







channel 死锁的场景
- 当一个
channel中没有数据,而直接读取时,会发生死锁:
q := make(chan int,2)
<-q解决方案是采用select语句,再default放默认处理方式:
q := make(chan int,2)
select{
case val:=<-q:
default:
...
}- 当channel数据满了,再尝试写数据会造成死锁:
q := make(chan int,2)
q<-1
q<-2
q<-3解决方法,采用select
func main() {
q := make(chan int, 2)
q <- 1
q <- 2
select {
case q <- 3:
fmt.Println("ok")
default:
fmt.Println("wrong")
}
}- 向一个关闭的channel写数据。
注意:一个已经关闭的channel,只能读数据,不能写数据。
参考资料:Golang关于channel死锁情况的汇总以及解决方案
对已经关闭的chan进行读写会怎么样?
- 读已经关闭的chan能一直读到东西,但是读到的内容根据通道内关闭前是否有元素而不同。
- 如果chan关闭前,buffer内有元素还未读,会正确读到chan内的值,且返回的第二个bool值(是否读成功)为true。
- 如果chan关闭前,buffer内有元素已经被读完,chan内无值,接下来所有接收的值都会非阻塞直接成功,返回 channel 元素的零值,但是第二个bool值一直为false。
写已经关闭的chan会panic。
说说 atomic底层怎么实现的
atomic源码位于`sync\atomic`。通过阅读源码可知,atomic采用CAS(CompareAndSwap)的方式实现的。所谓CAS就是使用了CPU中的原子性操作。在操作共享变量的时候,CAS不需要对其进行加锁,而是通过类似于乐观锁的方式进行检测,总是假设被操作的值未曾改变(即与旧值相等),并一旦确认这个假设的真实性就立即进行值替换。本质上是不断占用CPU资源来避免加锁的开销。
channel底层实现?是否线程安全。
channel底层实现在src/runtime/chan.go中
channel内部是一个循环链表。内部包含buf, sendx, recvx, lock ,recvq, sendq几个部分;
buf是有缓冲的channel所特有的结构,用来存储缓存数据。是个循环链表;
- sendx和recvx用于记录buf这个循环链表中的发送或者接收的index;
- lock是个互斥锁;
- recvq和sendq分别是接收(<-channel)或者发送(channel <- xxx)的goroutine抽象出来的结构体(sudog)的队列。是个双向链表。
channel是线程安全的。
map的底层实现。
源码位于src\runtime\map.go 中。
go的map和C++map不一样,底层实现是哈希表,包括两个部分:hmap和bucket。
里面最重要的是buckets(桶),buckets是一个指针,最终它指向的是一个结构体:
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}每个bucket固定包含8个key和value(可以查看源码bucketCnt=8).实现上面是一个固定的大小连续内存块,分成四部分:每个条目的状态,8个key值,8个value值,指向下个bucket的指针。
创建哈希表使用的是makemap函数.map 的一个关键点在于,哈希函数的选择。在程序启动时,会检测 cpu 是否支持 aes,如果支持,则使用 aes hash,否则使用 memhash。这是在函数 alginit() 中完成,位于路径:src/runtime/alg.go 下。
map查找就是将key哈希后得到64位(64位机)用最后B个比特位计算在哪个桶。在 bucket 中,从前往后找到第一个空位。这样,在查找某个 key 时,先找到对应的桶,再去遍历 bucket 中的 key。
关于map的查找和扩容可以参考map的用法到map底层实现分析。
select的实现原理?
select源码位于src\runtime\select.go,最重要的scase 数据结构为:
type scase struct {
c *hchan // chan
elem unsafe.Pointer // data element
}scase.c为当前case语句所操作的channel指针,这也说明了一个case语句只能操作一个channel。
scase.elem表示缓冲区地址:
- caseRecv : scase.elem表示读出channel的数据存放地址;
- caseSend : scase.elem表示将要写入channel的数据存放地址;
select的主要实现位于:select.go函数:其主要功能如下:
1. 锁定scase语句中所有的channel
2. 按照随机顺序检测scase中的channel是否ready
2.1 如果case可读,则读取channel中数据,解锁所有的channel,然后返回(case index, true)
2.2 如果case可写,则将数据写入channel,解锁所有的channel,然后返回(case index, false)
2.3 所有case都未ready,则解锁所有的channel,然后返回(default index, false)
3. 所有case都未ready,且没有default语句
3.1 将当前协程加入到所有channel的等待队列
3.2 当将协程转入阻塞,等待被唤醒
4. 唤醒后返回channel对应的case index
4.1 如果是读操作,解锁所有的channel,然后返回(case index, true)
4.2 如果是写操作,解锁所有的channel,然后返回(case index, false)
参考资料:Go select的使用和实现原理.
go的interface怎么实现的?
go interface源码在runtime\iface.go中。
go的接口由两种类型实现iface和eface。iface是包含方法的接口,而eface不包含方法。
iface
对应的数据结构是(位于src\runtime\runtime2.go):
type iface struct {
tab *itab
data unsafe.Pointer
}可以简单理解为,tab表示接口的具体结构类型,而data是接口的值。
- itab:
type itab struct {
inter *interfacetype //此属性用于定位到具体interface
_type *_type //此属性用于定位到具体interface
hash uint32 // copy of _type.hash. Used for type switches.
_ [4]byte
fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter.
}属性interfacetype类似于_type,其作用就是interface的公共描述,类似的还有maptype、arraytype、chantype…其都是各个结构的公共描述,可以理解为一种外在的表现信息。interfaetype和type唯一确定了接口类型,而hash用于查询和类型判断。fun表示方法集。
eface
与iface基本一致,但是用_type直接表示类型,这样的话就无法使用方法。
type eface struct {
_type *_type
data unsafe.Pointer
}这里篇幅有限,深入讨论可以看:深入研究 Go interface 底层实现
go的reflect 底层实现
go reflect源码位于src\reflect\下面,作为一个库独立存在。反射是基于接口实现的。
Go反射有三大法则:
- 反射从接口映射到反射对象;
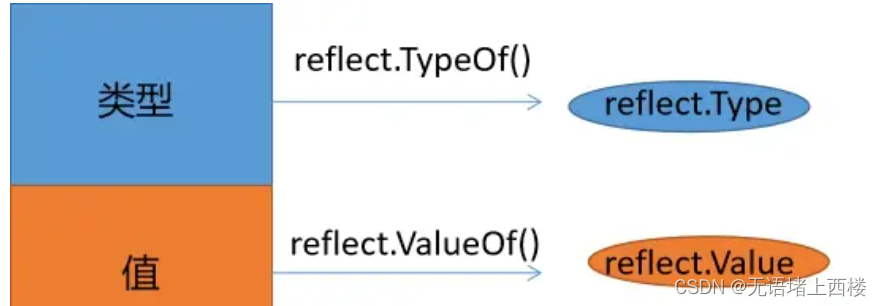
- 反射从反射对象映射到接口值;

