)的编码方式。所以它广泛用于文件存储和互联网传输,因为它能有效地编码常见字符(例如英文字符)并且对不同平台和系统具有良好的兼容性。
3.UTF-16
UTF-16(Unicode Transformation Format - 16-bit)是于1996年由由 Unicode 联盟提出和开发的一种变长字符编码,使用 2 或 4 个字节来表示 Unicode 代码点,其中2 个字节表示基本多语言平面(BMP)内的字符,使用 4 个字节表示 BMP 之外的字符(通过代理对),这样就能表示更多的字符了。UTF-16 实际上是在 UCS-2 的基础上进行了扩展,以支持代理对,允许表示所有 Unicode 字符。
(1)编码规则:
- Unicode 代码点在 U+0000 到 U+FFFF 范围内的字符使用单个 16 位单元表示(2 个字节)。
- 超过 U+FFFF 的字符(即从 U+10000 到 U+10FFFF)使用一对 16 位单元表示,称为代理对(surrogate pairs)。
- 高代理(high surrogate):范围为 D800-DFFF
- 低代理(low surrogate):范围为 DC00-DFFF
(2)兼容性:
- UTF-16 对于 BMP(基本多语言平面)字符非常高效,但对于需要代理对的字符则需要 4 个字节,效率低下。
4.UTF-32
2000年,为了简化字符处理,避免变长编码的复杂性,Unicode 联盟提出和开发了一种固定长度的 Unicode 编码方案UTF-32(32-bit Unicode Transformation Format)。它使用 4 个字节表示每个字符,所有字符都占用相同的空间,这样简化了字符处理,避免变长编码的复杂性。
(1)编码规则:
- 每个 Unicode 代码点直接映射到一个 32 位整数,因而每个字符都用 4 个字节表示。
(2)兼容性:
- UTF-32 的优点是简单且直接,解码非常容易。但由于每个字符都占用 4 个字节,因此对存储和传输的效率较低,特别是对于通常只需一个或两个字节的字符集(如 ASCII 字符集)。
5.评价
这些编码体现了编码算法的通性。一般来说,变长编码平均码长更短,传输和存储效率高,但是编码和解码的过程复杂;而定长编码虽然简单,容易造成存储空间和传输的浪费。因此需要结合实际应用情况进行选择。现如今在互联网中,UTF-16和UTF-32基本不用,而采用UTF-8进行编码解码。
五、区分文件编码
介绍了这么多的编码,自然有个一个问题,假如我们收到一份文件,计算机是如何知道这份文件采用的是什么编码呢?这里将介绍一些常用方法。这些方法可以单独使用,也可以结合使用,以确保正确地识别文件编码。
1. 字节顺序标记 (BOM)
一些编码标准在文件开头包含一个特殊的字节序列,称为字节顺序标记 (Byte Order Mark, BOM)。不同的编码有不同的 BOM:
- UTF-8:EF BB BF
- UTF-16 (Big Endian):FE FF
- UTF-16 (Little Endian):FF FE
- UTF-32 (Big Endian):00 00 FE FF
- UTF-32 (Little Endian):FF FE 00 00
通过检测文件开头的这些字节,计算机可以确定文件的编码。
2. 文件扩展名和协议规范
某些文件类型使用特定的扩展名或协议约定,隐含了编码方式。例如:
- .txt 文件通常默认使用 ANSI 编码或 UTF-8 编码。
- .html 文件通常使用 UTF-8 编码,但可以在文件内的元数据中指定其他编码。
3. 语言特定模式和字节模式分析
根据文本内容的语言特性和特定的字节模式分析编码。
- 中文文本:GB2312、GBK、GB18030 的中文文本中,字符频率和分布具有一定模式。
- 日文文本:Shift JIS、EUC-JP 编码的日文文本有特定的字节模式。
- ASCII:仅使用 0x00 到 0x7F 范围内的字节。
- UTF-8:多字节序列有特定模式,首字节以 110xxxxx、1110xxxx、11110xxx 开头,后续字节以 10xxxxxx 开头。
4. 用户输入或系统默认设置
在缺乏其他信息的情况下,系统或应用程序可能会使用默认编码设置,或提示用户选择编码。例如:
- 操作系统或文本编辑器通常有默认的编码设置。
- 用户在打开文件时可以手动选择编码。
5. 字符集检测工具和库
使用字符集检测工具和库是最常见和有效的方法。这些工具通过分析文本的字节模式和统计特征来猜测编码。
以下是展示如何使用 chardet 库检测文件编码Python 代码:
import chardet
# 读取文件的前1024字节以进行编码检测
with open('example.txt', 'rb') as f:
raw_data = f.read(1024)
# 使用 chardet 检测编码
result = chardet.detect(raw_data)
encoding = result['encoding']
print(f"The detected encoding is {encoding}")六、大端(Big endian)和小端(Little endian)
文章前面不断提到大端和小端的概念,这里进行详细说明。
Unicode码可以采用UTF-16格式直接存储。以汉字"严"为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式。这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
因此,第一个字节在前,就是"大头方式"(Big endian),第二个字节在前就是"小头方式"(Little endian)。
Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(ZERO WIDTH NO-BREAK SPACE),用FEFF表示。这正好是两个字节,而且FF比FE大1。如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。
Ok,了解了大小端的知识,我们现在可以对编码的大小端进行区分。但是文件的大小端是由什么决定的呢,操作系统、软件还是硬件架构?
答案是当前所使用的软件。操作系统和硬件架构本身并不直接决定字符串编码的字节序。它们提供底层支持,例如字节序在内存中的存储方式(大端或小端架构),但字符串编码的实际字节序是由上层软件控制的。某些操作系统可能有默认的编码配置或推荐使用的编码,但具体到每个文件或数据流的字节序还是由应用程序决定。
在跨平台软件中,开发者通常会确保在不同的操作系统上,得到的文本数据具有相同的字节序。这是通过在软件中明确定义字节序处理规则来实现的,以确保软件在不同平台上的一致性。
七、编码之间的转换(实验)
"严"的Unicode码是4E25,UTF-8编码是E4B8A5,两者是不一样的。它们之间的转换可以通过程序实现。
在Windows平台下,有一个最简单的转化方法,就是使用内置的记事本应用程序Notepad.exe。打开文件后,点击"文件"菜单中的"另存为"命令,会跳出一个对话框,在最底部有一个"编码"的下拉条。

