









Item-CF召回的全面解释
Item-CF(基于物品的协同过滤,Item-based Collaborative Filtering) 是推荐系统中最常用的一种算法,尤其适用于用户行为数据丰富的场景。它的核心思想是:通过计算物品之间的相似性,根据用户的历史行为推荐与其互动过的物品相似的其他物品。如果两个物品被同一群用户多次共同互动(例如共同被购买或点击),它们之间的相似度就越高,可以作为互相的推荐对象。
应用场景:
- 电商平台推荐:用户买了 A 商品,可以推荐与 A 相似的商品。
- 视频平台推荐:用户看了某部电影,可以推荐相似类型的电影。
下面,我们将详细介绍 Item-CF召回 的底层原理,并通过源代码展示完整的实现步骤,从基础到生产环境的应用,易于理解和使用。
1. Item-CF 的核心原理
Item-CF 的目标是:根据用户的历史行为记录,找到与用户行为最相关的物品,作为推荐结果。
1.1 算法的核心步骤
-
构建用户-物品行为矩阵:
- 每一行代表一个用户,每一列代表一个物品。
- 矩阵的值表示用户与物品的交互强度(如点击次数、评分、购买行为等)。
-
计算物品相似度:
- 物品之间的相似度是由它们共同被用户交互的次数决定的。
- 常用的相似度计算方法包括 余弦相似度 和 皮尔逊相关系数。
-
为用户推荐相似物品:
- 根据用户历史交互的物品,找到这些物品的相似物品,并结合用户对原物品的偏好强度,生成推荐分数,由高到低排序来判断推荐优先级。
数据结构
假设有以下用户行为数据:
| 用户ID | 物品A | 物品B | 物品C | 物品D |
|---|---|---|---|---|
| 用户1 | 1 | 1 | 0 | 1 |
| 用户2 | 1 | 1 | 1 | 0 |
| 用户3 | 0 | 1 | 1 | 1 |
- 1 表示用户与物品有交互(如购买、点击等)。
- 0 表示用户未与物品交互。
1.2 核心公式
1.2.1 物品相似度计算
1. 余弦相似度公式:
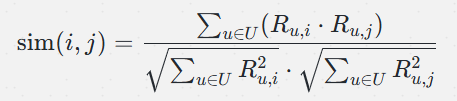
:用户 u 对物品 i 的评分(或交互值)。
- U:同时交互过物品 i 和 j 的用户集合。
2. 皮尔逊相关系数:
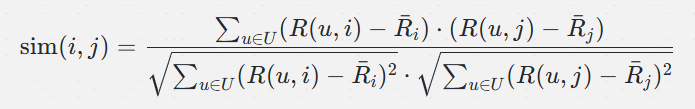
:物品 i 的平均评分。
1.2.2 推荐分数计算
对于用户 u,推荐分数为:
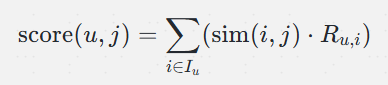
:用户 u 交互过的物品集合。
- sim(i,j):物品 i 和 j 的相似度。
2. Item-CF 的实现
我们将从底层实现每一步,详细展示代码。
推荐步骤
-
构建用户行为矩阵:
- 行表示用户,列表示物品。
- 矩阵中的值表示用户对物品的行为(如评分或购买次数)。
-
计算物品相似度矩阵:
- 针对每一对物品,计算它们之间的相似度。
-
生成推荐列表:
- 根据用户历史行为中互动过的物品,找到相似的物品,按照相似度排序推荐。
2.1 数据准备
模拟用户-物品交互数据。
import numpy as np
import pandas as pd
# 模拟用户-物品交互数据
data = [
{"user": 1, "item": "A", "rating": 5},
{"user": 1, "item": "B", "rating": 3},
{"user": 2, "item": "A", "rating": 4},
{"user": 2, "item": "C", "rating": 5},
{"user": 3, "item": "B", "rating": 2},
{"user": 3, "item": "C", "rating": 4},
]
# 转换为 DataFrame
df = pd.DataFrame(data)
# 打印交互数据
print(df)
2.2 构建用户-物品行为矩阵
# 构建用户-物品行为矩阵
user_item_matrix = df.pivot_table(index="user", columns="item", values="rating", fill_value=0)
# 打印用户-物品行为矩阵
print(user_item_matrix)
结果示例:
item A B C
user
1 5 3 0
2 4 0 5
3 0 2 4
2.3 计算物品相似度
使用余弦相似度计算物品相似度矩阵。
from sklearn.metrics.pairwise import cosine_similarity
# 物品特征矩阵(转置用户-物品行为矩阵)
item_matrix = user_item_matrix.T
# 计算余弦相似度
item_similarity = cosine_similarity(item_matrix)
# 转换为 DataFrame,便于查看
item_similarity_df = pd.DataFrame(item_similarity, index=item_matrix.index, columns=item_matrix.index)
# 打印物品相似度矩阵
print(item_similarity_df)
结果示例:
item A B C
item
A 1.000000 0.707107 0.707107
B 0.707107 1.000000 0.894427
C 0.707107 0.894427 1.000000
说明:
- 对角线值为 1,表示物品与自身完全相似。
- 非对角线值越接近 1,表示两个物品的相似度越高。
