







目录
摘要:
与通常具有独特格式的视觉和语言数据不同,分子可以自然地使用不同的化学配方来表征。人们可以将分子看作二维图形,也可以将其定义为位于三维空间中的原子集合。对于分子表示学习,大多数先前的工作只针对特定的数据格式设计了神经网络,这使得学习到的模型可能无法适用于其他数据格式。我们相信一个通用的化学神经网络模型应该能够处理跨数据模式的分子任务。为了实现这一目标,在这项工作中,我们开发了一种新的基于transformer的分子模型,称为Transformer-M,它可以将2D或3D格式的分子数据作为输入,并生成有意义的语义表示。Transformer- m使用标准的Transformer作为主干架构,开发了两个独立的通道来编码二维和三维结构信息,并将其与网络模块中的原子特征结合起来。当输入的数据是特定格式时,相应的通道将被激活,另一个通道将被禁用。通过使用适当设计的监督信号对2D和3D分子数据进行训练,Transformer-M自动学习利用来自不同数据模式的知识并正确捕获表征。我们对变压器m进行了大量的实验。所有的实证结果表明,Transformer-M可以同时在二维和三维任务上取得较强的性能,表明其广泛的适用性。代码和模型将在https://github.com/lsj2408/Transformer-M上公开提供。
1 介绍:
深度学习方法已经彻底改变了许多领域,包括计算机视觉(He等人,2016)、自然语言处理(Devlin等人,2019;Brown et al, 2020)和游戏(Mnih et al, 2013;Silver et al, 2016)。最近,研究人员开始研究神经网络的力量是否可以帮助解决化学中的重要科学问题,例如,预测分子的性质并从大规模训练数据中模拟分子动力学(Hu et al ., 2020a;2021;Zhang et al ., 2018;Chanussot et al, 2020)。
化学与视觉和语言等传统领域的一个关键区别是数据的多模态。在视觉和语言中,数据实例通常具有特定形式的特征。例如,将图像定义为像素网格中的RGB值,而将句子定义为序列中的标记。相反,分子自然具有不同的化学配方。一个分子可以表示为一个序列(Weininger, 1988),一个二维图形(Wiswesser, 1985),或者一个位于三维空间的原子集合。2D和3D结构是最常用的公式,因为可以从中获得许多有价值的属性和统计数据(Chmiela等人,2017;Stokes et al, 2020)。然而,据我们所知,以往的工作大多集中在设计二维或三维结构的神经网络模型,使得以一种形式学习的模型无法应用于另一种形式的任务。
我们认为,化学中的通用神经网络模型至少应该能够处理跨数据模式的分子任务。在本文中,我们通过开发Transformer-M迈出了实现这一目标的第一步,Transformer-M是一种基于transformer的多功能分子模型,在2D和3D分子表示学习中都表现良好。请注意,对于一个分子,它的2D和3D形式描述了相同的原子集合,但使用了不同的结构表征。因此,关键的挑战是设计一个表达和兼容的模型,以捕获不同公式的结构知识,并训练参数从这两种信息中学习。transformer比其他架构更有利,因为它可以显式地将结构信号插入模型中作为偏置项(例如,位置编码(V aswani等人,2017;拉斐尔等人,2020))。我们可以方便地将二维和三维结构信息通过分离的通道设置为不同的偏置项,并将其与注意层中的原子特征结合起来。
体系结构。我们的Transformer- m的骨干网络由标准Transformer模块组成。我们开发了两个独立的通道来编码二维和三维结构信息。
2D通道采用度编码、最短路径距离编码和从2D图结构中提取的边缘编码,遵循Ying等(2021a)。最短路径距离编码和边缘编码反映了一对原子的空间关系和键合特征,并作为softmax最大注意中的偏置项。度编码被添加到输入层的原子特征中。
对于3D通道,我们遵循Shi等人(2022)使用3D距离编码对3D几何结构中原子之间的空间距离进行编码。每个原子对的欧几里得距离通过高斯基核函数(Scholkopf et al, 1997)进行编码,并将用作softmax注意中的偏差项。对于每个原子,我们将其与所有其他原子之间的三维距离编码相加,并将其添加到输入层的原子特征中。图1给出了一个说明。
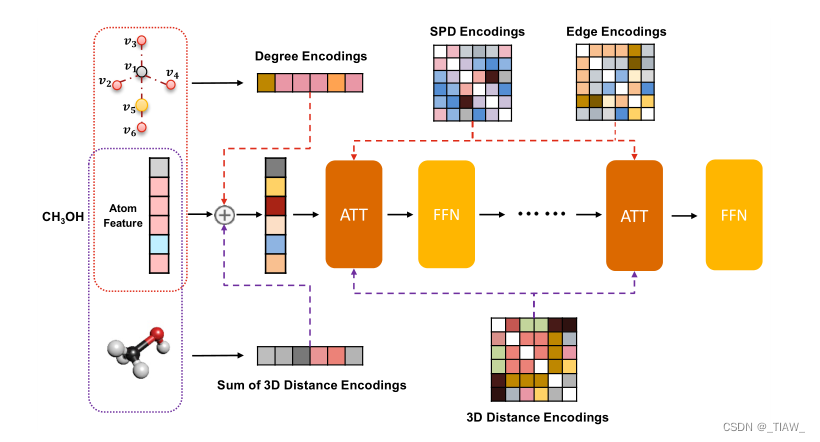
图1:我们的Transformer-M模型体系结构的插图。我们在主干变压器上建立了两个通道。红色通道用于包含度、最短路径距离和边缘信息的2D图形结构的数据。紫色通道为3D几何结构数据激活,以利用欧几里得距离信息。不同的编码位于相应的模块中。
训练。除了两个结构通道中的参数外,Transformer-M中的所有其他参数(例如自关注和前馈网络)对于不同的数据模式都是共享的。我们为Transformer-M设计了一种联合训练方法来学习其参数。在训练过程中,当批处理中的实例仅与2D图结构相关联时,2D通道将被激活,3D通道将被禁用。类似地,当批处理中的实例使用3D几何结构时,3D通道将被激活,2D通道将被禁用。当同时给出二维和三维信息时,两个通道都会被激活。这样,我们可以从单独的数据库中收集2D和3D数据,并根据不同的训练目标训练Transformer-M,使训练过程更加灵活。我们期望单个模型能够学习识别和合并来自不同模态的信息,并有效地利用这些参数,从而获得更好的泛化性能。
实验结果。我们在OGB大规模挑战(OGBLSC)中使用PCQM4Mv2数据集(Hu等人,2021)来训练我们的Transformer-M,它由340万个2D和3D形式的分子组成。通过针对3D数据的预文本3D去噪任务,训练模型预测不同格式的每个数据实例的预先计算的HOMO-LUMO间隙。通过预训练模型,我们可以直接使用或微调不同数据格式的各种分子任务的参数。首先,我们证明了在PCQM4Mv2任务的验证集上,仅包含二维分子图,我们的Transformer-M大大超过了以前的所有作品。这种改进归功于联合训练,它有效地缓解了过拟合问题。其次,在pdbbind上(Wang et al ., 2004;2005b) (2D&3D),与强大的基线相比,经过微调的Transformer-M实现了最先进的性能。最后,在QM9 (Ramakrishnan et al, 2014) (3D)基准上,与最近的方法相比,微调后的Transformer-M模型实现了具有竞争力的性能。所有结果表明,我们的Transformer-M具有在化学领域广泛应用的通用模型的潜力。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