- 只有值可以修改(settable),才可以修改反射对象。
Go反射基于上述三点实现。我们先从最核心的两个源文件入手type.go和value.go.
type用于获取当前值的类型。value用于获取当前的值。
go GC的原理知道吗?
如果需要从源码角度解释GC,推荐阅读(非常详细,图文并茂):
https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-garbage-collector/
go里用过哪些设计模式 ?
go的调试/分析工具用过哪些。
go的自带工具链相当丰富,
- go cover : 测试代码覆盖率;
- godoc: 用于生成go文档;
- pprof:用于性能调优,针对cpu,内存和并发;
- race:用于竞争检测;
goroutine监听SIGKILL信号,一旦接收到SIGKILL,则立刻退出。可采用select方法。
进程被kill,如何保证所有goroutine顺利退出
goroutine监听SIGKILL信号,一旦接收到SIGKILL,则立刻退出。可采用select方法。
var wg = &sync.WaitGroup{}
func main() {
wg.Add(1)
go func() {
c1 := make(chan os.Signal, 1)
signal.Notify(c1, syscall.SIGINT, syscall.SIGTERM, syscall.SIGQUIT)
fmt.Printf("goroutine 1 receive a signal : %v\n\n", <-c1)
wg.Done()
}()
wg.Wait()
fmt.Printf("all groutine done!\n")
}说说context包的作用?你用过哪些,原理知道吗?
context可以用来在goroutine之间传递上下文信息,相同的context可以传递给运行在不同goroutine中的函数,上下文对于多个goroutine同时使用是安全的,context包定义了上下文类型,可以使用background、TODO创建一个上下文,在函数调用链之间传播context,也可以使用WithDeadline、WithTimeout、WithCancel 或 WithValue 创建的修改副本替换它,听起来有点绕,其实总结起就是一句话:context的作用就是在不同的goroutine之间同步请求特定的数据、取消信号以及处理请求的截止日期。
关于context原理,可以参看:小白也能看懂的context包详解:从入门到精通
grpc为啥好,基本原理是什么,和http比呢
官方介绍:gRPC 是一个现代开源的高性能远程过程调用 (RPC) 框架,可以在任何环境中运行。它可以通过对负载平衡、跟踪、健康检查和身份验证的可插拔支持有效地连接数据中心内和跨数据中心的服务。它也适用于分布式计算的最后一英里,将设备、移动应用程序和浏览器连接到后端服务。
区别:
- rpc是远程过程调用,就是本地去调用一个远程的函数,而http是通过 url和符合restful风格的数据包去发送和获取数据;
- rpc的一般使用的编解码协议更加高效,比如grpc使用protobuf编解码。而http的一般使用json进行编解码,数据相比rpc更加直观,但是数据包也更大,效率低下;
- rpc一般用在服务内部的相互调用,而http则用于和用户交互;
相似点:
都有类似的机制,例如grpc的metadata机制和http的头机制作用相似,而且web框架,和rpc框架中都有拦截器的概念。grpc使用的是http2.0协议。
官网:gRPC
其他问题















 7361
7361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