2.4 为用户推荐相似物品
# 为用户生成推荐
def recommend_items(user_id, user_item_matrix, item_similarity_df, top_k=3):
# Step 1: 获取用户的历史行为
user_ratings = user_item_matrix.loc[user_id]
# Step 2: 计算推荐分数
scores = {}
for item, rating in user_ratings.items():
if rating > 0: # 只考虑用户交互过的物品
similar_items = item_similarity_df[item]
for similar_item, similarity in similar_items.items():
if similar_item not in user_ratings or user_ratings[similar_item] == 0:
scores[similar_item] = scores.get(similar_item, 0) + similarity * rating
# Step 3: 排序推荐结果
recommended_items = sorted(scores.items(), key=lambda x: x[1], reverse=True)[:top_k]
return recommended_items
# 示例:为用户1推荐物品
recommended = recommend_items(user_id=1, user_item_matrix=user_item_matrix, item_similarity_df=item_similarity_df)
print("Recommended items for user 1:", recommended)
结果示例:
Recommended items for user 1: [('C', 6.535533905932738)]
每一步的设计原因和原理
-
用户-物品矩阵的构建:
- 记录用户与物品之间的交互行为,作为物品相似度计算的基础。
-
物品相似度计算:
- 利用余弦相似度衡量物品间的相似性,能够捕捉共享用户行为的相似性。
-
推荐分数的加权求和:
- 基于用户历史物品的相似物品进行打分,将相似度加权叠加,生成推荐物品。
-
排序与去重:
- 排除用户已经交互过的物品,只推荐新物品,并根据相似度排序。
3. 工业化部署
将 Item-CF 实现为在线服务,需要实时响应用户请求。
Item-CF的工业级部署,可以参考以下流程:
-
离线计算物品相似度矩阵:
- 将物品相似度矩阵预先计算并保存,用于在线推荐。
-
实时推荐服务:
- 部署API服务,接收用户请求,根据用户行为计算推荐物品。
-
优化性能:
- 使用分布式计算(如Spark)处理大规模数据。
- 使用稀疏矩阵存储用户行为数据和相似度矩阵,减少内存占用。
3.1 构建 RESTful API 服务
from flask import Flask, request, jsonify
app = Flask(__name__)
# 加载物品相似度和用户-物品行为矩阵
user_item_matrix = user_item_matrix # 用户-物品矩阵
item_similarity_df = item_similarity_df # 物品相似度矩阵
@app.route("/recommend", methods=["POST"])
def recommend():
# 获取请求数据
data = request.json # 请求体应包含 {"user_id": 1}
user_id = data.get("user_id")
# 推荐物品
recommended = recommend_items(user_id, user_item_matrix, item_similarity_df)
# 返回推荐结果
return jsonify({"user_id": user_id, "recommendations": recommended})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)
3.2 使用示例
POST 请求示例:
curl -X POST http://localhost:5000/recommend -H "Content-Type: application/json" -d '{"user_id": 1}'
返回示例:
{
"user_id": 1,
"recommendations": [
["C", 6.535533905932738]
]
}
4. Item-CF 的优缺点
优点
- 简单直观,容易实现。
- 适用于用户行为数据丰富的场景。
- 可解释性强:推荐的物品相似度来源清晰。
缺点
- 冷启动问题:对新物品或新用户效果较差。
- 稀疏性问题:用户-物品矩阵过于稀疏时,物品相似度难以计算。
- 扩展性差:当物品数量特别大时,计算相似度的开销较高。
总结
Item-CF 是推荐系统中经典且高效的算法,通过基于历史行为计算物品之间的相似度,为用户推荐相似物品。本文从算法原理到代码实现,再到工业部署,全面介绍了如何将 Item-CF 应用于实际场景,并提供了详细注释和示例代码,易于理解和实践。


















 2127
2127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









