









692. 前K个高频单词
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
示例 1:
输入: words = [“i”, “love”, “leetcode”, “i”, “love”, “coding”], k = 2
输出: [“i”, “love”]
解析: “i” 和 “love” 为出现次数最多的两个单词,均为2次。
注意,按字母顺序 “i” 在 “love” 之前。
示例 2:
输入: [“the”, “day”, “is”, “sunny”, “the”, “the”, “the”, “sunny”, “is”, “is”], k = 4
输出: [“the”, “is”, “sunny”, “day”]
解析: “the”, “is”, “sunny” 和 “day” 是出现次数最多的四个单词,
出现次数依次为 4, 3, 2 和 1 次。
注意:
1 <= words.length <= 500
1 <= words[i] <= 10
words[i] 由小写英文字母组成。
k 的取值范围是 [1, 不同 words[i] 的数量]
进阶:尝试以 O(n log k) 时间复杂度和 O(n) 空间复杂度解决。
原题链接:https://leetcode.cn/problems/top-k-frequent-words/description/
思路:
首先将这些单词放入map中统计次数,k是单词,v是次数。
然后对这棵树进行频率大小的的排序,这里要注意,如果用快排会导致结果有可能错误,因为map是按照k(单词)排序的,也是字典排序,那么最多也就是将频率高的单词排在前面,并不需要动其他的单词原本的顺序,但是快排是一个不稳定排序,有可能会打乱原来的排序。
代码:
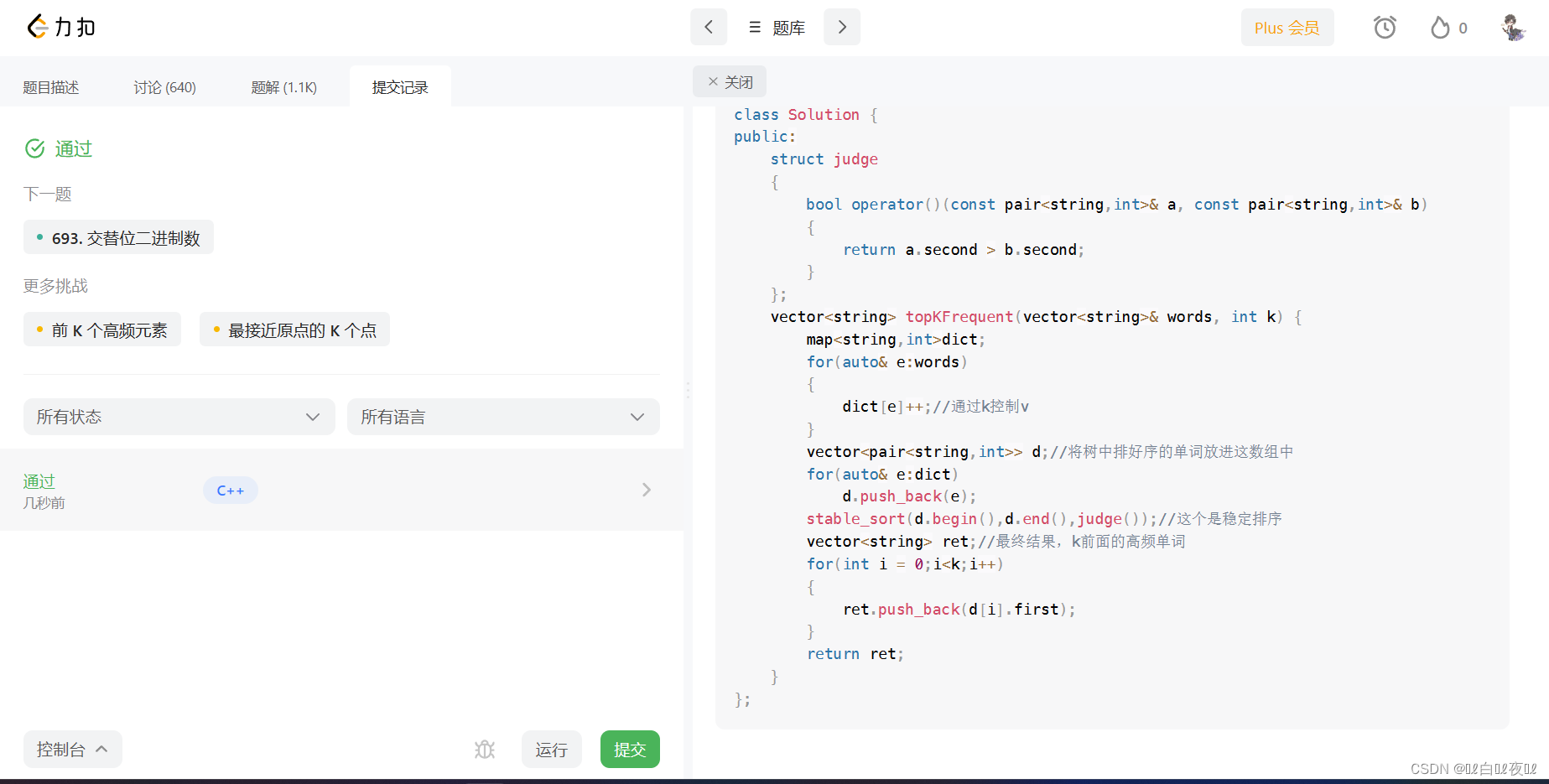
class Solution {
public:
struct judge
{
bool operator()(const pair<string, int>& a, const pair<string, int>& b)//稳定排序的仿函数
{
return a.second > b.second;
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string, int>dict;
for (auto& e : words)//对所有单词进行字典排序
{
dict[e]++;//通过k控制v
}
vector<pair<string, int>> d;//将树中排好序的单词放进这数组中
for (auto& e : dict)
d.push_back(e);
stable_sort(d.begin(), d.end(), judge());//这个是稳定排序
vector<string> ret;//最终结果,k前面的高频单词
for (int i = 0; i < k; i++)
{
ret.push_back(d[i].first);//放入前k个单词
}
return ret;
}
};
















 156
156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











