







C/C++——排列算法
题目描述:
(排列数)输入两个正整数 𝑛,𝑚(1≤𝑛≤20,1≤𝑚≤𝑛)n,m(1≤n≤20,1≤m≤n),在 1∼𝑛1∼n 中任取 𝑚m 个数,按字典序从小到大输出所有这样的排列。例如:
输入:3 2
输出:1 2 1 3 2 1 2 3 3 1 3 2
题目分析:
偶然间看到这道NOIP 2012提高组初赛的试题,觉得还挺有趣的。之前一直都是做全排列的题,这次看到排列的题还一下子没转过来。其实这道题目可以理解为有n个编号为1~n的小球需要放在m个编号为1~m的盒子里,每个盒子只能放一个小球,让你把所有可能的结果按照字典序从小到大输出。其中n>=m。就是求。
因为,所以这道题的时间复杂度就是O(n!),所以n和m的值不会太大。因为要输出所有的情况,所以可以直接暴力。
算法1:
一开始我选择的是直接从字典序最小的时候开始遍历,时间复杂度变为O(nm),这比O(n!)还要大。
# include "stdio.h"
# include "time.h"
# define maxsize 25
int n, m;
long long count = 0;
int visited[maxsize]={0}, arr[maxsize]={0};
void permutation(int index)
{
for(int i=1;i<=n;i++)
{
if(visited[i] == 0)
{
if(index<m)
{
visited[i] = 1;
arr[index] = i;
permutation(index+1);
visited[i] = 0;
}
else if(index == m)
{
arr[index] = i;
// for(int j = 1;j<=m;j++)
// printf("%d ", arr[j]);
count++;
// printf("\n");
}
}
}
}
int main()
{
scanf("%d%d", &n, &m);
int index = 1;
clock_t start, end;
double cpu_time_used;
start = clock(); // 开始计时
permutation(index);
end = clock(); // 结束计时
cpu_time_used = ((double) (end - start)) / CLOCKS_PER_SEC; // 计算时间
printf("程序执行时间为: %f seconds\n", cpu_time_used);
printf("%lld", count);
return 0;
}算法2:
上面的算法时间复杂度会变成O(nm)是因为在我已经选择了一个小球也就是选择了一个编号之后,我并没有将其剔出待选集,也就少了一个筛选操作,这其实并没有对整个过程的正确模拟。
所以我想,可不可以增加一个筛选的操作但又不增加时间复杂度呢。这让我想起了单调队列优化,可以将所有小球当作一个有序链表,如果已经放了一个小球,直接用链表的删除操作删除对应节点,而删除操作是不增加时间复杂度的。想法可行,直接开始优化。
# include "stdio.h"
# include "stdlib.h"
# include "time.h"
# define maxsize 25
int n, m;
long long count = 0;
int visited[maxsize]={0}, arr[maxsize]={0};
typedef struct List{
int num;
struct List *next;
}List, *L;
L head=NULL;
void create(L &head)
{
L p, q;
head = (L)malloc(sizeof(List));
head->next = NULL;
q = head;
for(int i =1;i<=n;i++)
{
p = (L)malloc(sizeof(List));
p->next = NULL;
p->num = i;
q->next = p;
q = p;
}
}
void push(L &p, L &q)
{
q->next = p->next;
p->next = q;
}
void pop(L &p, L &q)
{
p->next = q->next;
q->next = NULL;
}
void permutation(int index)
{
L p = head, q = head->next;
int i = 0;
while(q)
{
i = q->num;
if(index < m)
{
pop(p, q);
arr[index] = i;
permutation(index+1);
push(p ,q);
}
else if(index == m)
{
arr[index] = i;
// for(int j = 1;j<=m;j++)
// printf("%d ", arr[j]);
count++;
// printf("\n");
}
p = q;
q = q->next;
}
}
int main()
{
scanf("%d%d", &n, &m);
int index = 1;
clock_t start, end;
double cpu_time_used;
create(head);
start = clock(); // 开始计时
permutation(index);
end = clock(); // 结束计时
cpu_time_used = ((double) (end - start)) / CLOCKS_PER_SEC; // 计算时间
printf("程序执行时间为: %f seconds\n", cpu_time_used);
printf("%lld", count);
return 0;
}结果分析:
算法优化完成后并在运行函数前后加入时间获取,观察一下优化效果。
当输入20 6时,程序运行27907200次,未优化前耗时0.104秒,优化后只用了0.072秒,大约提升了大约0.032/0.104≈30.8%的效率。
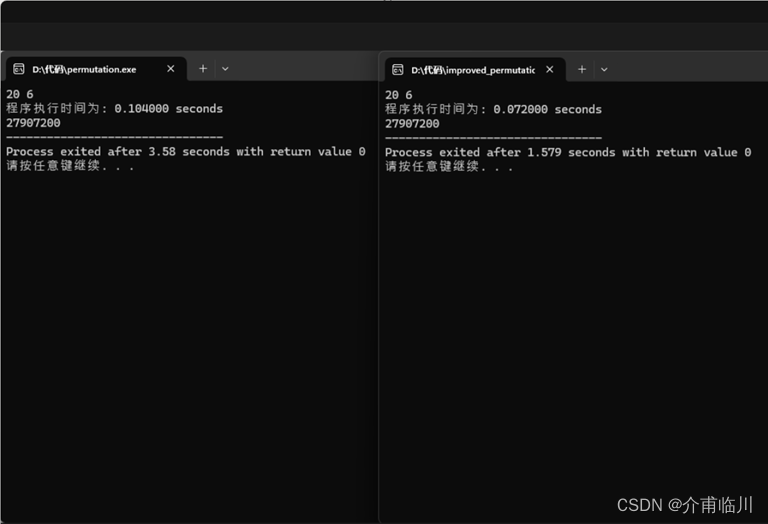
当输入20 7时,程序运行390700800次,未优化前耗时1.654秒,优化后只用了1.062秒,大约提升了大约0.592/1.654≈35.8%的效率。
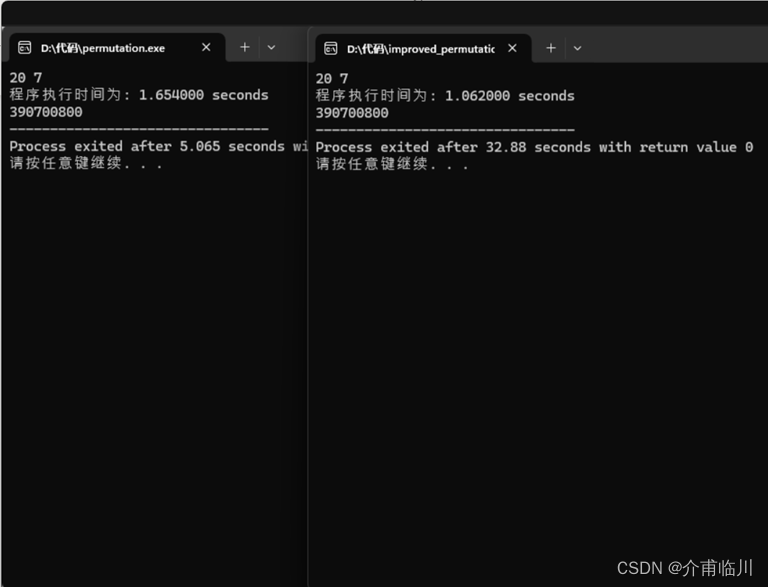
可以发现,当运行次数越多,提升的效率越多,符合O(nm)与O(n!)之间差距递增的趋势,说明优化有效。















 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









