




业务流程
首先我们看看项目中的下单业务整体流程:
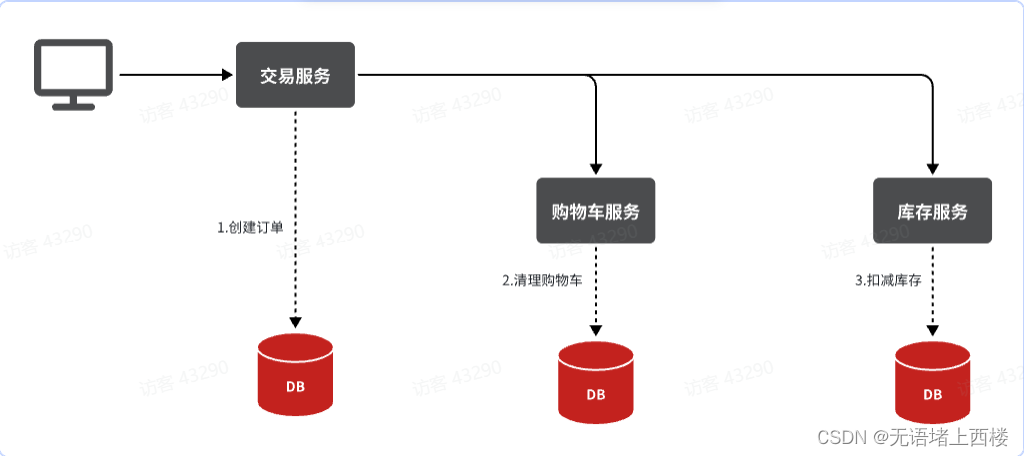
由于订单、购物车、商品分别在三个不同的微服务,而每个微服务都有自己独立的数据库,因此下单过程中就会跨多个数据库完成业务。而每个微服务都会执行自己的本地事务:
-
交易服务:下单事务
-
购物车服务:清理购物车事务
-
库存服务:扣减库存事务
整个业务中,各个本地事务是有关联的。因此每个微服务的本地事务,也可以称为分支事务。多个有关联的分支事务一起就组成了全局事务。我们必须保证整个全局事务同时成功或失败。
我们知道每一个分支事务就是传统的单体事务,都可以满足ACID特性,但全局事务跨越多个服务、多个数据库,是否还能满足呢?
我们来做一个测试,先进入购物车页面:
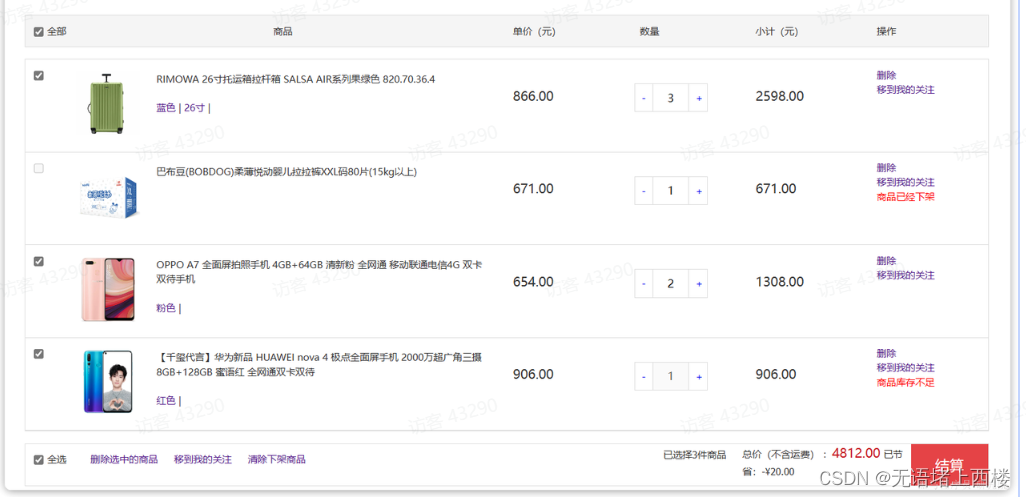
目前有4个购物车,然结算下单,进入订单结算页面:
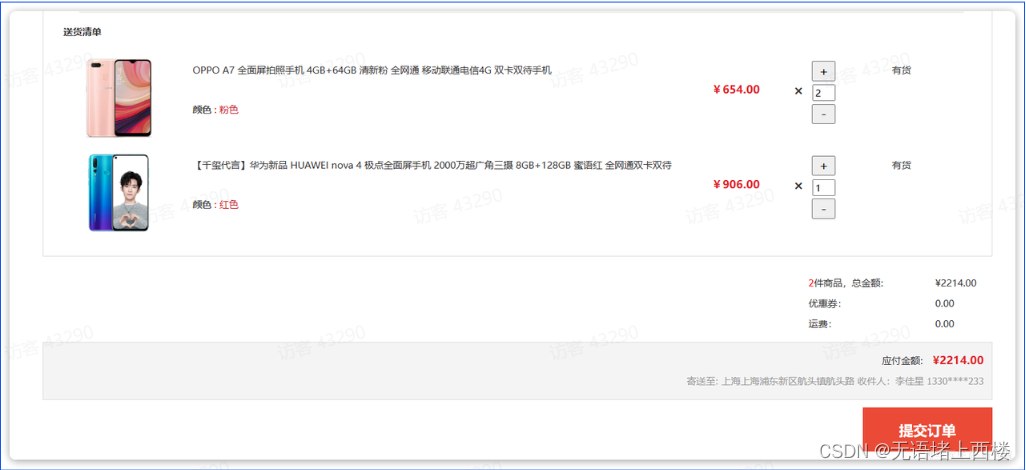
然后将购物车中某个商品的库存修改为0:
然后,提交订单,最终因库存不足导致下单失败:
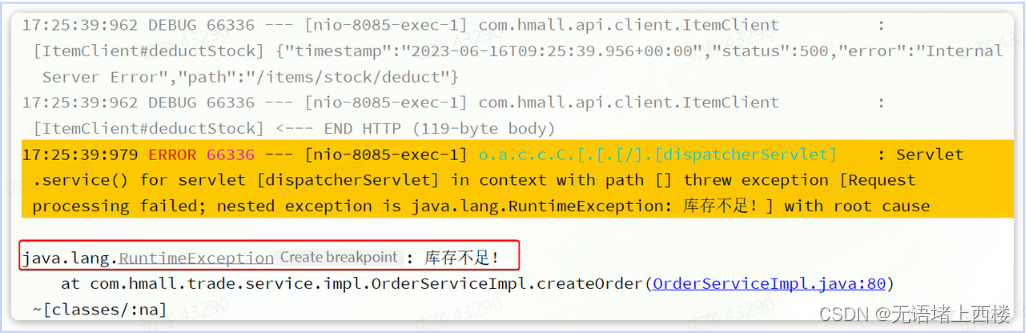
然后我们去查看购物车列表,发现购物车数据依然被清空了,并未回滚:
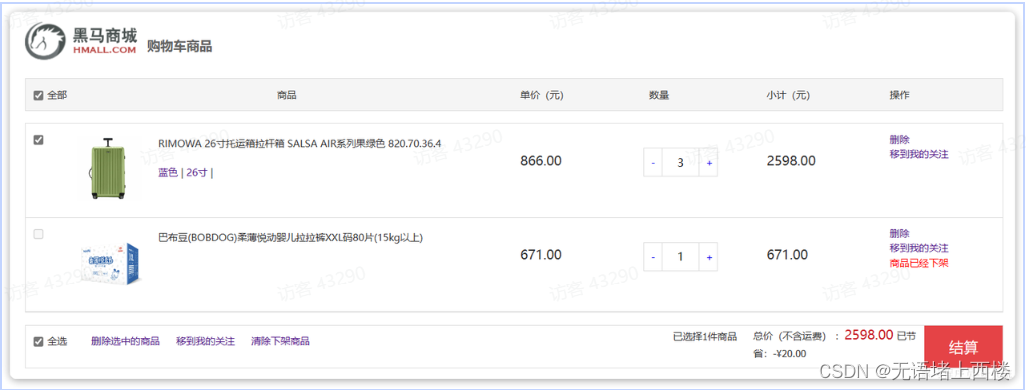
事务并未遵循ACID的原则,归其原因就是参与事务的多个子业务在不同的微服务,跨越了不同的数据库。虽然每个单独的业务都能在本地遵循ACID,但是它们互相之间没有感知,不知道有人失败了,无法保证最终结果的统一,也就无法遵循ACID的事务特性了。
