



为什么选择学习这篇代码?
-
核心思想: 它体现了“用户行为数据”是搜广推系统的基石。通过分析用户对物品的偏好,来发现物品之间的关联,进而进行推荐。
-
直观易懂: “喜欢A的用户也喜欢B,那么A和B是相似的”这个逻辑非常直观。
-
应用广泛: 它的思想被广泛应用于推荐系统、搜索引擎的相关推荐、甚至广告系统的兴趣匹配中。
-
可扩展性: 它是许多更复杂算法(如矩阵分解、深度学习推荐模型)的基础或前置知识。
当一个用户喜欢了某个物品A时,我们找到与物品A相似的其他物品B、C、D,并将这些相似物品推荐给该用户。这里的关键在于如何定义和计算“物品相似度”。
整体代码:
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
data = {
'user_id': ['user_A', 'user_A', 'user_A', 'user_B', 'user_B', 'user_B', 'user_C', 'user_C', 'user_D', 'user_D', 'user_D'],
'item_id': ['item_1', 'item_2', 'item_3', 'item_1', 'item_3', 'item_4', 'item_2', 'item_5', 'item_1', 'item_2', 'item_4'],
'interaction': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}
df = pd.DataFrame(data)
print("--- 原始用户-物品交互数据 ---")
print(df)
print("\n")
user_item_matrix = df.pivot_table(index='user_id', columns='item_id', values='interaction').fillna(0)
print("--- 用户-物品矩阵 ---")
print(user_item_matrix)
print("\n")
item_user_matrix = user_item_matrix.T
print("--- 物品-用户矩阵 (用于计算物品相似度) ---")
print(item_user_matrix)
print("\n")
# cosine_similarity返回的是一个矩阵,(num_items x num_items)
item_similarity = cosine_similarity(item_user_matrix)
item_similarity_df = pd.DataFrame(item_similarity, index=item_user_matrix.index, columns=item_user_matrix.index)
print("--- 物品相似度矩阵 (余弦相似度) ---")
print(item_similarity_df)
print("\n")
def recommend_items(user_id, user_item_matrix, item_similarity_df, top_n=3, k_similar_items=5):
user_interactions = user_item_matrix.loc[user_id]
print(user_interactions)
interacted_items = user_interactions[user_interactions > 0].index.tolist()
print(f"用户 {user_id} 已交互的物品: {interacted_items}")
recommendation_scores = {}
for item in interacted_items:
similar_items = item_similarity_df[item].sort_values(ascending=False)
similar_items = similar_items[similar_items.index != item]
similar_items = similar_items[similar_items > 0]
similar_items = similar_items.head(k_similar_items)
print(f" 与 {item} 最相似的物品: {similar_items.index.tolist()}")
for similar_item, similarity_score in similar_items.items():
if user_item_matrix.loc[user_id, similar_item] == 0:
recommendation_scores[similar_item] = recommendation_scores.get(similar_item, 0) + similarity_score
recommended_items = pd.Series(recommendation_scores).sort_values(ascending=False)
return recommended_items.head(top_n)
print("--- 为 'user_A' 生成推荐 ---")
recommended_for_A = recommend_items('user_A', user_item_matrix, item_similarity_df, top_n=2)
print(f"推荐给 user_A 的物品:\n{recommended_for_A}")
print("\n")
print("--- 为 'user_C' 生成推荐 ---")
recommended_for_C = recommend_items('user_C', user_item_matrix, item_similarity_df, top_n=2)
print(f"推荐给 user_C 的物品:\n{recommended_for_C}")
print("\n")逐段解析:
步骤1: 模拟用户-物品交互数据
假设我们有以下用户和物品的交互数据
1表示用户与物品有交互(如购买、点击、收藏),0则表示没有。
data = {
'user_id': ['user_A', 'user_A', 'user_A', 'user_B', 'user_B', 'user_B', 'user_C', 'user_C', 'user_D', 'user_D', 'user_D'],
'item_id': ['item_1', 'item_2', 'item_3', 'item_1', 'item_3', 'item_4', 'item_2', 'item_5', 'item_1', 'item_2', 'item_4'],
'interaction': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}
df = pd.DataFrame(data)
print("--- 原始用户-物品交互数据 ---")
print(df)然后将数据转换为pandas的dataframe格式,展示如下图。
步骤2: 构建用户-物品矩阵
使用pivot_table将刚刚的dataframe数据转换为用户-物品矩阵,横标签为用户id,竖标签为物品id,矩阵各元素为用户与物品之间的交互情况(1为有交互,0为无交互),并且将矩阵中为NaN的元素替换为0
user_item_matrix = df.pivot_table(index='user_id', columns='item_id', values='interaction').fillna(0)
print("--- 用户-物品矩阵 ---")
print(user_item_matrix)该矩阵如下图所示