里面有六个选项:ANSI、UTF-16 LE、UTF-16 BE 、UTF-8、UTF-8 BOM和GB18030。
1)ANSI是默认的编码方式。对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对Windows简体中文版,如果是繁体中文版会采用Big5码)。
2)UTF-16 LE是使用小端序(Little Endian, LE)表示的 UTF-16编码,通过字节顺序标记 (BOM) 来指示文件的编码格式。
3)UTF-16 BE编码与上一个选项相对应,使用大端序(Big Endian, BE)表示的 UTF-16编码。
4)UTF-8编码,也就是上文谈到的编码方法。
5)UTF-8 BOM即在UTF-8编码上使用BOM来标识文件编码格式,三个字节 EF BB BF 组成,可以帮助提高文件在不同平台和应用程序间的兼容性。
6)GB18030 是中国国家标准 GB 18030-2005,采用单字节、双字节和四字节编码,灵活表示不同范围的字符,支持所有汉字及其他少数民族语言字符。
选择完"编码方式"后,点击"保存"按钮,文件的编码方式就立刻转换好了。
八、 查看编码(实验)
打开"记事本"程序Notepad.exe,新建一个文本文件,内容就是一个"严"字,依次采用ANSI、UTF-16 LE、UTF-16 BE 、UTF-8、UTF-8 BOM和GB18030编码方式保存。
然后,用文本编辑软件UltraEdit中的"十六进制功能"("control"+"H"),观察该文件的内部编码方式。
1)ANSI:文件的编码就是两个字节"D1 CF",这正是"严"的GB2312编码,这也暗示GB2312是采用大头方式存储的。