这就是分布式事务问题,出现以下情况之一就可能产生分布式事务问题:
-
业务跨多个服务实现
-
业务跨多个数据源实现
认识Seata
解决分布式事务的方案有很多,但实现起来都比较复杂,因此我们一般会使用开源的框架来解决分布式事务问题。在众多的开源分布式事务框架中,功能最完善、使用最多的就是阿里巴巴在2019年开源的Seata了。
其实分布式事务产生的一个重要原因,就是参与事务的多个分支事务互相无感知,不知道彼此的执行状态。因此解决分布式事务的思想非常简单:
就是找一个统一的事务协调者,与多个分支事务通信,检测每个分支事务的执行状态,保证全局事务下的每一个分支事务同时成功或失败即可。大多数的分布式事务框架都是基于这个理论来实现的。
Seata也不例外,在Seata的事务管理中有三个重要的角色:
-
TC (Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。
-
TM (Transaction Manager) - 事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。
-
RM (Resource Manager) - 资源管理器:管理分支事务,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
Seata的工作架构如图所示:
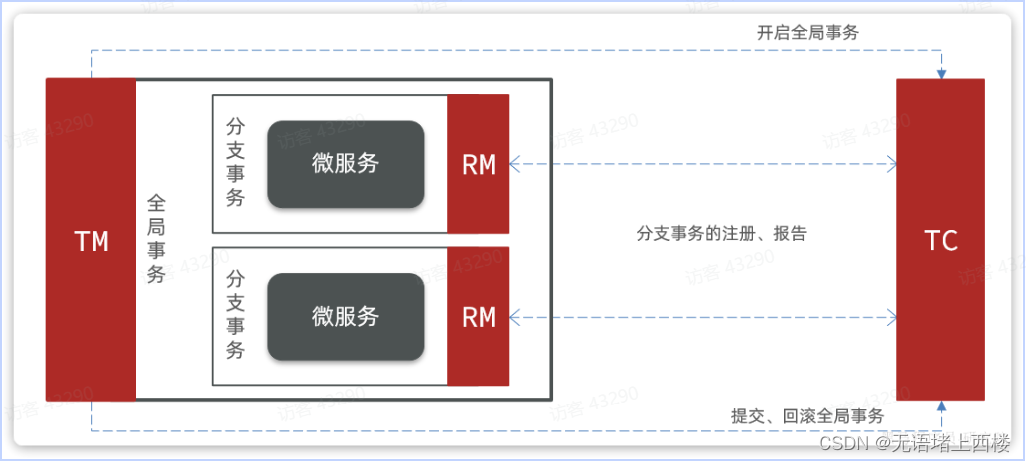
其中,TM和RM可以理解为Seata的客户端部分,引入到参与事务的微服务依赖中即可。将来TM和RM就会协助微服务,实现本地分支事务与TC之间交互,实现事务的提交或回滚。
而TC服务则是事务协调中心,是一个独立的微服务,需要单独部署。
部署TC服务
准备数据库表
Seata支持多种存储模式,但考虑到持久化的需要,我们一般选择基于数据库存储。seata-tc.sql导入数据库表:
CREATE DATABASE IF NOT EXISTS `seata` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
USE `seata`;
------------------------------- The script used when storeMode is 'db' --------------------------------
-- the table to store GlobalSession data
CREATE TABLE IF NOT EXISTS `global_table`
(
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`status` TINYINT NOT NULL,
`application_id` VARCHAR(32),
`transaction_service_group` VARCHAR(32),
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 435
435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