步骤3: 计算物品之间的相似度
为了计算物品相似度,我们需要将上面的用户-物品矩阵进行转置,使行代表物品,列代表用户。然后放入cosine_similarity函数中,计算得到余弦相似度,这个值得到了这五个物品两两之间的相似度。
item_user_matrix = user_item_matrix.T
print("--- 物品-用户矩阵 (用于计算物品相似度) ---")
print(item_user_matrix)
item_similarity = cosine_similarity(item_user_matrix)转置后的矩阵如下图

将相似度矩阵转换为DataFrame,方便查看和索引
item_similarity_df = pd.DataFrame(item_similarity, index=item_user_matrix.index, columns=item_user_matrix.index)
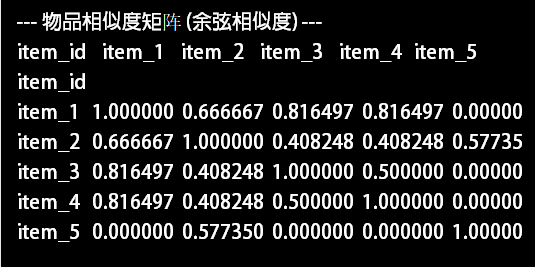
print("--- 物品相似度矩阵 (余弦相似度) ---")
print(item_similarity_df)下图就是相似度矩阵
步骤4: 生成推荐列表
def recommend_items(user_id, user_item_matrix, item_similarity_df, top_n=3, k_similar_items=5):
"""
为指定用户生成推荐列表
Args:
user_id (str): 目标用户的ID
user_item_matrix (pd.DataFrame): 用户-物品交互矩阵
item_similarity_df (pd.DataFrame): 物品相似度矩阵
top_n (int): 最终推荐的物品数量
k_similar_items (int): 考虑每个已交互物品的多少个最相似物品
Returns:
pd.Series: 推荐物品及其推荐得分
"""
# 获取用户已交互的物品
user_interactions = user_item_matrix.loc[user_id]
print(user_interactions)
# 找到用户已交互且交互值为1的物品
interacted_items = user_interactions[user_interactions > 0].index.tolist()
print(f"用户 {user_id} 已交互的物品: {interacted_items}")
# 用于存储推荐物品及其得分
recommendation_scores = {}
for item in interacted_items:
# 获取与当前物品最相似的物品(排除自身)
# 排序并取前 k_similar_items 个
similar_items = item_similarity_df[item].sort_values(ascending=False)
# 过滤掉自身和相似度为0的物品
similar_items = similar_items[similar_items.index != item]
similar_items = similar_items[similar_items > 0] # 排除相似度为0的物品
similar_items = similar_items.head(k_similar_items)
print(f" 与 {item} 最相似的物品: {similar_items.index.tolist()}")
for similar_item, similarity_score in similar_items.items():
# 检查该相似物品是否用户已经交互过
if user_item_matrix.loc[user_id, similar_item] == 0: # 如果用户未交互过
# 累加推荐得分
# 这里的得分可以是简单相加,也可以是加权平均(例如,用户对原物品的评分 * 相似度)
# 由于我们是二元交互,直接累加相似度即可
recommendation_scores[similar_item] = recommendation_scores.get(similar_item, 0) + similarity_score
# 将推荐得分转换为Series并排序
recommended_items = pd.Series(recommendation_scores).sort_values(ascending=False)
return recommended_items.head(top_n)loc是pandas中常用的索引方式,表示索引dataframe矩阵中标签名为user_id的那一行或列的全部元素;
user_interactions > 0会生成一个布尔序列,表示每个物品的交互值是否大于 0;
接着user_interactions[user_interactions > 0]则筛掉了原来矩阵中为0的元素及其标签,剩下了都是1的;
.index则得到该矩阵的序号,即标签,不包含元素;再用.tolist生成列表。
user_interactions = user_item_matrix.loc[user_id]
interacted_items = user_interactions[user_interactions > 0].index.tolist()下面这部分代码从相似度矩阵中提取与特定物品 item 相关的相似度列,然后按照相似度值从高到低排序。
similar_items = item_similarity_df[item].sort_values(ascending=False)下面三句,第一句是提取出除自己外的其他元素;第二句是排除掉相似度为0的物品;第三句是仅保留前k_similar_items个物品。
similar_items = similar_items[similar_items.index != item]
similar_items = similar_items[similar_items > 0]
similar_items = similar_items.head(k_similar_items)首先,recommendation_scores是字典。
recommendation_scores.get(similar_item, 0) 的含义是:
-
“去 recommendation_scores 字典里找 similar_item 的当前得分。”
-
“如果 similar_item 已经在字典里了,那就取出它当前的得分。”
-
“如果 similar_item 还没有在字典里,那就把它当前的得分视为 0。”
... + similarity_score 的作用:
-
recommendation_scores.get(similar_item, 0) 的结果(无论是已有的得分还是 0)会与当前的 similarity_score 相加。
这里直接将相似度作为用户对未交互过的物品的预估评分,并以此叠加。
recommendation_scores[similar_item] = recommendation_scores.get(similar_item, 0) + similarity_score以上就是对代码的解析,这个代码只是对于ItemCF的基础实现,可以理解这个代码进行入门。

















 9243
9243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