2)UTF-16 LE:编码是四个字节"FF FE 25 4E",其中"FF FE"表明是小头方式存储,真正的编码是4E25。

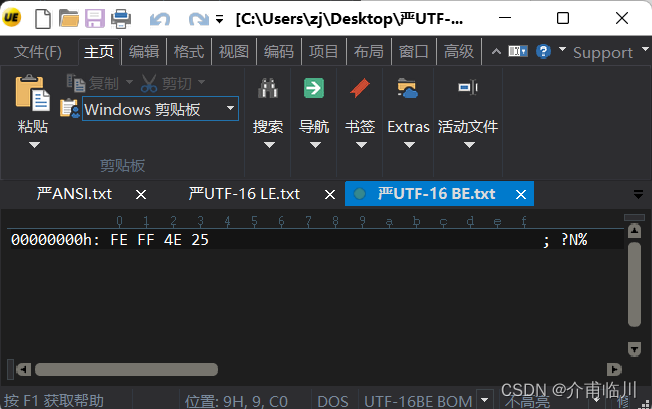
3)UTF-16 BE:编码是四个字节"FE FF 4E 25",其中"FE FF"表明是大头方式存储。
4)UTF-8:编码的三个字节"E4 B8 A5"是"严"的Unicode编码,这里没有使用BOM标记。

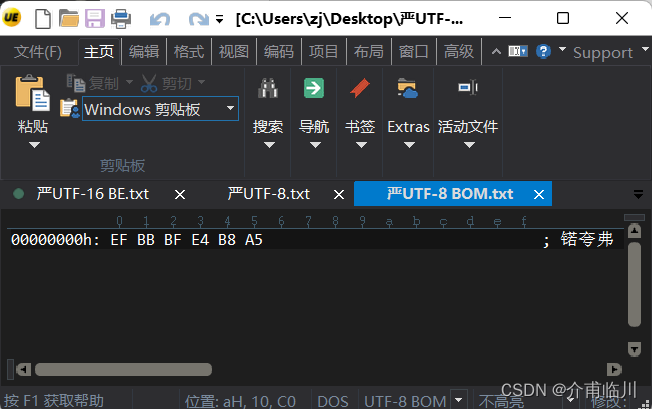
5)UTF-8:编码是六个字节"EF BB BF E4 B8 A5",前三个字节"EF BB BF"是UTF-8的BOM标记,后三个"E4B8A5"就是"严"的具体编码,它的存储顺序与编码顺序是一致的。
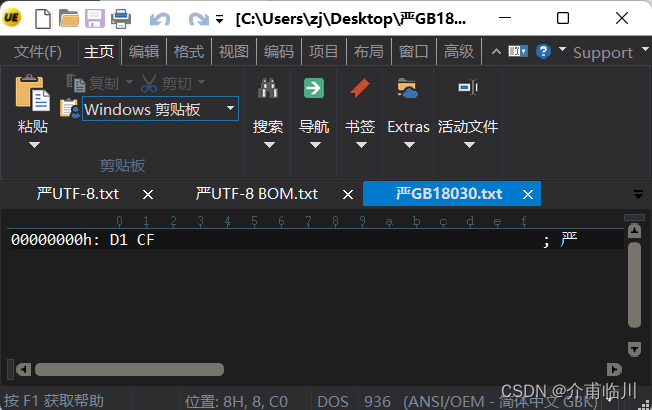
6)GB18030:和ANSI的编码一样,都是GB2312中的"D1 CF",因为GB18030 是 GB2312 的扩展,包含更多字符和向后兼容。
九、总结感悟
各编码方式的出现是为了满足不同历史阶段和技术背景下的需求,从早期的单字节编码(ASCII)到支持东亚字符的双字节编码(DBCS、GB2312),再到全球统一的字符编码(Unicode)及其变体(UTF-8、UTF-16、UTF-32)。随着全球化的发展,Unicode 编码及其变体逐渐成为主流,以解决不同语言和字符集之间的兼容性问题。
纵观字符编码整个发展过程,可以发现这还是一个满接地气的领域。人们为了在计算机上实现信息传递的便捷,先提出解决方案,然后有新问题又提出新的解决方案,不断融合、统一,直到Unicode的出现,颇有统一度量衡的感觉。
当细心去了解这些编码后面巧妙的规则和严密的逻辑,有时会不住赞叹;有时又觉得和自己想法很契合,觉得就应该这样;有时看到一些编码的简单、粗暴和局限性的时候,又会发现这些都是如此现实,并不虚无缥缈。
其实,我个人觉得这种给文字编码的工程虽然恢弘、意义非凡,但干起来一定很枯燥,不是我爱干的。Anyway,前人栽树,后人乘凉。感谢为字符编码领域付出的大佬,也感谢互联网上乐于分享的博主们,让我受益匪浅。
参考















 255
255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









