










🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
do_sample
do_sample 参数控制是否使用采样方法生成输出。当 do_sample=True 时,模型会根据下一个 token 的概率分布进行采样;当 do_sample=False 时,模型会选择概率最大的 token 作为输出。
temperature
temperature 参数通过影响 softmax 控制生成输出时每个 token 的概率分布的平滑程度。
不考虑 temperature 参数,softmax 概率分布的计算公式为:
prob ( x i ) = e x i ∑ j = 1 n e x j \text{prob}(x_i) = \frac{e^{x_i}}{\sum_{j=1}^{n} e^{x_j}} prob(xi)=∑j=1nexjexi
加入 temperature 参数后,softmax 概率分布的计算公式为:
prob ( x i , t ) = e x i t ∑ j = 1 n e x j t \text{prob}(x_i,t) = \frac{e^{\frac{x_i}{t}}}{\sum_{j=1}^{n} e^{\frac{x_j}{t}}} prob(xi,t)=∑j=1netxjetxi
下图展示了 temperature 参数的影响:

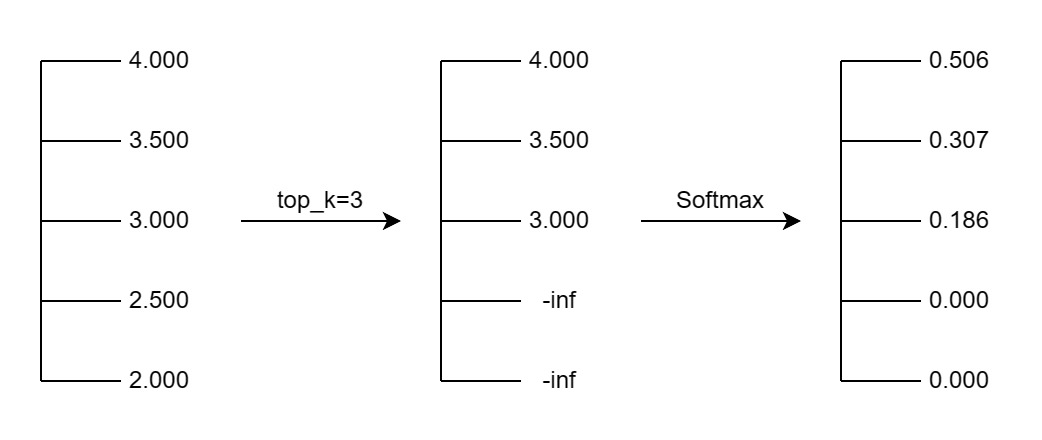
top_k
top_k 参数控制生成输出时,只考虑概率最高的 top_k 个 token。
下图展示了 top_k 参数的影响:
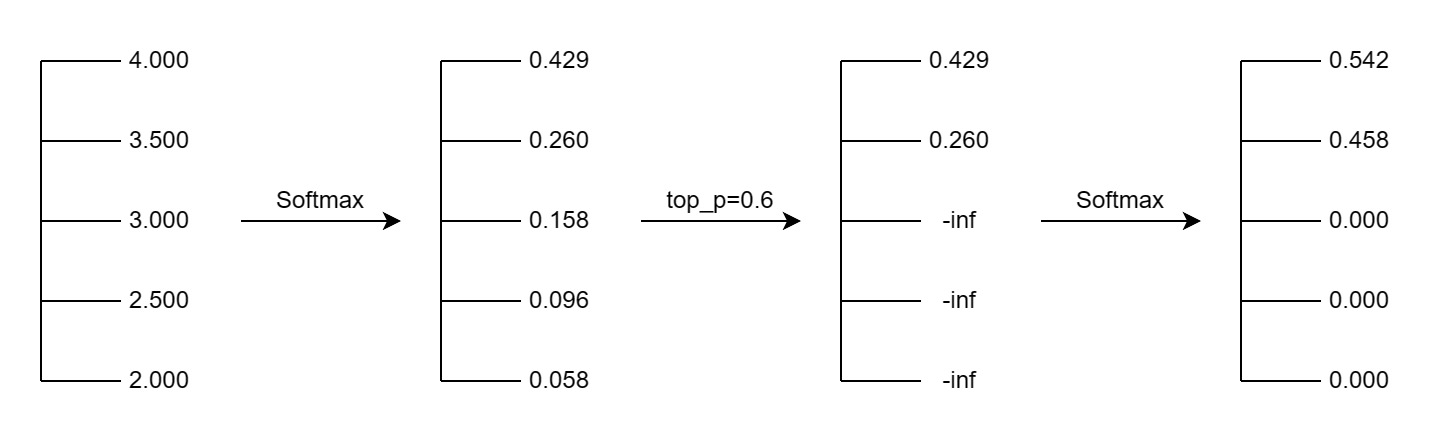
top_p
top_p 参数与 top_k 参数类似,区别在于 top_p 参数控制生成输出时,只考虑累计概率分布在前 top_p 的 token。
下图展示了 top_p 参数的影响:
协同工作
同时使用 temperature、top_k、top_p 参数时,它们的影响会以一定顺序叠加。
下图展示了同时使用 temperature、top_k、top_p 参数的影响:

temperature、top_k、top_p 参数不会改变各 token 概率的相对大小,因此当 do_sample=False 时,token 的选择不会受到上述三个参数的影响。
















 2070
2070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











